『Yolo_v3』項目詳細分析
標簽: 深度學習
一.前言
最近在學習yolo_v3項目,該項目是深度學習發展到現階段最受歡迎的大項目之一,是多目標識別跟蹤框架集大成者。
yolo_v3是yolo系列之一神經網絡,同時也是發展到的最優美的網絡。當然,隨著系列發展,yolo_v3也保留和yolo_v1和yolo_v2神經網絡的部分優點,同時,也拋棄了yolo_v1和yolo_v2中大多數缺點。下面就yolo_v3進行理論和代碼信息分析。同學完全可以通過這篇文章,完全學會使用yolo_v3,并結合做出自己好玩的東西。話不過說,開始你的路程吧。
先寫上yolo_v3設計上的一些思想,先不必看懂:
- “分而治之”:yolo系列算法是通過對原始輸入圖片通過劃分單元格來做檢測。不同之處在于劃分的格子數量不同而已。
- **函數:yolo_v3采用Leaky ReLU函數作為**函數。
- 普通卷積層:yolo_v2和yolo_v3使用 Batch Normalization 作為正則化、加速收斂、避免過擬合的方法。在每一層卷積層后接上 BN層和Leaky Relu層 。
class ConvolutionalLayer(torch.nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, bias=False):
super(ConvolutionalLayer, self).__init__()
self.sub_module = torch.nn.Sequential(
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=bias),
torch.nn.BatchNorm2d(out_channels),#BN
torch.nn.LeakyReLU(0.1)#leaky relu
)
- 度尺度訓練: 在速度和準確率之間tradeoff。想速度快點,可以犧牲準確率;想準確率高點兒,可以犧牲一點速度 。
- 分類函數: 對象分類用Logistic取代了softmax。
二.yolo系列簡要分析
yolo適合作為工程算法。從yolo_v1到yolo_v3,不難發現yolo每一代神經網絡性能達大幅提升很大一部分功勞在于基礎網絡的提升。yolo_v2使用Darkent-19基礎網絡,yolo_v3使用 darknet-53 基礎網絡(網絡性能高)。yolo_v3還可以使用 tiny-darknet (輕量加速)替換darknet-53。( 在官方代碼里用一行代碼就可以實現切換 )
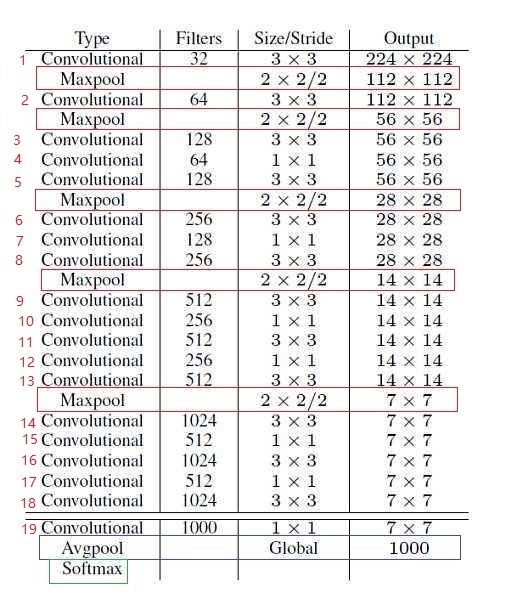
1.yolo_v1
- 輸入圖像大小224x224,分7x7個格子,每個格子代表原來的32x32大小。
- 5個下采樣。(2的5次方)
- 缺點:輸入圖片較小。
- 輸出層用全連接層。
- 只有2種建議框:橫向長方形,豎向長方形。
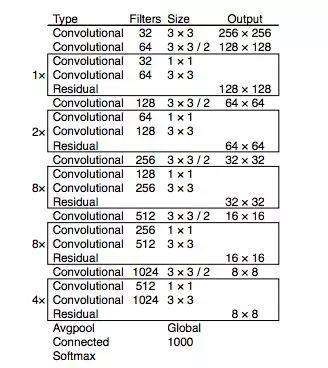
2.yolo_v2
- 輸出層用全卷積結構。從原理上,輸入可以任意大小。
- 兩種尺寸:448和224。
- 448:每個格子64x64大小。組合卷積的步長也為64。
- 224:每個格子代表原來的32x32大小。
- Darkent-19:19個帶權重的層。
- 對于前向過程中張量尺寸變換,是通過最大池化來進行,一共有5次下采樣。
- 設計技巧:3x3–>1x1–>3x3。尺寸大小不變,固可進行更改:1)可使用殘差層替換;2)可更改為:1x1–>3x3–>1x1(計算量小) 。
- darknet-19最后面沒有全局平均池化。
- darknet-19是不存在殘差結構的,和VGG是同類型的backbone(屬于上一代CNN結構) 。
3.yolo_v3
- 上采樣:過程使用特征金字塔。(尺寸受到限制,限制不嚴重)
- 3種尺寸:608、416、320。(實際中反推合理數據都可以。是32的倍數)
- 9種建議框。并使用K-mean做聚類。
- Darkent-53:53個帶權重的層(基礎網絡)。
- 首先,使用基礎網絡在其他數據集上進行分類(最后一層使用softmax做分類),然后將權重保存;最后再用于Yolov3上。【遷移學習:訓練速度調小。盡量使用SGD等反應比較溫和的訓練器。因為,訓練速度調大,會破壞掉原來的知識體系。訓練技巧:先凍結前邊的知識體系,等后邊的知識體系學好了,再將前邊的放開,一起去學習。】
- 將輸入圖像分化為SxS的 網格,一個格子是一個向量,每個向量代表原來的一塊。
- 步長=核尺寸。使用組合卷積。
- 對于前向過程中張量尺寸變換,是通過卷積核增大步長來進行,一共有5次 。
- darknet-53最后面有一個全局平均池化 。因為最后的特征信息都是有用的。如果使用最大池化會將部分有用信息過濾掉。 在一些層之間設置了快捷鏈路(shortcut connections)。
- 使用卷積進行下采樣,增加網絡容量。因為卷積層帶有參數,最大池化不帶參數。
- 跳躍連接。
三.yolo_v3理論分析
1.幾個關鍵結構
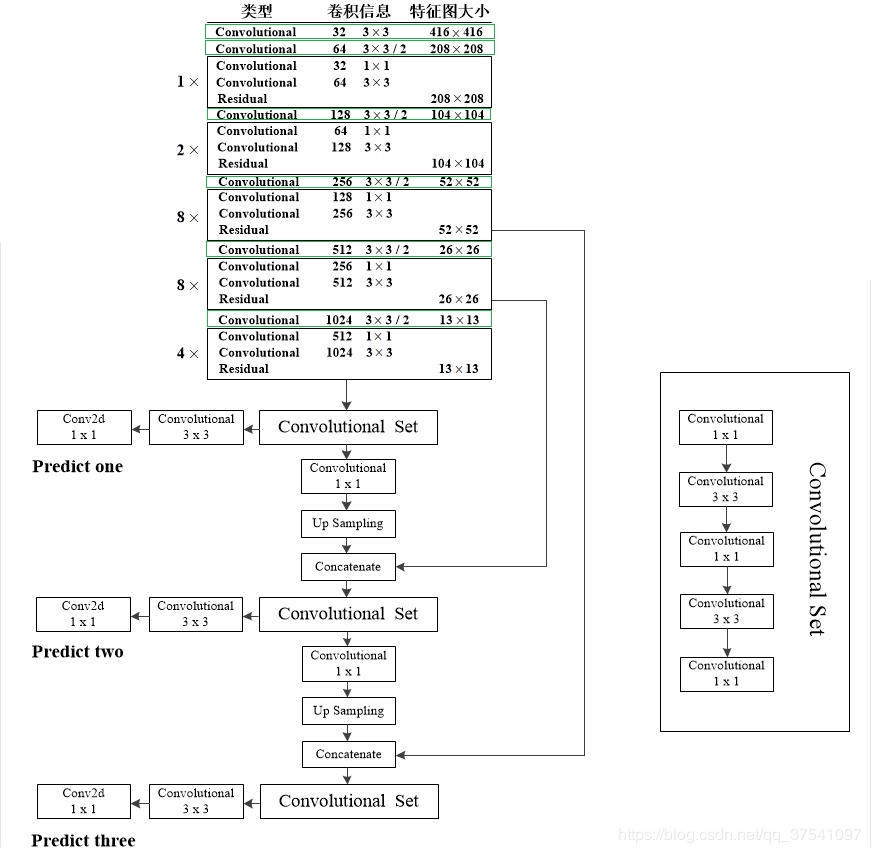
(1)DBL
全稱: Darknetconv2d_BN_Leaky ( 卷積+BN+Leaky relu ),是 yolo_v3的基本組件 。如圖yolo_v3網絡結構(1)中綠色框中的內容。代碼處使用面向對象思想單獨寫出來。代碼如下:
"""普通卷積層(DBL)"""
class ConvolutionalLayer(torch.nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, bias=False):
super(ConvolutionalLayer, self).__init__()
self.sub_module = torch.nn.Sequential(
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=bias),#Darknetconv2d
torch.nn.BatchNorm2d(out_channels),#BN
torch.nn.LeakyReLU(0.1)#Leaky
)
def forward(self, x):
return self.sub_module(x)
(2)resn
res代表殘差結構,n代表數字。res1,res2, … ,res8等, 表示多少個重復的殘差組件。(可以此更改網絡結構。相關論文: 基于改進損失函數的YOLOv3網絡 ),是 yolo_v3的大組件 。借鑒了ResNet的殘差結構 。這樣做的好處是:使用殘差網絡結構,讓網絡結構更深,這也就是從yolo_v2中的 darknet-19提升到yolo_v3的darknet-53的原理。結構:DBL降低通道+DBL還原通道。 每個殘差組件有兩個卷積層和一個快捷鏈路,示意圖如下:

代碼如下:
"""普通卷積層(DBL)"""
