android學習筆記----xml語法、約束、解析
目錄
xml作用:
一:可以在客戶端/服務器之間傳遞數據
二:用來保存有關系的數據
三:用來做配置文件
在android中的界面的布局文件、清單文件都是用xml文件來描述的。
所有的瀏覽器都可以解析xml
xml語法:

xml文件的encoding默認是:"utf-8",但是如果用記事本編輯xml,保存的時候默認ANSI,代表使用平臺的編碼表gbk保存,不指定編碼的話,在解析的時候可能會出現問題。在保存的時候選擇UTF-8保存就可以不指定編碼,最好還是要指定編碼。
保存的時候,編碼方式要和聲明的encoding一致,如果不一致,則按照保存的為準,忽視了聲明encoding。比如保存的時候選擇ANSI,但是encoding=“utf-8”,則還是按照平臺編碼標準gbk,解析的時候,中文會亂碼。除非保存選擇ANSI,encoding=“gbk”
用集成開發環境就不會出現上述問題,會自動處理成一致的。
元素:

比如:
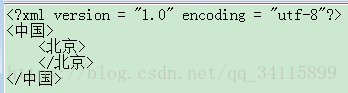
<?xml version = "1.0" encoding = "utf-8"?>
<中國>
<北京>
</北京>
</中國>
<中國>
<武漢>
</武漢>
</中國>
這就是錯誤的,要么認為沒有根標簽,要么認為有2個根標簽<中國>,語法不對。

如果標簽中沒有其他內容,那么可以自閉合,如<tag />
第一種寫法:(可讀性好,浪費流量)
空格對用戶來說也是需要流量的
第二種寫法:(可讀性差,節省流量)

元素--命名規范:

屬性:

注釋:

切記,第一行一定是xml聲明,不能是注釋
CDATA區:

比如:想顯示尖括號<>這個直接打上去不允許,會被認為是標簽的尖括號。那么操作如下:
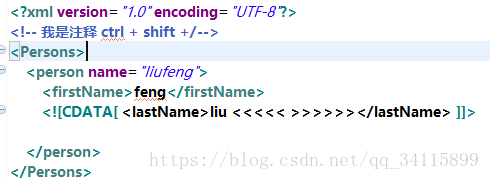
瀏覽器打開效果:

特殊字符:
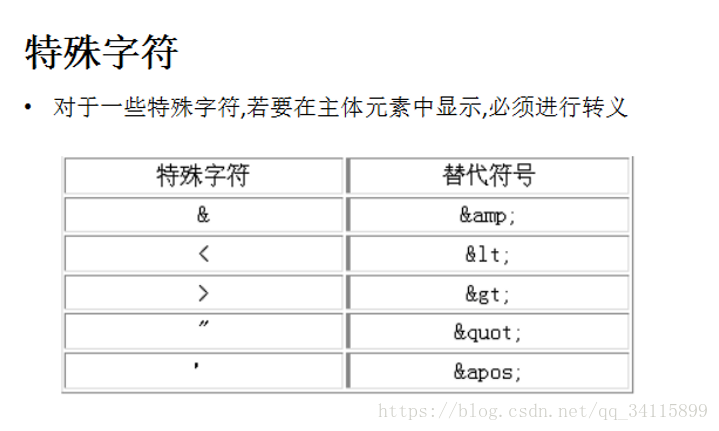
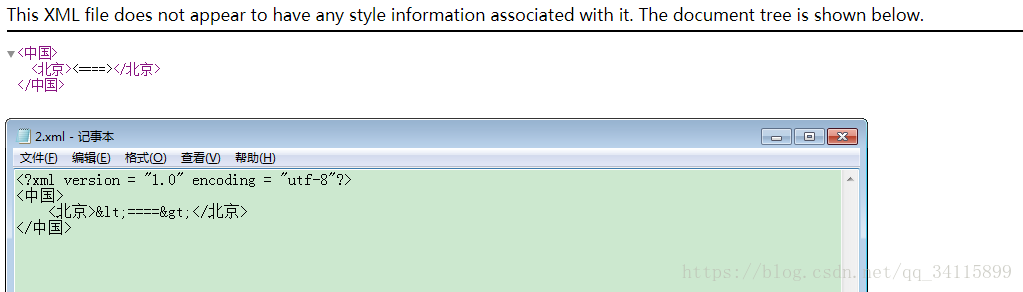
要想直接顯示大于號小于號,則需要轉義字符
XML約束:

