scrapy框架簡介
標簽: python爬蟲
scrapy庫
scrapy庫的安裝
1,使用pip install scrapy安裝,但是因為來源于外網,網絡不穩定,所以很難安裝
2,使用anaconda安裝
? (1)安裝anaconda,按照這兩個博客① ②就可以,注意:添加環境變量的時候不需要在目錄名后面加上\
? (2)把anaconda連接到IDE上(我用的是pycharm),直接在interpreter里面勾選anaconda就好了
? (3)win開始位置打開anaconda navigator,更改安裝來源,換成國內鏡像地址,安裝scrapy包,安裝指導在此
? (4)在pycharm中導入看一看能不能用,沒有報錯,應該是ok了
爬蟲框架
-
爬蟲框架是實現爬蟲功能的一個軟件結構和功能組件集合
-
爬蟲框架是一個半成品,能夠幫助用戶實現專業網絡爬蟲
-
spiders是入口,item pipelines是出口,engine/downloader和scheduler是已有的功能實現,用戶不需要自己編寫;用戶需要自己編寫spiders和item pipelines模塊。由于用戶不需要自己編寫完整的程序,而只是對已有的框架進行局部調整,所以我們也把這種編寫方式稱為配置
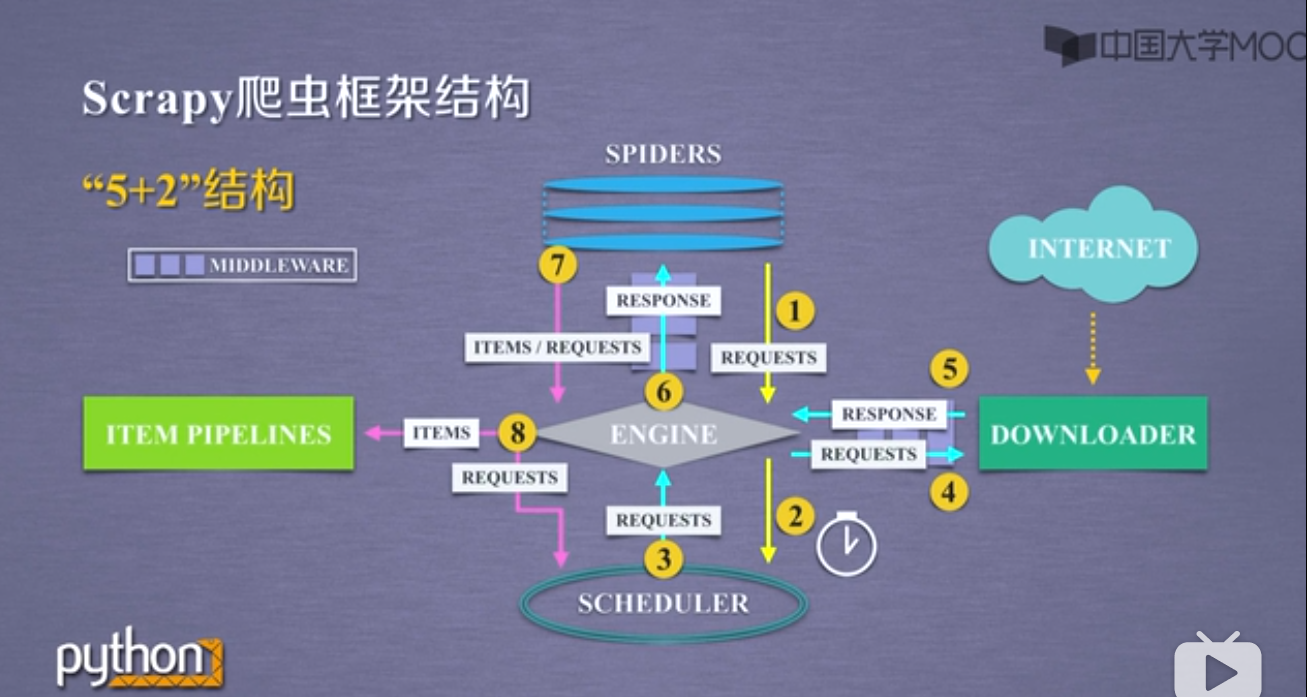
-
Engine,整個框架的核心,它控制所有模塊之間的數據流,根據條件觸發事件
-
Downloader模塊根據請求下載網頁,不需要用戶修改,功能單一
-
Scheduler模塊對所有的爬取請求進行調度管理,確定先后順序
-
在Engine和Downloader之間增加一個Downloader Middleware,實施Engine,Scheduler和Downloader之間用戶可配置的控制,因為如果三個模塊都是自動運行的,那么就沒用戶什么事了,功能是修改、丟棄、新增請求或者響應
-
Spider模塊解析Doenloader返回的響應(response),產生爬取項(scraped item)并產生額外的爬取請求(request),用戶主要編寫的就是這個模塊
-
item pipelines以流水線的方式處理spider模塊產生的爬取項,它由一組操作順序組成,類似于流水線,每個操作是一個item pipeline類型,可能的操作包括清理、檢驗和查重爬取項中的HTML數據、將數據儲存到數據庫,完全需要由用戶配置
-
在spider和engine之間有一個中間鍵spider middlewire,它的目的是對請求和爬取項進行再處理,功能包括修改、丟棄、新增請求或爬取項,用戶可以編寫配置代碼
-
requests庫和scrapy框架的比較
- 相同點
- 兩者都可以進行頁面請求和爬取,是python爬蟲的兩個重要技術路線
- 兩者可用性都好,文檔豐富,入門簡單
- 兩者都沒有處理js、提交表單、應對驗證碼等功能,需要加入其它的庫
- 不同點
- r是頁面級爬蟲;s是網站級爬蟲
- r是功能庫,主要由函數構成;s是一個框架,重點不在函數
- r并發性考慮不足,性能較差;s并發性好,性能較高
- r重點在于頁面下載;s重點在于爬蟲結構
- r定制靈活;s一般定制靈活,深度定制困難
- r上手十分簡單;s入門稍難
- 庫的選取
- 非常小的需求,使用r庫
- 不太小的需求,使用s庫,即反復爬取、積累信息類
- 如果需要定制很高的需求(不考慮規模),則需要自己搭建框架,使用r庫
- 相同點
srcapy庫的常用命令
cmd中輸入 scrapy -h打開scrapy命令行,它通過命令行操作而不是圖形界面
scrapy命令行格式:
>scrapy<command>[options][args]
具體命令在command中,常用命令包括6個:
| 命令 | 說明 | 格式 |
|---|---|---|
| startproject | 創建一個新工程 | scrapy startproject<name>[dir] |
| genspider | 創建一個爬蟲 | scrapy genspider[options]<name><domain> |
| settings | 獲取爬蟲配置信息 | scrapy settings[options] |
| crawl | 運行一個爬蟲 | scrapy crawl<spider> |
| list | 列出工程中所有爬蟲 | scrapy list |
| shell | 啟動URL調試命令行 | scrapy shell[url] |
scrapy實例
演示頁面的地址:http://python123.io/ws/demo.html
cmd中cd到指定目錄,然后scrapy startproject python123創建一個scrapy文件
