Python 爬蟲:Scrapy 框架入門初探【 Xpath 改寫】
Scrapy 是一種用于抓取網站和提取結構化數據的應用程序框架,可用于廣泛的有用應用程序,如數據挖掘、信息處理或歷史存檔等。
安裝 Scrapy
從 PyPI 安裝:
pip install Scrapy
使用 Anaconda 或 Miniconda 安裝:
conda install -c conda-forge scrapy
安裝后可在命令行查看是否成功:
> scrapy
Scrapy 1.6.0 - no active project # 因為尚未新建 scrapy 項目
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command
初試 Scrapy
以爬取一個列出著名作家語錄的外國網站 quotes.toscrape.com 為例。
ps.官方中文教程使用的 http://dmoz.org 已經無法訪問了
第1步:創建項目
> cd D:\your_path
> scrapy startproject tutorial
將創建一個包含以下內容的 tutorial 目錄:
tutorial/
scrapy.cfg
tutorial/
__init__.py
...
settings.py
spiders/ # 放置spider代碼的目錄【入門時重點關注】
__init__.py
第2步:編寫代碼
(實際上在此之前還有分析網頁結構的過程)
將以下代碼保存到 tutorial/spiders 下的 quotes_spider.py 文件中:
import scrapy
# 定義一個類,繼承于 scrapy.Spider 父類
class QuotesSpider(scrapy.Spider):
# 定義 spider 的名稱,便于命令行識別
name = "quotes"
# 需要爬取的(首頁)網址
start_urls = [
'http://quotes.toscrape.com/page/1/',
]
# 利用 Xpath 解析 response 提取需要的信息(官方教程使用的 csss 選擇器)
def parse(self, response):
for quote in response.xpath('//div[@class="quote"]'):
yield {
'text': quote.xpath('./span[@class="text"]/text()').get(),
'author': quote.xpath(('.//small[@class="author"]/text()').get(),
'tags': quote.xpath('.//div[@class="tags"]/a[@class="tag"]/text()').getall(),
}
# 【下一頁】的 url(/page/n/) 存在時則拼接完整后訪問,實現自動循環抓取
next_page = response.xpath('//li[@class="next"]/a/@href').get()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(url=next_page, callback=self.parse)
第3步:運行爬蟲
轉到項目的頂級目錄并運行:
> cd tutorial
> scrapy crawl quotes # 直接運行
第4步:保存數據
直接在上一步的基礎上增加命令行參數即可:
> scrapy crawl quotes -o quotes.json # 運行并將結果保存到 quotes.json
> scrapy crawl quotes -o quotes.csv # 運行并將結果保存到 quotes.csv
輸出內容類似如下:
2019-04-30 23:16:39 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: scrapy_spider)
...
2019-04-30 23:16:43 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/1/>
{'text': '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”', 'author': 'Alb
ert Einstein', 'tags': ['(about)', 'change', 'deep-thoughts', 'thinking', 'world']}
...
{'text': "“A person's a person, no matter how small.”", 'author': 'Dr. Seuss', 'tags': ['(about)', 'inspirational']}
2019-04-30 23:16:47 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/10/>
{'text': '“... a mind needs books as a sword needs a whetstone, if it is to keep its edge.”', 'author': 'George R.R. Martin', 'tags': ['(about
)', 'books', 'mind']}
2019-04-30 23:16:47 [scrapy.core.engine] INFO: Closing spider (finished)
...
'start_time': datetime.datetime(2019, 4, 30, 15, 16, 42, 286835)}
2019-04-30 23:16:47 [scrapy.core.engine] INFO: Spider closed (finished)
結果展示
quotes.json
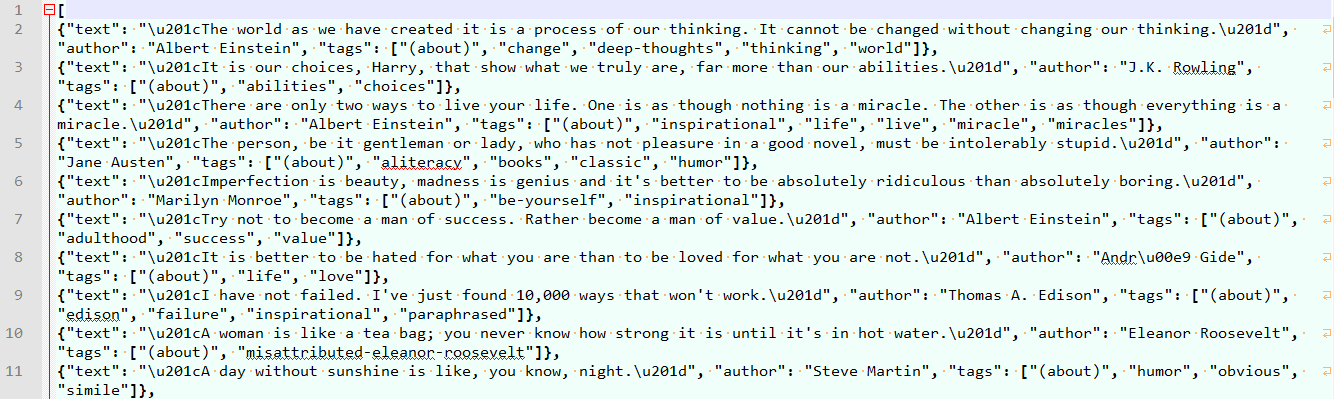
quotes.csv

