極客 | Python | 學習筆記01:Python 定向爬蟲入門
視頻課程:牛客網-Python開發入門到實戰 https://www.nowcoder.com/courses/10 (講師:極客學院)
* 極客學院網站中也有對應視頻內容 http://www.jikexueyuan.com/course/python/ (可自行按標題搜索)
Ps_1:視頻中的PPT以及代碼可以在網站中下載
Ps_2:由于網站提供的代碼是兩年前所寫,代碼中爬取的網頁兩年來可能有變動,所以代碼運行結果會和視頻中不一致,甚至出現報錯。
在本文中的代碼均為個人修改后的,無法修改的也進行了標記。
# 三、Python 定向爬蟲入門
┏━━━━━目錄━━━━━┓
(一)【基本的正則表達式】
3.1 Pycharm 的安裝與配置(略)
3.2 正則表達式符號與方法
3.3 正則表達式的應用舉例
3.4 實戰——制作文本爬蟲
(二)【Requests 介紹和安裝】
3.5 Requests 介紹和安裝
3.6 第一個網頁爬蟲
3.7 向網頁提交數據
3.8 實戰——極客學院課程爬蟲
(三)【XPath 與多線程爬蟲】
3.9 神器 XPath 的介紹與配置
3.10 神器 XPath 的使用
3.11 神器 XPath 的特殊用法
3.12 Python 并行化介紹與演示
3.13 實戰——百度貼吧爬蟲
┗━━━━━━━━━━━━┛
(一)【基本的正則表達式】
3.2 正則表達式符號與方法
1、常用符號
. : 匹配任意字符,換行符\n除外(占位符)
* :匹配前一個字符0次或無限次
? :匹配前一個字符0次或1次
.*:貪心算法(貪心算法將會按照盡可能大的原則去匹配字符串。)
——其中標點 . 表示通配符,可以用來匹配除換行符之外的任意符號,* 為重復子模式,允許模式重復0次或者多次;
.*?:非貪心算法
——其中標點 . 表示通配符,可以用來匹配除換行符之外的任意符號,* 為重復子模式,允許模式重復0次或者多次;? 為可選項。
\d+:匹配純數字
import re
s="gaxxIxxefahxxlovexxhoghexxpythonxxghaweoif"
r=re.compile('xx(.*)xx') # 貪心算法
content=r.findall(s)
print content
r=re.compile('xx(.*?)xx') # 非貪心算法
content=r.findall(s)
print content['Ixxefahxxlovexxhoghexxpython']
['I', 'love', 'python']
2、常用函數
s = '''sdfxxhello
xxfsdfxxworldxxasdf'''
print 1, re.findall('xx(.*?)xx', s) # .不能匹配換行符,在第一行沒找到對象,返回了第二行匹配到的
print 2, re.findall('xx(.*?)xx', s, re.S) # 參數re.S表示多行匹配
s2 = 'asdfxxIxx123xxlovexxdfd,asdfxxhahaxx123xxXIXIxxdfd'
print 3, re.findall('xx(.*?)xx123xx(.*?)xx', s2) # 找到所有匹配子串2 ['hello\n', 'world']
3 [('I', 'love'), ('haha', 'XIXI')]
(2)Search:匹配并提取第一個符合規律的內容,返回一個正則表達式對象(object)
# re.search(pattern, string)
s2 = 'asdfxxIxx123xxlovexxdfd,asdfxxhahaxx123xxXIXIxxdfd'
print 4, re.search('xx(.*?)xx123xx(.*?)xx', s2).group(1) # 輸出一次匹配中的第1個()
print 5, re.search('xx(.*?)xx123xx(.*?)xx', s2).group(2) # 輸出一次匹配中的第2個()
print 6, (re.search('as', s2).span()) # 在起始位置匹配
print 7, (re.search('xx', s2).span()) # 不在起始位置匹配
print 8, (re.search('xx', s2)) # 返回一個正則表達式對象(object)5 love
6 (0, 2)
7 (4, 6)
8 <_sre.SRE_Match object at 0x0000000001CCB510>
# re.sub(pattern, repl, string)
s3 = 'aaa123rrrrr123aaa'
print 9, re.sub('123(.*?)123', '替換', s3) # 連通123一起替換
print 10, re.sub('123(.*?)123', '123%s123' % "替換后", s3) # 替換123與123之間的內容
p1 = re.compile('123(.*?)123')