class ConvolutionalLayer(torch.nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, bias=False):
super(ConvolutionalLayer, self).__init__()
self.sub_module = torch.nn.Sequential(
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=bias),
torch.nn.BatchNorm2d(out_channels),
torch.nn.LeakyReLU(0.1)
)
def forward(self, x):
return self.sub_module(x)
"""殘差層"""#(輸入大小=輸入大小)
class ResidualLayer(torch.nn.Module):
def __init__(self, in_channels):
super(ResidualLayer, self).__init__()
self.sub_module = torch.nn.Sequential(
ConvolutionalLayer(in_channels, in_channels // 2, 1, 1, 0),#DBL降低通道。調用普通卷積層。
ConvolutionalLayer(in_channels // 2, in_channels, 3, 1, 1),#DBL還原通道。
)
def forward(self, x):
return x + self.sub_module(x)#H(x)=x+F(x)
(3)concat
張量拼接。 將基礎網絡中間層和后面的某一層的上采樣進行拼接。拼接的操作和殘差層add的操作是不一樣的,拼接會擴充張量的維度,而add只是直接相加不會導致張量維度的改變。
concat和相加的對比分析:
相加可以提高對特征的增強,但分類效果不高。因為人臉識別,最終是人臉人類,最終一層特征至少保存128個維度,當類別少,會分的不清。增加效果的提升是在分類維度上進行增加的。相加時,特征維度不增加;拼接會增加特征維度,增加分類能力。
拼接好的另一個原因:基礎網絡中注重局部信息(如26x26大小。局部信息好,感受野小。維度大512。);當下采樣后再上采樣的特征圖(如26x26大小。特征融合更好,全局性更好,特征更全面,感受野大。維度小256。26x26預測更小的物體,局部重要,所以,局部數據維度大,全局維度信息少,更加注重基礎網絡中得到的局部信息)與基礎網絡中的特征圖進行拼接時。52x52道理同上。預測更更小的物體,局部重要,所以,局部數據維度大,全局維度信息少,更加注重基礎網絡中得到的局部信息。
(4)總結
yolo_v3共包含252層結構。
2.幾個關鍵內容
(1)基礎網絡
- yolo_v3的改進:在基礎網絡結構中張良尺寸的變化技巧取消使用池化層和全連接層,取而代之的是卷積層。通過改變卷積核步長實現的,如:s=2時,等于將圖像邊長縮小為原來的1/2,面積縮小為原來的1/4。
- 神器的數字5:在yolo_v2和yolo_v3的基礎網絡結構中,原始圖片經歷5次縮小,最終特征圖變為原來的,即1/32。當輸入圖片大小為416x416時,輸出圖片大小為13x13。
- 輸入圖片要求: 通常要求輸入圖片是32的倍數。
(2)網絡的輸出
如下圖所示,yolo_v3 輸出了3個不同尺度的特征圖。這是 yolo_v3 的**一大改進。**該思想借鑒與FPM( feature pyramid networks )。是的yolo_v3 可以對多尺度目標進行檢測。3種不同尺寸特征圖邊長規律為13:26:52。
這三種不同尺寸的深度為255。解釋如下:
-
論文中,作者使用COCO數據集進行分類,該數據集有80種物體類別。
-
每個網格單元預測3個實際框,每個實際框需要五個參數和80個類別概率才能作為分類使用:中心點坐標兩個值、框的寬和高兩個值、置信度一個值(x,y,w,h, confidence )。
-
綜上:255=3x(5+80)=255。
-
當然,數據集不同,類別也不用,深度也不同。
-
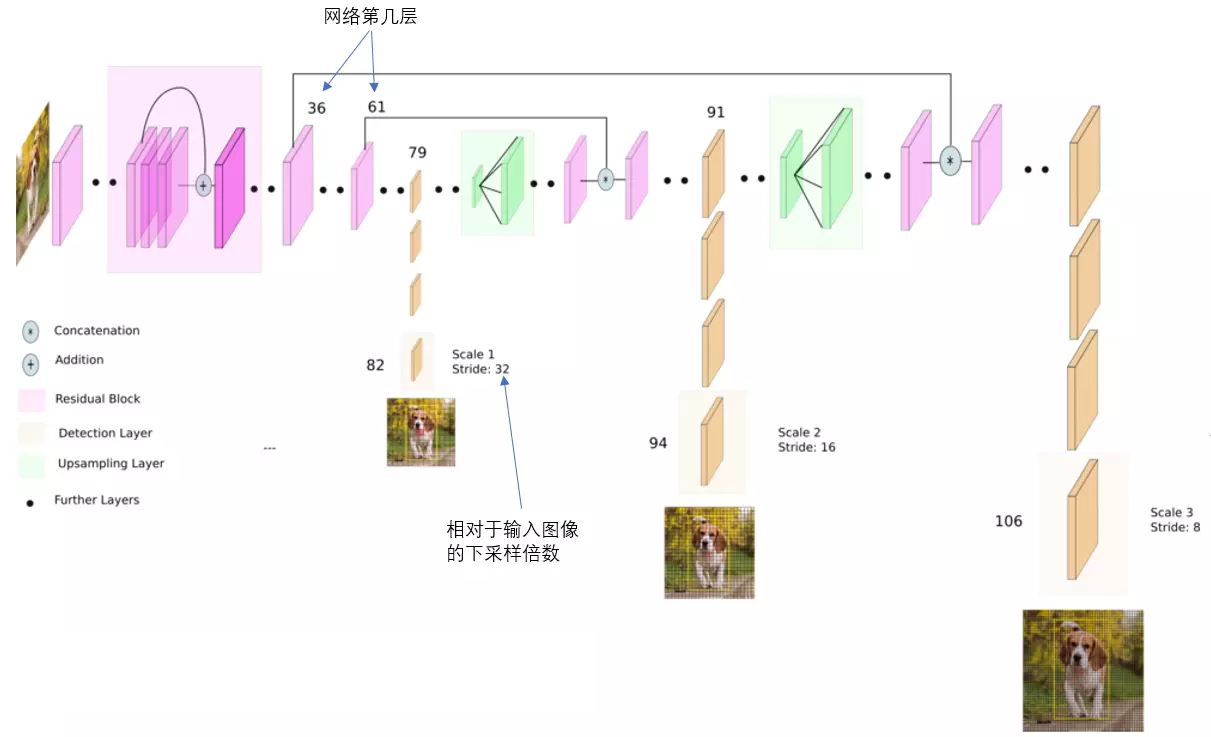
13x3特征圖偵測
如下圖中,卷積網絡在第79層處,經過向下幾次卷積得到一種尺度特征圖用于偵測。在yolo_v3 中,輸入圖片大小416x416,下采樣32倍,得到13x13大小的特征圖。因為下采樣倍數高,得到的特征圖感受野較大,適合偵測圖片中尺寸較大的物體。
- 26x26特征圖偵測
如下圖中,卷積網絡在第79層處向右開始作上采樣,然后與第61層特征圖融合(Concatenation),在第91層向下幾次卷積得到另一種尺度特征圖用于偵測。在yolo_v3 中,輸入圖片大小416x416,下采樣16倍,得到26x26大小的特征圖。得到的特征圖感受野中等,適合偵測圖片中尺寸中等的物體。
- 52x52特征圖偵測
在第91層特征圖再次上采樣,并與第36層特征圖融合(Concatenation),最后得到相對輸入圖像8倍下采樣的特征圖。得到的特征圖感受野中最小,適合偵測圖片中尺寸小的物體。
(3)9種尺度建議框
YOLO3 中延續 YOLO2中采用 K-means聚類得到建議框的尺寸 。每種下采樣尺度設定3種建議框,3種偵測結果,共聚類出來9種建議框。 在COCO數據集這9個先驗框是:
10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
分配如下:
- 13x13大小特征圖
具有最大的感受視野,使用較大的建議框: (116x90),(156x198),(373x326) 。 適合檢測較大的物體 。
- 26x26大小特征圖
具有中等的感受視野,使用中等的建議框: (30x61),(62x45),(59x119) 。 適合檢測中等大小的物體 。
- 52x52大小特征圖
具有最大的感受視野,使用較小的建議框: (10x13),(16x30),(33x23) 。 適合檢測較小的物體 。
下面在視覺上感受9種建議框的尺寸:
- 藍色框為聚類得到的建議框;
- 黃色框為實際框;
- 紅色框為對象中心點所在的網格。

(4)網絡偵測技術
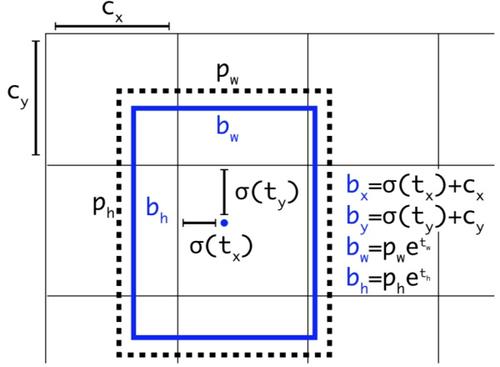
預測相對位置 。 預測出b-box中心點相對于網格單元左上角的相對坐標。
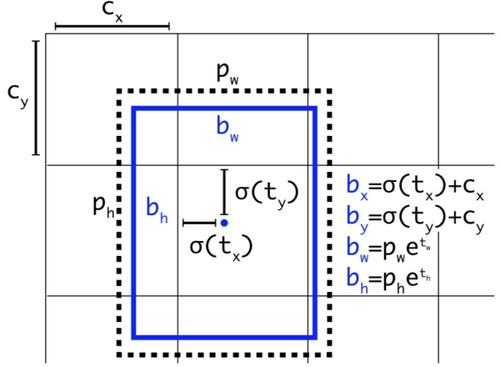

-
預測五個參數(,,,,)。從上述公式可以看出,b-box的位置大小和置信度可以通過(,,,,)計算得來。其中,b-box的寬和高的預測受到 prior影響(即,建議框框的種類。yolo_v3中有9中建議框) 。
-
對 b-box進行預測時,輸出 (,,,,),然后通過上述公式計算出絕對的 (x, y, w, h, c) 。
-
使用 logistic回歸對邊界框包圍的部分進行目標性評分, 即這塊位置是目標的可能性有多大。 這一步是在predict之前進行的,可以去掉不必要anchor,可以減少計算量。