生成的工程目錄
- python123 -->外層目錄
- scrapy.cfg scrapy的配置文件,就是把爬蟲放在服務器上并在服務器上配置好相關的操作接口,對于這個實例,不需要配置
- python123 scrapy框架的用戶自定義python代碼
- _init_.py初始化腳本,不需要用戶編寫
- items.py Items代碼模版,需要繼承scrapy提供的Item類,一般不需要用戶編寫
- middlewares.py Middlewares代碼模版,需要繼承類
- pipelines.py,pipelilnes代碼模版(繼承類)
- settings.py scrapy爬蟲的配置文件
- spiders,spiders代碼模塊
- _init_.py 初始文件,無須修改
- _pycache_/ 緩存目錄,無需修改
生成一個爬蟲
cmd到先前目錄中,使用scrapy genspider X python123.io,生成一個叫做X的爬蟲,然后會在spiders的目錄下生成一個spiders.py,實際上也可以手工生成
- 這個DemoSpider是繼承scrapy.Spider的子類
- name是爬蟲的名字
- allowed_domains是域名,指定爬蟲只能爬取這個域名以下的相關鏈接
- start_urls以列表形式包含一個或多個url,就是scrapy框架所要爬取頁面的初始頁面
- parse是解析頁面的空的方法,用于處理響應,解析內容形成字典,發現其中新的URL爬取請求
配置產生的spiders爬蟲
就是編寫demo.py
- allowed_domains不需要,可以注釋掉
- 修改start_urls,修改為我們需要訪問的http://python123.io/ws/demo.html
- 更改爬取方法的具體功能,爬取方法有2個參數一個是self,是面向對象類所屬關系的標記,還有一個是response,相當于從網絡中返回內容所存儲的或對應的對象,這里我們要把response中內容寫到一個html文件中,首先定義這個文件的名字
運行爬蟲,獲取文件
cmd中使用crawl命令執行,存儲的文件在demo.html中
這是一個簡化版的代碼
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
# allowed_domains = ['python123.io']
start_urls = ['http://python123.io/ws/demo.html']
def parse(self, response):
#從響應的url中提取文件名字,作為保存問本地的文件名
fname = response.url.split('/')[-1]
#將返回的內容保存為文件
with open(fname,'wb') as f:
f.write(response.body)
self.log('Saved file %s.'% fname) #在self中記錄日志
完整版的代碼:
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
def start_requests(self):
urls =[
'http://python123.io/ws/demo.html'
]
for url in urls:
yield scrapy.Requests(url = url,calssback = self.parse)
def parse(self,response):
fname = response.url.split('/')[-1]
with open(fname,'wb') as f:
f.write(response.body)
self.log('Saved file %s.'%fname)
yield關鍵字的使用
生成器:是一個不斷產生值的函數,包含yield語句的函數就是一個生成器,生成器每次產生一個值(yield語句),函數被凍結,被喚醒后再產生一個值,而生成器喚醒時,它所使用的局部變量的值與之前執行所使用的值是一致的,也就是說一個函數執行到某一個位置,產生了一個值,然后它被凍結,再次被喚醒的時候繼續從這個位置去執行,每次執行的時候都產生一個數據,這樣這個函數不停執行就產生了源源不斷的數據,這樣的函數就叫生成器
栗子:
def gen(n):
for i in range(n):
yield i**2 #這一行產生的值會被返回
for i in gen(5):
print(i," ",end = "")
生成器相比于普通寫法(一次列出所有內容)的優勢:
更節省存儲空間;響應更迅速;使用更靈活
scrapy爬蟲的基本使用
-
創建一個工程和Spider模版
