多核多線程自旋鎖spinlock 與互斥量mutex性能分析
標簽: 嵌入式編程基礎
多核多線程 自旋鎖(spinlock )與 互斥量(mutex)
mutex方式:(sleep-wait)
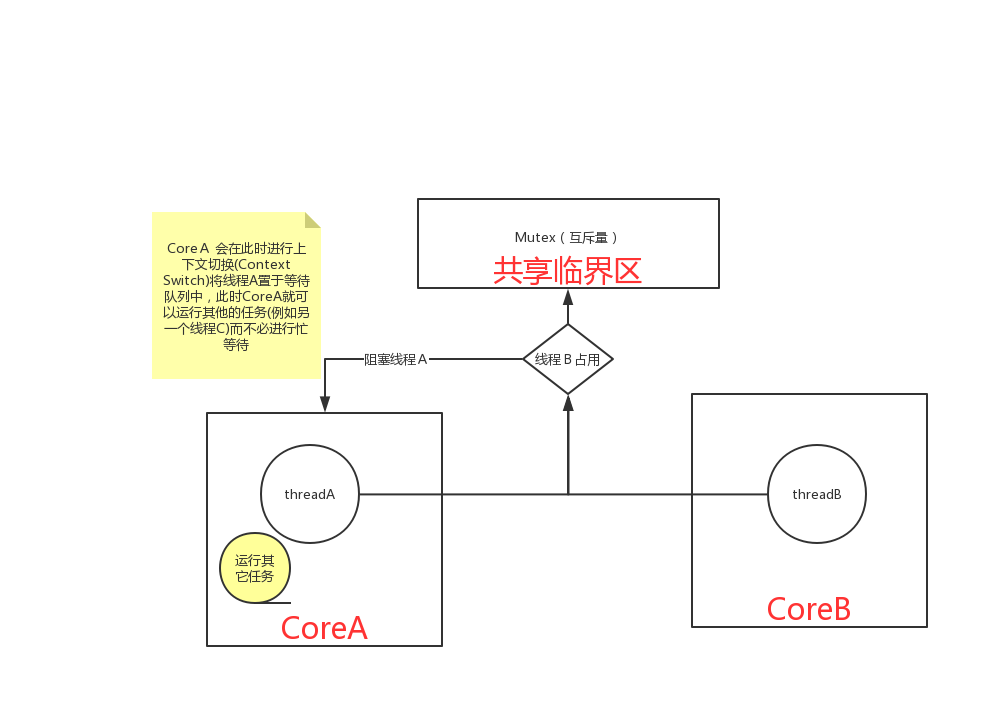
從實現原理上來講,Mutex屬于sleep-waiting類型的鎖。例如在一個雙核的機器上有兩個線程(線程A和線程B),它們分別運行在Core0和Core1上。假設線程A想要通過pthread_mutex_lock操作去得到一個臨界區的鎖,而此時這個鎖正被線版程B所持有,那么線程A就會被阻塞(blocking),Core0 會在此時進行上下文切換(Context Switch)將線程A置于等待隊列中,權此時Core0就可以運行其他的任務(例如另一個線程C)而不必進行忙等待。
Mutex適合對鎖操作非常頻繁,臨界區較大的場景,并且具有更好的適應性。
對鎖操作非常頻繁:
例如測試程序關鍵代碼,每獲取一次鎖,執行 100000次 累加 操作(臨界區較大),耗時比較長
//--每獲取一次鎖,執行 100000次 累加 操作
//--耗時比較長
for (j = 0; j < 100000; j++) {
//--打印優先完成的線程ID
if (g_count++ == 123456789){
printf("Thread %lu wins!\n", (unsigned long)gettid());
}
}
盡管相比spin lock它會花費更多的開銷(主要是上下文切換),但是它能適合實際開發中復雜的應用場景,在保證一定性能的前提下提供更大的靈活度。
消耗時間的地方:(系統調用,mutex會在鎖沖突時調用system wait)
上下文切換對已經拿著鎖的那個線程性能也是有影響的,因為當該線程釋放該鎖時它需要通知操作系統去喚醒那些被阻塞的線程
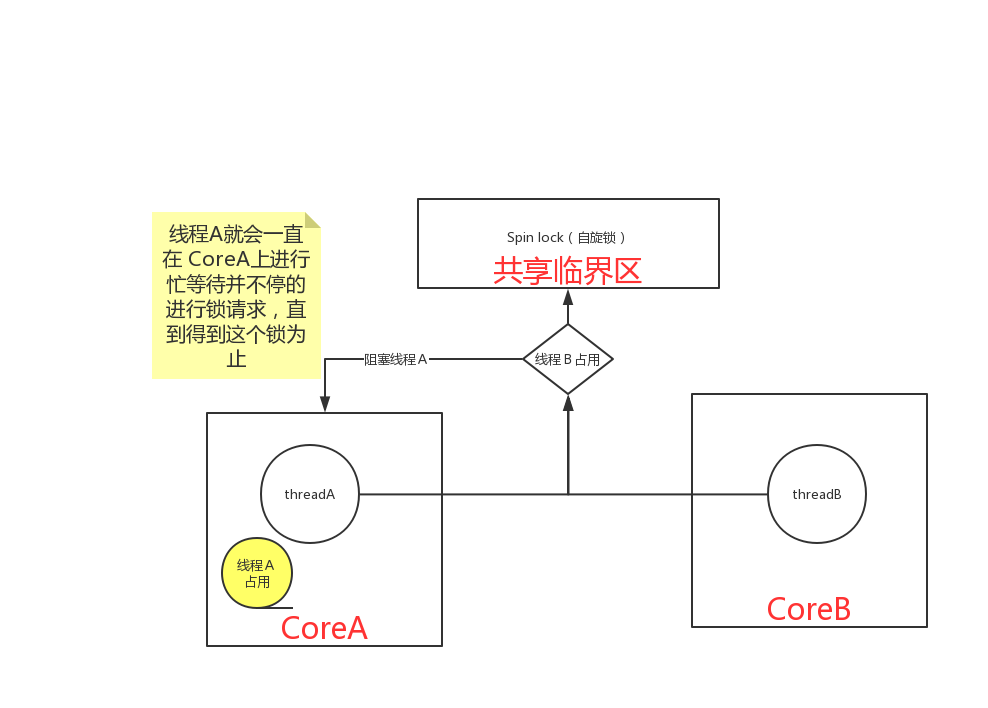
spinlock 方式:(busy-wait)
spin lock 性能更好(花費更少的cpu指令),但是它只適應用于臨界區運行時間很短的場景。
臨界區運行時間很短:
例如測試程序關鍵線程代碼,每獲取一次鎖,執行 1次 賦值和 pop_front 操作,耗時非常短
//---取出列表第一個值
//--每獲取一次鎖,執行 1次 賦值和 pop_front 操作
//--耗時非常短
i = the_list.front();
the_list.pop_front();
而在實際軟件開發中,除非程序員對自己的程序的鎖操作行為非常的了解,否則使用spin lock不是一個好主意。
通常一個多線程程序中對鎖的操作有數以萬次,如果失敗的鎖操作(contended lock requests)過多的話就會浪費很多的時間進行空等待。
消耗時間的地方:
兩個線程分別運行在兩個核上,大部分時間只有一個線程能拿到鎖,所以另一個線程就一直在它運行的core上進行忙等待,CPU占用率一直是100%
而在實際軟件開發中,除非程序員對自己的程序的鎖操作行為非常的了解,否則使用spin lock不是一個好主意。
通常一個多線程程序中對鎖的操作有數以萬次,如果失敗的鎖操作(contended lock requests)過多的話就會浪費很多的時間進行空等待。
消耗時間的地方:
兩個線程分別運行在兩個核上,大部分時間只有一個線程能拿到鎖,所以另一個線程就一直在它運行的core上進行忙等待,CPU占用率一直是100%
而在實際軟件開發中,除非程序員對自己的程序的鎖操作行為非常的了解,否則使用spin lock不是一個好主意。
通常一個多線程程序中對鎖的操作有數以萬次,如果失敗的鎖操作(contended lock requests)過多的話就會浪費很多的時間進行空等待。