-
對那個最佳預測進行操作。
(5)分類函數
在物體預測時,yolo_v3使用 logistic 代替 softmax 函數。 logistic支持多標簽對象,如:男人和人的預測。
(6)損失函數
yolo_v3的重要改進。在目標檢測中有幾個關鍵信息需要確定:。根據關鍵信息的特點可以分為四類(中心點坐標、寬和高、分類、置信度),損失函數也用該由各自的特點確定。最后將四類相加得到最終的損失函數。這也就是一個神經網絡項目中損失函數最為重要,確定了損失函數,基本整個項目就確定了。
除了(w, h)的損失函數依然采用總方誤差之外,其他部分的損失函數用的是二值交叉熵 。
(7)輸入->輸出

yolo_v3將輸入圖像映射到3個尺度的輸出張量。對于一個416x416的圖像,每個尺度的特征圖的每個網格設置了3個建議框,總共得到10647的預測=13x13x3+26x26x3+52x52x3。每個預測是一個85維向量=(2+2+1+80)。其中,兩個2分別代表中心點坐標值2個和框的置信度1個,物體概率類別概率(COCO數據集80個種類)。
三種尺寸輸出特征圖結構:NCHW。其中,C=(1+4+S)x3。公式中,1代表一個置信度,4代表中心點坐標兩個值,寬和高兩個值,S代表分類的類別數量,3代表三種建議框。
(8)總結
-
yolo_v3借鑒了殘差網絡結構,形成更深的網絡層次;
-
使用多尺度檢測,提升了mAP及小物體檢測效果。
(9)幾點建議
在實際項目中,當數據集和Yolov3的數據集不相同時,建議框的選擇有兩種方法:(1)人為畫出建議框(對特定模型很好。但是人為具有局限性,通用性差);(2)通過K-mean聚類算法聚類得到合適建議框(推薦。可能特定目標效果不好,但是整體效果很好)。
四.yolo_v3代碼分析
1.網絡結構
寫網絡結構:清晰、便于修改
- 拆分成塊;
- 寫塊代碼塊;
- 主框架(組裝塊)。
代碼:
import torch
"""上采樣層"""
class UpsampleLayer(torch.nn.Module):
def __init__(self):
super(UpsampleLayer, self).__init__()
def forward(self, x):
return torch.nn.functional.interpolate(x, scale_factor=2, mode='nearest')#臨近采樣,快一些,插值為原來的2倍。插值方法很多:像素混合,反卷積等
"""普通卷積層"""
class ConvolutionalLayer(torch.nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, bias=False):
super(ConvolutionalLayer, self).__init__()
self.sub_module = torch.nn.Sequential(
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=bias),
torch.nn.BatchNorm2d(out_channels),
torch.nn.LeakyReLU(0.1)#Prelu的參數需要學習
)
def forward(self, x):
return self.sub_module(x)
"""殘差層"""#(輸入大小=輸入大小)
class ResidualLayer(torch.nn.Module):
def __init__(self, in_channels):
super(ResidualLayer, self).__init__()
self.sub_module = torch.nn.Sequential(
ConvolutionalLayer(in_channels, in_channels // 2, 1, 1, 0),#調用普通卷積層。
ConvolutionalLayer(in_channels // 2, in_channels, 3, 1, 1),#輸出通道大小=輸出通道大小
)
def forward(self, x):
return x + self.sub_module(x)#H(x)=x+F(x)
"""下采樣層"""
class DownsamplingLayer(torch.nn.Module):
def __init__(self, in_channels, out_channels):
super(DownsamplingLayer, self).__init__()
self.sub_module = torch.nn.Sequential(
ConvolutionalLayer(in_channels, out_channels, 3, 2, 1)
)
def forward(self, x):
return self.sub_module(x)
"""專用卷積集"""
class ConvolutionalSet(torch.nn.Module):
def __init__(self, in_channels, out_channels):#輸入和輸出單獨列出來
super(ConvolutionalSet, self).__init__()
self.sub_module = torch.nn.Sequential(
ConvolutionalLayer(in_channels, out_channels, 1, 1, 0),#1x1的卷積
ConvolutionalLayer(out_channels, in_channels, 3, 1, 1),#3x3的卷積
ConvolutionalLayer(in_channels, out_channels, 1, 1, 0),#1x1的卷積
ConvolutionalLayer(out_channels, in_channels, 3, 1, 1),#3x3的卷積
ConvolutionalLayer(in_channels, out_channels, 1, 1, 0),#1x1的卷積
)
def forward(self, x):
return self.sub_module(x)
"""Concatenate不需要寫出來"""
"""主網絡"""
class MainNet(torch.nn.Module):
def __init__(self):
super(MainNet, self).__init__()
"""52*52的基礎網絡"""
self.trunk_52 = torch.nn.Sequential(
ConvolutionalLayer(3, 32, 3, 1, 1),
ConvolutionalLayer(32, 64, 3, 2, 1),#可調用下采樣函數替換
ResidualLayer(64),#一個殘差
DownsamplingLayer(64, 128),#一個下采樣
ResidualLayer(128),#兩個殘差
ResidualLayer(128),