-
編寫spider模版
-
編寫Item pipeline
-
優化策略配置
-
scapy爬蟲的數據類型
-
Request類,代表向網絡上提交請求的內容,request對象是一個http請求,它由spider生成,并由downloader執行
屬性或方法 說明 .url Request對應的請求URL地址 .method 對應的請求方法,‘GET’'POST’等等 .headers 字典類型風格的請求頭 .body 請求內容主體,字符串類型 .meta 用戶添加的擴展信息,在scrapy內部模板間傳遞信息使用 .copy() 復制該請求 -
Response類,表示從網絡中爬取內容的封裝類,由downloader生成,由spider處理
屬性或方法 說明 .url Response對應的URL地址 .status HTTP狀態碼,默認是200 .headers Response對應的頭部信息 .body Response對應的內容信息,字符串類型 .flags 一組標記 .request 產生Response類型對應的Request對象 .copy() 復制該響應 -
Item類,由spider產生的信息封裝而來的類,表示從HTML頁面中提取的信息內容,由spider生成,由Itempipeline處理,item類似字典類型,可以按照字典類型操作
-
-
scrapy爬蟲提取信息的方法
- scrapy爬蟲支持多種HTML信息提取方法
- Beautiful Soup
- lxml
- re
- XPath Selector
- CSS Selector
- CSS Selector的基本使用
- 使用格式:<HTML>.css(‘a::attr(href)’).extract(),其中a是標簽名稱,attr(href)是標簽屬性,這樣可以獲得對應的標簽信息
- CSS Selecter由W3C組織維護并規范
- scrapy爬蟲支持多種HTML信息提取方法
股票數據scrapy實例
功能描述:
? 技術路線;scrapy
? 目標:獲取上交所和深交所所有股票的名稱和交易信息
? 輸出:保存到文件中
? 數據網站:
? 獲取股票列表用東方財富網
? 獲取個股信息使用百度股票和單個股票
? 步驟:
? 1,建立工程和spider模版
? 2,編寫Spider,包括配置stocks.py文件,修改對返回頁面的處理,修改對(可能)新增URL爬取請求的處理
? 3,編寫ITEM Pipelines
? 4,在setting.py中修改ITEM_PIPELINES,將自己定義的BaidustocksInfoPipeline寫入配置文件中
? 5,crawl執行命令
stocks.py文件
# -*- coding: utf-8 -*-
import scrapy
import re
class StocksSpider(scrapy.Spider):
name = 'stocks'
# allowed_domains = ['baidu.com']
start_urls = ['http://quote.eastmoney.com/stock_list.html']
def parse(self, response):
#對頁面的a標簽進行提取
for href in response.css('a::attr(href)').extract():
try:
#獲取了單一股票的代碼
stock = re.findall(r"\d{6}",herf)[0]
#生成百度個股的對應鏈接
url = 'https://gupiao.baidu.com/stock/' + stock + '.html'
#將這個url重新提交給scrapy框架,callback給出了對這個頁面的處理函數,定義了一個新的處理函數parse_stock()
yield scrapy.Request(url,callback = self.parse_stock)
except:
continue
def parse_stock(selfself,response):
infoDict= {} #因為要提交給itempipeline,所以要先生成一個空的字典
stockInfo = response.css('.stock-bets')#找到數據區域
name = stockInfo.css('.bets-name').extract() #拿到股票的名字
keyList = stockInfo.css('dt').extract()
valueList = stockInfo.css('dd').extract()
#將提取的信息保存在字典中
for i in range(len(keyList)):
