深度學習--【1】Ubuntu下caffe環境搭建,CPU
在Windows下安裝caffe遇到好多奇奇怪怪的問題,于是轉戰Ubuntu,比windows下要簡單很多。
本篇博文主要講解快速搭建caffe環境:
電腦系統:ubuntu 16.04
1、安裝caffe所需要的依賴庫
Caffe的所有依賴包都可以使用apt-get大發搞定。
#在Ubuntu下如果沒有使用root賬號,則每個命令前需要加sudo。
$ sudo apt-get install git
$ sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler
$ sudo apt-get install --no-install-recommends libboost-all-dev
$ sudo apt-get install libatlas-base-dev
$ sudo apt-get install python-dev
$ sudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev
2、下載caffe源碼
我的caffe源碼下載到home目錄下
$ cd ~
$ sudo git clone https://github.com/bvlc/caffe.git
$ cd caffe
下載完成后可以看到caffe的源碼包如下:
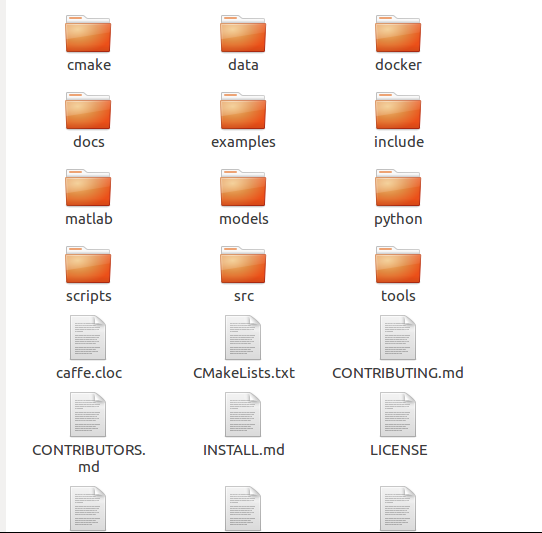
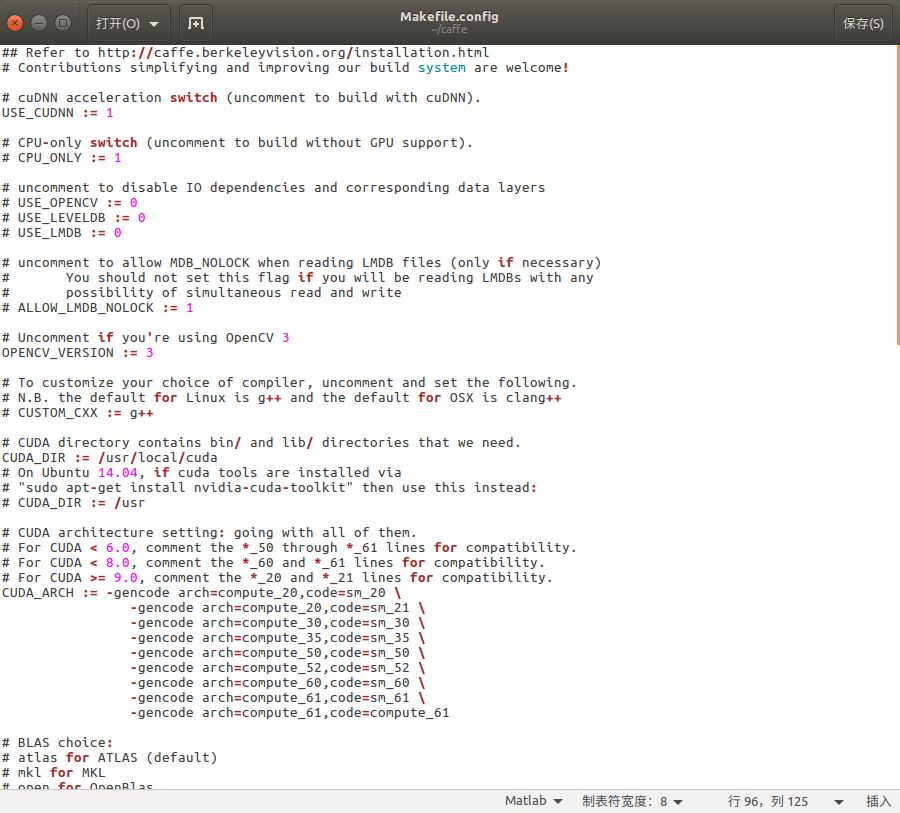
3、配置Make.config文件
caffe文件解壓后,文件夾下面有一個Makefile.config.example文件,我們需要將這個文件復制一份并重命名:Make.config 。
$ sudo cp Makefile.config.example Makefile.config
然后我們打開這個文件,可以看到如下內容:
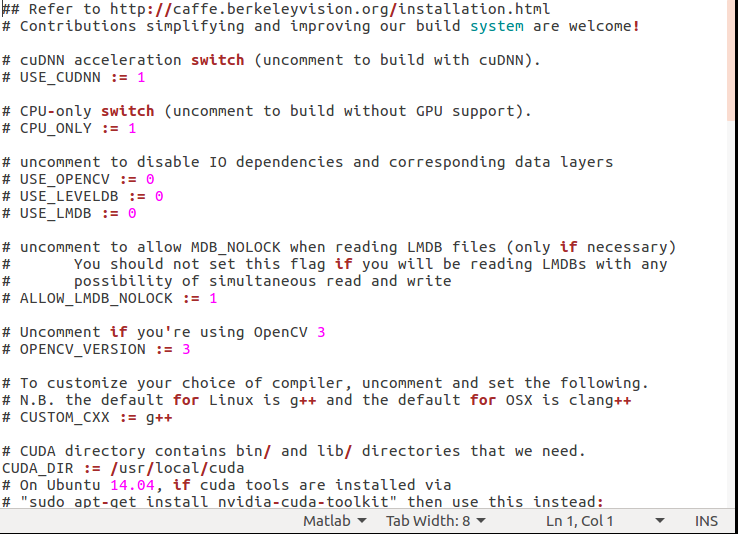
4、編譯
方案一:
(1)在完成Make.config配置后,我們輸入命令:
$ make -j
進行caffe源碼編譯.這一步有可能遇到如下錯誤:
- 錯誤1 caffe/proto/caffe.pb.h: No such file or directory
如果出現這個錯誤,那么輸入命令:
- sudo protoc src/caffe/proto/caffe.proto --cpp_out=.