剛接觸和學習 Scrapy,行文較倉促,主要是記錄和分享一下改寫的示例代碼,同時也是 Scrapy 項目的通用步驟。
已測試可順利爬取 51job 的職位,節后再增加解析職位詳情信息。
智能推薦
python爬蟲-scrapy框架
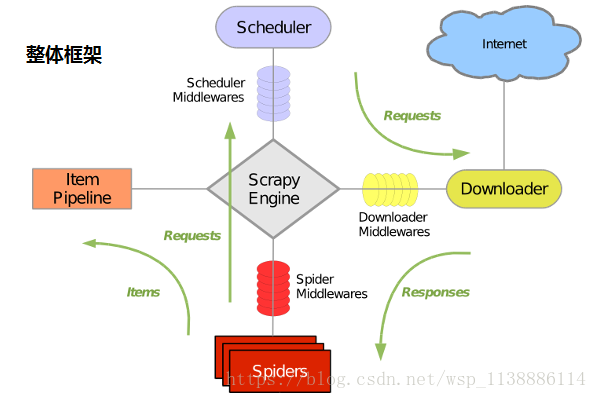
一、利用Scrapy框架抓取數據 1.1 Scrapy吸引人的地方在于它是一個框架。 任何人都可以根據需求方便的修改。它也提供了多種類型爬蟲的基類,如BaseSpider、sitemap爬蟲等,最新版本又提供了web2.0爬蟲的支持。 1.2、Scrapy主要包括了以下組件: 1.3、Scrapy運行流程大概如下: 1.4 安裝模塊(可以在Anaconda環境中執行) 依次執行下列命令安裝 pip...
python爬蟲--Scrapy框架
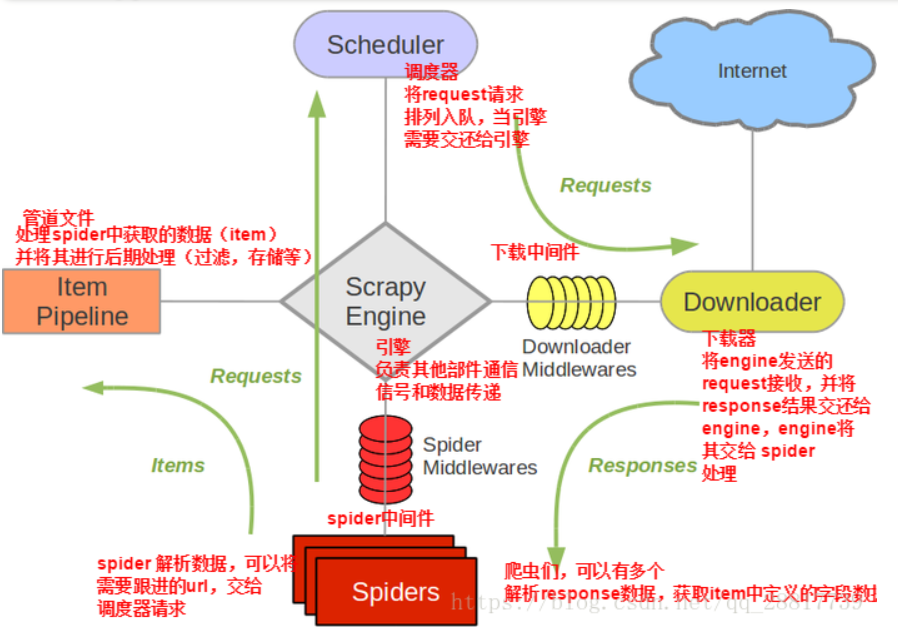
目錄: 一.Scrapy框架簡介 二.Scrapy框架的安裝 三.Scrapy框架中各組件的介紹及之間的關系 四.Scrapy運行流程 五.Scrapy框架項目的創建及運行 六.Scrapy框架項目結構 七.Scrapy框架詳細應用&實戰項目 八.Scrapy框架的特殊用法 九.總結 一.Scrapy框架簡介: 為了爬取網站數據而編寫的一款應用框架,所謂的框架其實就是一個集成了相應的功能且...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...
猜你喜歡

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...

統計學習方法 - 樸素貝葉斯
引入問題:一機器在良好狀態生產合格產品幾率是 90%,在故障狀態生產合格產品幾率是 30%,機器良好的概率是 75%。若一日第一件產品是合格品,那么此日機器良好的概率是多少。 貝葉斯模型 生成模型與判別模型 判別模型,即要判斷這個東西到底是哪一類,也就是要求y,那就用給定的x去預測。 生成模型,是要生成一個模型,那就是誰根據什么生成了模型,誰就是類別y,根據的內容就是x 以上述例子,判斷一個生產出...

styled-components —— React 中的 CSS 最佳實踐
https://zhuanlan.zhihu.com/p/29344146 Styled-components 是目前 React 樣式方案中最受關注的一種,它既具備了 css-in-js 的模塊化與參數化優點,又完全使用CSS的書寫習慣,不會引起額外的學習成本。本文是 styled-components 作者之一 Max Stoiber 所寫,首先總結了前端組件化樣式中的最佳實踐原則,然后在此基...