DownsamplingLayer(128, 256),#一個下采樣
ResidualLayer(256),#八個殘差
ResidualLayer(256),
ResidualLayer(256),
ResidualLayer(256),
ResidualLayer(256),
ResidualLayer(256),
ResidualLayer(256),
ResidualLayer(256),
)
"""26*13的基礎網絡"""
self.trunk_26 = torch.nn.Sequential(
DownsamplingLayer(256, 512),#一個下采樣
ResidualLayer(512),#八個殘差
ResidualLayer(512),
ResidualLayer(512),
ResidualLayer(512),
ResidualLayer(512),
ResidualLayer(512),
ResidualLayer(512),
ResidualLayer(512),
)
"""13*13的基礎網絡"""
self.trunk_13 = torch.nn.Sequential(
DownsamplingLayer(512, 1024),#一個下采樣
ResidualLayer(1024),#四個殘差。這里可更改為16個殘差
ResidualLayer(1024),
ResidualLayer(1024),
ResidualLayer(1024)
)
"""13*13---專用卷積集"""
self.convset_13 = torch.nn.Sequential(
ConvolutionalSet(1024, 512)
)
"""13*13的偵測"""
self.detetion_13 = torch.nn.Sequential(
ConvolutionalLayer(512, 1024, 3, 1, 1),#1024可更改
torch.nn.Conv2d(1024, 45, 1, 1, 0)#10各類。三個建議框。每個建議框包括5個值:一個置信度(置信度用iou)、四個坐標值、分類類型。預測:3*(1+4+10)=45
)
"""上采樣-->26*26"""
self.up_26 = torch.nn.Sequential(
ConvolutionalLayer(512, 256, 1, 1, 0),#1x1的卷積,
UpsampleLayer()#上采樣。Concatenate無法體現
)
"""26*26--專用卷積集"""
self.convset_26 = torch.nn.Sequential(#專有卷積
ConvolutionalSet(768, 256)#通道數要計算。512+256=768
)
"""26*26的偵測"""
self.detetion_26 = torch.nn.Sequential(#26的偵測部分
ConvolutionalLayer(256, 512, 3, 1, 1),
torch.nn.Conv2d(512, 45, 1, 1, 0)
)
"""上采樣-->52*52"""
self.up_52 = torch.nn.Sequential(
ConvolutionalLayer(256, 128, 1, 1, 0),#1x1的卷積
UpsampleLayer()#上采樣(#如果使用轉置卷積,需要學習)
)
"""52*52---專用卷積集"""
self.convset_52 = torch.nn.Sequential(#專有卷積
ConvolutionalSet(384, 128)#通道數要計算
)
"""52*52的偵測"""
self.detetion_52 = torch.nn.Sequential(#52的偵測部分
ConvolutionalLayer(128, 256, 1, 1, 0),
torch.nn.Conv2d(256, 45, 1, 1, 0)
)
def forward(self, x):
#基礎網絡13、16、52的輸出
h_52 = self.trunk_52(x)
h_26 = self.trunk_26(h_52)
h_13 = self.trunk_13(h_26)
# 13的偵測部分
convset_out_13 = self.convset_13(h_13)
detetion_out_13 = self.detetion_13(convset_out_13)
# 26的偵測部分
up_out_26 = self.up_26(convset_out_13)
route_out_26 = torch.cat((up_out_26, h_26), dim=1)
convset_out_26 = self.convset_26(route_out_26)
detetion_out_26 = self.detetion_26(convset_out_26)
# 52的偵測部分
up_out_52 = self.up_52(convset_out_26)
route_out_52 = torch.cat((up_out_52, h_52), dim=1)
convset_out_52 = self.convset_52(route_out_52)
detetion_out_52 = self.detetion_52(convset_out_52)
return detetion_out_13, detetion_out_26, detetion_out_52
if __name__ == '__main__':
trunk = MainNet()
# x = torch.Tensor(2, 3, 416, 416)
x=torch.randn([2,3,416,416],dtype=torch.float32)
y_13, y_26, y_52 = trunk(x)
print(y_13.shape)#兩張圖、每個格子15個通道(3x5)、高和寬=13
print(y_26.shape)
print(y_52.shape)
print(y_13.view(-1, 3, 5, 13, 13).shape)
2.數據制作
數據格式:
圖片 類別1 x1 y1 w1 h1 類別2 x2 y2 w2 h2 ...
images/1.jpg 1 12 13 51 18 2 22 31 55 98 2 44 33 62 62
置信度:IOU值。來自實際框與建議框的比值。
建議框、類別、坐標值。
-
寬和高做處理
-
實際框和建議框的寬和高不能直接拿去神經網絡進行訓練。可以學習真實框/建議框的比值(真實框的寬/建議框的寬;真實框的高/建議框的高)是整數。要神經網路學習比例(比例>0)。神經網絡輸出值范圍在(-∞,+∞),要變為>0。使用log函數**。–>。w變為正數。又因為,log的在(0-1)梯度非常大,因為比值不是很大(學的置信度很高的框,比值在1附近),易于網絡收斂。也可以起到數據壓縮的作用,易于模型收斂。
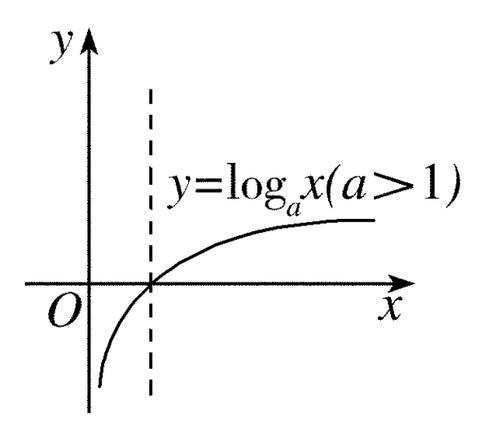
