HashMap 源碼超詳細分析
標簽: Java 基礎知識 源碼分析 java hashmap
集合框架總體結構
Collection 頂層接口下細分為三個類型,分別為
- List,一種有序的集合。根據索引可以方便的插入,訪問。允許重復元素。
- LinkedList,較高性能的刪除插入操作,畢竟指針指一下就好了。
- ArrayList,根據下標的高性能隨機訪問。
- Vector,線程安全的和 ArrayList 幾乎功能一樣的結構。
- Set,存儲不重復元素的集合。通過 equals 方法來判斷
- HashSet,基于哈希表,保證存儲唯一元素的結構。
- TreeSet,底層利用了許多 TreeMap 的 API。
- Queue/Deque,Java 提供的標準隊列實現,其中 Deque 雙端隊列支持隊列的兩端操作。
- Map,最常用的鍵值對存儲結構。
- HashMap,提供高效的插入,訪問,無序存儲。
- LinkedHashMap,HashMap 的子類,保存了記錄的插入順序。一般通過 Iterator 去遍歷。
- Hashtable,線程安全的 HashMap,已經不建議使用。可以使用同步性能更高的** juc.ConcurrentHashMap**
- TreeMap,基于紅黑樹的映射結構, log(n) 時間復雜度的基本操作。提供順序訪問,通過指定的 Comparator 指定,默認升序。其 key 必須實現 Comparable 接口或傳入自定義的 Comparator。
(圖來自美團點評團隊)
常用類分析
對任何集合類的性能分析,具體場景中的適用情況,都不能脫離其底層數據結構的特點。
例如 ArrayList 底層采用動態數組實現,那對于保證有序的,且頻繁的插入刪除場景其性能是有限的。LinkedList 底層使用雙向鏈表,隨機訪問的性能就沒那么友好了。
HashMap
底層結構
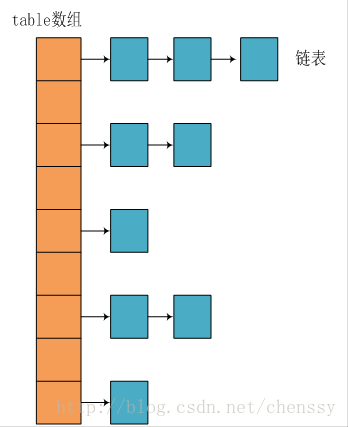
首先要知道的就是構成 HashMap 的內部結構,是 數組(Node<K,V>[] table) + 鏈表 + 紅黑樹(1.8 后引入)。
static class Node<K,V> implements Map.Entry<K,V> {}
HashMap 將要存儲的鍵值通過其哈希值確定元素在桶中存儲的位置。因為桶的位置有限,而要存儲的元素可能無限,所以不同的元素很可能被映射到同一個桶,就是我們常說的哈希沖突。
到這你就要想到為什么重寫了 equals 方法,對應的 hashCode 也需要重寫。 當一個類提供了自己的相等邏輯時(重寫了 equals 方法),這時如果沒有重寫 hashCode 方法,就無法保證兩個 equals 返回 true 的實例的 哈希值相同。
舉一個更新的例子,那么當使用該類作為哈希表的鍵值時就會出現預期外的行為。例如:
User userA = new User(24,"crayon"); // id,昵稱
Map<User,String> userMap = new HashMap<>();
userMap.put(userA,"用戶A");
//在下一次我們構建一個和 userA “邏輯相同”的對象去取值
User userB = new User(24,"crayon");
userMap.get(userB);
在我們調用 userMap 的 get 方法時,我們預期中返回的正確結果應該是 “crayon”,但很可能取出來的是一個 null。
關鍵在于,我們自己提供了對象“邏輯相等”的概念,但二者調用 hashCode 時返回的 hash 值卻不同。當去 get 的時候,根據 userB 的 hash 值找桶中的位置,而 Object 中默認的 hashCode 計算方法是隨著對象的內存地址在改變的,導致最終結果是定位不到 userA 存儲的桶位置。
重寫 hashCode 方法保證了 equals 相等時,調用 hashCode 返回的 int 值也相同
源碼分析
// The default initial capacity - MUST be a power of two.
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 結點樹化的閾值
static final int TREEIFY_THRESHOLD = 8;
// 退化為鏈表的閾值
static final int UNTREEIFY_THRESHOLD = 6;
// The smallest table capacity for which bins may be treeified.
// 就是說當桶的數目大于這個值是拉出來的鏈表才會樹化,不然就直接 resize。
static final int MIN_TREEIFY_CAPACITY = 64;
DEFFAULT_LOAD_FACTOR 一般叫負載因子,他是觸發哈希擴容的重要條件。
再看一個成員變量,size(哈希表實際存儲的元素個數)超過 threshold 就觸發擴容。
//The next size value at which to resize (capacity * load factor).
int threshold;
插入方法
看來秘密都在 putVal 中
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
建議自己去源碼再實際分析一遍
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 1. 空表的話,再去 resize() 進行初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 2. (n - 1) & hash 就是哈希尋桶位置的實現
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 3. 發生哈希沖突
else {
Node<K,V> e; K k;
// p - 已存儲元素,hash - 待存儲元素的哈希值
// 4. 判斷是不是相同的元素,是的話跳到 10.
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 5. 不同元素,是紅黑樹結構,調紅黑樹的插入
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 6.
else {
for (int binCount = 0; ; ++binCount) {
// 一直沒有重復元素,到末尾直接newNode 放進去就行
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 在遍歷鏈表的過程中,看有沒有重復元素,有的話跳出來
// 去 10. 處更新舊value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
// p = p.next
p = e;
}
}
// 10.
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
// 只有插入新的值才會改變 modCount
++modCount;
// size 有沒有超過 閾值
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
從 p = tab[i = (n - 1) & hash] 我們知道是通過 (n - 1) & hash 去把哈希值映射到數組下標中。n 是桶數組長度。
這里就解釋了為什么 HashMap 的桶長度 must be power of two.
當長度為 2 的冪時,其二進制表示中只有一位為 1,例如 16 表示為
0001 0000,32 表示為 0010 0000。那么對應為 n - 1時,其表示為
0000 1111。我們假設某個要存儲的哈希值的二進制表示為 1101 1001,是完全沒有規律的。那么當這兩個數做 與 操作(同 1 才為 1,否則為 0)時,
0000 1111
1101 1001
0000 1001
有沒有發現,高幾位的值不管哈希值是什么,都算出是 0,也就保證 & 出來的結果一定在桶長度內。(優化思路就是把簡單的取余操作換成位運算)
桶長度 must be power of two 還有一個好處,往下看你就知道了。
擴容方法
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超過最大長度了,隨你碰撞好了
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 可以看到,新的容量是舊容量的兩倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
// 初始化操作
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 計算哈希值的高一位是 0 還是 1
if ((e.hash & oldCap) == 0) { // 為 0
...
}
else { // 高一位為 1
...
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
// 高一位為 0 時,元素的存儲位置數組下標沒有變化
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 為 1,元素存儲位置為 舊數組下標 + 原容量 。
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
大家可以先自己思考一下為什么通過判斷(e.hash & oldCap) == 0 就能判斷擴容后元素的存儲位置。