- sudo mkdir include/caffe/proto
- sudo mv src/caffe/proto/caffe.pb.h include/caffe/proto
然后在進行make -j就可以了
- 錯誤2 hdf5.h: No such file or directory
① 在Makefile.config的95行添加/usr/include/hdf5/serial/ 到INCLUDE_DIRS也就是把下面第一行代碼改為第二行代碼
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include- 1
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/include/hdf5/serial/- 1
② 在Makefile文件的第173行,把 hdf5_hl 和hdf5修改為hdf5_serial_hl 和 hdf5_serial,也就是把下面第一行代碼改為第二行代碼。
LIBRARIES += glog gflags protobuf boost_system boost_filesystem m hdf5_hl hdf5- 1
LIBRARIES += glog gflags protobuf boost_system boost_filesystem m hdf5_serial_hl hdf5_serial 然后在進行make -j就可以了
(2)編譯成功后編譯python接口,輸入命令
- make pycaffe
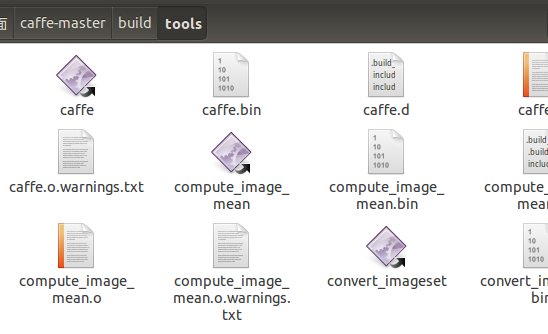
這個文件夾下面的工具可是個好東西啊,以后我們會經常用到這些可執行文件,最常用的就是可執行文件:caffe,我們只要調用這個工具,就可以進行訓練。
- 錯誤1 numpy/arrayobject.h No such file or directory
如果出現這個錯誤,那么輸入命令:
sudo apt-get install python-numpy
方案二:直接采用cmake:
- mkdir build
- cd build
- cmake ..
- make all -j8
安裝完了,自然要測試一下能不能用咯。首先cd到caffe目錄,然后輸入命令:
- ./data/mnist/get_mnist.sh
- ./examples/mnist/create_mnist.sh
- sudo vim examples/mnist/lenet_solver.prototxt
把lenet_solver.prototxt里面的solver_mode 改為 CPU。因為我們還沒裝GPU,暫時只使用CPU就好了。
./data/mnist/get_mnist.sh下載MNIST數據集,下載完成后,在data/mnist下會出現四個文件:
t10k-images-idx3-ubyte 測試圖片數據
t10k-labels-idx1-ubyte 測試標簽
train-images-idx3-ubyte 訓練圖片數據
train-labels-idx1-ubyte 訓練標簽
因為下載完的數據為二進制文件,需要轉換為LEVELDB或LMDB才能被caffe識別,因此執行./examples/mnist/create_mnist.sh 生成
可以通過修改create_mnist.sh中的BACKEND="lmdb"或者BACKEND="leveldb"來選擇生成數據格式。
執行完create_mnist.sh以后,在examples/mnist下生成兩個文件夾mnist_train_lmdb和mnist_test_lmdb兩個目錄,每個目錄下都有兩個文件data.mdb和lock.mdb,顧名思義,mnist_train_lmdb就是生成的LMDB格式的MNIST數據集,mnist_test_lmdb則為LMDB格式的測試集。
然后我們運行腳本:
- ./examples/mnist/train_lenet.sh
訓練完成以后,會在mnist文件夾下生成lenet_iter_10000.caffemodel
7、測試
利用訓練好的模型權值文件(examples/mnist/lenet_iter_10000.caffemodel)可以對測試數據集(或外部測試集)進行預測,運行如下命令:
$ ./build/tools/caffe test \
-model examples/mnist/lenet_train_test.prototxt \
-weights examples/mnist/lenet_iter_10000.caffemodel \
-iterations 100
命令行解釋:
- ./build/tools/caffe test, 表示只做預測(前向傳播計算),不進行參數更新(后向傳播計算)
- -model examples/mnist/lenet_train_test.prototxt, 指定模型描述文件文件
- -weights examples/mnist/lenet_iter_10000.caffemodel, 指定模型預先訓練好的權值文件。
- -iterations 100,指定測試迭代次數。參與測試的樣例數目為(iterations * batch_size),batch_size在model prototxt中設定,為100時正好覆蓋全部10000個測試樣本。
智能推薦
Ubuntu16+Anaconda3+tensorflow(cpu),深度學習環境搭建
摘要: 引言 Anaconda3安裝 tensorflow(cpu)安裝 spyder安裝 1.引言 最近需要研究基于深度學習的語義分割,了解到語義分割有二維與三維的領域。還是先了解一下二維語義分割方面的,選定了deeplab和mobileNet。所以先搭建一下簡單的深度學習環境,算是新手入門。 WINDOWS10+ubuntu16.04雙系統 NVIDIA 940m顯卡,2GB獨立顯存 用下面命...