有效的xml一定是格式良好的xml,而格式良好的xml不一定是有效的xml

DTD約束:

book.dtd中
“(書+)”代表可以有多個<書>這種結點

引入DTD文檔URL會自動下載DTD文檔





#PCDATA說明標簽內只能是普通文本,不能含有其他標簽,比如<書名><a>java就業培訓教程</a></書名>就出錯,因為不能含有<a>標簽,只能是普通文本。
EMPTY說明標簽內不能有任何內容,只能是空標簽
()括號里面表示該標簽包含哪些子標簽,比如<!ELEMENT 書 (書名,作者,售價)>,因為是用逗號分隔,所以子標簽的順序一定是<書名><作者><售價>

<!ATTLIST>約束屬性列表
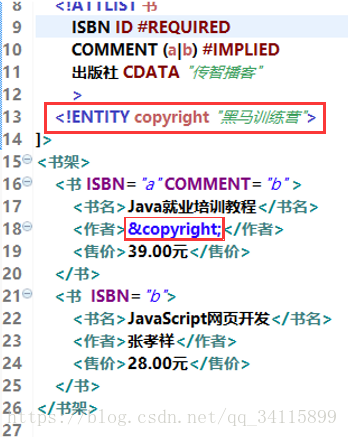
比如

上圖說明,ISBN屬性ID表示取值不能重復,如果另一個<書>標簽的ISBN屬性與這個標簽的ISBN值重復就會報錯,#REQUIRED說明這個ISBN屬性是必須有的。
COMMENT的屬性CDATA表示這個屬性只能是普通文本字符串,#IMPLIED表示這個屬性可有可無,假如屬性加上(a|b)就表示只能從“a”或“b”任選其一,上面的<書 ISBN="a" COMMENT="ddd">就會報錯,不能取值“ddd”。

比如:
網頁效果:


通過DTD可以約束元素的名稱,元素出現的順序、次數,屬性的名稱、類型、是否必須出現、值是否可以重復。
如果是聲明在xml文檔中的DTD,那么編碼沒有要求,如果是獨立的DTD文檔,擴展名是dtd,則編碼必須是utf-8
Schema約束:



xmlns表示命名空間
targetNamespace表示目標空間,通常是指公司的域名,都是不同的。
在xml文檔中,需要符合schema約束,比如在xml中的xmlns:android就是schema約束中的目標空間android,比如為xmlns:android="http://schemas.android.com/apk/res/android",這是作為一個文檔的標識,并不是說文檔就在這個網址中,比如另外一個xml文件中也有<書>標簽,就用名稱空間來區分,比如android:layout_height="wrap_content"就用到了schema技術,表示這個layout_height屬性的名稱空間是android。
xmlns:xsi就是需要符合的標準比如xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http//www.itheima.com bookschema.xsd"表示對應的文檔在http//www.itheima.com, 文檔名字是bookschema.xsd。
Schema:
一:Schema擴展名.xsd,本身也是一份xml文檔
二:對名稱空間(namespace)支持的很好
三:支持的類型比dtd更豐富,約束的更細致,可以支持自定義的類型
四:schema正在逐步替換dtd,在android中清單文件和布局文件就用到了schema約束
xml約束技術的作用:規范xml文件的書寫(標簽 屬性 文本)
xml約束常用技術:dtd schema
android中用到的約束schema
名稱空間:起到了類似包名的作用
如果xml沒有約束,那么只需要遵循xml基本語法即可,比如服務端和客戶端傳輸數據,只要事先協商好每個標簽是什么意思就行,就不必用約束。
XML解析:

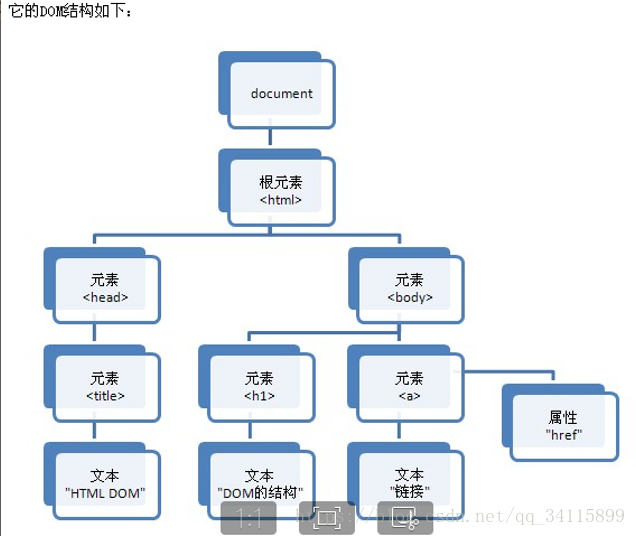
DOM解析:
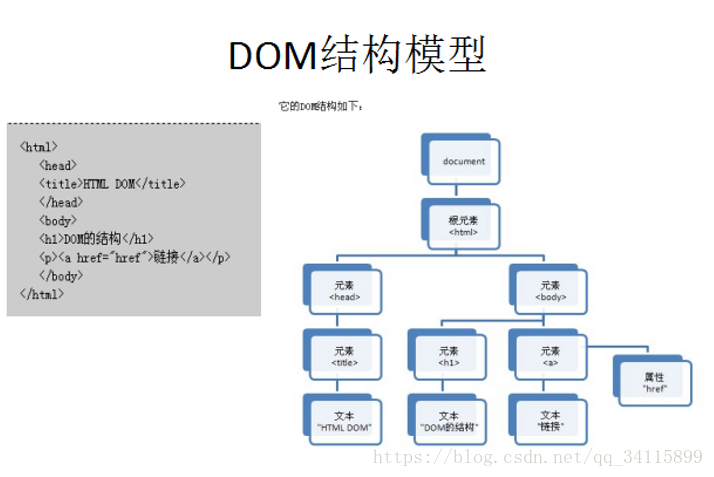
DOM文檔都加載到內存中



