【java】IO詳解之BIO
注:本篇所寫的io均為java bio體系(即jdk1.0發布的io)
1.IO相關概念一覽
1.1 什么是IO
所謂IO即input和output的縮寫,是對數據的流入和流出的一種抽象,編程中很常見的一個概念。
1.2 什么是流
體會一下這幾個詞:水流(靜止的水想必沒人會叫水流),物流,人流(此人流非彼人流 = =!),可以發現流的特點:動態的,可轉移的,從一處到另一處的
1.3 java io
java為了我們調用方便,而屏蔽輸入/輸出源和流動細節,抽象出的用于解決數據流動問題的類體系,這就是java的io流
1.4 輸入流和輸出流
用于讀取的流稱為輸入流(輸入流只能用來讀),用于寫入的流稱為輸出流(輸出流只能用來寫)。輸入輸出的概念一般是針對內存來說的,流(寫)入內存,從內存流(讀)出。
1.5 字節流和字符流
輸入輸出流可操作最小單位來區分字節流和字符流,最小操作單位是一個字節(8bit)的為字節流,最小操作單位為一個字符(16bit)的為字符流,java io體系中字節操作流以stream結尾,字符操作流以reader和writer結尾
1.6 節點流和包裝(處理)流
1)節點流偏向實現細節,直接與細節打交道,比如FileInputStream,而包裝(處理)流偏功能,以目標功能為抽象,比如PrintStream。
2)區分節點流和包裝(處理)流最簡單的一個方式:處理流的構造方法中需要另一個流作為參數,而節點流構造方法則是具體的物理節點,如上FileInputStream構造法中需要一個文件路徑或者File對象,而PrintStream構造方法中則需要一個流對象
3)包裝流使用了裝飾器模式(什么是裝飾器模式?傳送門),包裝流對節點流進行了一系列功能的強化包裝,讓包裝后的流擁有了更多的操作手段或更高的操作效率,而隱藏節點流底層的復雜性。
1.7 低級流和高級流
低級流和高級流對應的概念即對應上面的節點流和包裝(處理)流概念
1.8 普通流和緩沖流
普通流和緩沖流主要是針對讀寫性能上提出的相對概念。普通流與緩沖流的區別在于一個一個數據的流動還是一堆一堆數據的流動。
1.9 bio,nio,aio
bio:b有兩說,一為base,jdk中最早抽象出的io體系;一為block,jdk 1.0 中的io體系是阻塞的。所以兩說皆有道理,一般我們認為b取block之意
nio:n也有兩說,一為new,針對base而言;一為non-block,針對block而言。
aio:a為asynchronous,異步的,異步io,aio還有個名字叫:nio2
發展歷程:bio(jdk1.0) -> nio(jdk1.4) -> aio(jdk1.7)
2.BIO類體系
2.1 體系圖
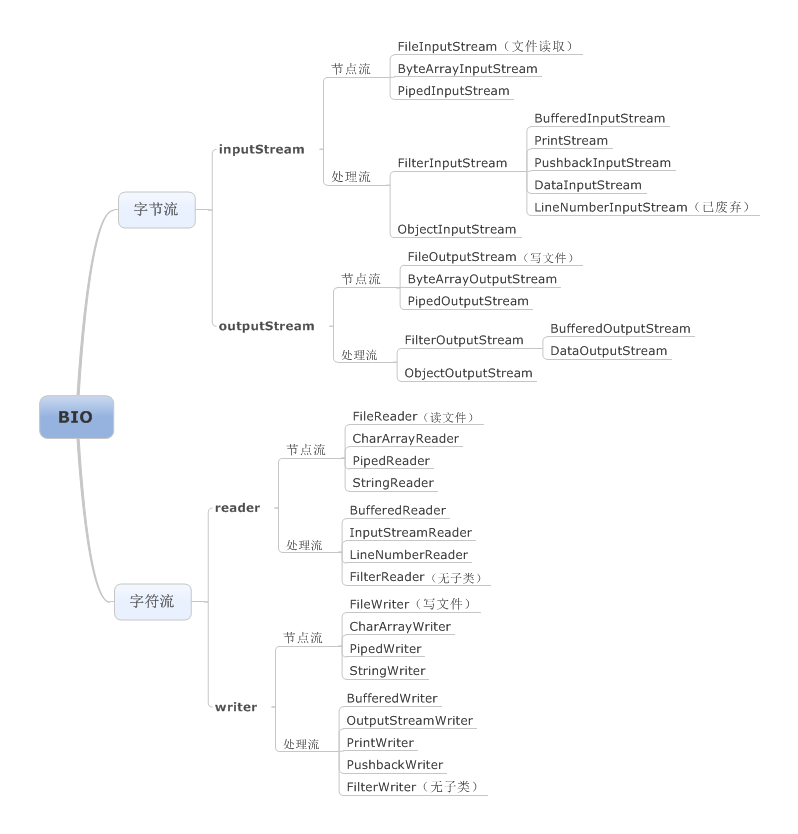
3.BIO體系中的類該怎么使用?
