統計學習方法第四章(樸素貝葉斯)及Python實現及sklearn實現
標簽: 機器學習
1原理
樸素貝葉斯
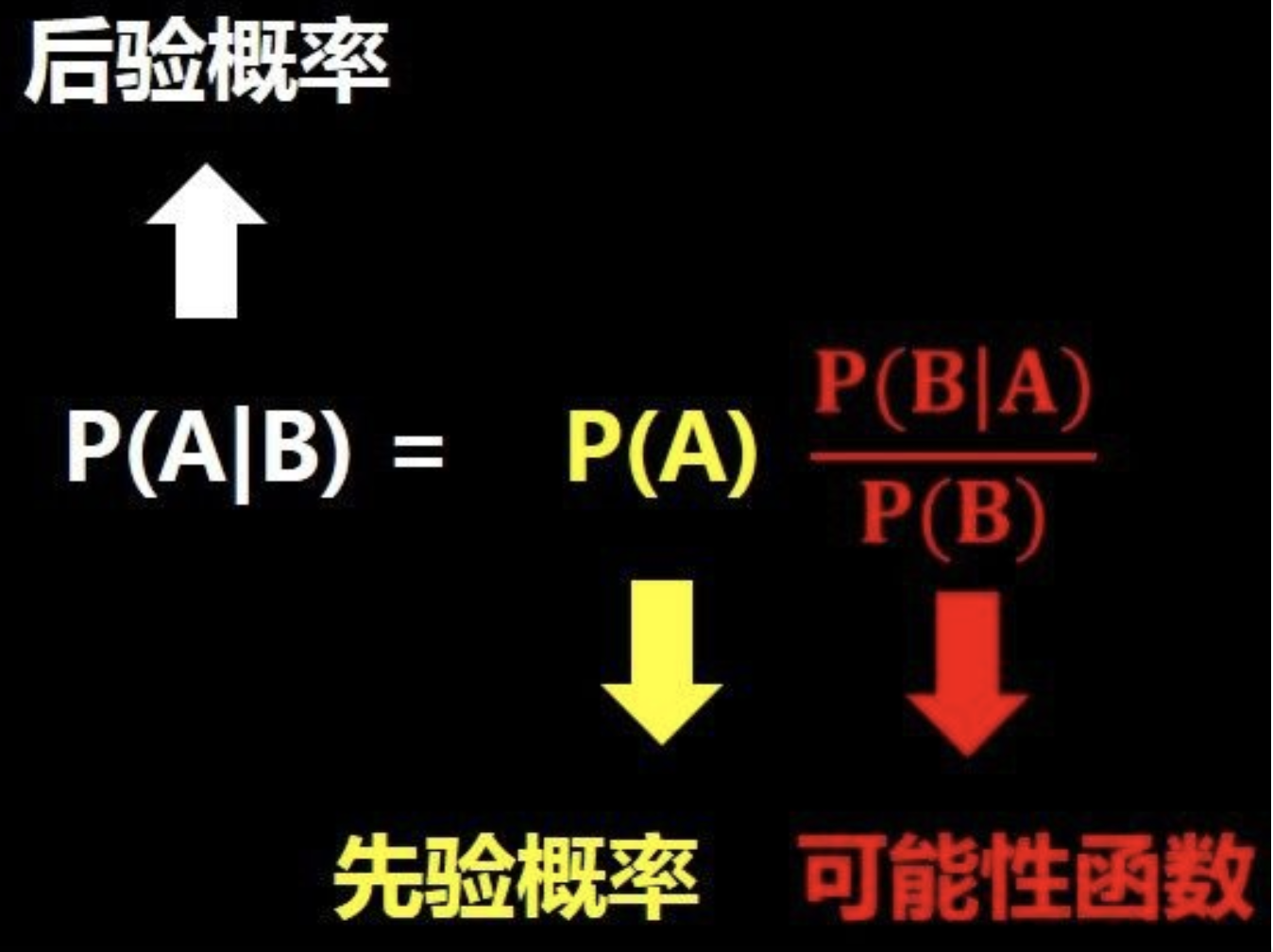
貝葉斯:根據貝葉斯定理p(y|x) = p(y)p(x|y)/p(x).選擇p(y|x) 最大的類別作為x的類別。可知樸素貝葉斯是監督學習的生成模型(由聯合概率分布得到概率分布)。選擇p(y|x) 最大的類別時,分母相同,所以簡化為比較 p(y)p(x|y)的大小。
樸素: 計算p(x|y)的概率,假設x是n維向量,每維向量有sn個取值可能,則就要計算類別*(sn的n次方)次。過于復雜。因此假設樣本的特征之間相互獨立,所以叫樸素。則p(x|y) = p(xi|y)的乘積,i=1,2,n.