-
中心點的處理
-
中心點的坐標也不能直接拿來學習。中心點與當前格子的左上角做一個偏移。當一張圖特別大,比值非常小,數值非常小,計算機容易丟失精度,收斂起來也很慢。首先需要知道當前格子的坐標:使用索引。如,中心點坐標x=3x32+比例x32(格子數從o開始數);中心點坐標y=2x32+比例x32。同樣,索引通過特征圖計算:x(y)/32,整數部分是索引,小數部分是中心點在當前格子的偏移比值。做樣本時只需要小數部分(偏移量)。反算:索引x32為當前格子左上角坐標值(記為A);偏移量x32+A為當前格子中心點的坐標值。下圖中,是真實框的寬和高,是建議框的寬和高。計算:,;反算:如下圖。
-
實際使用中:使用標注精靈時,首先在圖片上框出物體對象(實際框,即得到種類),得到物體的中心點坐標,然后除以32,結果中整數部分為索引值,小數為中心點相對當前格子偏移了多少;接著,依據實際框得到三種建議框,建議框以實際框為中心,分別有正方形、豎著的長方形、橫著的長方形三種;最后,按比例縮放三種框得到9個建議框(也可聚類得到),并使用9個建議框和實際框做IOU,即置信度。,,反算得到寬和高。最終得到
- 代碼:
import torch
from torch.utils.data import Dataset,DataLoader
import torchvision
import numpy as np
from my_yolov3 import cfg
import os
from PIL import Image
import math
LABEL_FILE_PATH = "data/person_label.txt"#數據集
IMG_BASE_DIR = "data"#圖片(416*416)(建議:先將圖片處理為416*416大小,再做標簽。因為長方形處理為正方形時左上角參考會變化)
transforms = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
def one_hot(cls_num, i):
b = np.zeros(cls_num)#一維0數組
b[i] = 1.#i:當前類別。
return b
class MyDataset(Dataset):
def __init__(self):
with open(LABEL_FILE_PATH) as f:#with:防止資源泄露
self.dataset = f.readlines()#readlines():讀取所有行。
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
labels = {}#三個尺寸。存放數據標簽
line = self.dataset[index]#根據索引拿到每一行
strs = line.split()#切開
_img_data = Image.open(os.path.join(IMG_BASE_DIR, strs[0]))#第0個為圖片名字。圖片位置。(原數據格式:images/1.jpg 1 12 13 51 18 2 22 31 55 98 2 44 33 62 62)
img_data = transforms(_img_data)#to tensor (NCHW) #還可以進行縮放、變換等操作(自行更改)
# _boxes = np.array(float(x) for x in strs[1:])
_boxes = np.array(list(map(float, strs[1:])))# 切割出來是列表,需要轉成數組格式進行廣播。#map:迭代器。 #_boxes = np.array(list(map(float, strs[1:])))
boxes = np.split(_boxes, len(_boxes) // 5)#除圖片,剩下的每5個一組(原數據格式:images/1.jpg 1 12 13 51 18 2 22 31 55 98 2 44 33 62 62)
#建議框及其尺寸
for feature_size, anchors in cfg.ANCHORS_GROUP.items():#循環三種尺寸及三種尺寸下的建議框。ANCHORS_GROUP:建議框#得到特征圖尺寸、建議框數據(因為是字典形式存放)。
labels[feature_size] = np.zeros(shape=(feature_size, feature_size, 3, 5 + cfg.CLASS_NUM))#生成一個0數組,形狀為13x13/26x26/52x52,3(三種建議框),5+類別數量-->如:(13,13,3,15),最終得到HWC(13,13,45),其中沒有批次。通過index添加的是一張圖片,沒有批次。如果需要添加批次,在訓練數據時添加數據時設置批次。
# 設計0矩陣用于填充特征值
#建議box計算索引和偏移量
for box in boxes:#分好的,每5個一組的。格式如:[[1,2,3,4,5],[1,2,3,4,5],...]。循環拿出每個box
cls, cx, cy, w, h = box#每個box有5個值。
cx_offset, cx_index = math.modf(cx * feature_size / cfg.IMG_WIDTH)#cx*13/416=cx/32 小數、整數=偏移量和索引。
cy_offset, cy_index = math.modf(cy * feature_size / cfg.IMG_WIDTH)#cy*13/416=cy/32 小數、整數=偏移量和索引。
#每個建議框
for i, anchor in enumerate(anchors):#遍歷每一種尺寸的每個建議框
anchor_area = cfg.ANCHORS_GROUP_AREA[feature_size][i]#得到三個建議框的面積列表
p_w, p_h = w / anchor[0], h / anchor[1]#計算真實框/建議框#anchor[0]:建議框的寬;anchor[1]:建議框的高
p_area = w * h#真實框面積
iou = min(p_area, anchor_area) / max(p_area, anchor_area)#iou值一定小于1。選擇小的面積除以大的面積。
#打包。輸出每種尺寸下的建議框的標簽值
labels[feature_size][int(cy_index), int(cx_index), i] = np.array(
[iou, cx_offset, cy_offset, np.log(p_w), np.log(p_h), *one_hot(cfg.CLASS_NUM, int(cls))])#10,i#hwc-->y,x,3。cy_index代表H;cx_index代表W;i代表哪一個(3個)。
return labels[13], labels[26], labels[52], img_data
data = MyDataset()
