python 爬蟲實例----采集''極客學院"課程頁面數據
import requests
import re
class spider(object):
def __init__(self):
print (u'開始爬取內容。。。')
# getsource用來獲取網頁源代碼
def getsource(self,url):
html = requests.get(url)
return html.text
# changepage用來生產不同頁數的鏈接
def changepage(self, url, total_page):
now_page = int(re.search('pageNum=(\d+)', url, re.S).group(1))
page_group = []
for i in range(now_page,total_page+1):
link = re.sub('pageNum=\d+', 'pageNum=%s'%i, url, re.S)
page_group.append(link)
return page_group
# geteveryclass用來抓取每個課程塊的信息
def geteveryclass(self, source):
everyclass = re.findall('<li id="\d+" test="0" deg="0"(.*?)</li>', source, re.S)
return everyclass
# getinfo用來從每個課程塊中提取出我們需要的信息
def getinfo(self, eachclass):
info = {}
info['title'] = re.search('title="(.*?)" alt="', eachclass, re.S).group(1)
info['content'] = re.search('<p style="height: 0px; opacity: 0; display: none;">\s*(.*?)\s*</p>',
eachclass,re.S).group(1)
info['classtime'] = re.findall('<dd class="mar-b8"><i class="time-icon"></i><em>(.*?)\s\t\t\t\t\t\t\t(.*?)</em>', eachclass, re.S)
info['classlevel'] = re.findall('<i class="xinhao-icon\d*"></i><em>(.*?)</em>', eachclass, re.S)
info['learnnum'] = re.search('<em class="learn-number">(.*?)</em>', eachclass, re.S).group(1)
return info
# saveinfo用來保存結果到info.txt文件中
def saveinfo(self, classinfo):
with open('info.txt','w') as f:
for each in classinfo:
f.writelines('title:' + each['title'] + '\n')
f.writelines('content:' + each['content'] + '\n')
f.writelines('classtime:' + each['classtime'].__str__() + '\n')
f.writelines('classlevel:' + each['classlevel'].__str__() + '\n')
f.writelines('learnnum:' + each['learnnum'] +'\n\n')
if __name__ == '__main__':
classinfo = []
url = 'http://www.jikexueyuan.com/course/?pageNum=1'
jikespider = spider()
all_links = jikespider.changepage(url,20)
for link in all_links:
print (u'正在處理頁面:' + link)
html = jikespider.getsource(link)
everyclass = jikespider.geteveryclass(html)
for each in everyclass:
info = jikespider.getinfo(each)
classinfo.append(info)
jikespider.saveinfo(classinfo)
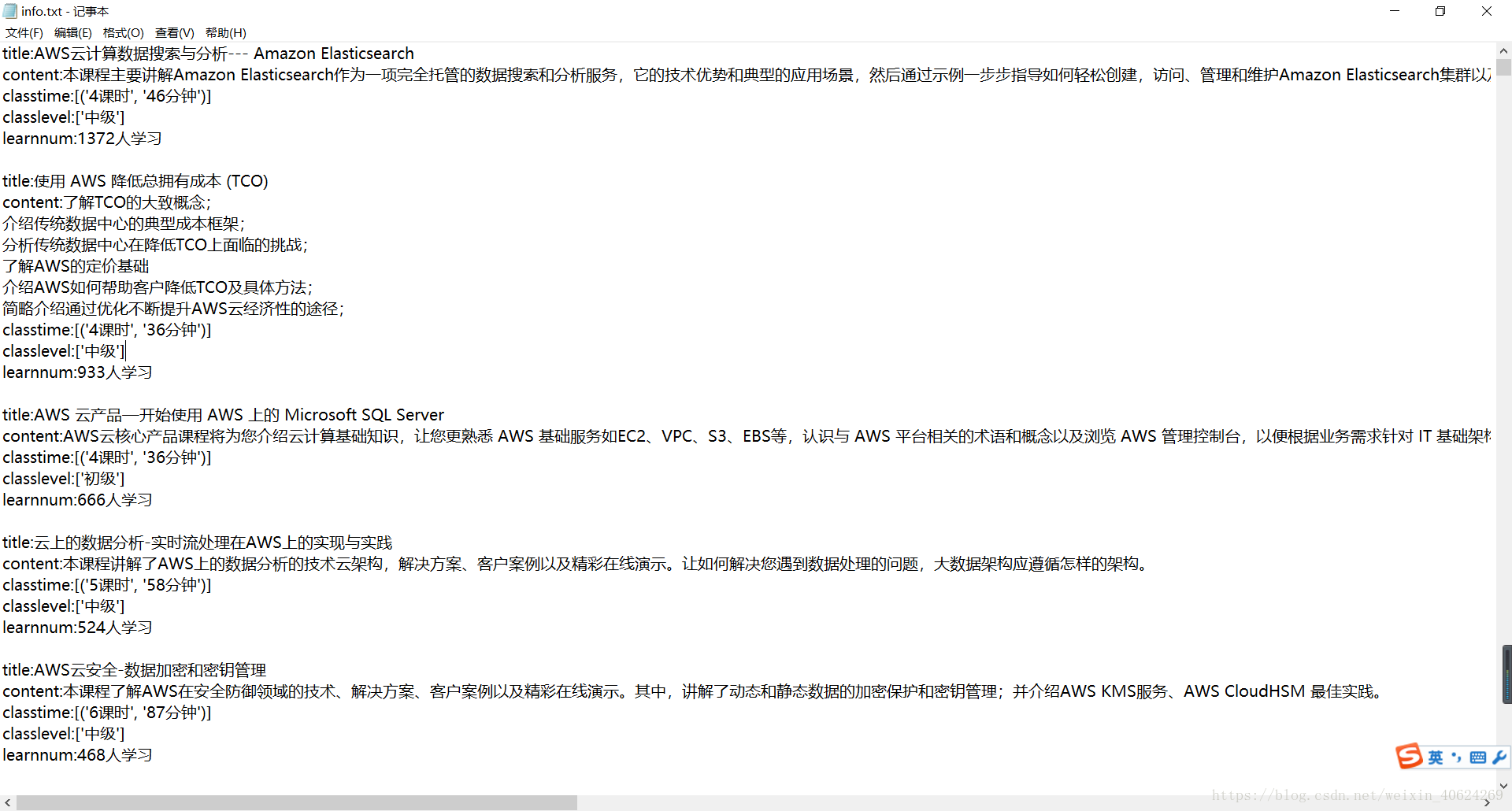
結果如下
智能推薦

