01_爬蟲入門級教程__什么是爬蟲?
文章目錄
一.初探數據
概述
爬蟲通俗的講呢就是能夠自動訪問互聯網并將網站內容下載下來的程序或腳本,類似一個機器人,能夠把別人網站的信息弄到電腦上,在做一些過濾,篩選,歸納,整理,排序等。
網絡爬蟲又名Web Spider,即把互聯網比喻成一個蜘蛛網,那么spider就是在網上爬來爬去的蜘蛛。網絡蜘蛛就是通過網頁的連接來尋址網頁,從網站的某個頁面(通常是首頁)開始,讀取網頁的內容,找到在網頁中的其他連接地址,然后通過這些連接地址尋找下一個網頁,這樣一直循環,直到把這個網站所有網頁都抓取完為止。
如果把整個互聯網當成一個網站,那么爬蟲就可以用這個原理把互聯網上所有的網頁抓取下來。
編程語言
本次教程使用的是python,這是菜鳥教程python的連接,有需要的讀者可以移步做進一步了解。
爬蟲平臺
Pycharm官網鏈接傳送門
二.前提知識
URL
Universal Resource Locator 即統一資源定位符)URL 是對能從 Internet 上得到資源的位置和訪問方法的一種簡潔的表示。URL 給資源的位置提供一種抽象的識別方法,并用這種方法給資源定位,使得系統得以對資源(指 Internet 上可以訪問的任何對象,包括文件目錄、文件、文檔、圖像等,以及其他任何形式的數據)進行各種操作,如存儲、更新、替換和查找其屬性。
<URL 的訪問形式>://<主機>:<端口>/<路徑>
左邊的<URL 的訪問形式>主要有文件傳送協議(FTP)、超文本傳送協議(HTTP)等方式,常見形式為 HTTP,下面將會介紹到。<主機>一項是必須的,<端口>和<路徑>有時侯可省略。
HTTP
HTTP(HyperText Transfer Protocol 即超文本傳輸協議)是一個簡單的請求——響應協議,通常運行在 TCP 之上,它指定了客戶端可能發送給服務器的消息,以及得到的響應。(3)HTML
HTML
HTML(HyperText Markup Lanhguage 即超文本標記語言)是一種制作萬維網頁面的標準語言,它消除了計算機信息交流的障礙。HTML 定義了許多用于排版的”標簽“,各種標簽嵌入到萬維網的頁面就構成了 HTML 文檔,所要爬取的頁面也基本是 HTML 網頁。
三.請求
請求,由客戶端向服務器發出。常用的兩種請求有 get 和 post。get 一般用來獲取數據、 post 用來提交數據。
一個請求包含三個要素,分別是:
○1請求方法 URI 協議/版本
○2請求頭(Request Header)
○3請求正文
四.響應
響應(Response),由服務器構造 POST 請求,需要使用正確的 Content-Type,并了解各種請求庫的各個參數設置時使用的是哪種 Content-Type,不然可能會導致 POST 提交后無法正常響應。
○1響應狀態
200:成功
301:跳轉
404:找不到頁面
502:服務器錯誤
○2響應頭:如內容類型,內容長度,服務器信息,設置 cookie 等
○3響應體:最主要部分,包含了請求資源內容,如網頁 HTML,圖片,二進制數劇等
五.基本庫
requests 是 python 實現的簡單易用的 HTTP 庫,使用起來比 urllib 簡潔很多,所以在次教程只講解 Requests 庫。
requests安裝
(1)因為是第三方庫,所以使用前需要 cmd 安裝。
pip3 install requests
命令行操作如下:
先找到我的電腦中pip3的安裝路徑
 進入目錄下安裝
進入目錄下安裝
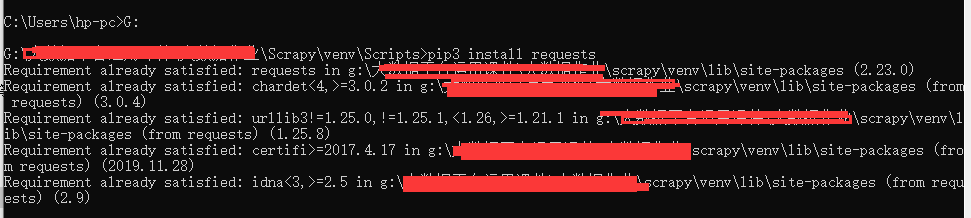 我是已經安裝過所以顯示已安裝,這里就是演示一下。
我是已經安裝過所以顯示已安裝,這里就是演示一下。
接下來進入pycharm
基本用法
(2)基本用法:requests.get()用于請求目標網站。
寫入代碼
import requests
response = requests.get('http://www.baidu.com')
print(response.status_code) #打印狀態碼
print(response.url) #打印請求 url
print(response.headers) #打印頭信息
print(response.cookies) #打印 cookie 信息
print(response.text) #以文本形式打印網頁源碼 print(response.content) #以字節流形式打印
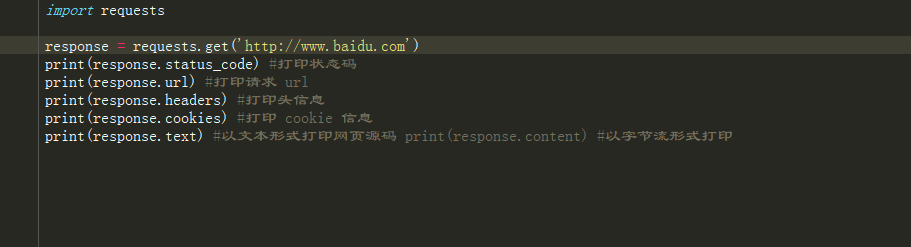
運行結果如下:
 還記得我們在響應板塊談到的響應狀態為200就代表成功嗎
還記得我們在響應板塊談到的響應狀態為200就代表成功嗎
(3)各種請求方式
import requests
requests.get('http://httpbin.org/get')
requests.post('http://httpbin.org/post')
requests.put('http://httpbin.org/put')
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/get')