消耗時間的地方:
兩個線程分別運行在兩個核上,大部分時間只有一個線程能拿到鎖,所以另一個線程就一直在它運行的core上進行忙等待,CPU占用率一直是100%
測試代碼(臨界區運行時間很短):
1 編譯spin lock版本 : g++ -o spin_version -DUSE_SPINLOCK spinlockvsmutex1.cc -lpthread
2 編譯mutex 版本 : g++ -o mutex_version spinlockvsmutex1.cc -lpthread
// Name: spinlockvsmutex1.cc
// Source: http://www.alexonlinux.com/pthread-mutex-vs-pthread-spinlock
// Compiler(spin lock version): g++ -o spin_version -DUSE_SPINLOCK spinlockvsmutex1.cc -lpthread
// Compiler(mutex version): g++ -o mutex_version spinlockvsmutex1.cc -lpthread
#include <stdio.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <errno.h>
#include <sys/time.h>
#include <list>
#include <pthread.h>
#define LOOPS 50000000
using namespace std;
list<int> the_list;
//-- spinlock 或者 mutex
#ifdef USE_SPINLOCK
pthread_spinlock_t spinlock;
#else
pthread_mutex_t mutex;
#endif
//Get the thread id
pid_t gettid() { return syscall( __NR_gettid ); }
void *consumer(void *ptr)
{
int i;
//--打印線程ID
printf("Consumer Thread ID %lu\n", (unsigned long)gettid());
while (1)
{
#ifdef USE_SPINLOCK
pthread_spin_lock(&spinlock);
#else
pthread_mutex_lock(&mutex);
#endif
//--列表為空,結束
if (the_list.empty())
{
#ifdef USE_SPINLOCK
pthread_spin_unlock(&spinlock);
#else
pthread_mutex_unlock(&mutex);
#endif
break;
}
//---取出列表第一個值
//--每獲取一次鎖,執行 1次 賦值和 pop_front 操作
//--耗時非常短
i = the_list.front();
the_list.pop_front();
#ifdef USE_SPINLOCK
pthread_spin_unlock(&spinlock);
#else
pthread_mutex_unlock(&mutex);
#endif
}
return NULL;
}
int main()
{
int i;
pthread_t thr1, thr2;
struct timeval tv1, tv2;
#ifdef USE_SPINLOCK
pthread_spin_init(&spinlock, 0);
