Python爬蟲入門筆記
最近又學了一遍爬蟲的入門,記住步驟立刻就上手了
1.獲取頁面源代碼
5個小步驟:
1.偽裝成瀏覽器
2.進一步包裝請求
3.網頁請求獲取數據
4.解析并保存
5.返回數據
代碼:
import urllib.request,urllib.error #指定URL,獲取頁面數據
#爬取指定url
def askUrl(url):
#請求頭偽裝成瀏覽器(字典)
head = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3776.400 QQBrowser/10.6.4212.400"}
#進一步包裝請求
request = urllib.request.Request(url = url,headers=head)
#存儲頁面源代碼
html = ""
try:
#頁面請求,獲取內容
response = urllib.request.urlopen(request)
#讀取返回的內容,用"utf-8"編碼解析
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reson"):
print(e.reson)
#返回頁面源代碼
return html
2.獲取標簽
通過BeautifulSoup進一步解析頁面源代碼
from bs4 import BeautifulSoup #頁面解析,獲取數據
Beautiful Soup 將復雜 HTML 文檔轉換成一個復雜的樹形結構,每個節點都是 Python 對象,可分為四大對象種類,這里主要用到Tag類的對象,還有三種,有興趣可以自己去深入學習~~
#構建了一個BeautifulSoup類型的對象soup
#參數為網頁源代碼和”html.parser”,表明是解析html的
bs = BeautifulSoup(html,"html.parser")
#找到所有class叫做item的div,注意class_有個下劃線
bs.find_all('div',class_="item")
3.正則表達式匹配
先準備好相應的正則表達式,然后在上面得到的標簽下手
#Python正則表達式前的 r 表示原生字符串(rawstring)
#該字符串聲明了引號中的內容表示該內容的原始含義,避免了多次轉義造成的反斜杠困擾
#re.S它表示"."的作用擴展到整個字符串,包括“\n”
#re.compile()編譯后生成Regular Expression對象,由于該對象自己包含了正則表達式
#所以調用對應的方法時不用給出正則字符串。
#鏈接
findLink = re.compile(r'<a href="(.*?)">',re.S)
#找到所有匹配的
#參數(正則表達式,內容)
#[0]返回匹配的數組的第一個元素
link = re.findall(findLink,item)[0]
4.保存數據
兩種保存方式
1.保存到Excel里
import xlwt #進行excel操作
def saveData(dataList,savePath):
#創建一個工程,參數("編碼","樣式的壓縮效果")
woke = xlwt.Workbook("utf-8",style_compression=0)
#創建一個表,參數("表名","覆蓋原單元格信息")
sheet = woke.add_sheet("豆瓣電影Top250",cell_overwrite_ok=True)
#列明
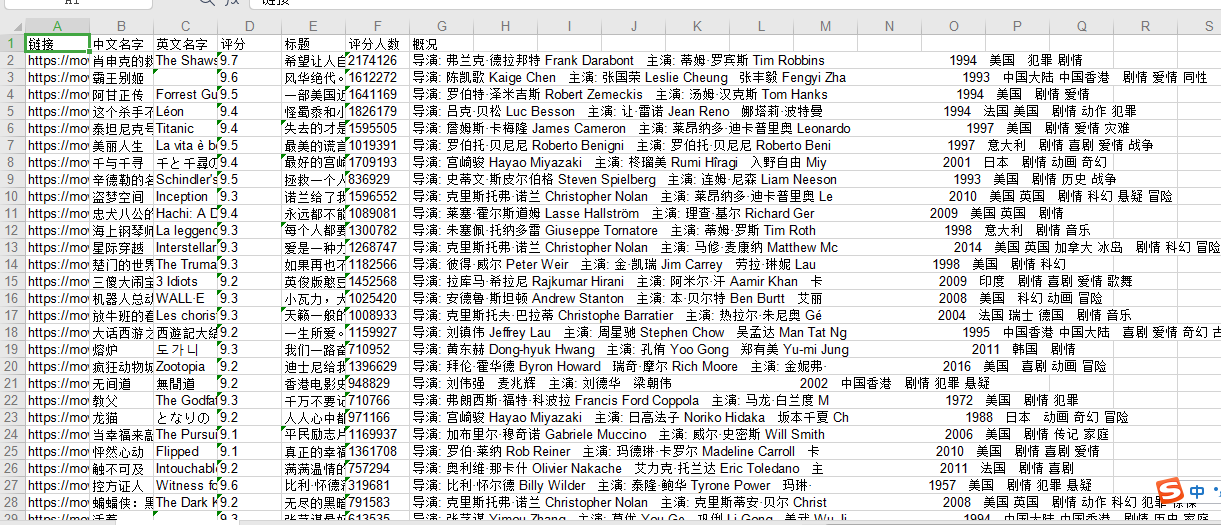
col = ("鏈接","中文名字","英文名字","評分","標題","評分人數","概況")
#遍歷列名,并寫入
for i in range (7):
sheet.write(0,i,col[i])
#開始遍歷數據,并寫入
for i in range (0,250):
for j in range (7):
sheet.write(i+1,j,dataList[i][j])
print("第%d條數據"%(i+1))
#保存數據到保存路徑
woke.save(savePath)
print("保存完畢")
結果文件:
2.保存到數據庫
import sqlite3 #進行sql操作
#新建表
def initdb(dataPath):
#連接dataPath數據庫,沒有的話默認新建一個
conn = sqlite3.connect(dataPath)
#獲取游標
cur = conn.cursor()
#sql語句
sql = '''
create table movie(
id Integer primary key autoincrement,
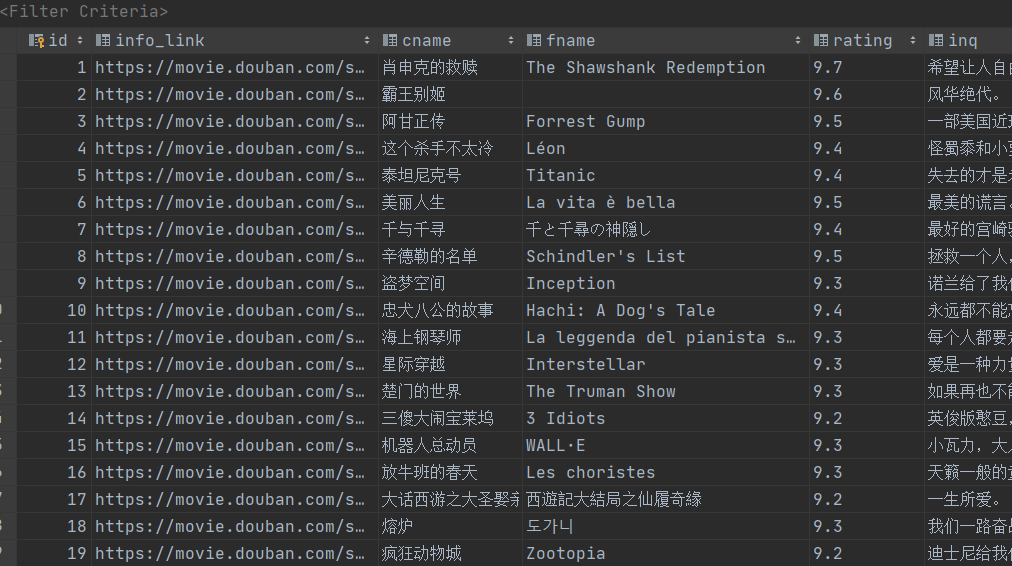
info_link text,
cname varchar ,
fname varchar ,
rating varchar ,
inq text,
racount varchar ,
inf text
)
'''
#執行sql語句
cur.execute(sql)
#提交事物
conn.commit()
#關閉游標
cur.close()
#關閉連接
conn.close()
def savedb(dataList,dataPath):
#新建表
initdb(dataPath)
#連接數據庫dataPath
conn = sqlite3.connect(dataPath)
#獲取游標
cur = conn.cursor()
#開始保存數據
for data in dataList:
for index in range(len(data)):
#在每個數據字段兩邊加上""雙引號
data[index] = str('"'+data[index]+'"')
#用","逗號拼接數據
newstr = ",".join(data)
#sql語句,把拼寫好的數據放入sql語句
sql ="insert into movie(info_link,cname,fname,rating,inq,racount,inf)values(%s)"%(newstr)
print(sql)
#執行sql語句
cur.execute(sql)
#提交事務
conn.commit()
#關閉游標
cur.close()
#關閉連接
conn.close()
print("保存完畢")
結果文件:

爬取豆瓣TOP250的所有代碼
from bs4 import BeautifulSoup #頁面解析,獲取數據
import re #正則表達式
import urllib.request,urllib.error #指定URL,獲取頁面數據
import xlwt #進行excel操作
import sqlite3 #進行sql操作
def main():
baseUrl = "https://movie.douban.com/top250?start="
#1.爬取網頁,并解析數據
dataList = getData(baseUrl)
# savePath=".\\豆瓣電影Top250.xls"
savePath = "movies.db"
#2.保存數據
# saveData(dateList,savePath)
savedb(dataList,savePath)
#---正則表達式---
#鏈接
findLink = re.compile(r'<a href="(.*?)">',re.S)
#電影名字
findName = re.compile(r'<span class="title">(.*?)</span>',re.S)
#評分
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>')
#標題
findInq = re.compile(r'<span class="inq">(.*?)</span>',re.S)
#評分人數
findCount = re.compile(r'<span>(.*?)人評價</span>')
#電影信息
findInf = re.compile(r'<p class="">(.*?)</p>',re.S)
#1.爬取網頁
def getData(baseUrl):
dataList = []
for i in range(10):
html = askUrl(baseUrl + str(i * 25))
# 2.逐一解析數據
bs = BeautifulSoup(html,"html.parser")
for item in bs.find_all('div',class_="item"):
data = []
item = str(item)
#鏈接
link = re.findall(findLink,item)[0]
#名字
name = re.findall(findName,item)
if len(name) == 1:
cName = name[0]
fName = " "
else:
name[1] = name[1].replace(" / ","")
cName = name[0]
fName = name[1]
#評分
rating = re.findall(findRating,item)[0]
#標題
inq = re.findall(findInq,item)
if len(inq) < 1:
inq = " "
else:
inq= inq[0]
#評分人數
racount = re.findall(findCount,item)[0]
#電影信息
inf = re.findall(findInf,item)[0]
inf = re.sub("...<br(\s+)?/>(\s?)"," ",inf)
inf = re.sub("/"," ",inf)
inf = inf.strip()
#添加一部電影的信息進data
data.append(link)
data.append(cName)
data.append(fName)
data.append(rating)
data.append(inq)
data.append(racount)
data.append(inf)
dataList.append(data)
return dataList
#爬取指定url
def askUrl(url):
head = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3776.400 QQBrowser/10.6.4212.400"}
request = urllib.request.Request(url = url,headers=head)
http = ""
try:
response = urllib.request.urlopen(request)
http = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reson"):
print(e.reson)
return http
# 3.保存數據
def saveData(dataList,savePath):
woke = xlwt.Workbook("utf-8",style_compression=0)#樣式的壓縮效果
sheet = woke.add_sheet("豆瓣電影Top250",cell_overwrite_ok=True)#覆蓋原單元格信息
col = ("鏈接","中文名字","英文名字","評分","標題","評分人數","概況")
for i in range (7):
sheet.write(0,i,col[i])
for i in range (0,250):
for j in range (7):
sheet.write(i+1,j,dataList[i][j])
print("第%d條數據"%(i+1))
woke.save(savePath)
print("保存完畢")
#3.保存到數據庫
def savedb(dataList,dataPath):
initdb(dataPath)
conn = sqlite3.connect(dataPath)
cur = conn.cursor()
#開始保存數據
for data in dataList:
for index in range(len(data)):
data[index] = str('"'+data[index]+'"')
newstr = ",".join(data)
sql ="insert into movie(info_link,cname,fname,rating,inq,racount,inf)values(%s)"%(newstr)
print(sql)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
print("保存完畢")
#3-1新建表
def initdb(dataPath):
conn = sqlite3.connect(dataPath)
cur = conn.cursor()
sql = '''
create table movie(
id Integer primary key autoincrement,
info_link text,
cname varchar ,
fname varchar ,
rating varchar ,
inq text,
racount varchar ,
inf text
)
'''
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
if __name__ == "__main__":
#調用函數
main()
愉快爬蟲:
遵守 Robots 協議,但有沒有 Robots 都不代表可以隨便爬,可見下面的大眾點評百度案;
限制你的爬蟲行為,禁止近乎 DDOS的請求頻率,一旦造成服務器癱瘓,約等于網絡攻擊;
對于明顯反爬,或者正常情況不能到達的頁面不能強行突破,否則是 Hacker行為;
最后,審視清楚自己爬的內容,以下是絕不能碰的紅線(包括但不限于): 作者:張凱強
鏈接:https://www.zhihu.com/question/291554395/answer/514982754
來源:知乎
著作權歸作者所有。
智能推薦