極客學院的前端課程(十一)
3.3.2 CSS定位——浮動 第一個文件 style.css 第二個文件 55.html 3.3.3 CSS定位——浮動的應用 第一個文件 style.css 第二個文件 56.html 3.4.1 CSS盒子模型——概述 3.4.2 CSS盒子模型——內邊距 第一個文件 style.css 第二個文...

極客學院的前端課程(十二)
3.4.5 CSS盒子模型——外邊距合并 第一個文件style.css 第二個文件 60.html 3.4.6 CSS盒子模型——盒子模型應用 第一個文件style.css 第二個文件 62.html 3.5.1 CSS常用操作——對齊 第一個文件 style.css 第二個文件 63.html 3.5.2 CSS常用操作&m...

極客學院的前端課程(十四)
3.7.5 CSS瀑布流效果 第一個文件 style.css 第二個文件 73. html 3.8.1 HTML與CSS簡單頁面效果實例 第一個文件 style.css 第二個文件74.html 4.1.1 Javascript基礎——介紹,實現,輸出 文件 75.html 4.1.2 Javascript基礎——語法和注釋 4.1.3 Javasc...

極客學院的前端課程(十三)
3.6.2 選擇器——選擇器詳解2 第一個文件 style.css 第二個文件68.html 3.7.1 CSS動畫——2D, 3D轉換 第一個文件 style.css 第二個文件69.html 3.7.2 CSS動畫——過渡 第一個文件 style.css 第二個文件 70.html 3.7.3 CSS動畫—&m...

極客學院的前端課程(十五)
4.2.1 Javascript語法——運算符(1) 78.html 4.2.2 Javascript語法——運算符(2) 79.html 4.2.3 Javascript語法——條件語句if...else... 80.html 4.2.4 Javascript語法——條件語句switch 81.htm...
猜你喜歡

極客學院的前端課程(十六)
4.3.2 Javascript函數——定義函數 86.html 4.3.3 Javascript函數——調用函數 87.html 4.3.4 Javascript函數——帶參數的函數 88.html 4.3.5 Javascript函數——帶返回值的函數 89.html &nb...
極客學院的前端課程(一)
該套系列依據視頻: https://www.bilibili.com/video/av10298843 1.1.1 走進前端工程師的世界 淘寶主頁會根據不同的終端,比如iPhone5, iPad3等等進行頁面顯示的自動適配。。。 HTML5 WebGL可以進行3D的顯示 2.1.1 HTML5 開發前的準備 2.1.2 開發前的準備——快捷鍵 2.2.1 HTML...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...