#else
pthread_mutex_init(&mutex, NULL);
#endif
// Creating the list content...
//--生產者,創建列表內容
for (i = 0; i < LOOPS; i++)
the_list.push_back(i);
// Measuring time before starting the threads...
//--啟動線程前時間
gettimeofday(&tv1, NULL);
//--創建兩個消費者線程
pthread_create(&thr1, NULL, consumer, NULL);
pthread_create(&thr2, NULL, consumer, NULL);
//--主線程等待兩個消費者線程結束
pthread_join(thr1, NULL);
pthread_join(thr2, NULL);
// Measuring time after threads finished...
//--線程結束時間
gettimeofday(&tv2, NULL);
if (tv1.tv_usec > tv2.tv_usec)
{
tv2.tv_sec--;
tv2.tv_usec += 1000000;
}
//--打印耗時
printf("Result - %ld.%ld\n", tv2.tv_sec - tv1.tv_sec,
tv2.tv_usec - tv1.tv_usec);
#ifdef USE_SPINLOCK
pthread_spin_destroy(&spinlock);
#else
pthread_mutex_destroy(&mutex);
#endif
return 0;
}
運行
wmx@wmx-ubuntu:~/workspace/Multi-core scheduling/spinlockvsmutex1$ time ./mutex_version
Consumer TID 17599
Consumer TID 17600
Result - 23.863041
real 0m26.455s
user 0m30.596s
sys 0m19.712s
wmx@wmx-ubuntu:~/workspace/Multi-core scheduling/spinlockvsmutex1$ time ./spin_version
Consumer TID 17606
Consumer TID 17607
Result - 3.743531
real 0m6.293s
user 0m9.719s
sys 0m0.317s
可以看見spin lock的版本在該程序中表現出來的性能更好。另外值得注意的是sys時間,mutex版本花費了更多的系統調用時間,這就是因為mutex會在鎖沖突時調用system wait造成的。
測試代碼(鎖沖突程度非常劇烈的實例程序):
//Name: svm2.c
//Source: http://www.solarisinternals.com/wiki/index.php/DTrace_Topics_Locks
//Compile(spin lock version): gcc -o spin -DUSE_SPINLOCK svm2.c -lpthread
//Compile(mutex version): gcc -o mutex svm2.c -lpthread
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <sys/syscall.h>
//--線程數量
#define THREAD_NUM 2
pthread_t g_thread[THREAD_NUM];