要回答這個問題,我們需要將這個問題進行拆分為下面四個問題
3.1 什么時候該用輸入流,什么時候用輸出流?
從流中讀取信息使用輸入流(xxxInputStream/xxxReader),寫入信息使用輸出流(xxxOutputStream/xxxWriter)
3.2 什么時候該用字節流,什么時候用字符流?
處理純文本數據時使用字符流(xxxReader/xxxWriter),處理非純文本時使用字節流(xxxStream)。最后其實不管什么類型文件都可以用字節流處理,包括純文本,但會增加一些額外的工作量。所以還是按原則選擇最合適的流來處理
3.3 什么時候該用節點流,什么時候用包裝(處理)流?
不管你用什么包裝(處理)流,都需要先使用節點流獲取對應節點的數據流,然后根據具體需求來選擇相應的包裝(處理)流來對節點流進行包裝修飾,從而獲取相應的功能
3.4 什么時候該用普通流,什么時候用緩沖流?
一般如果對數據流不做加工處理,而是單純的讀寫,如數據轉移(拷貝,上傳,下載),則需要使用緩沖流來提高性能,當然你也可以自己使用buff數組來提高讀寫效率。
3.5 使用小結
1)判斷操作的數據類型
純文本數據:讀用Reader系,寫用Writer系
非純文本數據:讀用InputStream系,寫用OutputStream系
如果純文本數據只是簡單的復制,下載,上傳,不對數據內容本身做處理,那么使用Stream系
2)判斷操作的物理節點
內存:ByteArrayXXX
硬盤:FileXXX
網絡:http中的request和response均可獲取流對象,tcp中socket對象可獲取流對象
鍵盤(輸入設備):System.in
顯示器(輸出設備):System.out
3)搞清讀寫順序,一般是先獲取輸入流,從輸入流中讀取數據,然后再寫到輸出流中。
4)是否需增加特殊功能,如需要用緩沖提高讀寫效率則使用BufferedXXX,如果需要獲取文本行號,則使用LineNumberXXX,如果需要轉換流則使用InputStreamReader和OutputStreamWriter,如果需要寫入和讀取對象則使用ObjectOutputStream和ObjectInputStream
4.使用IO流一些注意點
4.1 關于流的read、write方法的使用
下面列出read和write的方法原型(這里以字節流為例,字符流道理相同):
// stream的read
int read();//返回值代表當前讀取的字節(8bit)所對應的整形
int read(byte b[]);//將讀入的數據裝入緩沖區b,實際裝了幾個字節?實際裝了返回值大小個字節,最常使用的read方法
int read(byte b[], int off, int len);//將讀入的數據裝入緩沖區b,從哪開始裝?從off開始,裝幾個字節?裝len個,實際裝了幾個?實際裝了返回值大小個字節
// stream的write
void write(int b);//一次寫入一個字節,寫入的內容是整型b所對應的二進制數據寫入流中
void write(byte b[]);//一次將b數組中的數據寫入流中
write(byte b[], int off, int len);//將b數組中區間為[off,off+len]的數據寫入流中,最常使用的write方法- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果不考慮性能會有如下兩種形式來讀寫:讀入一個字節,寫入一個字節;使用緩沖區讀入一堆字節,然后將緩沖區數據進行寫入輸出流。如下:
//讀一個字節,寫一個字節
int b = 0;
while((b = fis.read()) != -1){
fos.write(b);
}
//讀入一堆,寫入一堆
int b = 0;
byte[] buff = new byte[size];
while((b = fis.read(buff)) != -1){
fos.write(buff,0,b);//將緩沖數組索引區間為[0,b]的數據寫入
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
上面第一種方式讀一個字節寫一個字節沒什么說的;第二個方式則需要注意,調用write(buff,0,b)而不是write(buff,0,buff.length),為什么寫入[0,b]而不是[0,buff.length]區間的數據呢?因為假如只剩余3個字節沒有讀取,而緩沖數組定義的大小是8個字節,那么使用[0,buff.length]則會造成多寫入5個字節的臟數據
4.2 關于流讀寫性能問題
流的讀寫是比較耗時的操作,因此為了提高性能,便有緩沖的這個概念(什么是緩沖?假如你是個搬磚工,你工頭讓你把1000塊磚從A點運到B點,你可以一次拿一塊磚從A點運到B點放下磚,這樣你要來回跑1000次,大多數的時間開銷在路上了;你還可以使用一輛小車,在A點裝滿一車的磚,然后運到B點放下磚,如果一車最多可以裝500塊,那么你來回兩次便可以把這些磚運完。這里的小車便是那個緩沖),在java bio中使用緩沖一般有兩種方式。一種是自己申明一個緩沖數組,利用這個數組來提高讀寫效率;另一種方式是使用jdk提供的處理流BufferedXXX類。下面我們分別演示不使用緩沖讀寫,使用自定義的緩沖讀寫,使用BufferedXXX緩沖讀寫一個文件。
4.21 無緩沖讀寫文件
/**
* 拷貝文件(方法一)
* @param src 被拷貝的文件
* @param dest 拷貝到的目的地
*/
public static void copyByFileStream(File src,File dest){
FileInputStream fis = null;
FileOutputStream fos = null;
long start = System.currentTimeMillis();
try {
fis = new FileInputStream(src);
fos = new FileOutputStream(dest);
int b = 0;
while((b = fis.read()) != -1){//一個字節一個字節的讀
fos.write(b);//一個字節一個字節的寫
}
} catch (Exception e) {
e.printStackTrace();
} finally{
close(fis,fos);
}
System.out.println("使用FileOutputStream拷貝大小"+getSize(src)+"的文件未使用緩沖數組耗時:"+(System.currentTimeMillis()-start)+"毫秒");
