深度學習Caffe實戰筆記(7)Caffe平臺下,如何調整卷積神經網絡結構
授人以魚不如授人以漁,紅鯉魚家有頭小綠驢叫驢屢屢。至于修改網絡結構多虧了課題組大師姐老龐,在小米實習回校修整,我問她怎么修改網絡,她說改網絡就是改協議,哎呀,一語驚醒夢中人啊!老龐師姐,你真美!雖然博主之前也想過修改網絡協議試一試,鑒于一直不懂網絡結構中的各個參數是干啥的,所以一直沒去實施,這次終于開始嘗試了。
caffe平臺實現卷積神經網絡實在方便的很啊,只需要一個協議文件定義一下網絡結構,再定義一個超參協議文件即可。這里請注意我的措辭哈,只是介紹如何修改網絡結構,而不是如何合理的修改網絡結構,什么樣的網絡才是好的,這暫時還沒有一個明確的定義,大多數研究者還處于試一試的階段,如果誰能把這個問題搞清楚,估計能拿一個圖靈獎了。
開始trian。
以Alexnet為例
原始的Alexnet是這個樣子的(頁面問題只可視化部分好了): 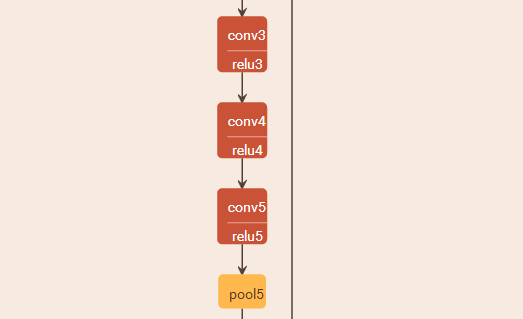
相應的協議文件中的部分:
layer {
name: "conv3"
type: "Convolution"
bottom: "pool2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
我們想要在第四個卷積層后再加上一層,怎么辦呢?只需要修改相應的協議即可:
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv4_p" #添加一層
type: "Convolution"
bottom: "conv4" #輸入層
top: "conv4_p" #修改一下
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu4_p" #添加一個relu4_p
type: "ReLU"
bottom: "conv4_p" #修改一下
top: "conv4_p" #修改一下
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4_p" #輸入層修改一下
top: "conv5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0.1
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
修改后的網絡結構如下:
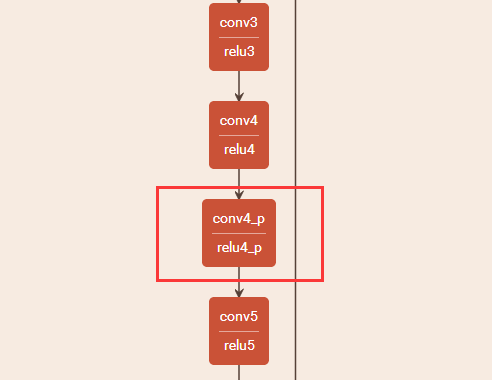
其中conv4_p和relu4_p就是我們自己添加進去的一個卷積層。訓練一下修改后的網絡,看精度會不會提升。。。。。哈哈哈
那么我們再做另一種修改如下: 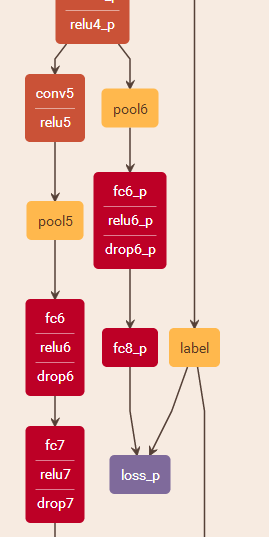
想要實現這樣的分支怎么實現呢?這里就不做解釋了,授人以魚不如授人以漁,紅鯉魚家有頭小綠驢叫驢屢屢。自己摸索一下吧。。。。
寫在后面的話:
再次強調一下,只是介紹了如何修改網絡結構,而不是如何合理的修改網絡結構,這篇博客僅僅介紹采用哪種手段和可以修改網絡結構,而不是如何修改網絡結構使效果更好。。。。。知道了如何修改網絡結構,那么搭建自己的網絡也不是什么難事了吧,授人以魚不如授人以漁,紅鯉魚家有頭小綠驢叫驢屢屢,又來了,又來了。哈哈哈
這幾篇博客里的內容從最初的如何搭建網絡,到如何用網絡跑標準數據集,到用現有的網絡跑自己的數據集,再到如何修改和搭建自己的網絡,基本上涵蓋了caffe使用的主要環節,供大家學習參考,我也是剛剛學習,所以有寫錯和不合適的地方還請大家及時批評指正。后續如果再有時間,我想補充一篇關于網絡協議文件參數說明的博客。再后續如果再更新博客,我想做深度學習的基礎理論和公式推導之類的工作,畢竟實戰加深度才是王道。。。。。
最后用王國維先生的三境界來結束這幾個博客:昨夜西風凋碧樹,獨上高樓,望盡天涯路;衣帶漸寬終不悔,為伊消得人憔悴;眾里尋他千百度,眸然回首,那人卻在燈火闌珊處。
智能推薦

Caffe網絡結構實現
對于神經網絡實現手寫數字識別(MNIST)網絡結構通過在線可視化工具查看和修改: (http://ethereon.github.io/netscope/#/editor ) 一、卷積層(Convolution) 輸入為28*28的圖像,經過5*5的卷積之后,得到一個(28-5+1)*(28-5+1) = 24*24的map。 每個map是不同卷積核在前一層每個map上進行卷積,并將每個對應位置上...
caffe網絡結構解析
一、均值文件是什么: 下面是make_imagenet_mean.sh里面的內容 可以看出用compute_image_mean.exe執行了均值文件計算,而且只計算了my_train_leveldb 的均值,這是訓練數據。 均值文件是通過訓練集計算出來的,測試集不需要計算出均值文件。在訓練階段和測試階段都是用的訓練集的均值文件。 均值的理論概念參考:http://ufldl.stanford.e...