requests.options('http://httpbin.
六.解析庫
解析庫有 Xpath、Pyquery、BeautifulSoup 等。Xpath,全稱 XML Path Language,即 XML 路徑語言,它是一門在 XML 文檔中查找信息的語言,Xpath 可用來在 XML 文檔中對元素和屬性進行遍歷;如果你比較喜歡用 CSS 選擇器,那么推薦你使用 Pyquery;BeautifulSoup 是個強大的解析工具,它借助網頁的結構和屬性等特征來解析網頁,提供一些簡單的、python式的函數用來處理導航、搜索、修改分析樹等功能。
BeautifulSoup
下面來講解BeautifulSoup 的一些基本用法。
(1)安裝
pip3 install beautifulsoup4
像安裝requests一樣在命令行安裝!
(2)導入 bs4 庫
from bs4 import BeautifulSoup
(3)先創建一個字符串
html = '''
<html>
<body>
<h1 id="title">Hello World</h1>
<a href="#link1" class="link">This is link1</a> <a href="#link2" class="link">This is link2</a>
</body>
</html>
'''
(4)創建 beautifulsoup 對象
soup = BeautifulSoup(html)
(5)打印一下 soup 對象的內容,格式化輸出.
print soup.prettify()
完整代碼如下:
from bs4 import BeautifulSoup
html = '''
<html>
<body>
<h1 id="title">Hello World</h1>
<a href="#link1" class="link">This is link1</a> <a href="#link2" class="link">This is link2</a>
</body>
</html>
'''
soup = BeautifulSoup(html,"html.parser")
print (soup.prettify()) #g個死話輸出
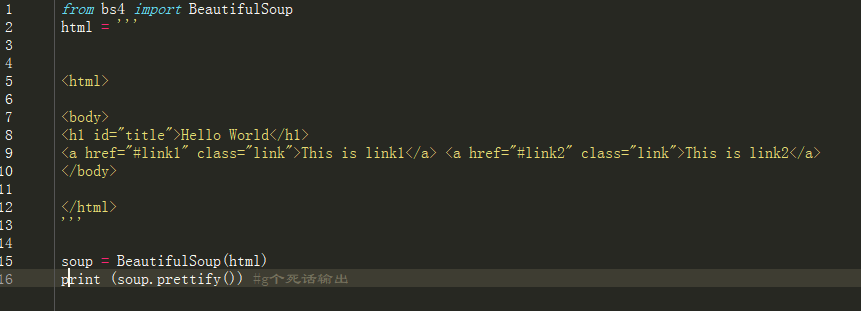
輸出結果如下:
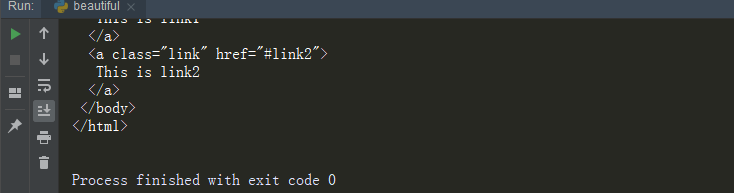
格式化完整輸出soup對象
(6)Soup.select()函數用法
獲取指定標簽的內容
代碼如下:
from bs4 import BeautifulSoup
html = '''
<html>
<body>
<h1 id="title">Hello World</h1>
<a href="#link1" class="link">This is link1</a> <a href="#link2" class="link">This is link2</a>
</body>
</html>
'''
soup = BeautifulSoup(html,"html.parser")
header = soup.select('h1')
print (type(header))
print (header)
print (header[0])
print (type(header[0]))
print (header)
輸出如下:
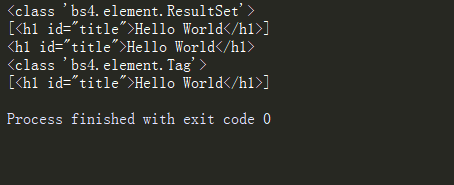
獲取指定標簽的位置用#
title = soup.select('#title')
print type(title)
print title[0].text
輸出:
<type 'list'>
Hello World
find函數
(7)Soup.find()和 soup.find_all()函數用法
(1)find()和 find_all()函數原型:
find 和 find_all 函數都可根據多個條件從 html 文本中查找標簽對象,只不過 find 的返回對象類型為 bs4.element.Tag,為查找到的第一個滿足條件的 Tag;而 find_all 的返回對象為bs4.element.ResultSet(實際上就是 Tag 列表),這里主要介紹 find 函數,find_all 函數類似。
find(name=None,attrs={},recursive=True,text=None,**kwargs)
find_all(name=None,attrs={},recursive=True,limit=None,**kwargs)
注:其中 name、attrs、text 的值都支持正則匹配。
獲取指定標簽的內容:
from bs4 import BeautifulSoup
html = '<p><a href="www.test.com" class="mylink1 mylink2">this is mylink</a></p>'
soup = BeautifulSoup(html,"html.parser")
a1 = soup.find('a')
print (type(a1))
輸出結果如下:

再來
from bs4 import BeautifulSoup
html = '<p><a href="www.test.com" class="mylink1 mylink2">this is mylink</a></p>'
soup = BeautifulSoup(html,"html.parser")
a1 = soup.find('a')
print (a1.name)
print (a1['href'])
print (a1['class'])
print (a1.text)
輸出結果

代碼要自己敲,多體會find函數的用法還有代碼格式和輸入一定要在英文輸入法的前提下輸入
多個條件的正則匹配:
代碼如下:
from bs4 import BeautifulSoup
import re
html = '<p><a href="www.test.com" class="mylink1 mylink2">this is mylink</a></p>'
soup = BeautifulSoup(html,"html.parser")
a2 = soup.find(name=re.compile(r'\w+'), class_=re.compile(r'mylink\d+'),text = re.compile(r'^this.+link$'))
print (a2)
運行結果如下:

find 函數的鏈式調用
代碼如下:
from bs4 import BeautifulSoup
import re
html = '<p><a href="www.test.com" class="mylink1 mylink2">this is mylink</a></p>'
soup = BeautifulSoup(html,"html.parser")
a3 = soup.find('p').find('a')
print (a3)
運行結果:

七.數據格式
(1)網頁文本:HTML 文檔,json 格式文件等。
(2)圖片:獲取到的是二進制文件,保存為圖片格式。
(3)視頻:同為二進制文件,保存為視頻模式即可。
(4)其他。
八.保存數據的方式
(1)文本:純文本,json,xml 等。
(2)關系型數據庫:mySQL,Oracle,SQLServer 等具有結構化表結構形式存儲。
(3)非關系型數據庫:MongoDB,Redis 等 key-value 形式存儲。
(4)二進制文件:如圖片,視頻,音頻等直接保存特定格式即可。
智能推薦


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...

猜你喜歡

Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...

統計學習方法 - 樸素貝葉斯
引入問題:一機器在良好狀態生產合格產品幾率是 90%,在故障狀態生產合格產品幾率是 30%,機器良好的概率是 75%。若一日第一件產品是合格品,那么此日機器良好的概率是多少。 貝葉斯模型 生成模型與判別模型 判別模型,即要判斷這個東西到底是哪一類,也就是要求y,那就用給定的x去預測。 生成模型,是要生成一個模型,那就是誰根據什么生成了模型,誰就是類別y,根據的內容就是x 以上述例子,判斷一個生產出...

styled-components —— React 中的 CSS 最佳實踐
https://zhuanlan.zhihu.com/p/29344146 Styled-components 是目前 React 樣式方案中最受關注的一種,它既具備了 css-in-js 的模塊化與參數化優點,又完全使用CSS的書寫習慣,不會引起額外的學習成本。本文是 styled-components 作者之一 Max Stoiber 所寫,首先總結了前端組件化樣式中的最佳實踐原則,然后在此基...

19.vue中封裝echarts組件
19.vue中封裝echarts組件 1.效果圖 2.echarts組件 3.使用組件 按照組件格式整理好數據格式 傳入組件 home.vue 4.接口返回數據格式...