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
4.22 自定義數組做緩沖讀寫文件
/**
* 拷貝文件(方法二)
* @param src 被拷貝的文件
* @param dest 拷貝到的目的地
* @param size 緩沖數組大小
*/
public static void copyByFileStream(File src,File dest,int size){
FileInputStream fis = null;
FileOutputStream fos = null;
long start = System.currentTimeMillis();
try {
fis = new FileInputStream(src);
fos = new FileOutputStream(dest);
int b = 0;
byte[] buff = new byte[size];//定義一個緩沖數組
//讀取一定量的數據(read返回值表示這次讀了多少個數據)放入數組中
while((b = fis.read(buff)) != -1){
fos.write(buff,0,b);//一次將讀入到數組中的有效數據(索引[0,b]范圍的數據)寫入輸出流中
}
} catch (Exception e) {
e.printStackTrace();
} finally{
close(fos,fis);
}
System.out.println("使用FileOutputStream拷貝大小"+getSize(src)+"的文件使用了緩沖數組耗時:"+(System.currentTimeMillis()-start)+"毫秒,生成的目標文件大小為"+getSize(dest));
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
4.23 使用BufferedXXX類使用默認大小緩沖來讀寫文件
/**
* 拷貝文件(方法三)
* @param src
* @param dest
*/
public static void copyByBufferedStream(File src,File dest) {
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
long start = System.currentTimeMillis();
try{
bis = new BufferedInputStream(new FileInputStream(src));
bos = new BufferedOutputStream(new FileOutputStream(dest));
int b = 0;
while( (b = bis.read())!=-1){
bos.write(b);//使用BufferedXXX重寫的write方法進行寫入數據。該方法看似未緩沖實際做了緩沖處理
}
bos.flush();
}catch(IOException e){
e.printStackTrace();
}finally{
close(bis,bos);
}
System.out.println("使用BufferedXXXStream拷貝大小"+getSize(src)+"的文件使用了緩沖數組耗時:"+(System.currentTimeMillis()-start)+"毫秒");
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
4.24 使用BufferedXXX類自定義大小緩沖來讀寫文件
/**
* 拷貝文件(方法四)
* @param src 被拷貝的文件對象
* @param dest 拷貝目的地文件對象
* @param size 自定義緩沖區大小
*/
public static void copyByBufferedStream(File src,File dest,int size) {
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
long start = System.currentTimeMillis();
try{
bis = new BufferedInputStream(new FileInputStream(src));
bos = new BufferedOutputStream(new FileOutputStream(dest));
int b = 0;
byte[] buff = new byte[size];
while( (b = bis.read(buff))!=-1){//數據讀入緩沖區
bos.write(buff,0,b);//將緩存區數據寫入輸出流中
}
bos.flush();
}catch(IOException e){
e.printStackTrace();
}finally{
close(bos,bis);
}
System.out.println("使用BufferedXXXStream拷貝大小"+getSize(src)+"的文件使用了緩沖數組耗時:"+(System.currentTimeMillis()-start)+"毫秒");
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
方法測試:
public static void main(String[] args) {
File src = new File("E:\\iotest\\1.bmp");
File dest = new File("E:\\iotest\\1_copy.bmp");
//無緩沖區
copyByFileStream(src,dest);
sleep(1000);
//32k緩沖區
copyByFileStream(src,dest,32);
sleep(1000);
//64k緩沖區
copyByFileStream(src,dest,64);
sleep(1000);
//BufferedOutputStream緩沖區默認大小為8192字節
copyByBufferedStream(src, dest);
sleep(1000);
//BufferedOutputStream緩沖區默認大小為8192*2字節
copyByBufferedStream(src, dest, 8192*2);
