深度學習開發環境搭建
文章目錄
硬件環境
處理器:AMD Ryzen 5 3600 6-core processor × 12
顯卡:NVIDIA Corporation TU104 [GeForce RTX 2060]
內存:16G DDR4
硬盤:1T SSD
系統:Ubuntu 20.04.1 LTS
深度學習開發環境搭建
更改系統軟件源
- 備份原來的源:
cp /etc/apt/sources.list /etc/apt/sources.list.bak
- 將源的內容設置為阿里云鏡像:
sudo vim /etc/apt/sources.list
內容改為:
deb http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
- 更新軟件列表:
sudo apt updatesudo apt upgrade
安裝Python和pip
- Ubuntu系統默認自帶python,有版本需求的話也可以自己安裝一下
sudo apt install python3sudo apt install python3-pip
- 不管是不是自己安裝的python,替換python的pip源建議是一定操作一下的,pip安裝速度會快很多:
cd ~mkdir .pip
直接新建并編輯pip.conf:
sudo vim ~/.pip/pip.conf
改為以下內容(這里用的清華源,也可以試一下阿里、豆瓣等源):
[global]index-url = https://pypi.tuna.tsinghua.edu.cn/simple/ [install]trusted-host = pypi.tuna.tsinghua.edu.cn
- 更改默認python版本,python目錄默認鏈接的是python2,而現在基本都是用python3開發了
sudo apt install python-is-python3
安裝Nvidia顯卡驅動
- 打開軟件和更新
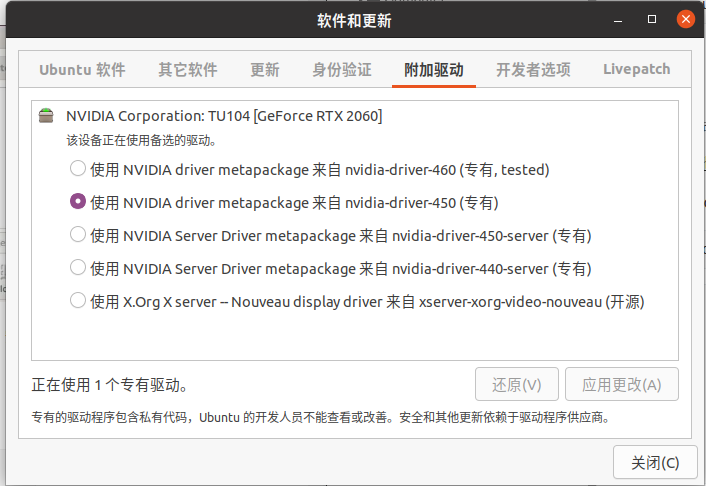
選擇安裝Nvidia官方驅動(第二個是開源驅動)
-
禁止nouveau 驅動
sudo gedit /etc/modprobe.d/blacklist.conf添加
blacklist nouveau blacklist lbm-nouveau options nouveau modeset=0 alias nouveau off alias lbm-nouveau off執行如下命令,更新系統,來禁用nouveau
sudo update-initramfs -u -
重啟完之后更新一下軟件:
sudo apt update sudo apt upgrade -
查看驅動
nvidia-smi輸出:
+-----------------------------------------------------------------------------+ | NVIDIA-SMI 450.102.04 Driver Version: 450.102.04 CUDA Version: 11.0 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 GeForce RTX 2060 Off | 00000000:26:00.0 On | N/A | | 0% 41C P8 7W / 160W | 675MiB / 5931MiB | 7% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 908 G /usr/lib/xorg/Xorg 53MiB | | 0 N/A N/A 1457 G /usr/lib/xorg/Xorg 219MiB | | 0 N/A N/A 1585 G /usr/bin/gnome-shell 178MiB | | 0 N/A N/A 31707 G ...cent\WeChat\WeChatApp.exe 10MiB | | 0 N/A N/A 37422 G ...AAAAAAAA== --shared-files 36MiB | | 0 N/A N/A 42882 G ...AAAAAAAAA= --shared-files 48MiB | | 0 N/A N/A 44445 G ...AAAAAAAAA= --shared-files 104MiB | | 0 N/A N/A 45053 G gnome-control-center 3MiB | +-----------------------------------------------------------------------------+
安裝CUDA
- 去官網下載cuda安裝包:CUDA Toolkit 11.0 Download | NVIDIA Developer
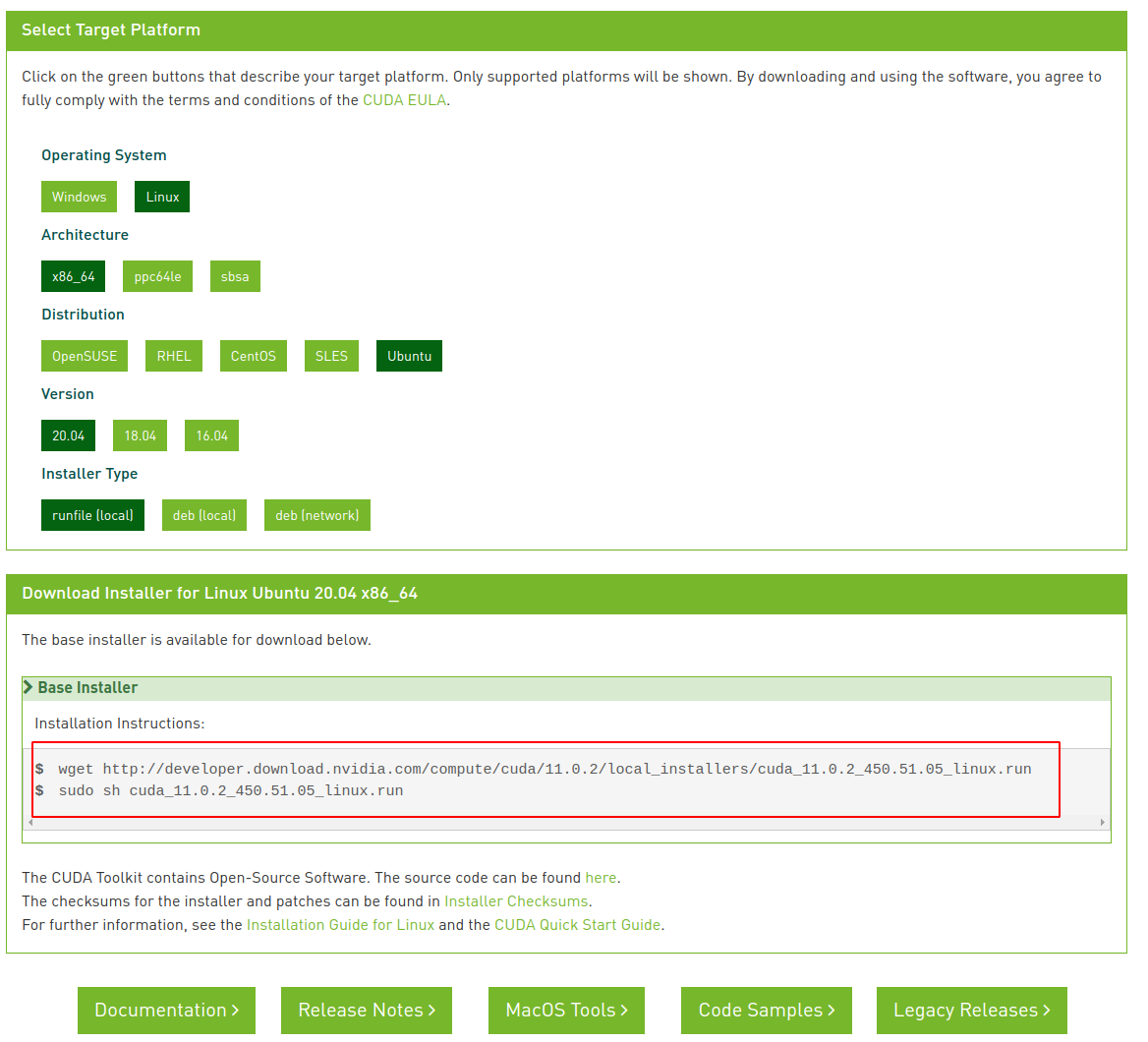
- 運行下面的命令進行安裝:
wget http://developer.download.nvidia.com/compute/cuda/11.0.2/local_installers/cuda_11.0.2_450.51.05_linux.run
chmod +x cuda_11.0.2_450.51.05_linux.runsudo sh
./cuda_11.0.2_450.51.05_linux.run
- 根據上圖提示需要配置環境變量:
gedit ~/.bashrc
再文件最后加入以下語句:
export CUDA_HOME=/usr/local/cuda-11.0
export LD_LIBRARY_PATH=${CUDA_HOME}/lib64
export PATH=${CUDA_HOME}/bin:${PATH}
然后使其生效:
source ~/.bashrc
- 可以使用命令nvcc -V查看安裝的版本信息:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2020 NVIDIA Corporation
Built on Thu_Jun_11_22:26:38_PDT_2020
Cuda compilation tools, release 11.0, V11.0.194
Build cuda_11.0_bu.TC445_37.28540450_0
也可以編譯一個程序測試安裝是否成功
找到 NVIDIA_CUDA-11.0_Samples 安裝位置
locate NVIDIA_CUDA-11.0_Samples
cd NVIDIA_CUDA-11.0_Samples/1_Utilities/deviceQuery
make
./deviceQuery
輸出
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce RTX 2060"
CUDA Driver Version / Runtime Version 11.0 / 11.0
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 5931 MBytes (6219563008 bytes)
(30) Multiprocessors, ( 64) CUDA Cores/MP: 1920 CUDA Cores
GPU Max Clock rate: 1695 MHz (1.70 GHz)