有沒有看出來點什么?擴容前和擴容后的 & 計算值差別就只是元素 hash 值中和原容量 16 二進制表示中的那個 1 的位置是 0 還是 1 有關。
如果舊元素的二進制表示為 1100 1001,那么計算結果就是 0000 1001。
看到這說明你是一個一直在提高自己的人,給自己點個贊!
如果你覺得對你有幫助的話,也可以點贊支持一下。
智能推薦
HashMap源碼
HashMap源碼 HashMap 簡介 HashMap 主要用來存放鍵值對,它基于哈希表的Map接口實現,是常用的Java集合之一。 JDK1.8 之前 HashMap 由 數組+鏈表 組成的,數組是 HashMap 的主體,鏈表則是主要為了解決哈希沖突而存在的(“拉鏈法”解決沖突).JDK1.8 以后在解決哈希沖突時有了較大的變化,當鏈表長度大于閾值(默認為 8)時,將...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...
猜你喜歡


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...

統計學習方法 - 樸素貝葉斯
引入問題:一機器在良好狀態生產合格產品幾率是 90%,在故障狀態生產合格產品幾率是 30%,機器良好的概率是 75%。若一日第一件產品是合格品,那么此日機器良好的概率是多少。 貝葉斯模型 生成模型與判別模型 判別模型,即要判斷這個東西到底是哪一類,也就是要求y,那就用給定的x去預測。 生成模型,是要生成一個模型,那就是誰根據什么生成了模型,誰就是類別y,根據的內容就是x 以上述例子,判斷一個生產出...

styled-components —— React 中的 CSS 最佳實踐
https://zhuanlan.zhihu.com/p/29344146 Styled-components 是目前 React 樣式方案中最受關注的一種,它既具備了 css-in-js 的模塊化與參數化優點,又完全使用CSS的書寫習慣,不會引起額外的學習成本。本文是 styled-components 作者之一 Max Stoiber 所寫,首先總結了前端組件化樣式中的最佳實踐原則,然后在此基...