dataloader = DataLoader(data,2,shuffle=True)#中間數字可更改
for y_13,y_26,y_52,image in dataloader:
print(y_13.shape)#幾種尺寸,特征圖大小,每種尺寸下有多少種建議框,15
print(y_26.shape)
print(y_52.shape)
print(image.shape)
3.訓練
做置信度比較,保留置信度大的框,做中心點和寬、高的損失,以及分類。
- 代碼
from my_yolov3 import dataset
from my_yolov3.model import *
import torch
from torch.utils.data import DataLoader
import os
def loss_fn(output, target, alpha):
conf_loss_fn = torch.nn.BCEWithLogitsLoss()#計算置信度。也可使用均方差損失計算。#sigmold+BCE,就不使用sigmold**,比BCEloss穩定。
# conf_loss_fn=torch.nn.BCELoss()#計算置信度。也可使用均方差損失計算。
crood_loss_fn = torch.nn.MSELoss()#計算坐標偏移量。
cls_loss_fn = torch.nn.CrossEntropyLoss()#計算多分類。可區別類與類之間的包含關系的情況。如果標簽里包含包含關系,不使用交叉熵損失函數。
output = output.permute(0, 2, 3, 1)#nchw-->nhwc(如:1,45,13,13-->1,13,13,45)。為了跟標簽匹配。先轉置,
output = output.reshape(output.size(0), output.size(1), output.size(2), 3, -1)#如(1,13,13,45)-->(1,13,13,3,15).再變形。
#先計算置信度的滿足情況
mask_obj = target[..., 0] > 0#掩碼。格式為true和fulse。(數值根據需求可更改。)
output_obj = output[mask_obj]#得到符合條件的正樣本輸出
target_obj = target[mask_obj]#得到符合條件的正樣本標簽
loss_obj_conf = conf_loss_fn(output_obj[:, 0], target_obj[:, 0])#置信度損失。正確的學正確
loss_obj_crood = crood_loss_fn(output_obj[:, 1:5], target_obj[:, 1:5])#中心點、寬和高,通過MSEloss計算
loss_obj_cls = cls_loss_fn(output_obj[:, 5:], target_obj[:, 5:])#類別,通過交叉熵計算
loss_obj = loss_obj_conf + loss_obj_crood + loss_obj_cls##總體損失計算(正樣本損失)
mask_noobj = target[..., 0] == 0#拿到標簽中置信度為0的掩碼。(數值根據需求可更改。)
output_noobj = output[mask_noobj]
target_noobj = target[mask_noobj]
loss_noobj = conf_loss_fn(output_noobj[:, 0], target_noobj[:, 0])#負樣本不學坐標的回歸量等。
loss = alpha * loss_obj + (1 - alpha) * loss_noobj#(1 - alpha):在yolo中正樣本的權重應該給高些,因為不需要學習太多背景信息。(與MTCNN相反)。這種方法稱為:樣本平衡。
# loss = loss_obj + loss_noobj
return loss
if __name__ == '__main__':
save_path = "models/net_yolo_GM.pth"
myDataset = dataset.MyDataset()
train_loader = DataLoader(myDataset, batch_size=2, shuffle=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = MainNet().to(device)
if os.path.exists(save_path):
net.load_state_dict(torch.load(save_path))
else:
print("NO Param")
net.train()
opt = torch.optim.Adam(net.parameters())
epoch = 0
while True:
for target_13, target_26, target_52, img_data in train_loader:
img_data = img_data.to(device)
output_13, output_26, output_52 = net(img_data)
loss_13 = loss_fn(output_13, target_13, 0.9)
loss_26 = loss_fn(output_26, target_26, 0.9)
loss_52 = loss_fn(output_52, target_52, 0.9)
loss = loss_13 + loss_26 + loss_52
opt.zero_grad()
loss.backward()
opt.step()
if epoch % 10 == 0:
torch.save(net.state_dict(), save_path)
print('save {}'.format(epoch))
print(loss.item())
epoch += 1
4.偵測
from my_yolov3.model import *
from my_yolov3 import cfg
import torch
import numpy as np
import PIL.Image as pimg
import PIL.ImageDraw as draw
from my_yolov3 import tool
class Detector(torch.nn.Module):
def __init__(self,save_path):
super(Detector, self).__init__()
self.net = MainNet()#實例化網絡
self.net.load_state_dict(torch.load(save_path))#加載訓練器
self.net.eval()#
def forward(self, input, thresh, anchors):
