HBase 0.92.1 Scan 源碼詳細分析
從這篇文章開始終于要討論比較正常版本的hbase了---0.92.1~~ 
Scan是hbase提供的非常重要的功能之一,我們的hbase分析系列就從這兒開始吧。
首先,我們有一些background的知識需要了解:
1.HBase是如何區分不同記錄的,大家可以參考http://punishzhou.iteye.com/blog/1266341,講的比較詳細
2.Region,MemStore,Store,StoreFile分別的含義和如何工作的,可以參考淘寶的入門文檔http://www.searchtb.com/2011/01/understanding-hbase.html
3.Scan的客戶端實現可以參考http://punishzhou.iteye.com/blog/1297015
4.hbase客戶端如何使用scan,這個文章實在太多了,隨便搜一篇吧~
在這篇文章中,我們主要focus在Scan的Server端實現。
Scan的概念是掃描數據集中[startkey,stopkey)的數據,數據必須是全體有序的,根據hbase mem+storefile的結構我們大致描述下scan的步驟:
1.準備好所有的scanner,包括memstorescanner,storefilescanner
2.將scanner放入一個prorityQueue
3.開始scan,從prorityQueue中取出當前所有scanner中最小的一個數據記錄
4.如果3取出的滿足結果則返回,如果不滿足則從prorityQueue中取next
5.如果取出的數據記錄等于stopkey或者prorityQueue為空則結束
下面開始進入實現部分。
scan過程中會使用到諸多scanner,scanner類圖如下:
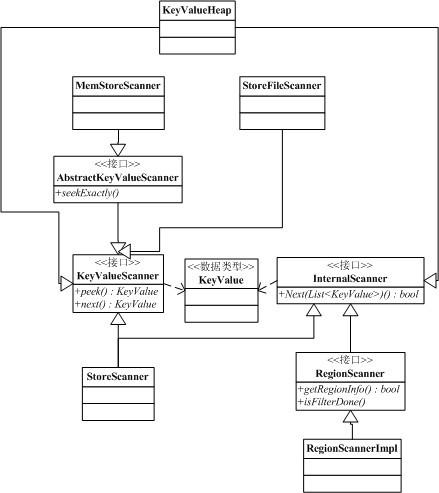
步驟1:準備Scanner:
memstore和storefile的getScanner:
return Collections.<KeyValueScanner>singletonList(
new MemStoreScanner());List<StoreFileScanner> scanners = new ArrayList<StoreFileScanner>(
files.size());
for (StoreFile file : files) {
StoreFile.Reader r = file.createReader();
scanners.add(r.getStoreFileScanner(cacheBlocks, usePread, isCompaction));
}
return scanners;store層的getScanner:對memstore和storefile分別判斷是否滿足scan的條件,包括時間,是否支持bloomfilter
List<KeyValueScanner> allStoreScanners =
this.store.getScanners(cacheBlocks, isGet, false);
List<KeyValueScanner> scanners =
new ArrayList<KeyValueScanner>(allStoreScanners.size());
// include only those scan files which pass all filters
for (KeyValueScanner kvs : allStoreScanners) {
if (kvs instanceof StoreFileScanner) {
if (memOnly == false
&& ((StoreFileScanner) kvs).shouldSeek(scan, columns)) {
scanners.add(kvs);
}
} else {
// kvs is a MemStoreScanner
if (filesOnly == false && this.store.memstore.shouldSeek(scan)) {
scanners.add(kvs);
}
}
}Store層:獲取store的scanner們,seekExactly檢查是否符合我們scan的column,scanner.seek調用memscanner或者storefilescanner的seek,檢查我們查詢的startkey是否在當前的scanner范圍中,過濾掉不需要搜索的查詢,其中,storefilescanner會使用bloomfilter來seek。當收集到當前store的scanner們后會構建store層的KeyValueHeap。
// pass columns = try to filter out unnecessary ScanFiles
List<KeyValueScanner> scanners = getScanners(scan, columns);
// Seek all scanners to the start of the Row (or if the exact matching row
// key does not exist, then to the start of the next matching Row).