}
//我本地測試如下:
使用FileOutputStream拷貝大小864054字節的文件未使用緩沖數組耗時:5092毫秒,生成的目標文件大小為864054字節
使用FileOutputStream拷貝大小864054字節的文件使用了緩沖數組耗時:215毫秒,生成的目標文件大小為864054字節
使用FileOutputStream拷貝大小864054字節的文件使用了緩沖數組耗時:124毫秒,生成的目標文件大小為864054字節
使用BufferedXXXStream拷貝大小864054字節的文件使用了緩沖數組耗時:41毫秒,生成的目標文件大小為864054字節
使用BufferedXXXStream拷貝大小864054字節的文件使用了緩沖數組耗時:8毫秒,生成的目標文件大小為864054字節- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
從上面可以看出來,如果不使用緩沖(4.21)拷貝一個八百多k的文件,竟然要5秒鐘,這個速度讓人捉急啊,所以我們拷貝文件時應該使用緩沖技術。由于這是常用功能,便提供了BuffereXXX類簡化這個工作,上面我們使用BufferedOutputStream(4.23),即使調用write(int b)方法沒有顯示使用緩沖數組為什么性能也大大得到提升?來看看BufferedOutputStream中的部分源碼:
public class BufferedOutputStream extends FilterOutputStream {
/**
* The internal buffer where data is stored.
*/
protected byte buf[];
public BufferedOutputStream(OutputStream out) {
this(out, 8192);
}
public BufferedOutputStream(OutputStream out, int size) {
super(out);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
public synchronized void write(int b) throws IOException {
if (count >= buf.length) {
flushBuffer();
}
buf[count++] = (byte)b;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
從上面BufferedOutputStream中可以看出,構造實例的時候便創造了一個大小為8192字節的緩沖數組,當我們調用write(int b)方法時,并沒有在調用完后直接寫入,而是將每一個傳入的int值放入到了buf中,只有count >= buf.length時,才調用flushBuffer將緩沖區的數據寫入。
4.3 如何判斷文件是否讀寫完畢?
我們一般在處理文件,一般是一邊從輸出流中讀數據,然后將讀出的部分進行處理,最后將處理好的數據寫入到輸出流中。那么要將一個文件完整的處理完,我們必須知道什么時候已經讀到文件的末尾了。
一般來說可以根據read方法返回的值,如果返回了-1表示沒有可讀取的字節了。
另一種是使用available()方法查看還有多少可供讀取的,當輸入流每讀一個字節,available()返回的值便減小1,這種模式很像游標的模式,但要注意的是available的適用場景是非阻塞讀取,如本地文件讀取,如果是網絡io使用該方法,可能你拿到的值就不對了。
總的來說一般輸入流提供的讀取方法是可以獲得文件是否結束的標志,比如流默認的read方法,根據返回值是否非負,比如PrintReader和BufferedReader的readLine()方法,根據返回數據是否非空。
4.4 關于flush()的問題
為什么緩沖輸出流寫數據結束需要調用flush方法?我們以BufferedOutputStream的write(int b)方法源碼為例,源碼如下:
public synchronized void write(int b) throws IOException {
if (count >= buf.length) {
flushBuffer();
}
buf[count++] = (byte)b;
}- 1
- 2
- 3
- 4
- 5
- 6
可以得知,BufferedOutputStream在write時候,只有count >= buf.length,即緩沖區數據填滿的時候才會自動調用flushBuffer()將緩沖區數據進行寫入,也就是說如果緩沖區數據未滿則將不會寫入,這時我們需人為的調用flush()方法將未滿的緩沖區數據進行寫入,如下例,可以看出未flush和flush后的區別。
public static void copyByBufferedStream(File src,File dest,int size) {
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
long start = System.currentTimeMillis();
try{
bis = new BufferedInputStream(new FileInputStream(src));
bos = new BufferedOutputStream(new FileOutputStream(dest));
int b = 0;
byte[] buff = new byte[size];
while( (b = bis.read(buff))!=-1){
bos.write(buff,0,b);
}
System.out.println("拷貝大小"+getSize(src)+"的文件使用了緩沖數組耗時:"+(System.currentTimeMillis()-start)+"毫秒,未flush生成的目標文件大小為"+getSize(dest));
bos.flush();
System.out.println("拷貝大小"+getSize(src)+"的文件使用了緩沖數組耗時:"+(System.currentTimeMillis()-start)+"毫秒,flush后生成的目標文件大小為"+getSize(dest));
}catch(IOException e){
e.printStackTrace();
}
}
//測試
public static void main(String[] args) {