//-- spinlock 或者 mutex
#ifdef USE_SPINLOCK
pthread_spinlock_t g_spin;
#else
pthread_mutex_t g_mutex;
#endif
__uint64_t g_count;
pid_t gettid()
{
return syscall(SYS_gettid);
}
void *run_amuck(void *arg)
{
int i, j;
//--打印線程ID
printf("Thread %lu started.\n", (unsigned long)gettid());
//--10000次請求鎖
for (i = 0; i < 10000; i++) {
#ifdef USE_SPINLOCK
pthread_spin_lock(&g_spin);
#else
pthread_mutex_lock(&g_mutex);
#endif
//--每獲取一次鎖,執行 100000次 累加 操作
//--耗時比較長
for (j = 0; j < 100000; j++) {
//--打印優先完成的線程ID
if (g_count++ == 123456789){
printf("Thread %lu wins!\n", (unsigned long)gettid());
}
}
#ifdef USE_SPINLOCK
pthread_spin_unlock(&g_spin);
#else
pthread_mutex_unlock(&g_mutex);
#endif
}
//--打印線程ID
printf("Thread %lu finished!\n", (unsigned long)gettid());
return (NULL);
}
int main(int argc, char *argv[])
{
int i, threads = THREAD_NUM;
//--打印線程數量
printf("Creating %d threads...\n", threads);
//-- spinlock 或者 mutex
#ifdef USE_SPINLOCK
pthread_spin_init(&g_spin, 0);
#else
pthread_mutex_init(&g_mutex, NULL);
#endif
for (i = 0; i < threads; i++)
pthread_create(&g_thread[i], NULL, run_amuck, (void *) i);
/*!
* @brief pthread_join
* 主線程會一直等待直到等待的線程結束自己才結束
* 對線程的資源進行回收
*/
for (i = 0; i < threads; i++)
pthread_join(g_thread[i], NULL);
printf("Done.\n");
return (0);
}
測試
wmx@wmx-ubuntu:~/workspace/Multi-core scheduling/spinlockvsmutex2$ time ./mutex
Creating 2 threads...
Thread 18389 started.
Thread 18390 started.
Thread 18389 wins!
Thread 18389 finished!
Thread 18390 finished!
Done.
real 0m3.150s
user 0m3.202s
sys 0m0.020s
wmx@wmx-ubuntu:~/workspace/Multi-core scheduling/spinlockvsmutex2$ time ./spin