output_13, output_26, output_52 = self.net(input)#輸出三種結果
idxs_13, vecs_13 = self._filter(output_13, thresh)#過濾器。輸出合格的特征點的索引和(15個)值
boxes_13 = self._parse(idxs_13, vecs_13, 32, anchors[13])#將值傳到專網解析網絡中得到建議框
idxs_26, vecs_26 = self._filter(output_26, thresh)#過濾器。
boxes_26 = self._parse(idxs_26, vecs_26, 16, anchors[26])#將值傳到專網解析網絡中得到建議框
idxs_52, vecs_52 = self._filter(output_52, thresh)#過濾器。
boxes_52 = self._parse(idxs_52, vecs_52, 8, anchors[52])#將值傳到專網解析網絡中得到建議框
return torch.cat([boxes_13, boxes_26, boxes_52], dim=0)
#特征圖上的特征點,判斷特征點在原圖上是否有物體,如果有,輸出(15個)值
def _filter(self, output, thresh):#
output = output.permute(0, 2, 3, 1)#nchw-->nhwc
output = output.reshape(output.size(0), output.size(1), output.size(2), 3, -1)#變成3x15
mask = output[..., 0] > thresh#掩碼。將>閾值的掩碼
idxs = mask.nonzero()#特征圖大于多少的索引
vecs = output[mask]#取值
return idxs, vecs #索引 值
#解析
def _parse(self, idxs, vecs, t, anchors):#索引 值 32 建議框
anchors = torch.Tensor(anchors)#將建議框轉為ensor
a = idxs[:, 3] # 建議框:3 #每個特征圖下有三種建議框,每個建議框下對應15個(置信度、中心點、寬和高 種類)值。nhw 3 15
confidence = vecs[:, 0]#置信度
_classify = vecs[:, 5:]#分類
if len(_classify) == 0:#如果onehot是0,表示沒有訓練.返回空
classify = torch.Tensor([])
else:
classify = torch.argmax(_classify, dim=1).float()#否則取最大值的索引,即取出類別
#取坐標(C XC XY W H)
cy = (idxs[:, 1].float() + vecs[:, 2]) * t# 原圖的中心點y。H計算Y值。H的索引+偏移值(Y的偏移)*32-->回到原圖上的坐標值
cx = (idxs[:, 2].float() + vecs[:, 1]) * t# 原圖的中心點x。W計算X值。W的索引+偏移值(X的偏移)*32-->回到原圖上的坐標值
w = anchors[a, 0] * torch.exp(vecs[:, 3])#anchors:獲得三組建議框。第一個建議框的第0個,乘以縮放比例-->真實寬度
h = anchors[a, 1] * torch.exp(vecs[:, 4])
x1 = cx - w / 2
y1 = cy - h / 2
x2 = x1 + w
y2 = y1 + h
out = torch.stack([confidence,x1,y1,x2,y2,classify], dim=1)
return out
if __name__ == '__main__':
save_path = "models/net_yolo_GM.pth"
detector = Detector(save_path)
# y = detector(torch.randn(3, 3, 416, 416), 0.3, cfg.ANCHORS_GROUP)
# print(y.shape)
img1 = pimg.open(r'data\images\1.jpg')
img = img1.convert('RGB')
img = np.array(img) / 255
img = torch.Tensor(img)
img = img.unsqueeze(0)
img = img.permute(0, 3, 1, 2)#nhwc-->nchw
img = img.cuda()
out_value = detector(img, 0.3, cfg.ANCHORS_GROUP)
boxes = []
for j in range(10):
classify_mask = (out_value[..., -1] == j)#類別正確的掩碼
_boxes = out_value[classify_mask]
boxes.append(tool.nms(_boxes))#拿到某一類最好的框
for box in boxes:
try:
img_draw = draw.ImageDraw(img1)#畫出來框
x1, y1, x2, y2 = box[0, 1:5]
print(x1, y1, x2, y2)
img_draw.rectangle((x1, y1, x2, y2))
except:
continue
img1.show()
好文連接:
https://www.jianshu.com/p/d13ae1055302
https://blog.csdn.net/litt1e/article/details/88907542
https://blog.csdn.net/leviopku/article/details/82660381
模型結構可視化工具是:Netron
智能推薦

KMP算法的詳細分析
前言 關于KMP算法的描述在網上可以說是多如牛毛,以前學習的時候也碰到過這個問題。只是一直對它的理解不夠深刻。而在網上搜索了一通之后,發現大量的文章要么就是簡單的說一下思路然后給一堆代碼,要么就是純粹講理論,對于實際的實現沒有任何幫助。自己在學習和實現整個算法的過程中也碰到過幾個小的細節,被卡在那里很久。經過很久的揣摩才想清楚了一點,這里就把整個算法的思想和實現過程詳細...
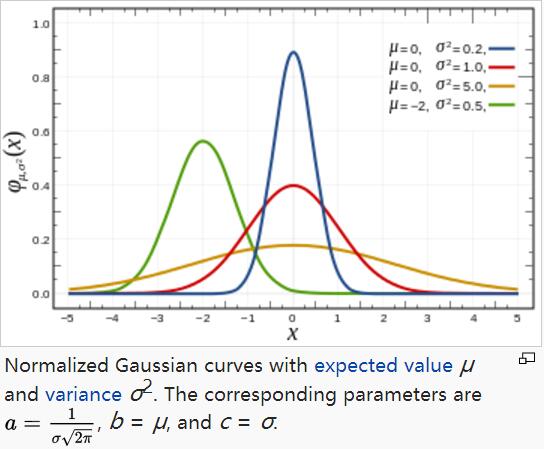
高斯函數的詳細分析
摘要 論文中遇到很重要的一個元素就是高斯核函數,但是必須要分析出高斯函數的各種潛在屬性,本文首先參考相關材料給出高斯核函數的基礎,然后使用matlab自動保存不同參數下的高斯核函數的變化gif動圖,同時分享出源代碼,這樣也便于后續的論文寫作。 高斯函數的基礎 2.1 一維高斯函數 高斯函數,Gaussian Function, 也簡稱為Gaussian,一...