if (matcher.isExactColumnQuery()) {
for (KeyValueScanner scanner : scanners)
scanner.seekExactly(matcher.getStartKey(), false);
} else {
for (KeyValueScanner scanner : scanners)
scanner.seek(matcher.getStartKey());
}
// Combine all seeked scanners with a heap
heap = new KeyValueHeap(scanners, store.comparator);region層:將store中的scanner中取出來放到scanners里,并創建RegionScanner的KeyValueHeap
for (Map.Entry<byte[], NavigableSet<byte[]>> entry :
scan.getFamilyMap().entrySet()) {
Store store = stores.get(entry.getKey());
StoreScanner scanner = store.getScanner(scan, entry.getValue());
scanners.add(scanner);
}
this.storeHeap = new KeyValueHeap(scanners, comparator);是不是已經被諸多scanner看暈了,這邊先梳理下思路:
- memscanner和storefilescanner為直接數據交互的scanner,因此繼承KeyValueScanner接口,每次next讀取一個KeyValue對象
- storescanner管理里面的memscanner和storefilescanner,并且將所有的scanner放到一個KeyValueHeap內,KeyValueHeap會保證每次next都會取Store中滿足條件的最小值
- regionscanner類似storescanner,管理所有的storescanner,并將所有的scanner放到KeyValueHeap中,作用同上
2.初始化KeyValueHeap(其實在第一部中已經做了),關鍵是初始化內部的PriorityQueue
this.comparator = new KVScannerComparator(comparator);
if (!scanners.isEmpty()) {
this.heap = new PriorityQueue<KeyValueScanner>(scanners.size(),
this.comparator);
for (KeyValueScanner scanner : scanners) {
if (scanner.peek() != null) {
this.heap.add(scanner);
} else {
scanner.close();
}
}
this.current = heap.poll();關于PriorityQueue可以看看http://blog.csdn.net/hudashi/article/details/6942789,內部實現了一個heap。
3.開始scan的next方法,首先,peekRow取得KeyValueHeap中當前的rowkey。這是通過current的scanner peek獲得當前的rowkey,從第二部可知,KeyValueHeap剛開始時current即為heap中最小的那個
public KeyValue peek() {
if (this.current == null) {
return null;
}
return this.current.peek();
}4.開始取出符合當前rowkey的values
調用heap.next 循環從heap中取出相同key的不同value,直到heap取出的key不等于當前的key為止,這就表示我們已經遍歷到下一個rowkey了必須停止這次next操作。
do {
this.storeHeap.next(results, limit - results.size());
if (limit > 0 && results.size() == limit) {
if (this.filter != null && filter.hasFilterRow()) {
throw new IncompatibleFilterException(
"Filter with filterRow(List<KeyValue>) incompatible with scan with limit!");
}
return true; // we are expecting more yes, but also limited to how many we can return.
}
} while (Bytes.equals(currentRow, nextRow = peekRow()));heap的next方法:首先取出當前的scanner,調用next方法取出一個result塞到results里,然后peek判斷這個scanner是否沒數據了,如果沒了就關閉,如果有就再將scanner放入heap中,再取出下一個最小的scanner
if (this.current == null) {
return false;
}
InternalScanner currentAsInternal = (InternalScanner)this.current;
boolean mayContainMoreRows = currentAsInternal.next(result, limit);
KeyValue pee = this.current.peek();
/*
* By definition, any InternalScanner must return false only when it has no
* further rows to be fetched. So, we can close a scanner if it returns
* false. All existing implementations seem to be fine with this. It is much
* more efficient to close scanners which are not needed than keep them in
* the heap. This is also required for certain optimizations.
*/
if (pee == null || !mayContainMoreRows) {
this.current.close();
} else {
this.heap.add(this.current);
}
this.current = this.heap.poll();
return (this.current != null);5.對取出的results進行filter,判斷是否到了stoprow,如果到了next返回false
final boolean stopRow = isStopRow(nextRow);
// now that we have an entire row, lets process with a filters:
// first filter with the filterRow(List)
if (filter != null && filter.hasFilterRow()) {
filter.filterRow(results);
}
if (results.isEmpty() || filterRow()) {
// this seems like a redundant step - we already consumed the row
// there're no left overs.