File src = new File("E:\\iotest\\1.bmp");
File dest = new File("E:\\iotest\\1_copy.bmp");
copyByBufferedStream(src, dest, 8192);
}
//測試結果:
拷貝大小864054字節的文件使用了緩沖數組耗時:3毫秒,未flush生成的目標文件大小為860160字節
拷貝大小864054字節的文件使用了緩沖數組耗時:3毫秒,flush后生成的目標文件大小為864054字節- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
從上面測試可以知道,如果未使用flush,帶來的后果可能會造成部分數據丟失,為什么說是可能?因為如果文件大小剛好是緩沖區的整倍數,即最后一次寫入的數據剛好填滿緩沖區,write方法也會自動flushBuffer。另一種原因是,調用close方法后會自動將緩沖區的數據flush,我們看看close方法源碼,由于BufferedOutputStream類中并沒有重寫close方法,因此我們去看看直接父類FilterOutputStream的close,源碼如下:
public void close() throws IOException {
try (OutputStream ostream = out) {
flush();
}
}- 1
- 2
- 3
- 4
- 5
從上可以看出,在調用close后,其實內部調用了flush(),因此我們在調用close后,數據也能保證數據完整寫入,我們驗證下我們剛才的分析:
public static void copyByBufferedStream(File src,File dest,int size) {
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
long start = System.currentTimeMillis();
try{
bis = new BufferedInputStream(new FileInputStream(src));
bos = new BufferedOutputStream(new FileOutputStream(dest));
int b = 0;
byte[] buff = new byte[size];
while( (b = bis.read(buff))!=-1){
bos.write(buff,0,b);
}
System.out.println("拷貝大小"+getSize(src)+"的文件使用了緩沖數組耗時:"+(System.currentTimeMillis()-start)+"毫秒,未flush,未調close生成的目標文件大小為"+getSize(dest));
}catch(IOException e){
e.printStackTrace();
}finally{
close(bos,bis);//一個工具方法,內部調用了輸出流的close方法,文章后面部分可以看到該方法的源碼
System.out.println("拷貝大小"+getSize(src)+"的文件使用了緩沖數組耗時:"+(System.currentTimeMillis()-start)+"毫秒,未flush,調用close后生成的目標文件大小為"+getSize(dest));
}
}
//測試
public static void main(String[] args) {
File src = new File("E:\\iotest\\1.bmp");
File dest = new File("E:\\iotest\\1_copy.bmp");
copyByBufferedStream(src, dest, 8192);
}
//測試結果如下:
拷貝大小864054字節的文件使用了緩沖數組耗時:5毫秒,未flush,未調close生成的目標文件大小為860160字節
拷貝大小864054字節的文件使用了緩沖數組耗時:6毫秒,未flush,調用close后生成的目標文件大小為864054字節- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
這樣的結果確實符合我們對源碼的分析
4.5 關于網絡流中使用available()方法的問題
當你在網絡io中,比如你用socket編程時獲取到的流進行讀寫時,會發現使用available方法有問題,原因是網絡io的特點是:
1.非實時性。你調用available()方法判斷剩余流的大小時,遠端數據可能還未發送,或者要發送的數據處于隊列中,因此通過available()拿到的可用長度可能是0
2.非連續性。由于網絡數據傳輸中,一般會分段多次發送,available僅僅能返回本次的可用長度。
鑒于以上兩個特點,使用available判斷網絡io還有多少數據可讀是不合適的,因此解決該問題一般采用自定義協議,比如文件大小,文件名等信息放入流的頭幾個字節中,接收方根據收到的頭信息來解析出對法傳送的文件大小,根據大小來判斷還剩多少字節需要讀取,是否讀取完畢。
4.6 關于關閉流的問題
1)為什么需要手動關閉?
參見【java】手動釋放資源問題
2) 關閉流的正確寫法
先來兩個不規范的,上代碼:
/**
* 案例一
*/
public static void main(String[] args) {
try {
FileInputStream fis = new FileInputStream(new File("E:\\iotest\\1.bmp"));
FileOutputStream fos = new FileOutputStream(new File("E:\\iotest\\1_copy.bmp"));
//其他代碼
//......
fos.close();
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 案例二
*/
public static void main(String[] args) {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream(new File("E:\\iotest\\1.bmp"));
fos = new FileOutputStream(new File("E:\\iotest\\1_copy.bmp"));
//其他代碼
//......