為了防止p(xi|y)連乘時初戀某個數為0,通常選擇一個拉普拉斯平滑。
2 三要素
模型:p(y|x) = p(y)p(x|y)/p(x),近似=p(y)p(x|y), =p(y)p(xi|y),i=1,2,n
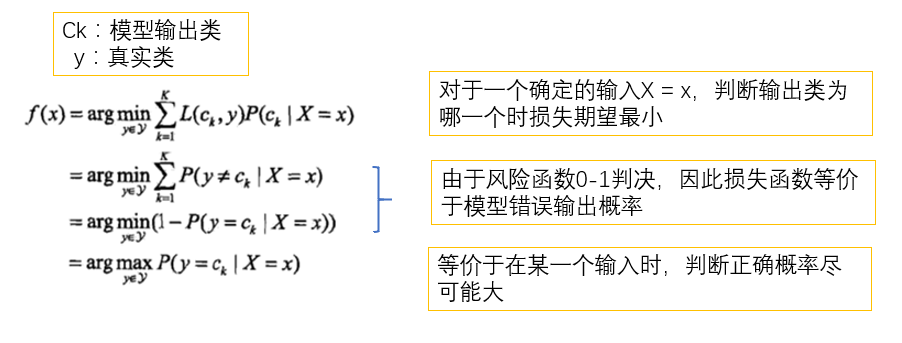
策略:01損失函數
算法:極大似然估計,貝葉斯估計(加拉普拉斯平滑)
應用
假設特征相互獨立,常用于垃圾郵件過濾,文本分類等詞袋模型。
python實現
class NB(object):
def __init__(self):
#每個特征屬性的取值列表
self.x = []
#標簽列表
self.y = []
#標簽概率列表
self.py = defaultdict(float)
#標簽概率列表
self.pxy = defaultdict(lambda:defaultdict(list))
#分階數
self.n = 5
def preProcess(self,X):
for i in range(X.shape[1]):
X[:,i] = self.step(X[:,i],self.n)
return X
#分階函數,因為不同特征的數值集大小相差巨大,造成部分概率矩陣變得稀疏,例如某個特征取值[0.2,0.4,0.6,1.2,1.4,1.6,2.2,2.4,2.6],如果分三階則0.2,0.4,0.6時,為1,1.2,1.4,1.6為2
def step(self,x,n):
ma = np.max(x)
mi = np.min(x)
stepN = (ma-mi)/float(n)
for i in range(len(x)):
for j in range(n):
a = mi + j*stepN
b = mi + (j+1)*stepN
if x[i]>= a and x[i] <= b:
x[i] = j + 1
break
return x
def prob(self,element,arr):
return sum(arr==element)/float(len(arr))
def fit(self,X,y):
X = self.preProcess(X)
self.y = list(set(y))
for i in range(X.shape[1]):
self.x.append(list(set(X[:,i])))
for yi in self.y:
# print(yi)
self.py[yi] = self.prob(yi,self.y)
for i in range(X.shape[1]):
# print(i)
samples = X[y==yi,i]
self.pxy[yi][i] = [self.prob(xi,samples) for xi in self.x[i]]
def predict_one(self,test_x):
print(test_x)
prob = 0
label = self.y[0]
for yi in self.y:
tempProb = np.log(self.py[yi])
for i in range(len(test_x)):
tempProb += np.log(self.pxy[yi][i][self.x[i].index(test_x[i])])
if tempProb>prob:
prob = tempProb
label = yi
return label
def predict(self,samples):
ylabels = []
samples = self.preProcess(samples)
for i in range(samples.shape[0]):
label = self.predict_one(test_x[i,:])
ylabels.append(label)
return np.array(ylabels)
def score(self,test_x,y):
ylabels = self.predict(test_x)
num = 0
for i in range(len(ylabels)):
if ylabels[i] == y[i]:
num += 1
return num/float(len(test_x))
測試
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import defaultdict
X,y = load_iris(return_X_y=True)
train_x,test_x,train_y,test_y = train_test_split(X,y,test_size=0.3)
nb = NB()
nb.fit(train_x,train_y)
nb.score(test_x,test_y)
由于iris更實用與高斯樸素貝葉斯估計,所以精確率不高
樸素貝葉斯用于垃圾郵件過濾時,使用多項式樸素貝葉斯,相當于只有一個特征,特征可以取值是所有文本組成的詞匯表。
python實現
import numpy as np
from collections import defaultdict
class NBClassify(object):
#構建包含所有詞的詞表
def createVocab(self,trainData):
vocabSet = set([])
for document in trainData:
vocabSet = vocabSet | set(document)
return list(vocabSet)
#將訓練樣本數據轉化為詞表向量
def bagOfVocab(self,vocabLst,inputData):
inputVocab = np.zeros(len(vocabLst))
for one in inputData:
if one in vocabLst:
inputVocab[vocabLst.index(one)] += 1
return inputVocab
def fit(self,X,y):
self.vocabLst = self.createVocab(X)
#標簽先驗概率
self.py = defaultdict(float)
#標簽,特征,條件概率,初始化特征為1
self.pxy = defaultdict(lambda :np.ones(len(self.vocabLst)))
dataVactor = []
for oneDocument in X:
documentVactor = self.bagOfVocab(self.vocabLst,oneDocument)
dataVactor.append(documentVactor)
dataMatrix = np.array(dataVactor)
for i in range(len(y)):
label = y[i]
self.py[label] += 1
self.pxy[label] += dataMatrix[i]
for key in self.py.keys():
self.py[key] = np.log(self.py[key]/dataMatrix.shape[0])
for key in self.pxy.keys():
self.pxy[key] = np.log(self.pxy[key]/np.sum(self.pxy[key]))
def predictOne(self,testData):
testDataVector = self.bagOfVocab(self.vocabLst,testData)
maxProb = -np.inf
label = 0
for key,value in self.pxy.items():
tempProb = self.py[key] + np.sum(value*testDataVector)
if tempProb>maxProb:
maxProb = tempProb
label = key
return label
測試
postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0, 1, 0, 1, 0, 1]
nb = NBClassify()
nb.fit(postingList,classVec)
testEntry = ['love', 'my', 'dalmation']
nb.predictOne(testEntry)
testEntry1 = ['stupid', 'garbage']
nb.predictOne(testEntry1)
sklearn實現
sklearn.naive_bayes包含三種貝葉斯分類器。高斯樸素貝葉斯(GaussianNB),多項式樸素貝葉斯(MultinomialNB),伯努利樸素貝葉斯(BernoulliNB )
1 GaussianNB:適用于特征是連續變量。條件概率分布p(x|y)符合高斯分布。例如load_iris。

均值和方差,從y=ck(某一類)且xi=xi的數據中求得。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB,MultinomialNB,BernoulliNB
X,y = load_iris(return_X_y=True)
train_x,test_x,train_y,test_y = train_test_split(X,y,test_size=0.3)
gnb = GaussianNB()
gnb.fit(train_x,train_y)#訓練
gnb.predict(test_x)#預測
gnb.score(test_x,test_y)#準確率
2 MultinomialNB:適用于特征是離散變量,條件概率分布p(x|y)符合多項式分布。例如上例中的垃圾郵件過濾。

from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
newsdata = fetch_20newsgroups(subset='all')
cv = CountVectorizer()
newsdataVector = cv.fit_transform(newsdata.data)
train_x,test_x,train_y,test_y = train_test_split(newsdataVector,newsdata.target,test_size=0.3)
mnb = MultinomialNB()
mnb.fit(train_x,train_y)
mnb.predict(test_x)
mnb.score(test_x,test_y)
3 BernoulliNB :適用于特征是離散變量,條件概率分布p(x|y)符合伯努利分布。即特征取值只有0,1.
垃圾郵件過濾中相當于文檔向量不是詞出現的詞數,而是是否出現0或1.