print 11, p1.sub('123%s123' % "替換后", s3) # 替換123與123之間的內容
10 aaa123替換后123aaa
11 aaa123替換后123aaa
* 先抓大再抓小
<html>
<head>
<title>極客學院爬蟲測試</title>
</head>
<body>
<div class="topic"><a href="http://jikexueyuan.com/welcome.html">歡迎參加《Python定向爬蟲入門課程》</a>
<div class="list">
<ul>
<li><a href="http://jikexueyuan.com/1.html">這是第一條</a></li>
<li><a href="http://jikexueyuan.com/2.html">這是第二條</a></li>
<li><a href="http://jikexueyuan.com/3.html">這是第三條</a></li>
</ul>
</div>
</div>
</body>
</html>f = open('text.txt','r')
html = f.read() # html里是文本里的內容
f.close()
# 需要尋找的<title>只出現一次,search()只返回第一個匹配的元素,不用遍歷全部,效率更高
title = re.search('<title>(.*?)</title>',html,re.S).group(1) # 爬取標題
print title
links = re.findall('href="(.*?)"',html,re.S) # 爬取鏈接
for each in links:
print each
# 抓取部分文字,先大再小
text_field = re.findall('<ul>(.*?)</ul>',html,re.S)[0] # 先抓大:把范圍縮小至<ul> </ul>,【html】→【text_field】
the_text = re.findall('">(.*?)</a>',text_field,re.S) # 在text_field 里再次findall()
for every_text in the_text:
print every_texthttp://jikexueyuan.com/welcome.html
http://jikexueyuan.com/1.html
http://jikexueyuan.com/2.html
http://jikexueyuan.com/3.html
這是第一條
這是第二條
這是第三條
old_url = 'http://www.jikexueyuan.com/course/android/?pageNum=2'
total_page = 20
# sub實現翻頁
for i in range(2, total_page + 1): # range范圍不包含上界,需要+1
new_link = re.sub('pageNum=\d+', 'pageNum=%d' % i, old_url, re.S) # i的范圍2~20替換數字實現翻頁
print new_linkhttp://www.jikexueyuan.com/course/android/?pageNum=3
http://www.jikexueyuan.com/course/android/?pageNum=4
http://www.jikexueyuan.com/course/android/?pageNum=5
http://www.jikexueyuan.com/course/android/?pageNum=6
http://www.jikexueyuan.com/course/android/?pageNum=7
http://www.jikexueyuan.com/course/android/?pageNum=8
http://www.jikexueyuan.com/course/android/?pageNum=9
http://www.jikexueyuan.com/course/android/?pageNum=10
http://www.jikexueyuan.com/course/android/?pageNum=11
http://www.jikexueyuan.com/course/android/?pageNum=12
http://www.jikexueyuan.com/course/android/?pageNum=13
http://www.jikexueyuan.com/course/android/?pageNum=14
http://www.jikexueyuan.com/course/android/?pageNum=15
http://www.jikexueyuan.com/course/android/?pageNum=16
http://www.jikexueyuan.com/course/android/?pageNum=17