} catch (IOException e) {
e.printStackTrace();
} finally{
try {
if(fos!=null){
fos.close();
}
if(fis!=null){
fis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
案例一寫法不規范的原因是fis和fos對象執行一些方法時是可能發生異常的,一旦出現異常,雖然由于進行了try catch,但是執行流程會直接進入到catch中,會跳過流的關閉操作。
案例二寫法不規范的原因是,雖然講close操作放入了finally中,但是一旦fos.close執行出現異常,則fis無法正常關閉,修改方法是在finally塊中的同時對每個close都單獨try catch。
因此寫一個關閉流的工具方法,寫法如下:
/**
* 關閉給定的io流
*/
public static void close(Closeable...closes){
for (Closeable closeable : closes) {
try {
if(closeable!=null){
closeable.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 調用close()方法
*/
public static void main(String[] args) {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream(new File("E:\\iotest\\1.bmp"));
fos = new FileOutputStream(new File("E:\\iotest\\1_copy.bmp"));
//其他代碼
//......
} catch (IOException e) {
e.printStackTrace();
} finally{
close(fos,fis);
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
5.java io流到底能干些什么?
java io主要做兩類事情:
1)數據傳輸,實際例子如文件上傳,下載,文件本地拷貝等
2)數據處理,如文本內容加密,圖片處理,文件壓縮,音視頻處理等
6.實踐一下
下面就來個簡單的實踐
6.1 文件拷貝
本文中4.2中的幾個方法均可進行文件拷貝,拷貝一般都會使用緩沖來提高性能
6.2 文本加密
因為我們通過java io流處理可以獲得文本的原始數據,我們在數據上進行加工就可以加密文本,通過相反的方式就可以解密文本,實際生產中當然不會像下面這么簡單的加密,下面我們只是做個示意
public static void encrypt(File src, File dest) {
FileReader fr = null;
FileWriter fw = null;
try {
fr = new FileReader(src);
fw = new FileWriter(dest);
int tmp = 0;
while ((tmp = fr.read()) != -1) {
fw.write(tmp+1);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
close(fw, fr);
}
}
public static void decrypt(File src, File dest) {
FileReader fr = null;
FileWriter fw = null;
try {
fr = new FileReader(src);
fw = new FileWriter(dest);
int tmp = 0;
while ((tmp = fr.read()) != -1) {
fw.write(tmp-1);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
close(fw, fr);
}
}
public static void main(String[] args) {
File src = new File("E:\\iotest\\1.txt");
File dest = new File("E:\\iotest\\1_jiami.txt");
File dest2 = new File("E:\\iotest\\1_jiemi.txt");
encrypt(src, dest);