Creating 2 threads...
Thread 18403 started.
Thread 18404 started.
Thread 18403 wins!
Thread 18403 finished!
Thread 18404 finished!
Done.
real 0m3.107s
user 0m4.641s
sys 0m0.004s
這個程序的特征就是臨界區非常大,這樣兩個線程的鎖競爭會非常的劇烈。當然這個是一個極端情況,實際應用程序中臨界區不會如此大,鎖競爭也不會如此激烈。測試結果顯示mutex版本性能更好
spin lock耗費了更多的user time。這就是因為兩個線程分別運行在兩個核上,大部分時間只有一個線程能拿到鎖,所以另一個線程就一直在它運行的core上進行忙等待,CPU占用率一直是100%
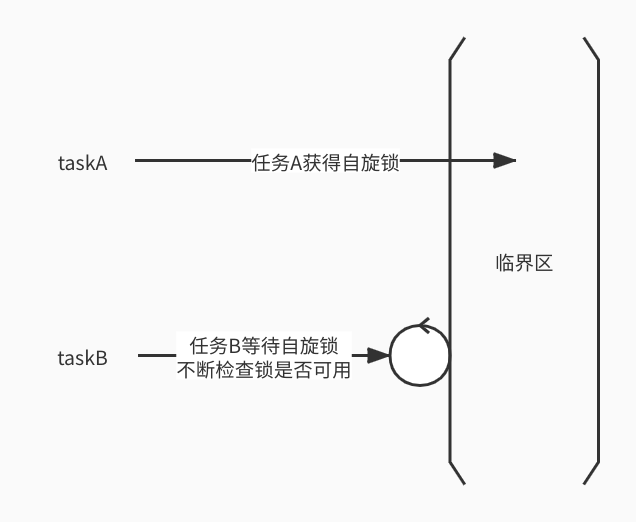
自旋鎖是一種非阻塞鎖,也就是說,如果某線程需要獲取自旋鎖,但該鎖已經被其他線程占用時,該線程不會被掛起,而是在不斷的消耗CPU的時間,不停的試圖獲取自旋鎖。
互斥量是阻塞鎖,當某線程無法獲取互斥量時,該線程會被直接掛起,該線程不再消耗CPU時間,當其他線程釋放互斥量后,操作系統會**那個被掛起的線程,讓其投入運行。
兩種鎖適用于不同場景:
如果是多核處理器,如果預計線程等待鎖的時間很短,短到比線程兩次上下文切換時間要少的情況下,使用自旋鎖是劃算的。
如果是多核處理器,如果預計線程等待鎖的時間較長,至少比兩次線程上下文切換的時間要長,建議使用互斥量。
如果是單核處理器,一般建議不要使用自旋鎖。因為,在同一時間只有一個線程是處在運行狀態,那如果運行線程發現無法獲取鎖,只能等待解鎖,但因為自身不掛起,所以那個獲取到鎖的線程沒有辦法進入運行狀態,只能等到運行線程把操作系統分給它的時間片用完,才能有機會被調度。這種情況下使用自旋鎖的代價很高。
如果加鎖的代碼經常被調用,但競爭情況很少發生時,應該優先考慮使用自旋鎖,自旋鎖的開銷比較小,互斥量的開銷較大。
參考文獻
《多核程序設計技術》
《linux內核設計與實現》
自旋鎖是一個互斥設備,它只有兩個值:“鎖定”和“解鎖”。它通常實現為某個整數值中的某個位。希望獲得某個特定鎖得代碼測試相關的位。如果鎖可用,則“鎖定”被設置,而代碼繼續進入臨界區;相反,如果鎖被其他人獲得,則代碼進入忙循環(而不是休眠,這也是自旋鎖和一般鎖的區別)并重復檢查這個鎖,直到該鎖可用為止,這就是自旋的過程。“測試并設置位”的操作必須是原子的,這樣,即使多個線程在給定時間自旋,也只有一個線程可獲得該鎖。
自旋鎖最初是為了在多處理器系統(SMP)使用而設計的,但是只要考慮到并發問題,單處理器在運行可搶占內核時其行為就類似于SMP。因此,自旋鎖對于SMP和單處理器可搶占內核都適用。可以想象,當一個處理器處于自旋狀態時,它做不了任何有用的工作,因此自旋鎖對于單處理器不可搶占內核沒有意義,實際上,非搶占式的單處理器系統上自旋鎖被實現為空操作,不做任何事情。
自旋鎖有幾個重要的特性:1、被自旋鎖保護的臨界區代碼執行時不能進入休眠。2、被自旋鎖保護的臨界區代碼執行時是不能被被其他中斷中斷。3、被自旋鎖保護的臨界區代碼執行時,內核不能被搶占。從這幾個特性可以歸納出一個共性:被自旋鎖保護的臨界區代碼執行時,它不能因為任何原因放棄處理器。