http://www.jikexueyuan.com/course/android/?pageNum=18
http://www.jikexueyuan.com/course/android/?pageNum=19
http://www.jikexueyuan.com/course/android/?pageNum=20
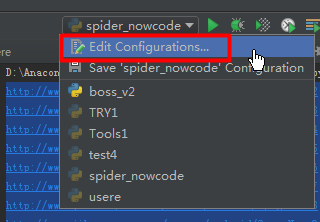
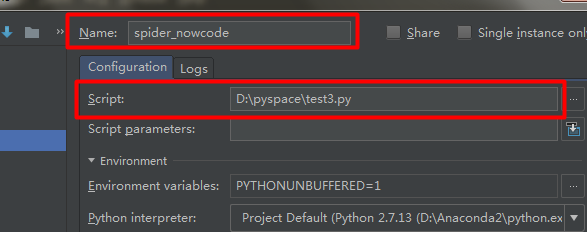
3.4 實戰——制作文本爬蟲
* 暫時使用“人肉爬蟲”;
* 手動將網頁【https://www.nowcoder.com/courses】源代碼保存到【nowcoder_source.txt】中。
* 運行前需要配置
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import re
import requests
f = open('nowcode_source.txt','r')
source_html = f.read() # html里是文本里的內容
f.close()
pic_url = re.findall('<div class="course-pic"><img src="(.*?)"',source_html,re.S)
i = 0
for each in pic_url:
print 'now downloading:' + each
pic = requests.get("http:"+each) # get每張圖片
fp = open("%d.jpg"%(i),'wb') # 強制全部以.jpg的格式保存了
fp.write(pic.content) # 保存到本地文件
fp.close()
i += 1圖片爬取成功

輸出
now downloading://static.nowcoder.com/live/4/217x145.png
now downloading://static.nowcoder.com/vod/7/217x145.png
now downloading://static.nowcoder.com/images/courselist/vod_course_chengyun_217x145.png
【# .…略…】
now downloading://uploadfiles.nowcoder.com/images/20170717/59_1500270283620_642FCEA8E7E6E7F22BA03B4FBD1612C0
now downloading://uploadfiles.nowcoder.com/images/20170717/59_1500270308088_08BF4382A2512CC13B0D0F81E84CFB4C
now downloading://uploadfiles.nowcoder.com/images/20170210/9859373_1486714945522_F0EE18EC0C3DB4D0103D98A142E6ED51
(二)【Requests 介紹和安裝】
3.5 Requests 介紹和安裝
1、Requests:HTTP for Humans
(1)完美替代Python的urllib2模塊
(2)更多的自動化
(3)更友好的用戶體驗
(4)更完善的功能
* 安裝方法:
Windows:pip install requests
Linux:sudo pip install requests
2、第三方庫安裝技巧
(1)少用easy_install 因為只能安裝不能卸載
(2)多用pip方式安裝
(3)撞墻了怎么辦?請戳-> http://www.lfd.uci.edu/~gohlke/pythonlibs/
* Ctrl+F搜索對應第三方庫,下載*.whl文件;
* 把后綴*.whl改為*.zip,解壓縮;
* 復制其中的request文件夾(另外兩個"request-xxx"不用復制)到python安裝目錄的Lib文件夾中(D:\python27\Lib)
3.6 第一個網頁爬蟲
* 使用Requests獲取網頁源代碼,再使用正則表達式匹配出感興趣的內容,這是單線程簡單爬蟲的基本原理。
(1)直接獲取源代碼
〖例〗爬取百度python吧首頁的源代碼http://tieba.baidu.com/f?ie=utf-8&kw=python
import requests
html = requests.get('http://tieba.baidu.com/f?ie=utf-8&kw=python')
print html.text(2)修改http頭獲取源代碼(反爬蟲)
* 按(1)中代碼若出現“403 Forbidden”則需要修改headers。
〖例〗爬取網頁http://jp.tingroom.com/yuedu/yd300p/
#! /usr/bin/env python2.7
# coding=utf-8
import requests