// the reasons for calling this method are:
// 1. reset the filters.
// 2. provide a hook to fast forward the row (used by subclasses)
nextRow(currentRow);
// This row was totally filtered out, if this is NOT the last row,
// we should continue on.
if (!stopRow) continue;
}
return !stopRow;
最后總結一下:
1.scan的實現是非常復雜的,原因主要是因為hbase在內存和硬盤中有很多顆有序樹,scan時需要將多顆有序樹merge成一個
2.scan.next出來的list<KeyValue>是同一個key下按照一定順序從小到大排列的,順序是key>column>quality>timestamp>type>maxsequenceId,然后如果是memstore,則比較memstoreTs,大的排前面,而且memstore的maxsequenceId默認是整數最大值
3.最好能指明scan的cf和quality,這樣會加快速度
4.memstore的scan和storefile的scan如果有機會后面會再寫文詳細闡述
智能推薦
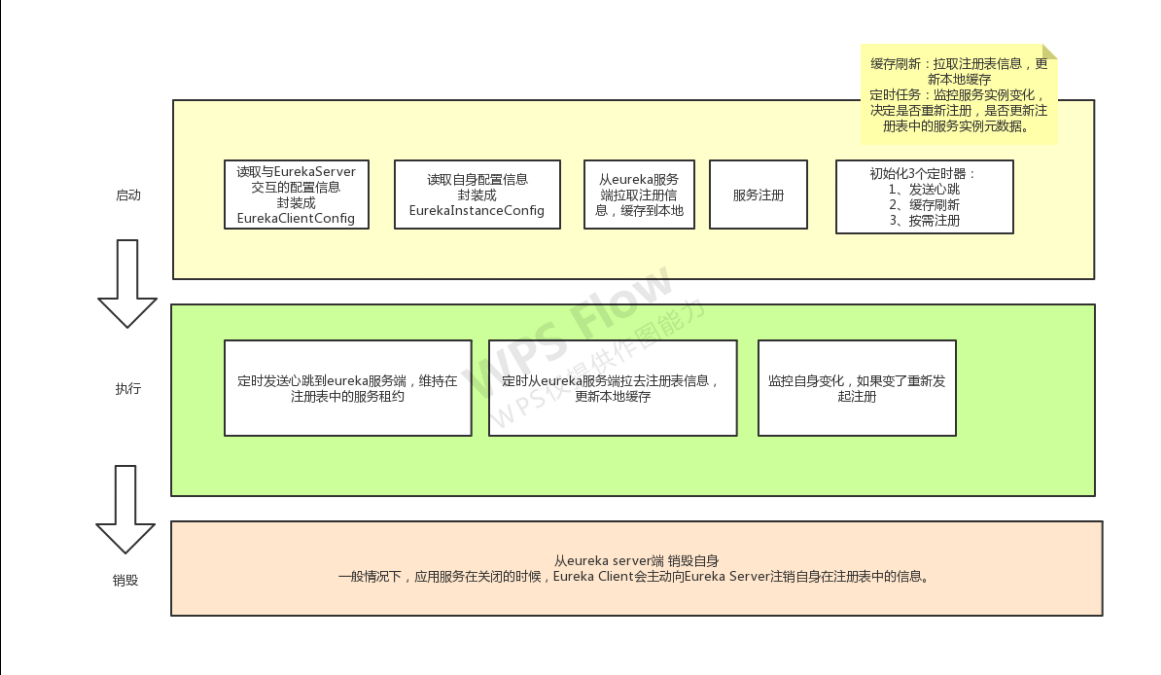
Eureka Client源碼詳細分析
一,Eureka Client概述 1,Eureka Client工作流程圖 2,@EnableDiscoveryClient注解 注意:Eureka Client在1版本是必須要加@EnableDiscoveryClient注解的,2版本@EnableDiscoveryClient注解加不加都沒有影響。 3,EurekaClientConfig和EurekaInstanceConfig Eure...

