《統計學習方法》讀書筆記——樸素貝葉斯法(公式推導+代碼實現)
標簽: 《統計學習方法》讀書筆記 概率論 機器學習 python 深度學習 人工智能
傳送門
《統計學習方法》讀書筆記——機器學習常用評價指標
《統計學習方法》讀書筆記——感知機(原理+代碼實現)
《統計學習方法》讀書筆記——K近鄰法(原理+代碼實現)
《統計學習方法》讀書筆記——樸素貝葉斯法(公式推導+代碼實現)
寫在前面
- 樸素貝葉斯法與貝葉斯估計是不同的概念。
- ?
- 損失函數與風險函數
- 損失函數用于度量一次預測的好壞;
- 風險函數用于度量平均意義下模型的好壞。
- 全概率公式與逆概率公式
- 設為一組完備事件組,則對任一事件,有如下全概率公式:
若,則有如下貝葉斯公式,或稱逆概率公式:
- 先驗概率與后驗概率
- 常稱為事件發生的先驗概率,而稱為事件發生的后驗概率。(概率論教程P25)
樸素貝葉斯法
“如果你不知道怎樣踢球,就往球門方向踢 ” ——施拉普納
要搞明白樸素貝葉斯法的原理,要先知道“球門方向”在哪里。
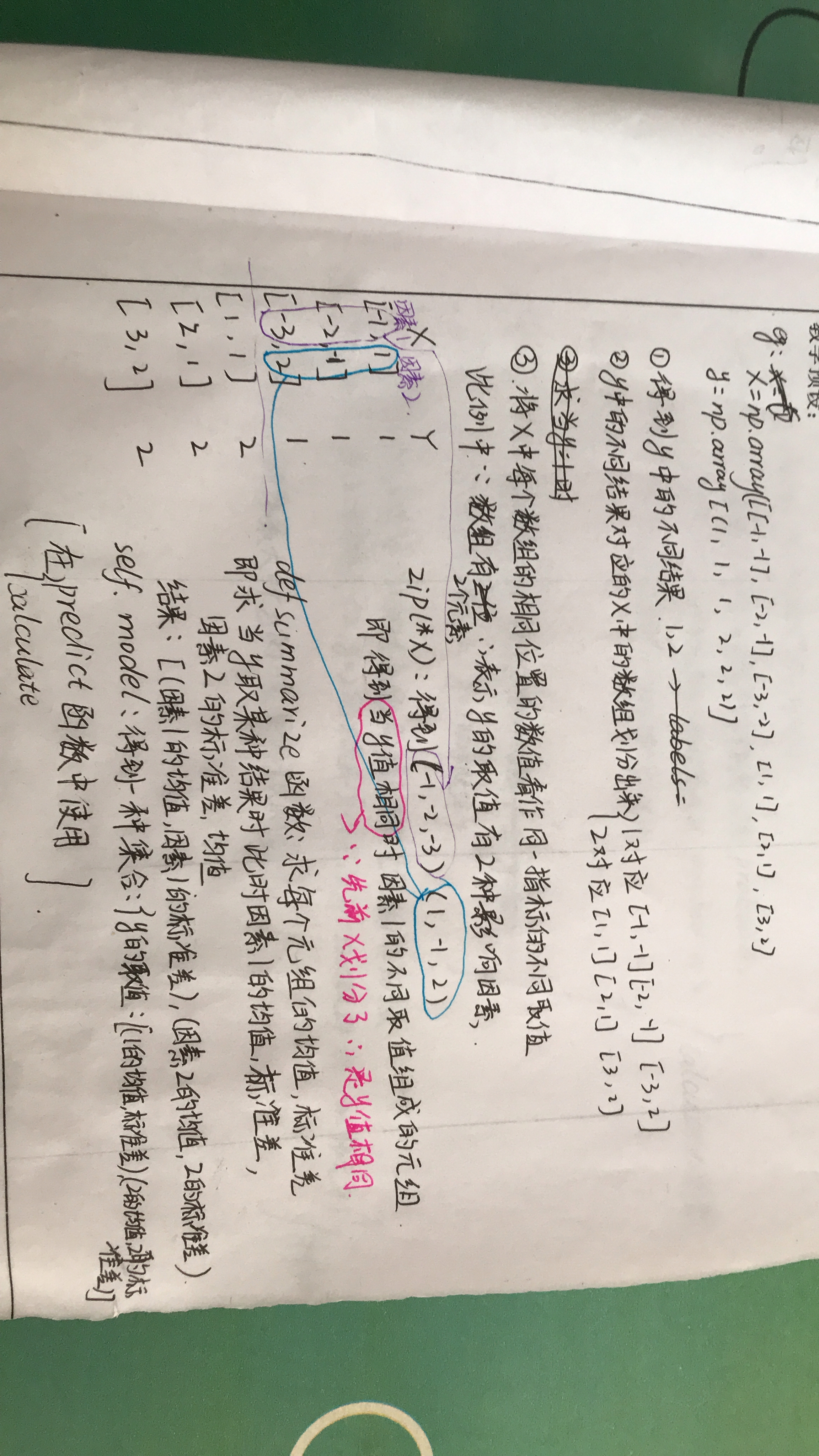
設輸入空間為維向量的集合,輸入空間為類標記集合。輸入為特征向量,輸入為類別。是定義在輸入空間上的隨機變量,是定義在輸出空間上的隨機變量。對于一個輸入的數據,要預測所屬的類別,相當于求以下概率的值:
根據貝葉斯公式(逆概率公式),可得:
插入部分
上述的貝葉斯公式中,容易求得,統計數據集中各個類別樣本的數量就可以計算出來。
因為是向量,即,因此將部分展開來就是。
這樣看來,假設對mnist數據集來說,每一張圖片有種可能的預測結果(即),每一張圖片由28*28=784個像素點組成(即,),每一個像素點的取值范圍為,即的可值為個。那么要計算的數據量為,無法計算。
樸素貝葉斯法對條件概率分布作了條件獨立性的假設,樸素貝葉斯法也由此得名,即
這一假設使樸素貝葉斯法變得簡單,但會犧牲一定的分類準確率。
(因為向量的特征之間大概率是不獨立地,如果我們獨立了,會無法避免地拋棄一些前后連貫的信息,比方說我說“三人成?”,后面大概率就是個”虎“,這個虎明顯依賴于前面的三個字。)
那么上面的貝葉斯公式就可以轉換為以下形式:
這是樸素貝葉斯法分類的基本公式。于是,樸素貝葉斯分類器可表示為
其中分母對所有都是相同的,所以
該公式即為樸素貝葉斯分類器。
至于式子里面的兩項具體怎么求,我們首先看第一項。
N為訓練樣本的數目,假設我們手里現在有100個樣本,那N就是100。
分子中是指示函數,括號內條件為真時指示函數為1,反之為0。分子的意思求在這100個樣本里有多少是屬于分類的。
再看第二項
其中
構造原理和上面第一項的一樣,也是通過指示函數來計數得出概率。那么兩項都能求了,給出樸素貝葉斯算法。