decrypt(dest, dest2);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
上面代碼中處理方式很簡單,僅僅做了一個字符加1處理,然后解密在字符上進行減1處理,便能達到一個加密解密的效果,效果如下
原始密文:
趙兄托你幫我辦點事- 1
加密后的文本:
趕充扙佡帯戒功為二- 1
解密后的文本:
趙兄托你幫我辦點事- 1
6.3 圖片處理
圖片文件中存放中圖片的分辨率,以及每個像素的色值等信息。我們經常看見如photoshop這類軟件對圖片進行旋轉,扭曲,濾鏡等處理,就是對圖片中的二進制信息進行一個矩陣變換。下面我們試著做一個圖片反相效果。
做這個處理前有兩個問題需要考慮:
1)由于平時使用的jpg采用了壓縮算法,所以圖片中的每個字節并不是圖片本身的像素信息,因此我們選擇一個bmp格式的圖片,來對每一位進行處理,以便達到我們想要的效果。
2)基本所有的二進制文件,圖片,音頻等文件都有一個頭信息,存放該文件的一些基本信息,這些基本信息決定了這個文件是一個bmp圖片或者是個gif圖片或者是個jpg圖片。因此我們對bmp圖片做處理時不能破壞bmp文件的頭信息。我們知道bmp文件很大,是因為他沒有進行壓縮,文件內容保存的是圖片上對應的像素點的顏色值信息,因此我們隊這些顏色值信息做一個處理,即可以得到一些特別的效果。
代碼如下:
public static void imageFilter(File src, File dest) {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream(src);
fos = new FileOutputStream(dest);
int b = 0;
int hasRead = 0;
int headSize = 8*12;
while ((b = fis.read()) != -1) {
hasRead++;
if(hasRead>headSize){
fos.write(-b);
}else{
fos.write(b);
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
close(fos, fis);
}
}
public static void main(String[] args) {
File src = new File("E:\\iotest\\1.bmp");
File dest = new File("E:\\iotest\\1_copy.bmp");
imageFilter(src, dest);//800k的文件執行時間大概好幾秒,比較長,這里只是做個示意處理
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
上面代碼中寫數據時,如果字節長度小于headSize則原樣輸出(headSize我這里取的是12個字節,bmp頭信息具體多大我并沒有去查詢。如果取太小頭信息被破壞,bmp文件將不是bmp文件。因此取幾十個字節只要保證頭信息完整即可。),大于headSize的部分進行一個處理,我們對顏色值取反。效果如下:
原圖: 
處理后圖片:

通過上面三個的示例可以大致了解java io能做些什么。當然上面只是一個簡單的處理,并不能用于實際生產,這里只是說明持有二進制數據,你將可以對文件為所欲為。
智能推薦
IO模型之BIO快速理解
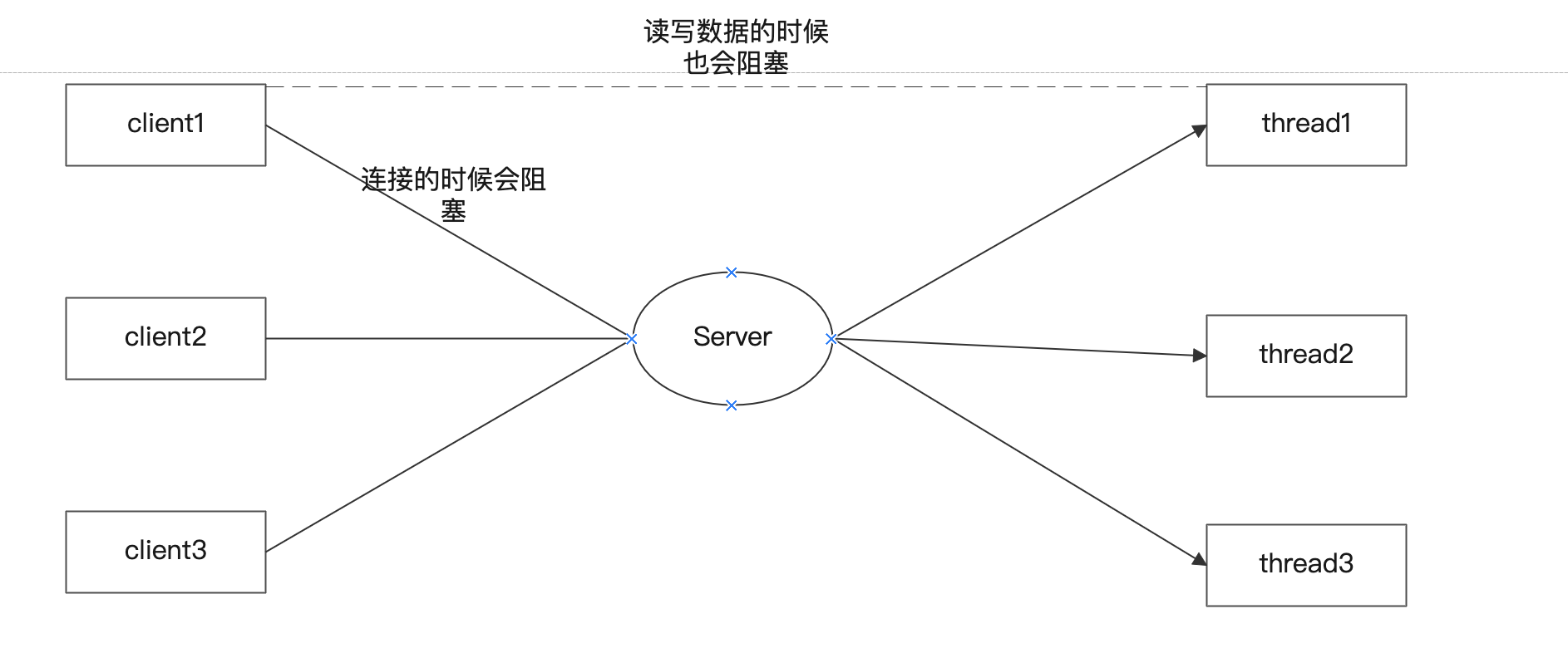
同步-異步-阻塞-非阻塞 說IO模型前先說一下同步-異步-阻塞-非阻塞的區分: 同步、異步關注的是消息通信機制 阻塞、非阻塞關注的是等待消息時的狀態 同步、異步:比如本人去燒一壺水,然后水開之后還是需要本人親自去把水裝在水壺里這叫同步,假如水開后我不用去裝水,由我提前安排好的人去做叫異步。 阻塞、非阻塞:如果在燒水的過程中我必須要在那等著水開叫阻塞,不用等在燒水期間我去做別的叫非阻塞。 快速理解B...
Netty學習(1):IO模型之BIO
概述 Netty其實就是一個異步的、基于事件驅動的框架,其作用是用來開發高性能、高可靠的IO程序。 因此下面就讓我們從Java的IO模型來逐步深入學習Netty。 IO模型 IO模型簡單來說,就是采用如何的方式來進行數據的接受和發送,因為存在著發送方和接收方兩個角色,因此IO模型一般分為以下3類:BIO(同步阻塞)、NIO(同步非阻塞)、AIO(異步非阻塞)。其3者的區別如下: BIO:是最傳統的...