key = re.findall(r'>.*</d>',keyList[i])[0][1:-5]
try:
val = re.findall(r'\d+\.?.*</dd>',valueList[i])[0][0:-5]
except:
val = '--'
infoDict[key] = val
infoDict.update(
{'股票名稱':re.findall('\s.*\(',name)[0].split()[0] + \
re.findall('\>.*\<',name)[0][1:-1]})
yield infoDict
pipeline.py文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
class BaidustocksPipeline(object):
def process_item(self, item, spider): #打開spider時使用的方法
return item
class BaidustocksInfoPipeline(object):
def open_spider(self,spider):
self.f = open('BaiduStockInfo.txt','w')
def close_spider(self,spider):
self.f.close()
def process_item(self,item,spider): #對每一個item項處理的方法
try:
line = str(dict(item)) + '\n'
self.f.write(line)
except:
pass
return item
實例優化,提高速度
配置并發聯結選項
settting.py
| 選項 | 說明 |
|---|---|
| CONCURRENT_REQUESTS | Downloader最大并發請求下載數量。默認32 |
| CONCURRENT_ITEMS | Item Pipeiline最大并發ITEM處理數量,默認100 |
| CONCURRENT_REQUESTS_PER_DOMAIN | 每個目標域名最大的并發請求數量,默認8 |
| CONCURRENT_REQUESTS_PER_IP | 每個目標IP最大的并發請求數量,默認0,非0有效 |
對于JavaScript頁面,可以引入第三方庫PhantomJS,這是一個輕量級的瀏覽器庫
可以在https://pypi.python.org上面看到一批以scrapy-*的第三方庫,是完善scrapy的功能單元
智能推薦
Scrapy框架簡介及第一個爬蟲
解析 Scrapy架構 組件(Scrapy Engine) 引擎負責控制數據流在系統中所有組件中流動,并在相應動作發生時觸發事件。 詳細內容查看下面的數據流(Data Flow)部分。 調度器(Scheduler) 調度器從引擎接受request并將它們入隊,以便之后引擎請求它們時提供給引擎 下載器(Downloader) 下載器負責獲取頁面數據兵器同給引擎,而后提供給spider Spider ...
【Python Scrapy 爬蟲框架】 1、簡介與安裝
0x00 簡介 下圖展示了 Scrapy 的體系結構及其組件概述,在介紹圖中的流程前,先來簡單了解一下圖中每個組件的含義。 Engine Engine 負責控制系統所有組件之間的數據流,并在某些操作發生時觸發事件。 Scheduler Scheduler 接收來自 Engine 的請求,并對請求進行排隊,以便稍后在 Engine 請求時提供這些請求。 Downloader Downloader 負...
Scrapy 框架
提問: 為什么使用scrapy框架來寫爬蟲 ? 在python爬蟲中:requests + selenium 可以解決目前90%的爬蟲需求,難道scrapy 是解決剩下的10%的嗎?顯然不是。scrapy框架是為了讓我們的爬蟲更強大、更高效。接下來我們一起學習一下它吧。 1.scr...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
猜你喜歡
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...

統計學習方法 - 樸素貝葉斯
引入問題:一機器在良好狀態生產合格產品幾率是 90%,在故障狀態生產合格產品幾率是 30%,機器良好的概率是 75%。若一日第一件產品是合格品,那么此日機器良好的概率是多少。 貝葉斯模型 生成模型與判別模型 判別模型,即要判斷這個東西到底是哪一類,也就是要求y,那就用給定的x去預測。 生成模型,是要生成一個模型,那就是誰根據什么生成了模型,誰就是類別y,根據的內容就是x 以上述例子,判斷一個生產出...