考慮上面第一種情況,想象你的內核代碼請求到一個自旋鎖并且在它的臨界區里做它的事情,在中間某處,你的代碼失去了處理器。或許它已調用了一個函數(copy_from_user,假設)使進程進入睡眠。也或許,內核搶占發威,一個更高優先級的進程將你的代碼推到了一邊。此時,正好某個別的線程想獲取同一個鎖,如果這個線程運行在和你的內核代碼不同的處理器上(幸運的情況),那么它可能要自旋等待一段時間(可能很長),當你的代碼從休眠中喚醒或者重新得到處理器并釋放鎖,它就能得到鎖。而最壞的情況是,那個想獲取鎖得線程剛好和你的代碼運行在同一個處理器上,這時它將一直持有CPU進行自旋操作,而你的代碼是永遠不可能有任何機會來獲得CPU釋放這個鎖了,這就是悲催的死鎖。
考慮上面第二種情況,和上面第一種情況類似。假設我們的驅動程序正在運行,并且已經獲取了一個自旋鎖,這個鎖控制著對設備的訪問。在擁有這個鎖得時候,設備產生了一個中斷,它導致中斷處理例程被調用,而中斷處理例程在訪問設備之前,也要獲得這個鎖。當中斷處理例程和我們的驅動程序代碼在同一個處理器上運行時,由于中斷處理例程持有CPU不斷自旋,我們的代碼將得不到機會釋放鎖,這也將導致死鎖。
因此,如果我們有一個自旋鎖,它可以被運行在(硬件或軟件)中斷上下文中的代碼獲得,則必須使用某個禁用中斷的spin_lock形式的鎖來禁用本地中斷(注意,只是禁用本地CPU的中斷,不能禁用別的處理器的中斷),使用其他的鎖定函數遲早會導致系統死鎖(導致死鎖的時間可能不定,但是發生上述死鎖情況的概率肯定是有的,看處理器怎么調度了)。如果我們不會在硬中斷處理例程中訪問自旋鎖,但可能在軟中斷(例如,以tasklet的形式運行的代碼)中訪問,則應該使用spin_lock_bh,以便在安全避免死鎖的同時還能服務硬件中斷。
補充:
鎖定一個自旋鎖的函數有四個:
void spin_lock(spinlock_t *lock);
最基本得自旋鎖函數,它不失效本地中斷。
void spin_lock_irqsave(spinlock_t *lock, unsigned long flags);
在獲得自旋鎖之前禁用硬中斷(只在本地處理器上),而先前的中斷狀態保存在flags中
void spin_lockirq(spinlock_t *lock);
在獲得自旋鎖之前禁用硬中斷(只在本地處理器上),不保存中斷狀態
void spin_lock_bh(spinlock_t *lock);
在獲得鎖前禁用軟中斷,保持硬中斷打開狀態
————————————————
版權聲明:本文為CSDN博主「vivi」的原創文章,遵循CC 4.0 BY-SA版權協議,轉載請附上原文出處鏈接及本聲明。
原文鏈接:https://blog.csdn.net/vividonly/article/details/6594195
————————————————
版權聲明:本文為CSDN博主「swordmanwk」的原創文章,遵循CC 4.0 BY-SA版權協議,轉載請附上原文出處鏈接及本聲明。
原文鏈接:https://blog.csdn.net/swordmanwk/article/details/6819457
————————————————
版權聲明:本文為CSDN博主「科技ing」的原創文章,遵循CC 4.0 BY-SA版權協議,轉載請附上原文出處鏈接及本聲明。
原文鏈接:https://blog.csdn.net/WMX843230304WMX/article/details/100052812
智能推薦

C++11并發與多線程筆記(12) windows臨界區、其他各種mutex互斥量
第十二節 windows臨界區、其他各種mutex互斥量 一和二、windows臨界區 Windows臨界區,同一個線程是可以重復進入的,但是進入的次數與離開的次數必須相等。 C++互斥量則不允許同一個線程重復加鎖。 windows臨界區是在windows編程中的內容,了解一下即可,效果幾乎可以等同于c++11的mutex 包含#include <windows.h> windows中...
