DC學院數據分析師(入門)學習筆記----高級爬蟲技巧
對于網站來說,實際上是不愿意讓大家去爬取它的內容的,因為爬蟲可能會對真實的用戶帶來不太好的影響(很多網站會限制流量,尤其是對爬蟲產生的流量,會對服務器帶來一定的壓力)。所以網站會對爬蟲有一定的抵制,如果不注意爬蟲的技巧,有可能就被網站封殺IP,以致暫停了。
那么如何能夠輕松繞過部分的反爬蟲限制,書寫我們的爬蟲呢??
1.設定程序休止時間
連續不斷的進行爬蟲的抓取,就會被網站監測出來是一個爬蟲程序。所以,我們應該在能夠接受的速度內,盡量降低一下自己爬取的頻率(中間停1-5秒,再去爬下一個),以免對這些網站產生不必要的影響,這樣做也對網站的負荷會比較好。
n為你想要實現的時間間隔
import time
time.sleep(n)
2.設定代理
設定代理的原因主要有兩個:
①、有時候需要爬取的網站,通過我們的網絡IP沒有辦法去進行訪問。所以需要設置代理。如:在教育網里訪問外網的網站;國內的IP有時候無法訪問國外的網站等。
②、有時候,不管我們怎么設置我們的爬取頻率,在爬取如新浪微博、Facebook等這些很成熟的網站的時候,這些網站的反爬蟲技術很高超,所以會很快的檢測到我們的機器爬蟲程序,從而會把我們登錄訪問的ip地址封掉。比如針對facebook,它會禁止這個ip地址再去訪問它的網站,即使我們重新啟動爬蟲,從無論是正常從瀏覽器訪問還是爬蟲訪問,Facebook都一律不允許這個ip地址再去訪問它的網站。
那么,通過代理服務器如何進行呢??
傳統:通常直接使用我們的電腦去訪問網頁。
通過代理服務器:我們發送一個網絡的請求,會首先發送到代理服務器上,代理服務器再把這個請求轉發到網頁所在的網站服務器。網站服務器回復的反饋會先發送到代理服務器上,代理服務器再發送給我們的電腦。在這種情況下,只要我們的電腦和代理服務器的連接是合理快速的,代理服務器和網站服務器的連接是順暢快速的,通過代理服務器往往就可以加速我們訪問目標網頁的速度,甚至我們可以訪問到一些我們之前無法訪問的網頁內容。
那么,如何通過python訪問代理服務器呢??
#使用urllib.request的兩個方法進行代理的設置
proxy = urlrequest.ProxyHandler({'https': '47.91.78.201:3128'})
opener = urlrequest.build_opener(proxy)代理服務器的存在,可以應對網站禁止某個IP訪問的反爬蟲措施,代理服務器有著不同的匿名類型,通常我們會挑選中、高級別的代理服務器來訪問網頁。(使用低級別的是沒有用的,網站還是能夠知道我們的真實IP,對于我們的爬取時沒有任何幫助的,因為它還是能夠封掉我們的真實IP)

3.設定User-Agent
網站是可以識別我們是否在使用Python進行爬取,需要我們在發送網絡請求時,把header部分偽裝成瀏覽器。
opener.addheaders = [('User-Agent','...')]