import re
# 下面三行是編碼轉換的功能,大家現在不用關心。
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
# headers是我們自己構造的一個字典,里面的key保存了user-agent
# 讓對方網站誤以為是一個瀏覽器在訪問,而不是一個爬蟲在訪問。
_headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36'}
html = requests.get('http://jp.tingroom.com/yuedu/yd300p/',headers = _headers)
html.encoding = 'utf-8' # 這一行是將編碼轉為utf-8否則中文會顯示亂碼。
print html.text # 獲取網頁的源代碼
# 使用正則表達式匹配內容
chinese = re.findall('color: #039;">(.*?)</a>',html.text,re.S)
for each in chinese:
print each* 如何獲取User-Agent
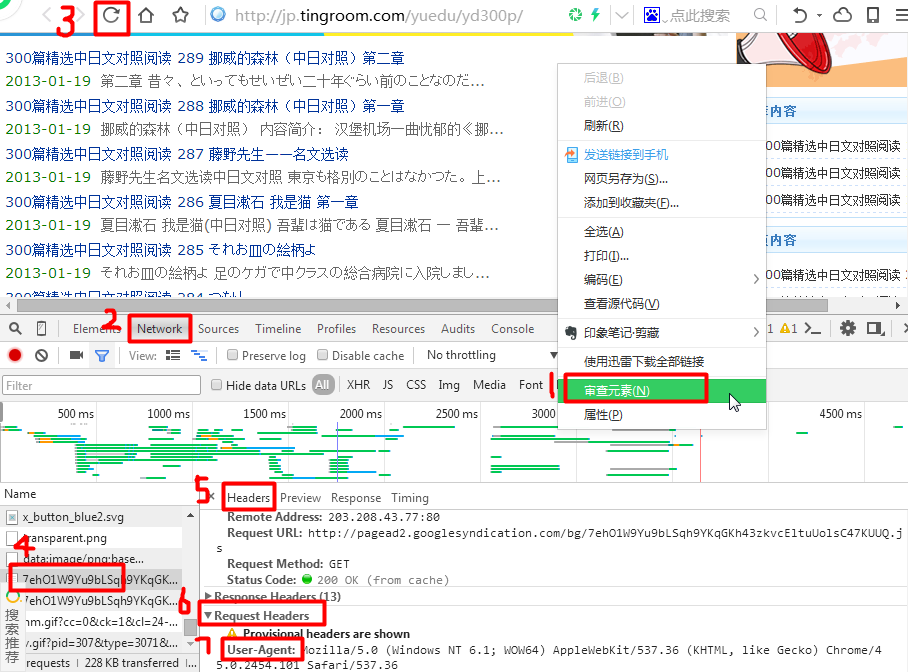
3.7 向網頁提交數據
【注:由于課程可能是前幾年出的,這一節中用到的網頁已經有變化,實際上不是視頻中出現的樣子了。
所以本節沒有進行實驗操作。以下部分圖片來自 視頻截圖,而不是我自己實際操作的截圖;沒有運行出一樣的結果不要覺得奇怪】
1、Get與Post介紹
(1)Get是從服務器上獲取數據;Get通過構造url中的參數來實現功能
(2)Post是向服務器傳送數據(并獲取它的返回值);Post將數據放在header提交數據
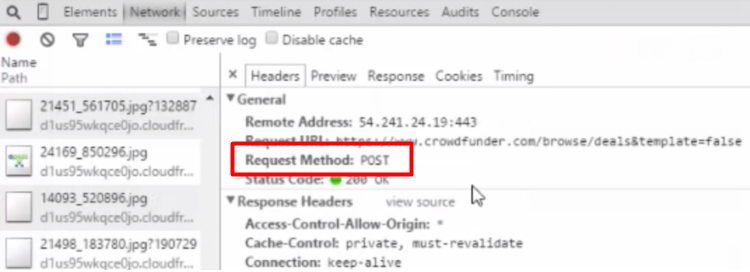
2、分析目標網站
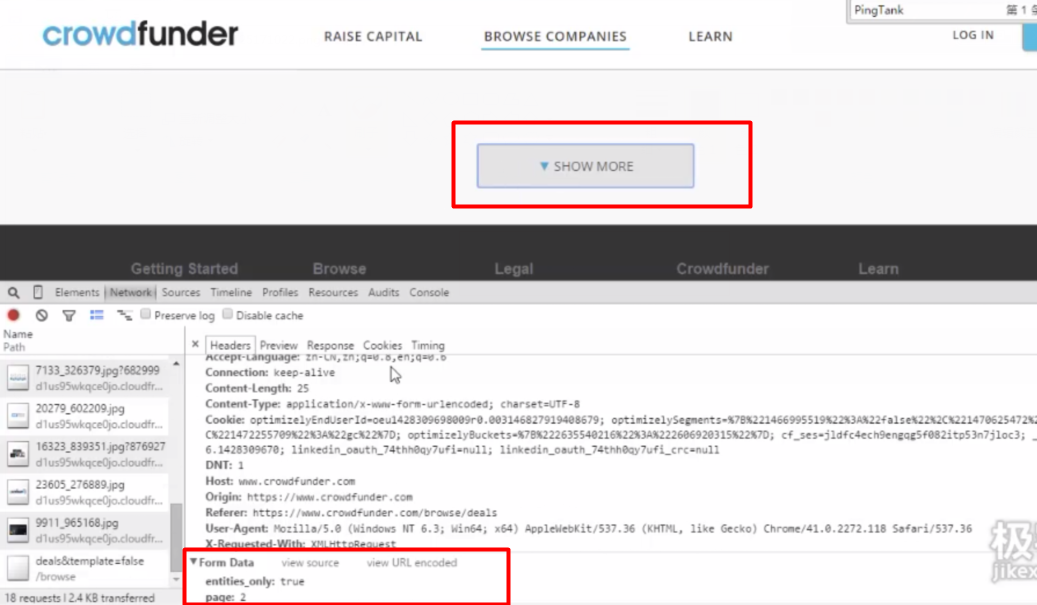
網站地址:https://www.crowdfunder.com/browse/deals
分析工具:Chrome-審核元素-Network
* 點擊show more 獲取更多信息;
* 因為是"異步加載",所以show more之后網址沒有變化;
* show more之后的內容在網頁源代碼中找不到;
3、Requests的表單提交
核心方法:request.post
核心步驟:構造表單-提交表單-獲取返回信息
#! /usr/bin/env python2.7
# coding=utf-8
import requests
import re
# url = 'https://www.crowdfunder.com/browse/deals'
url = 'https://www.crowdfunder.com/browse/deals&template=false'
# html = requests.get(url).text
# print html
# 注意這里的'true'是字符串;page后面跟的數字是字符不是數字1(加引號)。
data = {'entities_only': 'true', 'page': '3'} # data的值見上圖審查元素
html_post = requests.post(url, data=data)
title = re.findall('"card-title">(.*?)</div>', html_post.text, re.S)
for each in title:
print each3.8 實戰——極客學院課程爬蟲
目標網站:http://www.jikexueyuan.com/course/
目標內容:課程名稱,課程介紹,課程時間,課程等級,學習人數
涉及知識:Requests獲取網頁/ re.sub換頁/正則表達式匹配內容
#! /usr/bin/env python2.7
# coding=utf-8
import requests
import re
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
class spider(object):
def __init__(self):
print u'開始爬取內容。。。'
#getsource用來獲取網頁源代碼
def getsource(self,url):
html = requests.get(url)
return html.text
#changepage用來生產不同頁數的鏈接l
def changepage(self,url,total_page):
now_page = int(re.search('pageNum=(\d+)',url,re.S).group(1))
page_group = []
for i in range(now_page,total_page+1):
link = re.sub('pageNum=\d+','pageNum=%s'%i,url,re.S)
page_group.append(link)