智能推薦
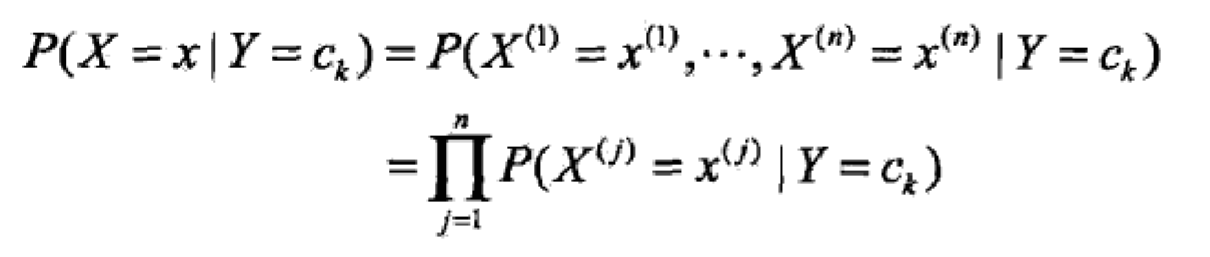
讀書筆記-統計學習方法(小藍)第四章
第四章 樸素貝葉斯法 4.1 樸素貝葉斯法的學習和分類 4.2 樸素貝葉斯法的參數估計 實踐: 4.1 樸素貝葉斯法的學習和分類 樸素貝葉斯法是基于貝葉斯定理 和條件獨立假設的分類方法。 先驗分布: 條件概率分布: 如果對條件概率分布做條件獨立性假設的話,條件概率分布的式子就會變成: 當x的條件下y是分類k的概率為(結果是通過貝葉斯轉化的結果,其中分母是相當于P(X=x)的邊際概率,與y無關,是個...
李航(統計學習方法第四章)
第四章 樸素貝葉斯法 樸素貝葉斯法和貝葉斯估計是不同的概念。 基于特征條件獨立假設學習輸入輸出聯合概率分布 基于此模型給出后驗概率最大的輸出y 本章敘述: 樸素貝葉斯法 學習與分類 參數估計算法 4.1 樸素貝葉斯法的學習與分類 4.1.1 基本方法 關于貝葉斯定理,以下摘一段 wikipedia 上的簡介: 所謂的貝葉斯定理源于他生前為解決一個“逆概”問題寫的一篇文章,而...
機器學習入門之《統計學習方法》筆記——樸素貝葉斯法
樸素貝葉斯(naive Bayes)法是基于貝葉斯定理與特征條件獨立假設的分類方法。 目錄 樸素貝葉斯法 參數估計 極大似然估計 學習與分類算法 算法 樸素貝葉斯算法 貝葉斯估計 小結 參考文章 樸素貝葉斯法 設輸入空間X⊆RnX⊆Rn 為nn 維向量的集合,輸出空間為類標記集合Y={c1,c2,...,cK}Y={c1,c2,....

統計學習方法學習筆記3——樸素貝葉斯模型
樸素貝葉斯屬于:概率模型、參數化模型、和生成模型 目錄 1.樸素貝葉斯基本方法 2.后驗概率最大化的含義 3.樸素貝葉斯算法: 樸素貝葉斯python實現4.1: 樸素貝葉斯sklearn實現作業4.1 貝葉斯的優缺點: 1.樸素貝葉斯基本方法 2.后驗概率最大化的含義 3.樸素貝葉斯算法: 樸素貝葉斯python實現4.1: 結果: 樸素貝葉斯sklearn實現作業4.1 貝葉斯的優缺點: 由于...
統計學習方法之樸素貝葉斯理解和代碼復現
樸素貝葉斯 聯合概率 P(A,B) = P(B|A)*P(A) = P(A|B)*P(B)將右邊兩個式子聯合得到下面的式子: P(A|B)表示在B發生的情況下A發生的概率。P(A|B) = [P(B|A)*P(A)] / P(B) 直觀理解一下這個式子,如下圖,問題A在我們知道B信息之后概率發生了變化(圖片來自于小白之通俗易懂的貝葉斯定理(Bayes’ Theorem) 1.后驗概率推...
猜你喜歡


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...