用不同瀏覽器訪問的header字符串,放入上述代碼省略號的部分即可。
常用的瀏覽器header有:
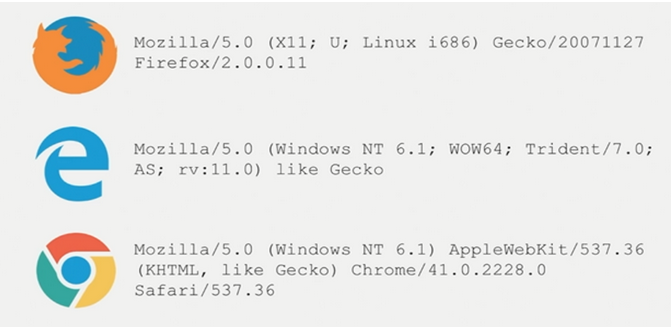
網上查看還有這些:
1.QQ瀏覽器: Mozilla/5.0 (compatible; MSIE 10.0; WindowsNT6.1; WOW64; Trident/6.0; QQBrowser/7.7.24962.400) (我在代碼中用的是這個)
2. IE瀏覽器:Mozilla/5.0(compatible; MSIE 10.0;Windows NT 6.1; WOW64; Trident/6.0)
示例:Place PulseGoogle街景圖爬取
這是MIT的學術項目,爬取不同城市的街景地圖,然后讓人去手工標注圖片中的城市哪個更安全,更有趣等等。
舉個例子,下面這兩個城市的圖景。如果認為左邊更好的話,就點擊左邊的城市,如果認為差不多的話就點擊等號,
如果認為右邊更好的話,就點擊右邊的城市。
MIT會統計這些標注結果。
這個數據集是這樣的:(左邊城市是什么,右邊城市是什么,某人的打分)
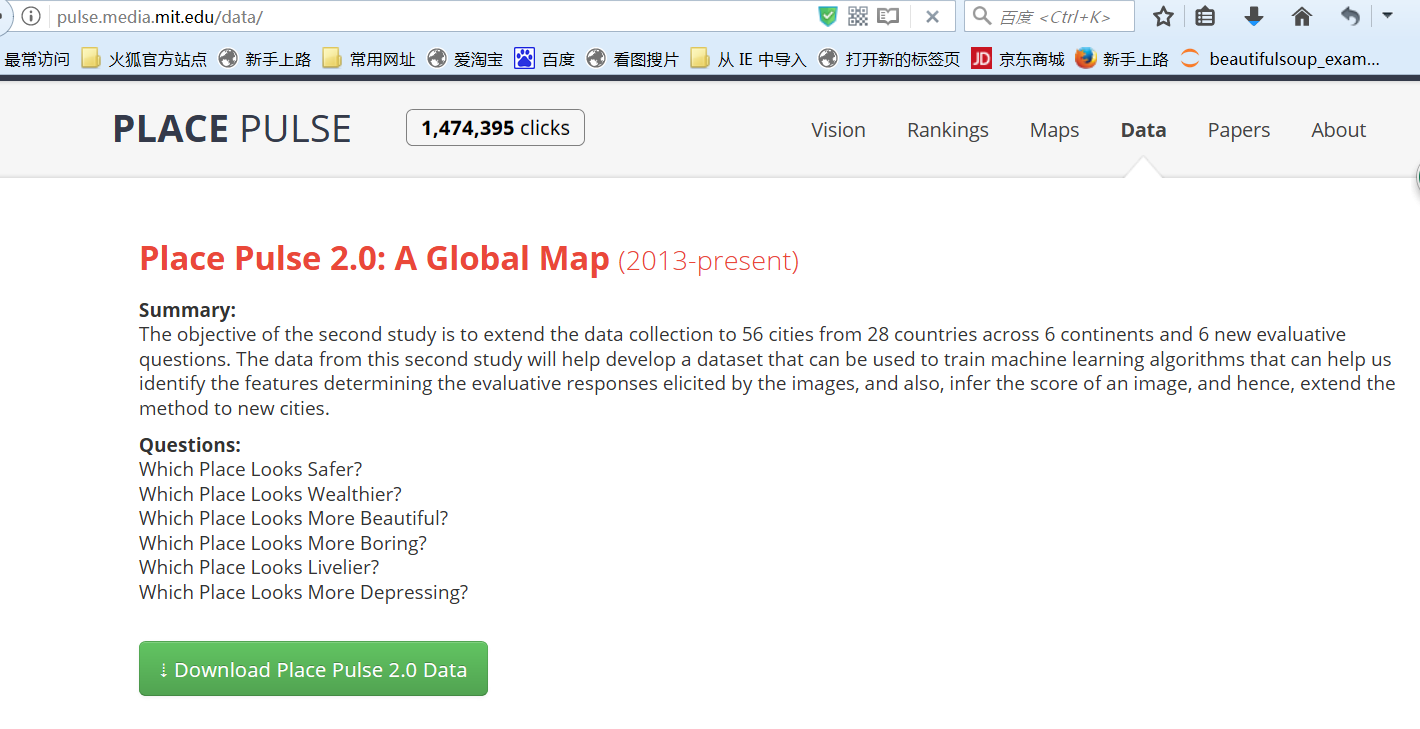
下載下來:

結構:
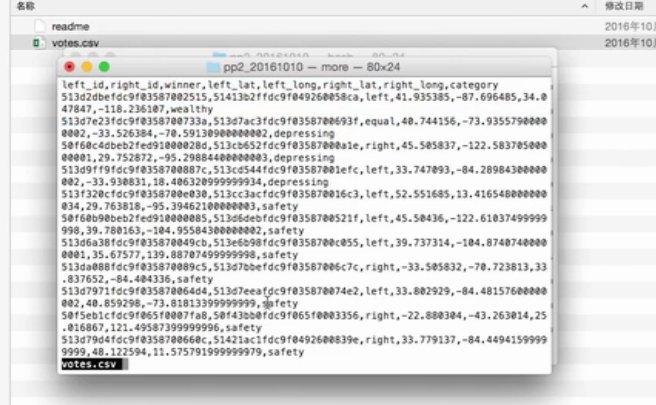
逗號來分隔每一個屬性里面的值
核心任務:
把對應每一個圖片ID的谷歌街景圖片,根據它告訴我們的這個圖片所在的GPS的經緯度的位置,利用readme中看到的google map的api,把這個圖片下載下來。
代碼及注釋:
# coding=utf-8
import urllib.request as urlrequest
import time
import random
# 1.準備工作:載入包,定義存儲目錄,連接API
IMG_PATH = './imgs/{}.jpg' # 最終會把下載的圖片存到這個目錄下面
DATA_FILE = './data/votes.csv'
# 記錄一下已經下載了哪些圖片,把圖片id放在里面,這樣如果下載中止也能知道哪些已經下載了,
# 這樣在下載一個圖片之前,我們可以先判斷一下這個圖片的id是否在這個文件中有,如果有,就不用再下載了。
STORED_IMG_ID_FILE = './data/cached_img.txt'
STORED_IMG_IDS = set() # 把已經下載的圖片的id放在一個集合里面