return page_group # 返回所有頁碼的網址列表
#geteveryclass用來抓取每個課程塊的信息
def geteveryclass(self,source):
everyclass = re.findall('(<li deg="".*?</li>)',source,re.S)
return everyclass
#getinfo用來從每個課程塊中提取出我們需要的信息
def getinfo(self,eachclass):
info = {}
info['title'] = re.search('target="_blank">(.*?)</a>',eachclass,re.S).group(1)
info['content'] = re.search('</h2><p>(.*?)</p>',eachclass,re.S).group(1)
timeandlevel = re.findall('<em>(.*?)</em>',eachclass,re.S) # 分析中發現時間和等級的元素都在<em>標簽中,則本行匹配出兩個元素
info['classtime'] = timeandlevel[0]
info['classlevel'] = timeandlevel[1]
info['learnnum'] = re.search('"learn-number">(.*?)</em>',eachclass,re.S).group(1)
return info
#saveinfo用來保存結果到info.txt文件中
def saveinfo(self,classinfo):
f = open('info.txt','a') # 以追加打開文件
for each in classinfo:
f.writelines('title:' + each['title'] + '\n')
f.writelines('content:' + each['content'] + '\n')
f.writelines('classtime:' + each['classtime'] + '\n')
f.writelines('classlevel:' + each['classlevel'] + '\n')
f.writelines('learnnum:' + each['learnnum'] +'\n\n')
f.close()
if __name__ == '__main__': # 程序入口
classinfo = [] # 所有課程的信息的列表,每個課程的信息是一字典
url = 'http://www.jikexueyuan.com/course/?pageNum=1'
jikespider = spider() # 實例化了spider類
all_links = jikespider.changepage(url,20)
for link in all_links:
print u'正在處理頁面:' + link
html = jikespider.getsource(link)
everyclass = jikespider.geteveryclass(html) # 先抓大:獲取每個課程的代碼部分
for each in everyclass: # 再抓小:獲取每個課程的各個信息
info = jikespider.getinfo(each)
classinfo.append(info)
jikespider.saveinfo(classinfo)(三)【XPath 與多線程爬蟲】
3.9 神器 XPath 的介紹與配置
1、XPath(Xml Path Language/可擴展標記語言路徑語言 )
* XPath 是一門語言;可以在XML文檔中查找信息;支持HTML;通過元素和屬性進行導航
* 即:可以用來提取信息;比正則表達式厲害、簡單
【百度百科】XPath即為XML路徑語言,它是一種用來確定XML(標準通用標記語言的子集)文檔中某部分位置的語言。XPath基于XML的樹狀結構,提供在數據結構樹中找尋節點的能力。起初 XPath 的提出的初衷是將其作為一個通用的、介于XPointer與XSLT間的語法模型。但是
XPath 很快的被開發者采用來當作小型查詢語言。
2、如何安裝使用XPath
(1) 安裝lxml庫
(2) from lxml import etree
(3) Selector = etree.HTML(網頁源代碼) 【TIP: etree提供了HTML這個解析函數,現在我們可以直接對HTML使用xpath了】
(4) Selector.xpath(xxxxxx)
3.10 神器 XPath 的使用
(1)XPath與HTML結構——樹狀結構、逐層展開、逐層定位、尋找獨立節點
(2)獲取網頁元素的Xpath——手動分析法;Chrome生成法
(3)應用XPath提取內容
① //定位根節點
② /往下層尋找 (可以通過屬性定位標簽div[@id="xxx"])
③ 提取文本內容:/text()
④ 提取屬性內容: /@id