Memory Clock rate: 7001 Mhz
Memory Bus Width: 192-bit
L2 Cache Size: 3145728 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 38 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.0, CUDA Runtime Version = 11.0, NumDevs = 1
Result = PASS
安裝CuDNN
進入到CUDNN的下載官網: cuDNN Download | NVIDIA Developer,登陸下載
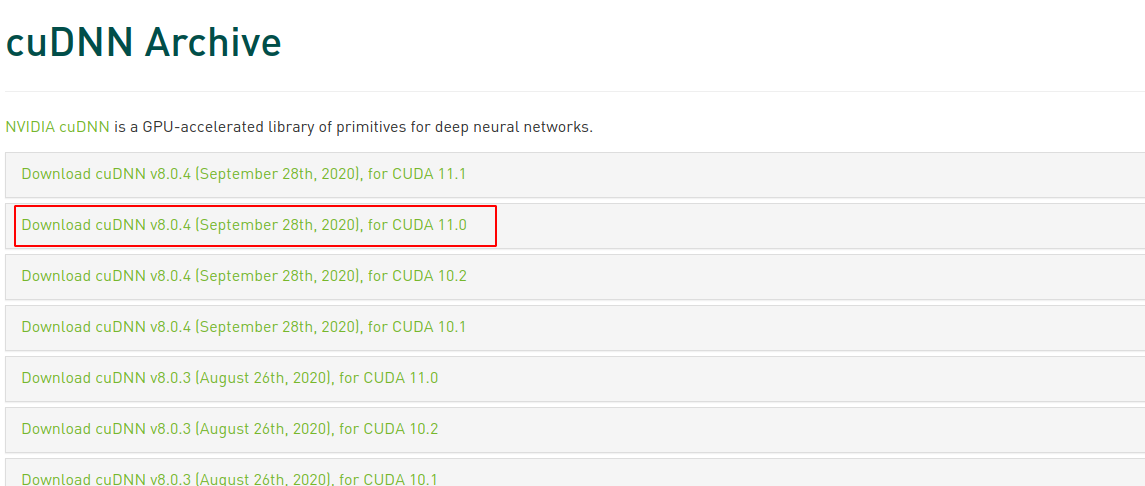
下載之后是一個壓縮包,對它進行解壓,命令如下:
tar -xzvf cudnn-11.0-linux-x64-v8.0.5.39.tgz
使用以下兩條命令復制這些文件到CUDA目錄下:
sudo cp cuda/lib64/* /usr/local/cuda-11.0/lib64/ sudo cp cuda/include/* /usr/local/cuda-11.0/include/
拷貝完成之后,可以使用以下命令查看CUDNN的版本信息:
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
輸出
#define CUDNN_MAJOR 8
#define CUDNN_MINOR 0
#define CUDNN_PATCHLEVEL 4
--
#define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)
#endif /* CUDNN_VERSION_H */
安裝Conda環境
什么是Conda
Conda是Python中用于管理包和環境的一大利器。使用Conda,我們還可以非常便利的使用數據科學相關的包。Conda可以幫助我們創建虛擬環境,從而方便的應用于多個項目中。
Anaconda實際上是一個軟件的發行版,附帶了Conda、python和150多個科學軟件包及其相關的包。Conda是一個包和環境管理器。Anaconda是一個本身很大(大約500M),因為它附帶了Python中最常見的數據科學包。如果您不需要所有的軟件包,或者需要節省帶寬或存儲空間,那么也有miniconda,一個只包含conda和python的發行版。我們同樣可以用Conda安裝任何可用的軟件包。
安裝conda
-
在Anaconda官網下載Linux安裝包:Anaconda | Individual Edition
-
運行下面的命令安裝:
chmod +x Anaconda3-2020.11-Linux-x86_64.sh./Anaconda3-2020.11-Linux-x86_64.sh
一路按ENTER確認,然后根據提示輸入yes,這里我為了目錄整潔不安裝在默認路徑,設置為下面的路徑:/home/zyh/app/anaconda3
然后會詢問你是否要初始化conda,輸入yes確認,重開終端窗口之后,就可以看到conda環境可用了
conda 簡單使用
**包管里 **
當我們成功安裝anaconda后,我們可以很容易的使用conda來進行包管理。例如:
conda install numpy
除了每次安裝一個包外,我們還可以一次性安裝多個包,例如:
conda install numpy pandas
此外,我們還可以安裝某個指定版本的包:
conda install numpy=1.10
Ps:使用conda安裝指定包時,conda可以自動處理相關的包依賴。假設本身沒有安裝numpy時,若我們使用conda install scipy,則此時conda會自動安裝numpy,因為scipy本身依賴numpy。