# readme中提到的google針對下載街景地圖的api
# 我們需要修改的是location,即經緯度
IMG_URL = 'https://maps.googleapis.com/maps/api/streetview?size=400x300&location={},{}'
# 2.應用爬蟲技巧:使用代理服務器、User-Agent
# 根據網上找到的代理服務器來更新一下,因為代理服務器可以運行的時間也是有限制的
proxy = urlrequest.ProxyHandler({'https': '173.213.108.111:3128'}) # 設置代理服務器的地址
#opener = urlrequest.build_opener(proxy)
opener = urlrequest.build_opener()
# 設定User-Agent
opener.addheaders = [('User-Agent',
'Mozilla/5.0 (compatible; MSIE 10.0; WindowsNT 6.1; WOW64; Trident/6.0; QQBrowser/7.7.24962.400) ')]
urlrequest.install_opener(opener)
# 3.讀取圖片的id
with open(STORED_IMG_ID_FILE) as input_file:
for line in input_file:
STORED_IMG_IDS.add(line.strip())
# 4.根據提供的votes.csv,進行google街景圖片的爬取
with open(DATA_FILE) as input_file: # 讀取votes.csv
skip_first_line = True
for line in input_file:
if skip_first_line: # 因為第一行是屬性行,所以跳過
skip_first_line = False
continue
# 根據逗號就行拆分成各個屬性(這些屬性在readme中可以看到)
left_id, right_id, winner, left_lat, left_long, right_lat, right_long, category = line.split(',')
# 針對左邊的圖片
if left_id not in STORED_IMG_IDS: # 如果左邊的圖片還沒有下載
print('saving img {}...'.format(left_id))