* 【注意對比以上兩種@的作用】
【過程:get網頁源碼 → etree分析源碼 → 指定xpath → 輸出內容】
#! /usr/bin/env python2.7
# coding=utf-8
from lxml import etree
html = '''
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title>測試-常規用法</title>
</head>
<body>
<div id="content">
<ul id="useful">
<li>這是第一條信息</li>
<li>這是第二條信息</li>
<li>這是第三條信息</li>
</ul>
<ul id="useless">
<li>不需要的信息1</li>
<li>不需要的信息2</li>
<li>不需要的信息3</li>
</ul>
<div id="url">
<a href="http://jikexueyuan.com">極客學院</a>
<a href="http://jikexueyuan.com/course/" title="極客學院課程庫">點我打開課程庫</a>
</div>
</div>
</body>
</html>
'''
selector = etree.HTML(html)
#提取文本
content = selector.xpath('//ul[@id="useful"]/li/text()') # 提取標簽中的內容,@:通過屬性定位標簽
for each in content:
print each
#提取屬性
link = selector.xpath('//a/@href')
for each in link:
print each
title = selector.xpath('//a/@title') # @:提取屬性的信息
print title[0]輸出
這是第一條信息
這是第二條信息
這是第三條信息
http://jikexueyuan.com
http://jikexueyuan.com/course/
極客學院課程庫
3.11 神器 XPath 的特殊用法
1、以相同的字符開頭
[starts-with(@屬性名稱, "屬性字符相同部分")]
〖例〗//div[starts-with(@id,"test")]/text()
<div id="test-1">需要的內容1</div>
<div id="test-2">需要的內容2</div>
<div id="testfault">需要的內容3</div>
#! /usr/bin/env python2.7
# coding=utf-8
from lxml import etree
html1 = '''
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<div id="test-1">需要的內容1</div>
<div id="test-2">需要的內容2</div>
<div id="testfault">需要的內容3</div>
</body>
</html>
'''
selector = etree.HTML(html1)
content = selector.xpath('//div[starts-with(@id,"test")]/text()')
for each in content:
print each需要的內容1
需要的內容2
需要的內容3
2、標簽套標簽
string(.)
#! /usr/bin/env python2.7
# coding=utf-8
from lxml import etree
html2 = '''
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<div id="test3">
1明月幾時有?
<span id="tiger">
2把酒問青天。
<ul>3不知天上宮闕,
<li>4今夕是何年。</li>
</ul>
5我欲乘風歸去,
</span>
6又恐瓊樓玉宇。
</div>
</body>
</html>
'''
selector = etree.HTML(html2)
content_1 = selector.xpath('//div[@id="test3"]/text()') # 這樣只能提取當前id的div內容,而無法獲得嵌套標簽的內容
for each in content_1:
print each
print "————————————"
data = selector.xpath('//div[@id="test3"]')[0] # 先取大獲得test3標簽內的所有內容
info = data.xpath('string(.)') # 再對test這個div內的內容使用xpath為string(.),獲取全部文本
content_2 = info.replace('\n','').replace(' ','') # 轉換文本中的回車&空格
print content_2
1明月幾時有?