vue-cli 詳細分析
是什么? vue-lic 是 vue 官方提供的腳手架工具,默認搭建好一個項目的基本架子,我們只需要在此基礎上進行相應的修改即可。 下載: https://github.com/vuejs/vue 安裝 注意:安裝 vue-cli 前需要事先配置好 node 環境 使用vue-cli創建vue工程項目 創建后需要進行配置: Project name :項目名稱 ,如果不需要更改直接回車就可以了。注...
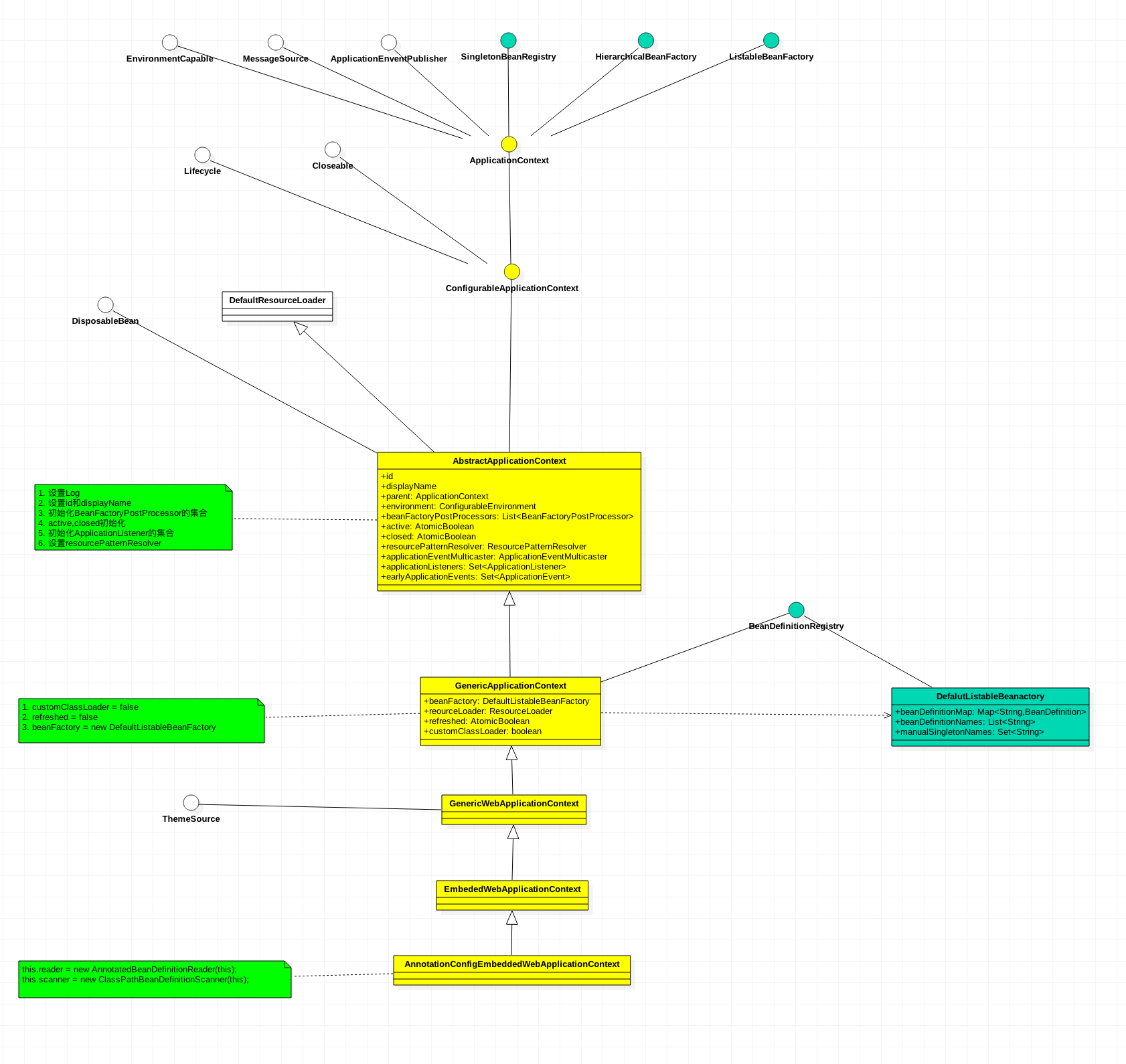
springboot啟動流程-詳細分析
一句話總結:在context的refresh方法中,需要注冊bean definition,實例化bean.在加載bean defintion的時候使用ConfigurationClassParser類來解析我們的主類。然后在解析主類的時候發現了@EnableAutoConfiguratio注解中的@Import注解,就去處理@Import注解中的value值,然后就使用ImportSelecto...
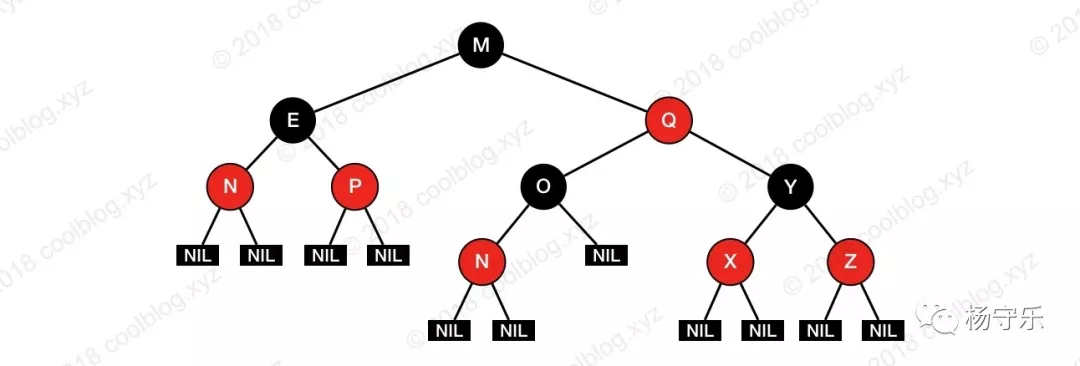
紅黑樹詳細分析
轉載自 coolblog 算法與數據結構 “ 一、紅黑樹簡介 紅黑樹是一種自平衡的二叉查找樹,是一種高效的查找樹。它是由 Rudolf Bayer 于1972年發明,在當時被稱為對稱二叉 B 樹(symmetric binary B-trees)。后來,在1978年被 Leo J. Guibas 和 Robert Sedgewick 修改為如今的紅黑樹...
猜你喜歡


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...