urlrequest.urlretrieve(IMG_URL.format(left_lat, left_long), IMG_PATH.format(left_id)) # 文件命名為這個圖片的id
STORED_IMG_IDS.add(left_id) # 把已經下載的圖片的id加進集合中
with open(STORED_IMG_ID_FILE, 'a') as output_file: # 把已經下載的圖片的id新添加進cached_img.txt中
output_file.write('{}\n'.format(left_id))
time_interval = random.uniform(1, 5)
time.sleep(time_interval) # wait some time, trying to avoid google forbidden (of crawler)
# 針對右邊的圖片
if right_id not in STORED_IMG_IDS:
print('saving img {}...'.format(right_id))
urlrequest.urlretrieve(IMG_URL.format(right_lat, right_long), IMG_PATH.format(right_id))
STORED_IMG_IDS.add(right_id)
with open(STORED_IMG_ID_FILE, 'a') as output_file:
output_file.write('{}\n'.format(right_id))
time_interval = random.uniform(1, 5)
time.sleep(time_interval) # wait some time, trying to avoid google forbidden (of crawler)
國外服務器的代理地址,可以在 http://www.kuaidaili.com/free/outha/這個網站中找到。
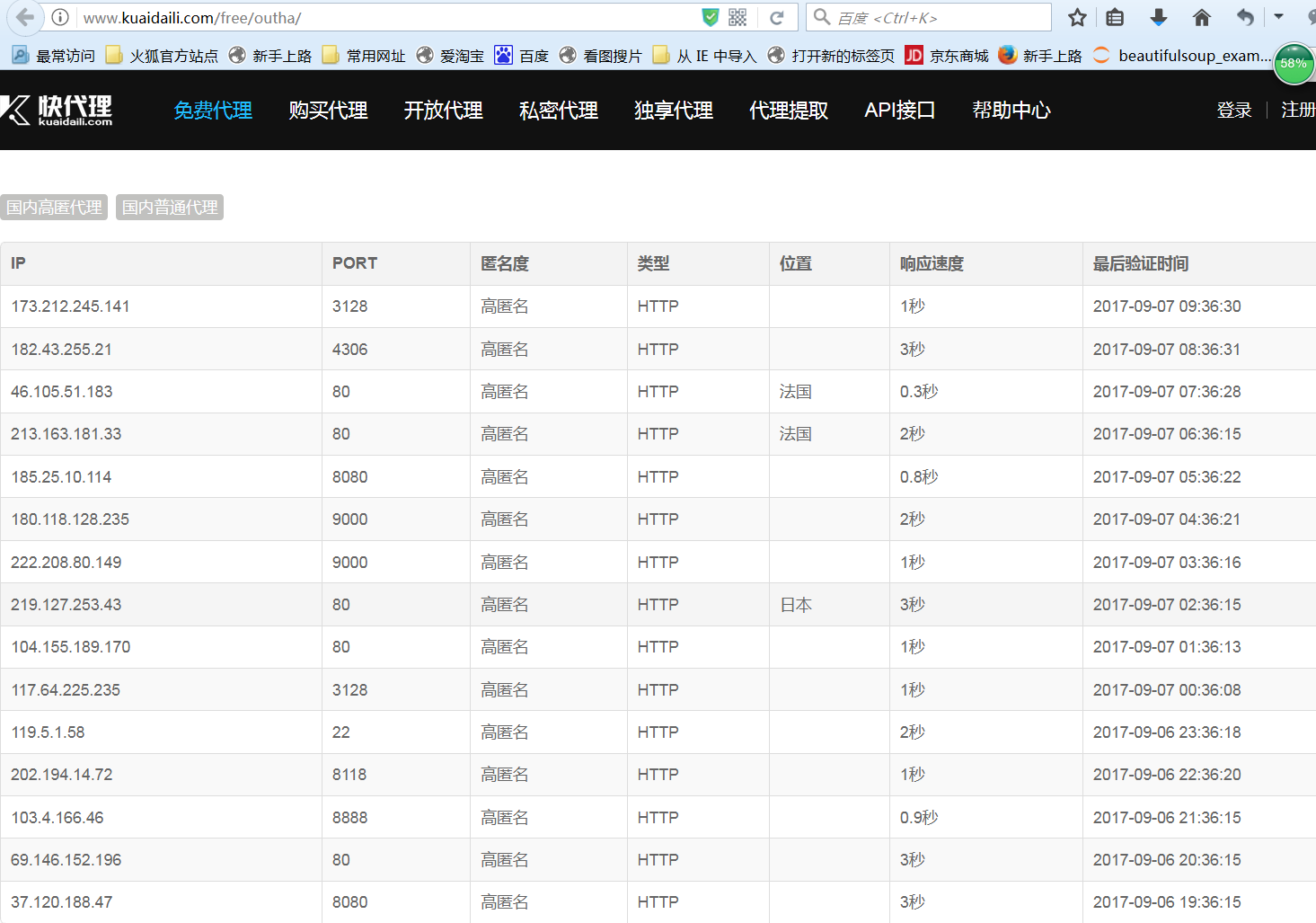
可以看到每個地址對應ip地址所在的國家,匿名的程度等等。
這里需要注意我們不能使用低級(Transparent)代理。
先來運行不使用代理服務器的程序:

速度很慢,存儲不動,google在大陸訪問起來還是比較困難的。
運行設置代理服務器的程序:

可以順利進行,這說明我們成功連接到了代理的一個服務器上,再通過這個代理服務器連接到了google上。
在文件夾里可以查看到我們從googlemap中下載到的圖片以及圖片的id。
智能推薦

hadoop for 數據分析師
hadoop的核心有兩個東西: HDFS Map Reduce運算模型 HDFS 什么是HDFS,有什么用? hadoop集群的文件系統,說白了就是存儲數據的地方,hadoop是一個集群,很多臺機器,我們要用它來跑數就先得把數據給它,最常見的就是數據文件的格式,例如txt或者csv之類的,然后它運算完之后的結果肯定也得寫到文件里面去(大數據的運算查詢不可能把結果全部放在顯示器上顯示的,放不下也)。...

大數據分析師工程師------入門 0(開篇詞)
大數據分析師工程師------入門 0(開篇詞) 最近幾十年,高速發展的互聯網,滲透進了我們生活的方方面面,整個人類社會都已經被互聯網連接為一體。身處互聯網之中,我們無時無刻不在產生大量數據,如瀏覽商品的記錄、成交訂單記錄、觀看視頻的數據、瀏覽過的網頁、搜索過的關鍵詞、點擊過的廣告、朋友圈的自拍和狀態等。這些數據,既是我們行為留下的痕跡,同時也是描述我們自身最佳的證據。2014年3月,馬云曾經在北...

python數據爬蟲——數據分析師崗位基本信息爬取(一)
爬取網址:www.51job.com 1.首先我們來分析需要爬取網站的情況 在51job中輸入:數據分析師 2.把URL復制到一個text文本中,分析一下地址。隨意的復制三頁的地址,找到其中的規律。 對比分析:URL前面都是一樣的,在“.html”前的數字不一樣,這個數字就是對應的頁面。“?”后面的一大串都是格式,對URL地址并沒有影響。于是我們只需...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
猜你喜歡
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...

統計學習方法 - 樸素貝葉斯
引入問題:一機器在良好狀態生產合格產品幾率是 90%,在故障狀態生產合格產品幾率是 30%,機器良好的概率是 75%。若一日第一件產品是合格品,那么此日機器良好的概率是多少。 貝葉斯模型 生成模型與判別模型 判別模型,即要判斷這個東西到底是哪一類,也就是要求y,那就用給定的x去預測。 生成模型,是要生成一個模型,那就是誰根據什么生成了模型,誰就是類別y,根據的內容就是x 以上述例子,判斷一個生產出...