6又恐瓊樓玉宇。
————————————
1明月幾時有?2把酒問青天。3不知天上宮闕,4今夕是何年。5我欲乘風歸去,6又恐瓊樓玉宇。
〖分析〗在info 之后設一個斷點,觀察info的值:包含了文本以及回車、空格

3.12 Python 并行化介紹與演示
1、Python并行化介紹——多個線程同時處理任務、高效、快速
2、Map的使用(在此僅作了解,之后會在框架中學到更高效的多線程爬蟲)
* map 函數一手包辦了序列操作、參數傳遞和結果保存等一系列的操作。
① from multiprocessing.dummy import Pool
② pool = Pool(4) #四核計算機寫4,八核計算機寫8,效率更高
③ results = pool.map(爬取函數, 網址列表)
#! /usr/bin/env python2.7
# coding=utf-8
from multiprocessing.dummy import Pool as ThreadPool
import requests
import time
def getsource(url): # get網頁源代碼
html = requests.get(url)
urls = [] # 【單線程爬取】,存放20個地址到urls列表
for i in range(1,21): # 生成20個地址
newpage = 'http://tieba.baidu.com/p/3522395718?pn=' + str(i)
urls.append(newpage)
time1 = time.time()
for i in urls:
print i
getsource(i) # 對urls中的20個地址爬取源碼
time2 = time.time()
print u'單線程耗時:' + str(time2-time1)
pool = ThreadPool(4) # 【并行化爬取】,初始化實例
time3 = time.time()
results = pool.map(getsource, urls) # 使用map連接自定義的getsource函數以及urls列表,進行多線程爬取
pool.close()
pool.join() # join()方法表示等待子進程結束以后再繼續往下運行,通常用于進程間的同步。
time4 = time.time()
print u'并行耗時:' + str(time4-time3)單線程耗時:6.60800004005
并行耗時:2.01599979401
3.13 實戰——百度貼吧爬蟲
目標網站:http://tieba.baidu.com/p/3522395718
目標內容:跟帖用戶名,跟帖內容,跟帖時間
涉及知識:Requests獲取網頁;XPath提取內容;map實現多線程爬蟲
#! /usr/bin/env python2.7
# coding=utf-8
from lxml import etree
from multiprocessing.dummy import Pool as ThreadPool
import requests
import json # 貼吧的編碼為 JSON 格式數據
import sys # 把編碼強制轉換為utf-8,才能正確輸出文本
reload(sys)
sys.setdefaultencoding('utf-8')
'''重新運行之前請刪除content.txt,因為文件操作使用追加方式,會導致內容太多。'''
def towrite(contentdict):
f.writelines(u'回帖時間:' + str(contentdict['topic_reply_time']) + '\n')
f.writelines(u'回帖內容:' + unicode(contentdict['topic_reply_content']) + '\n')
f.writelines(u'回帖人:' + contentdict['user_name'] + '\n\n')
def spider(url):
html = requests.get(url) # get網頁源碼
selector = etree.HTML(html.text) # etree提供了HTML這個解析函數,現在我們可以直接對HTML使用xpath了
content_field = selector.xpath('//*[@class="l_post j_l_post l_post_bright "]') # 先抓大,整體抓取每一條回帖包含所有信息標簽的內容
item = {}
for each in content_field:
reply_info = json.loads(each.xpath('@data-field')[0].replace('"','')) # 對每貼回帖內容信息再次xpath,此時不需要//;信息在屬性中:轉換一個轉義字符為空
author = reply_info['author']['user_name']
# content = each.xpath('div[@class="d_post_content_main"]/div/cc/div/text()')
content_1 = each.xpath('div[@class="d_post_content_main"]/div/cc/div')[0]
content_2 = content_1.xpath("string(.)") # 由于某些用戶的文本有被附加的邊框效果修飾,會多嵌套一層<div>,所以用string(.)解決嵌套標簽的文本
content = content_2.replace(' ','') # 每行前面有多個空格,將空格刪除
reply_time = reply_info['content']['date']
print 1,content
print 2,reply_time
print 3,author,"\n"
item['user_name'] = author # 將信息寫入字典
item['topic_reply_content'] = content
item['topic_reply_time'] = reply_time
towrite(item) # 將字典傳給towrite準備寫入文件
if __name__ == '__main__':
pool = ThreadPool(4)
f = open('content.txt','a') # 以追加形式打開文件content.txt
page = [] # 生成網頁的前20頁的地址,存入page
for i in range(1,21):
newpage = 'http://tieba.baidu.com/p/3522395718?pn=' + str(i)
print newpage
page.append(newpage)
results = pool.map(spider, page) # 連接20個地址與spider函數進行多線程爬取
pool.close()
pool.join()
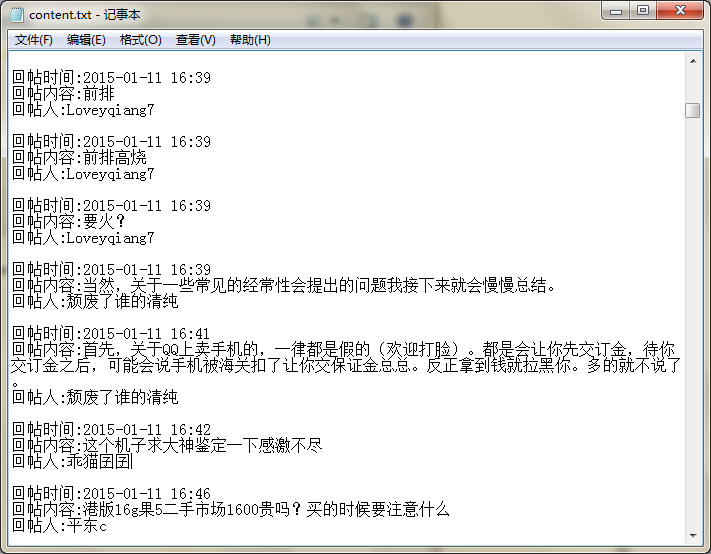
f.close()輸出(僅截取部分)

輸出的content.txt文本
智能推薦

Python爬蟲入門筆記
本來想著導師做C#的,一門心思先扎進去再說,但是一直沒有項目實踐的話,怕是會覺得越來越枯燥。索性先學學Python,畢竟以后每種類型的編程語言還是都要了解的。加上同學在研究這個,也有個討論的。 1.requests庫 python庫的通用安裝方法吧 2.beautifulsoup庫 參數1,html格式的內容;參數2,html解析器...
Python爬蟲入門筆記
最近又學了一遍爬蟲的入門,記住步驟立刻就上手了 爬蟲四大步驟 1.獲取頁面源代碼 2.獲取標簽 3.正則表達式匹配 4.保存數據 1.獲取頁面源代碼 5個小步驟: 1.偽裝成瀏覽器 2.進一步包裝請求 3.網頁請求獲取數據 4.解析并保存 5.返回數據 代碼: 2.獲取標簽 通過BeautifulSoup進一步解析頁面源代碼 Beautiful Soup 將復雜 HTML 文檔轉換成一個復雜的樹形...
Python爬蟲筆記——爬蟲入門
一、爬蟲 爬蟲是什么 我們把互聯網有價值的信息都比喻成大的蜘蛛網,而各個接地那就是存放的數據,而蜘蛛網上的蜘蛛比喻成爬蟲,而爬蟲是可以自動抓取互聯網信息的程序,從互聯網上抓取一切有價值的信息,并把站點的html和js返回的圖片爬到本地,并存出起來。 爬蟲用途 爬取網站信息數據,12306搶票,網絡投票等。 二、BeautifulSoup使用 BeautifulSoup是一個可以從HTML或XML文...

Python極簡入門(三)
廣播Broadcasting 廣播可以讓Numpy不同大小的矩陣進行數學計算,e.g.把一個向量加到矩陣每一行 但是當x非常大,上述運算就會很慢,另一種思路: 使用numpy的廣播機制就很直接了: 對兩個數組使用廣播也要遵守一定的規則: 1)如果數組的秩不同,使用1將秩較小的數組進行擴展,知道兩個數組的尺寸一樣。 2)如果兩個數組某個維度的長度一樣或者其中一個數組在某維度上長度為1,那么我們說兩個...

猜你喜歡

freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...