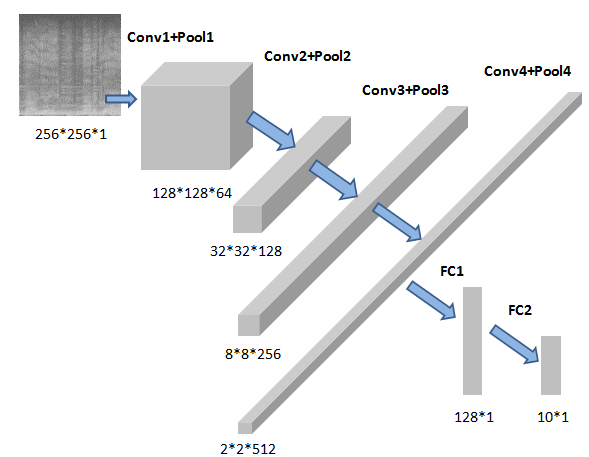
基于深度學習的音樂推薦系統(二)用于語譜圖分類的卷積神經網絡結構
Tensorflow1.13 極客云GPU服務器 極客云注冊地址 用這個鏈接可以免費獲得10元優惠券,好像是不需要充值就可以用。 本系統用單核GPU,最便宜的那種就行。 該CNN的訓練樣本分為兩類 一共10類音頻,每類100首歌曲,每首歌曲分割為11張圖。即每類1100張圖。 訓練集:每類的前1000張圖。 測試集:每類的后100張圖。 代碼如下: 輸入數據是256*256*1的形狀。...
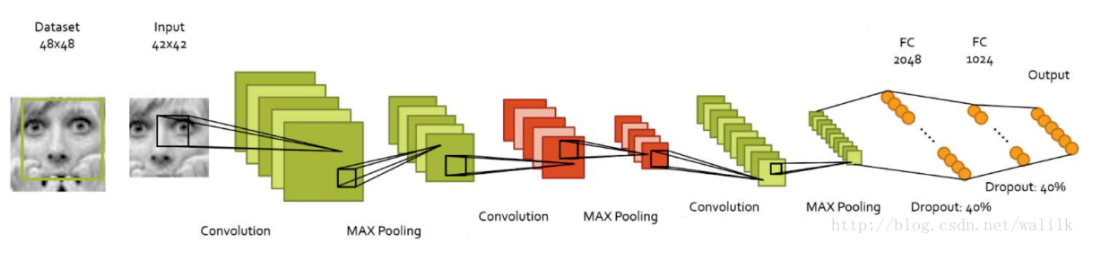
【深度學習】基于caffe的表情識別(三):搭建網絡結構
《基于caffe的表情識別》系列文章索引:http://blog.csdn.net/pangyunsheng/article/details/79434263 一、caffe網絡模型規則 在caffe中,最常見的就是搭建一個卷積神經網絡模型來解決一個識別問題,就如本例中,我們就是在alexnet上做適當修改,得到我們的卷積神經網絡模型,在這里我簡單稱...
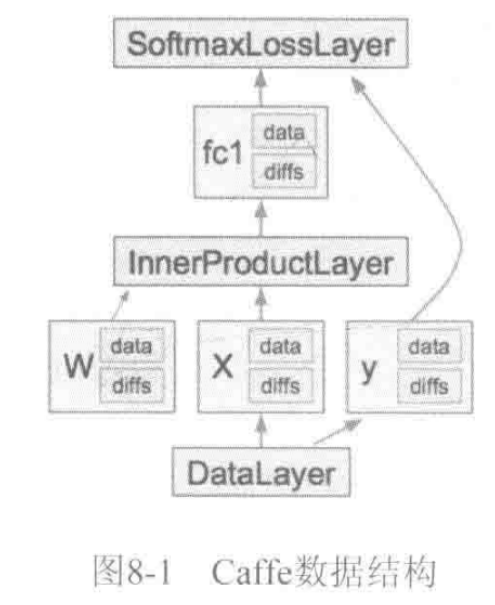
《深度學習——實戰caffe》——caffe數據結構
caffe中一個CNN模型由Net表示,Net由多個Layer堆疊而成。 caffe的萬丈高樓(Net)是由圖紙(prototxt),用blob這些磚塊筑成一層層(Layer),最后通過SGD方法(Solver)進行簡裝修(train)、精裝修(finetune)實現的。 Blob數據結構介紹 Blob提供了統一的存儲器接口,TensorFlow中的Tensor也有對應的Blob數據結構。 Caf...
猜你喜歡

【TensorFlow實戰Google深度學習框架】學習筆記(圖像識別與卷積神經網絡)
1、圖像識別經典數據集Cifar cifar是32x32x3的彩色圖片集 2、卷積神經網絡簡介 3、卷積神經網絡常用的結構 3.1卷積層 Filter的深度就是Filter的個數 3.2池化層 4、經典卷積神經網絡模型 卷積神經網絡結構的問題 卷積層和池化層的參數配置問題 5、卷積網絡的遷移學習 遷移學習可以總結為在別人成功的模型(網絡結構和訓練好的參數)的基礎上修改、增減自己的網絡結構。這樣做的...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...