但是,步驟(2)中,那么多概率連乘,如果其中有一個概率為0怎么辦?那整個式子直接就是0了,這樣不對。所以我們連乘中的每一項都得想辦法讓它保證不是0。

代碼實現
# coding=utf-8
import numpy as np
import time
def loadData(fileName):
print('start to read data:' + fileName)
dataArr = []
labelArr = []
fr = open(fileName, 'r')
# 將文件按行讀取
for line in fr.readlines():
# 對每一行數據按切割符','進行切割,返回字段列表
curLine = line.strip().split(',')
# 將mnist圖像二值化
dataArr.append([int(int(num) > 128) for num in curLine[1:]])
labelArr.append(int(curLine[0]))
# 返回data和label
return dataArr, labelArr
def NaiveBayes(Py, Px_y, x):
featrueNum = 784
classNum = 10
P = [0] * classNum
for i in range(classNum):
sum = 0
for j in range(featrueNum):
sum += Px_y[i][j][x[j]]
P[i] = sum + Py[i]
return P.index(max(P))
def model_test(Py, Px_y, testDataArr, testLabelArr):
errorCnt = 0
for i in range(len(testDataArr)):
predict = NaiveBayes(Py, Px_y, testDataArr[i])
if predict != testLabelArr[i]:
errorCnt += 1
return 1 - (errorCnt / len(testDataArr))
def getAllProbability(trainDataArr, trainLabelArr):
featureNum = 784
classNum = 10
lambbaVal = 1
#初始化先驗概率分布存放數組,后續計算得到的P(Y = 0)放在Py[0]中,以此類推
#數據長度為10行1列
Py = np.zeros((classNum, 1))
#對每個類別進行一次循環,分別計算它們的先驗概率分布
#計算公式為書中"4.2節 樸素貝葉斯法的參數估計 公式4.8"
for i in range(classNum):
# 計算先驗概率
Py[i] = ((np.sum(np.mat(trainLabelArr) == i)) + lambbaVal) / (len(trainLabelArr) + classNum * lambbaVal)
# 防止數據過小向下溢出使用log()
# 在似然函數中通常會使用log的方式進行處理
Py = np.log(Py)
# 計算條件概率 Px_y=P(X=x|Y = y)
# 計算分子部分
# 2表示一個像素點可取值的個數(因為對數據做了二值化處理)
Px_y = np.zeros((classNum, featureNum, 2))
for i in range(len(trainLabelArr)):
#獲取當前循環所使用的標記
label = trainLabelArr[i]
#獲取當前要處理的樣本
x = trainDataArr[i]
#對該樣本的每一維特診進行遍歷
for j in range(featureNum):
#在矩陣中對應位置加1
#這里還沒有計算條件概率,先把所有數累加,全加完以后,在后續步驟中再求對應的條件概率
Px_y[label][j][x[j]] += 1
# 計算分母部分
for label in range(classNum):
for j in range(featureNum):
#獲取y=label,第j個特診為0的個數
Px_y0 = Px_y[label][j][0]
#獲取y=label,第j個特診為1的個數
Px_y1 = Px_y[label][j][1]
#對式4.10的分子和分母進行相除,再除之前依據貝葉斯估計,分母需要加上2(為每個特征可取值個數)
#分別計算對于y= label,x第j個特征為0和1的條件概率分布
Px_y[label][j][0] = np.log((Px_y0 + 1) / (Px_y0 + Px_y1 + 2))
Px_y[label][j][1] = np.log((Px_y1 + 1) / (Px_y0 + Px_y1 + 2))
#返回先驗概率分布和條件概率分布
return Py, Px_y
if __name__ == "__main__":
start = time.time()
# 獲取訓練集、測試集
trainData, trainLabel = loadData('./mnist/mnist_train.csv')
testData, testLabel = loadData('./mnist/mnist_test.csv')
#開始訓練,學習先驗概率分布和條件概率分布
print('start to train')
Py, Px_y = getAllProbability(trainData, trainLabel)
#使用習得的先驗概率分布和條件概率分布對測試集進行測試
print('start to test')
accuracy = model_test(Py, Px_y, testData, testLabel)
print('the accuracy is:', accuracy)
print('time span:', time.time() -start)
輸出結果
start to read data:./mnist/mnist_train.csv
start to read data:./mnist/mnist_test.csv
start to train
start to test
the accuracy is: 0.8432999999999999
time span: 129.84226727485657
參考
原理:《統計學習方法》
代碼: https://github.com/Dod-o/Statistical-Learning-Method_Code
智能推薦

統計學習方法——第四章樸素貝葉斯
參考網址如下,講解更詳細: http://www.jianshu.com/p/5fd446efefe9 http://blog.csdn.net/v_victor/article/details/51319873 樸素navie:條件獨立性 【問題的引入】 經典的貝葉斯公式 實際問題中,能獲得的數據可能只有有限數...
樸素貝葉斯(naive Bayes)的python實現——基于《統計學習方法》例題的編程求解
樸素貝葉斯方法是基于貝葉斯定理與特征條件獨立假設的分類方法。認為樣本的特征X與標簽y服從聯合概率分布P(X, y),所有的樣本都是基于這個概率分布產生的。由于條件概率P(X=x|Y=y)的參數具有指數數量級,因此進行估算切實際。貝葉斯法對條件概率分布做了條件獨立性假設,從而減少了模型的復雜性,增加了模型的泛化能力,減少了過擬合的風險。 #后驗概率最大化 可以證明,期望風險最小化準則可以得到后驗概率...

統計學習筆記六----樸素貝葉斯
前言 樸素貝葉斯(naive Bayes)算法是基于貝葉斯定理和特征條件獨立假設的分類方法,它是一種生成模型! 對于給定的訓練數據集,首先基于特征條件獨立假設學習輸入/輸出的聯合概率分布;然后基于此模型,對給定的輸入x,利用貝葉斯定理求出后驗概率最大的輸出y。 樸素貝葉斯算法實現簡單,學習與預測的效率都很高,是一種常用的方法。 條件獨立性的假設 樸素貝葉斯法對條件概率分布作了條件獨立性...

猜你喜歡
《統計學習方法》讀書筆記——感知機
感知機 一、感知機的定義 假設輸入空間 X⊆Rn\mathcal{X}\subseteq{\mathcal{R^n}}X⊆Rn,輸出空間Y={+1,−1}\mathcal{Y} = \{+1, -1\}Y={+1,−1}; 輸入x∈Xx\in\mathcal{X}x∈X表示樣本的特征向量,輸出y∈Yy\in\mathcal{...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...