Spark獲取HBase海量數據方式之Scan
一.簡介 Scan掃描,類似于數據庫系統中的游標,底層依賴順序存儲的數據結構。掃描操作的作用跟get()方式非常類似,但由于掃描操作的工作方式類似于迭代器,所以用戶無需調用scan()方法創建實例,只需調用HTable的getScanner()方法【或者使用new Scan()】,此方法在返回真正的掃描器scanner實例的同時,用戶也可以使用它的迭代來獲取數據。如下: 后兩個為了方便用戶,隱式地...
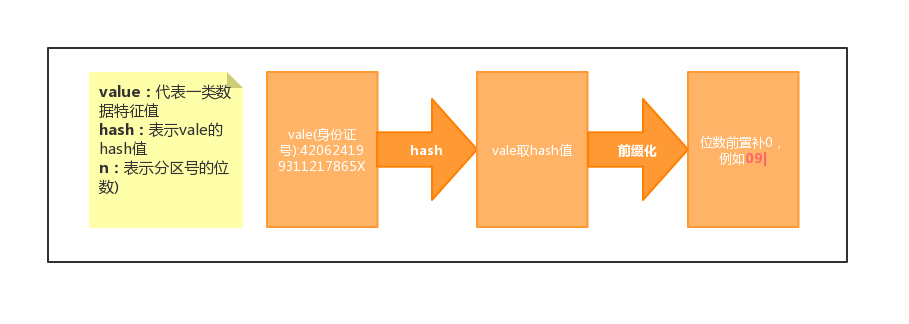
Hbase查詢Scan優化和Row設計策略
Hbase查詢Scan優化和Row設計策略 Hbase查詢Scan優化和Row設計策略 前言 分區號設計 時間因素 java查詢代碼 總結 Hbase查詢Scan優化和Row設計策略 好久沒有分享工作和學習經驗了,工作太忙,好多學習計劃都落下了,后面得加油了,本次就分享下在項目中運用的Hbase查詢和RowKey設計相關的東西。 前言 startKey和stopKey,scan中我建議必須要設置,...

超詳細!全注釋!java代碼對hbase進行建表(create),插入數據(put),查詢數據(get)以及掃描(scan)
一.導入核心jar包 hbase/lib/下的115個jar包 二.編寫代碼...
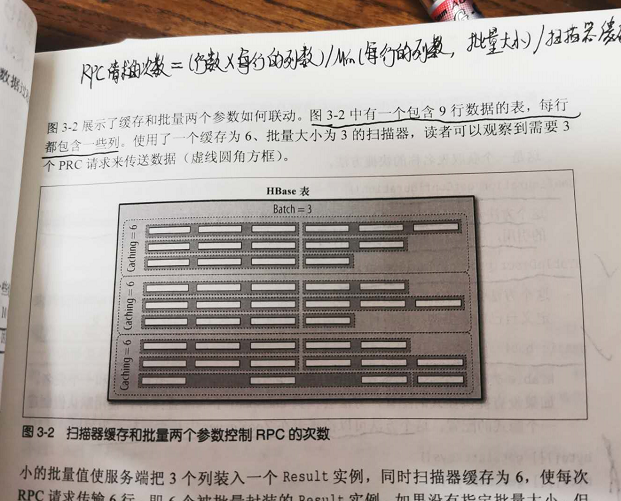
HBase_HBase2.0+ Java API 操作指南 (三) 掃描器Scan
Hbase 取數據通過 Get 方法去取數據還是效率太低了。這里我們學習下如何獲取一批數據。 這里我們首先學習下Scan ,Scan 是基礎,在Scan中可以設置過濾器 Filter。 掃描器 掃描技術。這種技術類似于數據庫系統中的游標(cursor), 并利用到了HBase 提供的底層順序存儲的數據結構...
猜你喜歡


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...