深度學習框架Caffe在Ubuntu下編譯安裝
國內相關教程都互相借鑒大同小異,于是連出錯的方式也雷同,所以借鑒了國外多個技術論壇,寫一篇配置教程。 環境: 操作系統: Ubuntu 16.04 GCC/G++:5.4.0 CUDA:9.0.252 OpenCV: 2.4.11和3.3.1 Matlab :R2014b(a) Python: 2.7 1.在安裝的路徑下 clone : 2.進入 caffe ,Makefile.config....
linux(ubuntu)下安裝深度學習框架caffe
953 首先在Linux下安裝OpenCV 3.0 安裝過程: 1. 安裝依賴項 查看是否安裝成功: 2. 安裝OpenCV 3 這里使用opencv3.0.0-beta版本,最好使用一樣的,否則可能要折騰很久。這里直接網上搜索下載即可,下載后傳到linux中,如果要在linux上下載可能會很慢。 下載完成后解壓 注意了:這一步開始編譯opencv,這里會出現要下載ippicv_lin...
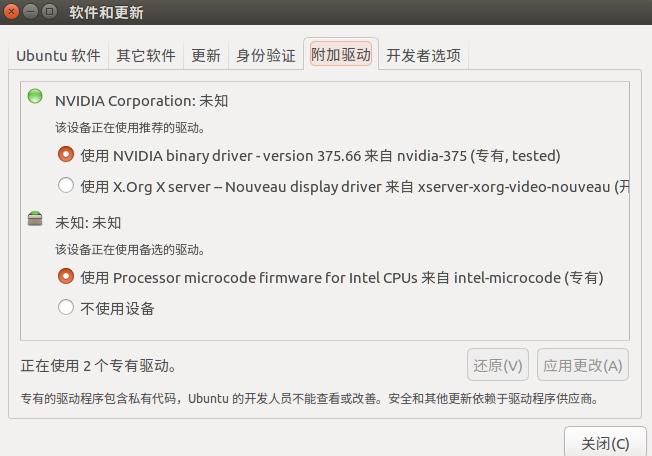
Ubuntu 16.04下配置深度學習庫caffe
博主是在T_H學長的幫助下完成安裝的,考慮到很多人應該需要一個比較詳細的安裝過程,特意寫下此教程,以及博主在安裝過程中遇到的問題及solution。 T_H學長的安裝過程鏈接,大家可以結合參考 ** 1. 安裝Nvidia顯卡驅動 ** 在系統設置->軟件和更新->附加驅動中:將NVIDIA Corporation里的選項選為第一項。完成后需要重啟。 ** 2. 安裝CUDA 8.0 ...
linux(ubuntu)下安裝深度學習框架caffe
本文所使用的的ubuntu的環境為16.04,為了安裝的順利,請先安裝opencv,詳見:Linux下安裝OpenCV 3.0 1. 安裝依賴項 建議不要一次安裝這么多,以免出錯可以排除錯誤: 1 2 3 4 5 6 7 1 2 3 4 5 6 7 2. 下載caffe源碼 1 2 3 4 1 2 3 4 3. 配置Makefile文件 修改默認的配置。打開文件:sudo gedit Makefi...
猜你喜歡
caffe學習筆記:windows環境下caffe-window安裝(CPU版)
配置:win7_64bit+VS2013 準備工作:下載微軟官方提供的caffe安裝包,下載地址:https://github.com/Microsoft/caffe,下載完畢解壓到目標文件夾即可,筆者放置在E盤根目錄中。 一、修改配置文件 打開E:\caffe-master\caffe-master\windows,找到CommonSettings.props.example文件復制(原文件作為...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...