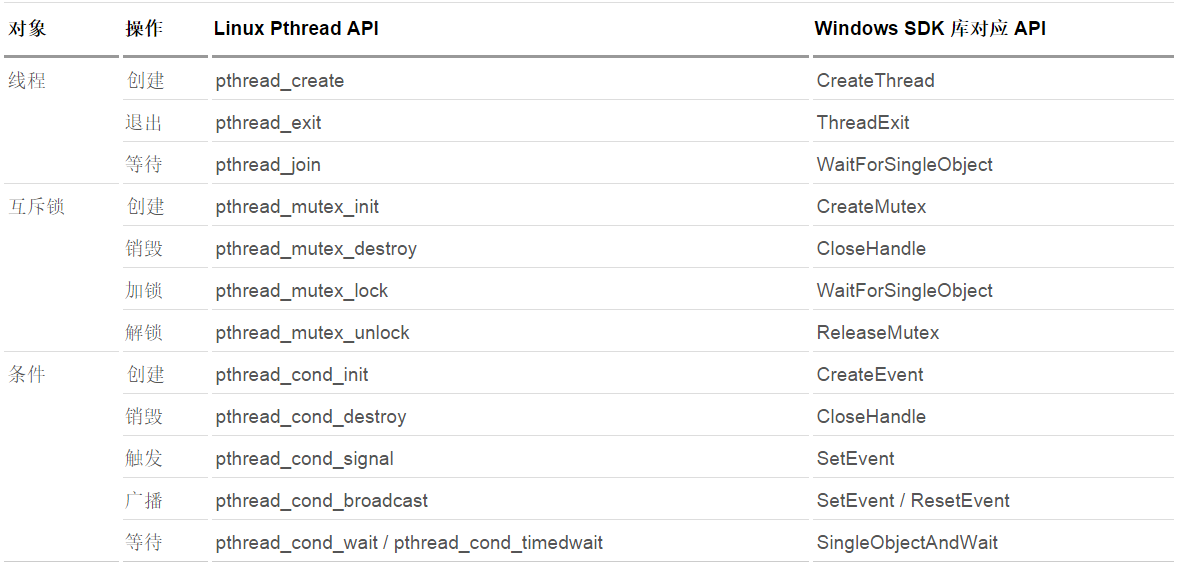
Linux線程-Mutex互斥鎖和信號量互斥鎖的筆記
多線程開發在 Linux 平臺上已經有成熟的 pthread 庫支持。其涉及的多線程開發的最基本概念主要包含三點:線程,互斥鎖,條件。其中,線程操作又分線程的創建,退出,等待 3 種。互斥鎖則包括 4 種操作,分別是創建,銷毀,加鎖和解鎖。條件操作有 5 種操作:創建,銷毀,觸發,廣播和等待。其他的一些線程擴展概念,如信號燈等,都可以通過上面的三個基本元素的基本操作封裝出來。詳細請見下表: 線程創...
Linux線程間同步③:自旋鎖Spinlock
對于Mutex互斥鎖,其同一時間只能被一個線程所占有,其它申請該鎖的線程會進入阻塞休眠態,讓出CPU時間片。 其一般使用在臨界區邏輯較長的程序中,使得多線程互斥的訪問臨界資源。而Linux中引入自旋鎖主要是解決多處理器 對內核數據結構的互斥訪問。確保其訪問的原子性,基本流程為:鎖定=》操作=》解鎖 自旋鎖其功能和互斥鎖類似,目的是保護一小段臨界區的原子性,其本質為一個原子變量atomic,主要包含...

多線程控制互斥鎖與信號量
1.多線程編臨界資源訪問 為了解決上述對臨界資源的競爭問題,pthread線程引出了互斥鎖來解決臨界資源訪問。通過對臨界資源加鎖來保護資源只被單個線程操作,待操作結束后解鎖,其余線程才可獲得操作權。 2.互斥鎖API簡述 函數作用為初始化一個互斥鎖,一般情況申請一個全局的pthread_mutex_t類型的互斥鎖變量,通過此函數完成鎖內的初始化,第一個函數將該變量的地址傳入,第二個參數為控制互斥鎖...
多線程與互斥鎖
轉載自博主:https://blog.csdn.net/qq_27312943/article/details/79084781 有的linux版本沒有包含以下函數的man手冊,需要手動下載!Ubuntu下載方法:apt-get install manpages-posix-dev 互斥鎖 主要作用是關鍵段代碼保護, &nb...
猜你喜歡

自旋鎖與互斥鎖
互斥鎖(mutex) 當一個線程試圖鎖定一個互斥鎖而沒有成功時,由于該互斥鎖已經被鎖定,它將進入睡眠狀態,并立即允許另一個線程運行,它將會立即睡眠直到被喚醒,當它睡眠前的上鎖的線程解鎖時,多個沉睡的線程會競爭鎖,得到鎖的話會被喚醒. 自旋鎖(spin-lock) 當一個線程使用自旋鎖鎖定沒有成功的時候,它將不斷的嘗試鎖定,直到鎖定成功;因此,自旋鎖不允許其他線程代替它,但是,一旦當前線程的被分配的...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...