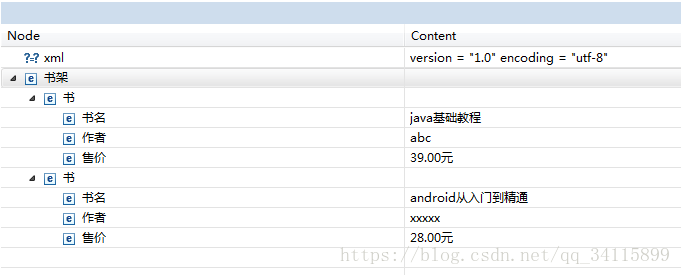
book.xml如下:

在eclipse中顯示:
先把book.xml復制粘貼到項目中
package xml解析;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class DomParseTest {
public static void main(String[] args) throws Exception {
// 獲取DocumentBuilderFactory
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
// 獲取DocumentBuilder
DocumentBuilder documentBuilder = builderFactory.newDocumentBuilder();
// 通過ducumentBuilder解析xml文檔獲得Document對象
Document document = documentBuilder.parse("book.xml");
// 通過元素的名字可以找到元素的集合
NodeList nodeList = document.getElementsByTagName("書");
// 找到第幾個元素
Node node = nodeList.item(0);
Node node1 = nodeList.item(1);
// 讀出對應的節點文本內容
String content = node.getTextContent();
String content1 = node1.getTextContent();
System.out.println("書:");
System.out.println(content);
System.out.println(content1);
System.out.println("============================");
// 通過元素的名字可以找到元素的集合
NodeList nodeList1 = document.getElementsByTagName("書名");
// 找到第幾個元素
Node node2 = nodeList1.item(0);
Node node3 = nodeList1.item(1);
// DOM把xml讀取到了內存中,這只是在內存中的修改,源文件并沒有變
node2.setTextContent("被修改了");
// 讀出對應的節點文本內容
String content2 = node2.getTextContent();
String content3 = node3.getTextContent();
System.out.println("書名:");
System.out.println(content2);
System.out.println(content3);
}
}運行結果如圖:

package xml解析;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.Result;
import javax.xml.transform.Source;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class DomParseTest {
public static void main(String[] args) throws Exception {
// 獲取DocumentBuilderFactory
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
// 獲取DocumentBuilder
DocumentBuilder documentBuilder = builderFactory.newDocumentBuilder();
// 通過ducumentBuilder解析xml文檔獲得Document對象
Document document = documentBuilder.parse("book.xml");
// 通過元素的名字可以找到元素的集合
NodeList nodeList = document.getElementsByTagName("書");
// 找到第幾個元素
Node node = nodeList.item(0);
Node node1 = nodeList.item(1);
// 讀出對應的節點文本內容
String content = node.getTextContent();
String content1 = node1.getTextContent();
System.out.println("書:");
System.out.println(content);
System.out.println(content1);
System.out.println("============================");
// 通過元素的名字可以找到元素的集合
NodeList nodeList1 = document.getElementsByTagName("書名");
// 找到第幾個元素
Node node2 = nodeList1.item(0);
Node node3 = nodeList1.item(1);
// DOM把xml讀取到了內存中,這只是在內存中的修改,源文件并沒有變
node2.setTextContent("被修改了");
// 讀出對應的節點文本內容
String content2 = node2.getTextContent();
String content3 = node3.getTextContent();
System.out.println("書名:");
System.out.println(content2);
System.out.println(content3);
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transformer = transformerFactory.newTransformer();
// 數據源
Source xmlSource = new DOMSource(document); // 獲取內存中的document對象
// 要輸出到的目的地
Result outputTarget = new StreamResult("book.xml");
transformer.transform(xmlSource, outputTarget);
System.out.println("=========================");
System.out.println("現在查看xml發現真正被修改了");
}
}運行結果:



DOM解析要點:

SAX解析:

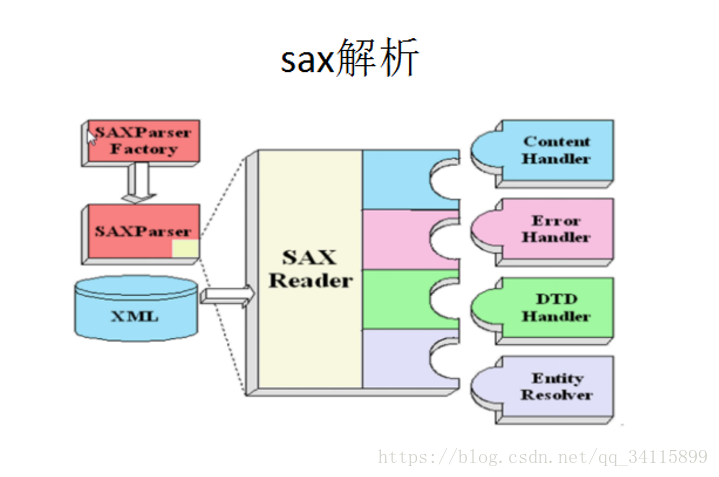
用代碼解決SAX解析的過程:
package xml解析;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
public class SaxParserTest {
public static void main(String[] args) throws Exception {
// 獲取工廠
SAXParserFactory parserFactory = SAXParserFactory.newInstance();
SAXParser saxParser = parserFactory.newSAXParser();
// 獲取xmlReader通過這個reader可以試著ContentHandler
XMLReader xmlReader = saxParser.getXMLReader();
// 給xmlReader設置contentHandler
// contentHandler是一個接口,里面太多的方法沒實現
// 所以不去直接實現contentHandler,而是繼承它默認的實現DefaultHandler
xmlReader.setContentHandler(new MyHandler());
// 解析xml文檔
xmlReader.parse("book.xml");
}
private static class MyHandler extends DefaultHandler {
@Override
public void startDocument() throws SAXException {
System.out.println("文檔開始");
}
@Override
public void endDocument() throws SAXException {
System.out.println("文檔結束");
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes)
throws SAXException {
System.out.println("開始標簽<" + qName + ">");
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
System.out.println("結束標簽</" + qName + ">");
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
String text = new String(ch, start, length);
System.out.println("文本內容" + text);
}
}
}運行結果:

從結果可以看出,不管開始標簽結束標簽,之后就會嘗試獲取內容,如果內容為空,那么就不會獲取結束標簽。
也就是調用了startElement方法或者endElement方法后,一定會調用characters方法,如果調用characters方法獲取的文本為空串,那么就會跳到下一行進行解析。
sax解析一次性解析完畢,中途不會停止,除非拋異常,而pull解析需要自己去next()進行下一次解析。
PULL解析:

pull解析在java里面需要導包,但是在android里面不需要解析,默認就是pull解析
關于pull解析可以看我的另一篇文章:android學習筆記----pull解析與xml生成和應用申請權限模版
================================Talk is cheap, show me the code================================
智能推薦
java -xml約束與解析簡介
1.xml的約束的種類:一般有dtd以及xsd,dtd對于元素的格式并無法規定,如格式而xsd對于 要會讀懂名稱空間,看懂前綴即可。 2.xml解析的方式:有dom以及sax,sax是逐行讀取,然后會釋放內存資源,所以不適合CRUD,通常用于移動端或者小型設備,優點是占內存少。dom即是前面javaScript的dom技術,把一顆dom樹讀取進內存, 缺點內存占用大,優點crud方便,多用于服務器...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...
猜你喜歡


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...

統計學習方法 - 樸素貝葉斯
引入問題:一機器在良好狀態生產合格產品幾率是 90%,在故障狀態生產合格產品幾率是 30%,機器良好的概率是 75%。若一日第一件產品是合格品,那么此日機器良好的概率是多少。 貝葉斯模型 生成模型與判別模型 判別模型,即要判斷這個東西到底是哪一類,也就是要求y,那就用給定的x去預測。 生成模型,是要生成一個模型,那就是誰根據什么生成了模型,誰就是類別y,根據的內容就是x 以上述例子,判斷一個生產出...

styled-components —— React 中的 CSS 最佳實踐
https://zhuanlan.zhihu.com/p/29344146 Styled-components 是目前 React 樣式方案中最受關注的一種,它既具備了 css-in-js 的模塊化與參數化優點,又完全使用CSS的書寫習慣,不會引起額外的學習成本。本文是 styled-components 作者之一 Max Stoiber 所寫,首先總結了前端組件化樣式中的最佳實踐原則,然后在此基...