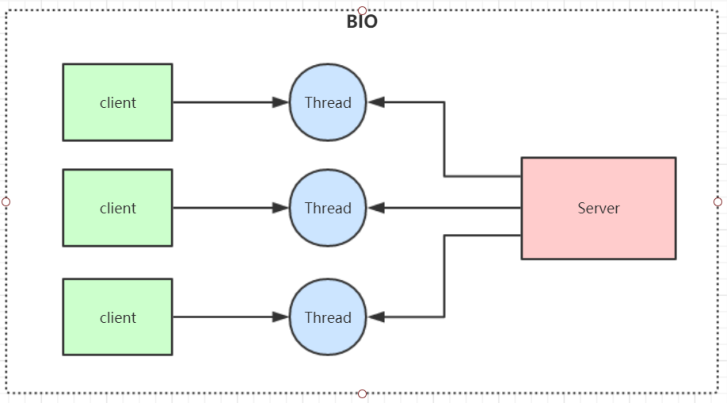
IO模型之BIO,NIO和AIO
目錄 了解IO模型 BIO(Blocking IO) 缺點: 應用場景: NIO(Non Blocking IO) 應用場景: AIO(NIO 2.0) 應用場景: 了解IO模型 IO模型就是說用什么樣的通道進行數據的發送和接收,Java共支持3種網絡編程IO模式:BIO,NIO,AIO BIO(Blocking IO) 同步阻塞模型,一個客戶端連接對應一個處理線程 缺點: 1、IO代碼里read...
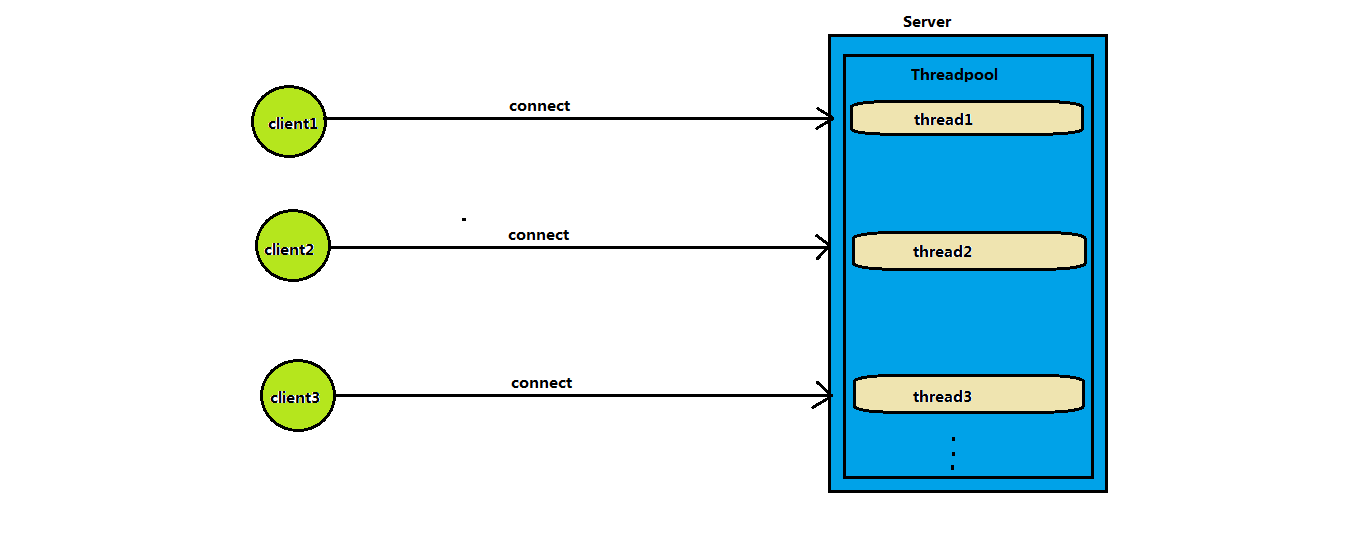
網絡IO模型之BIO與NIO
BIO模型(Blocking-IO) BIO最大的特點是單線程無法處理并發請求除非每連接每線程。每個請求服務器的客戶端,對于服務器來講,都要開辟一個線程去處理該客戶端的IO事件。在操作系統中線程是個開銷不小的資源,如果客戶端只是與服務器建立了連接,并沒有產生IO事件,那么對于服務器來講,為這個客戶端開辟這個線程豈不是在浪費資源?雖然可以使用線程池對服務端進行優化,但是治標不治本圖示: 在JAVA中...
猜你喜歡


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...