此外,conda還有一些其他的常用命令:
- 刪除某個包:
conda remove package_name - 升級某個包:
conda upgrade package_name - 升級全部包:
conda upgrade --all - 查看包列表:
conda list - 模糊查詢包:
conda search 'keywords'
**環境管里 **
conda可以用于創建多個環境而從進行項目隔離。
創建一個新的環境的格式如下:
conda create -n env_name list_of_packages
其中,-n后的參數env_name表示環境名稱。
接著可以跟著0個或多個包名稱。
一個示例如下:
conda create -n my_env numpy
表示創建了一個新的環境:my_env。并同時在該環境中安裝一個包:numpy。
此外,在創建環境時,我們可以指定Python的版本。例如:
conda create -n my_env python=2.7
其中,我們可以在conda命令中,增加python=x的信息用于指定Python的版本號。
此時,我們可以輕松的實現在一臺機器上兼容Python2和Python3了。
當我們使用conda創建了一個新的環境后,可以使用如下命令進入該環境:
conda activate env_name
此時,當我們進行該環境后,可以看命令行中的引導符中已經提示出了當前所屬的conda環境:
conda list
想要離開當前環境時,則只需要執行如下命令即可:
conda deactivate
環境的保存與加載
對于conda環境,其有著一個如下特性:環境共享。
通過以配置文件的形式可以保存環境相關的全部信息。
我們可以使用如下命令將相關的環境信息保存在一個yaml文件中:
conda env export > env.yaml
此時,我們已經將當前環境相關的信息全部存儲在env.yaml文件中。當我們希望在其他機器中創建一個相同的環境時,可以直接執行如下命令:
conda env create -f env.yaml
當你不記得在當前機器上存在哪些conda環境時,可以執行如下命令列出全部環境:
conda env list
此時,*號所在的行表示當前所屬的環境。
當某個環境我們不再需要時,可以直接執行如下命令來刪除該環境:
conda env remove -n env_name
測試一下GPU訓練
本地Conda環境方式
用conda新建一個python3.8+pytorch1.7+cuda11.0的虛擬環境:
conda create --name python_38-pytorch_1.7.0 python=3.8
#
# To activate this environment, use
#
# $ conda activate python_38-pytorch_1.7.0
#
# To deactivate an active environment, use
#
# $ conda deactivate
進入環境
conda activate python_38-pytorch_1.7.0
檢查一下是否切換到所需環境了
which pip
如果看到使用的確實是我們設置的環境目錄中的pip的話說明就ok。
接下來在環境中安裝pytorch,可以參考官網的安裝命令:Start Locally | PyTorch
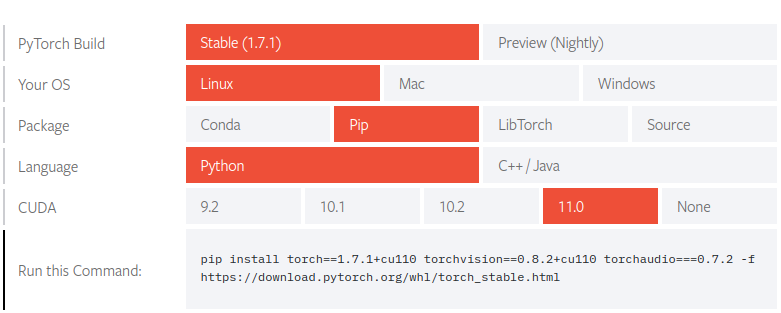
輸入以下命令進行安裝:
pip install torch==1.7.0+cu110 torchvision==0.8.1+cu110 torchaudio===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
環境配置就完成了,下面新建一個簡單的測試腳本驗證功能,新建mnist_train.py,內容如下:
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5, 1)
self.conv2 = nn.Conv2d(20, 50, 5, 1)
self.fc1 = nn.Linear(4 * 4 * 50, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4 * 4 * 50)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(args, model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
# sum up batch loss
test_loss += F.nll_loss(output, target, reduction='sum').item()
# get the index of the max log-probability
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def main():
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=args.lr,
momentum=args.momentum)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(args, model, device, test_loader)
if (args.save_model):
torch.save(model.state_dict(), "mnist_cnn.pt")
if __name__ == '__main__':
main()
運行腳本,正常的話就可以看到訓練輸出了:
參考
智能推薦


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...

猜你喜歡

Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...

統計學習方法 - 樸素貝葉斯
引入問題:一機器在良好狀態生產合格產品幾率是 90%,在故障狀態生產合格產品幾率是 30%,機器良好的概率是 75%。若一日第一件產品是合格品,那么此日機器良好的概率是多少。 貝葉斯模型 生成模型與判別模型 判別模型,即要判斷這個東西到底是哪一類,也就是要求y,那就用給定的x去預測。 生成模型,是要生成一個模型,那就是誰根據什么生成了模型,誰就是類別y,根據的內容就是x 以上述例子,判斷一個生產出...

styled-components —— React 中的 CSS 最佳實踐
https://zhuanlan.zhihu.com/p/29344146 Styled-components 是目前 React 樣式方案中最受關注的一種,它既具備了 css-in-js 的模塊化與參數化優點,又完全使用CSS的書寫習慣,不會引起額外的學習成本。本文是 styled-components 作者之一 Max Stoiber 所寫,首先總結了前端組件化樣式中的最佳實踐原則,然后在此基...

19.vue中封裝echarts組件
19.vue中封裝echarts組件 1.效果圖 2.echarts組件 3.使用組件 按照組件格式整理好數據格式 傳入組件 home.vue 4.接口返回數據格式...