Python爬蟲(入門+進階)學習筆記 1-2 初識Python爬蟲
本人Mac + Anaconda(Python3) + PyCharm + Chrome 簡單來說,Anaconda是包管理器和環境管理器。Anaconda 附帶了一大批常用數據科學包,它附帶了 conda、Python 和 150 多個科學包及其依賴項。因此你可以立即開始處理數據。Anaconda 是在 conda(一個包管理器和環境管理器)上發展出來的。在數據分析中,你會用到很多第三方的包,而...

Python爬蟲-Request入門
安裝Requests庫 requests.get()-獲取百度首頁信息 爬取網頁的通用代碼框架 HTTP協議及requests方法: HTTP協議:超文本傳輸協議 基于“請求與響應”模式的無狀態的應用層協議。無狀態-第一次和第二次請求沒有關聯。應用層-在TCP協議之上 URL:http://host【:port】【path】 host:Internet 主機域名。port:...

Python爬蟲簡易入門
文章目錄 什么是爬蟲 查看網頁源代碼 寫一個最簡單的爬蟲 結果分析 什么是爬蟲 查看網頁源代碼 我們首先打開進入瀏覽器打開搜狐網 然后點擊鼠標右鍵選擇查看網頁源代碼 我們發現網站背后都是一些數據,如果我們可以用一個自動化的程序輕輕松松就能把它們給爬取下來是不是很爽?比如,一些圖片和電影的網站,我們只要用 Python 寫幾行代碼然后一運行這個程序就幫我們爬取所有的圖片和電影到我們本地,完全不需要我...

猜你喜歡


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...
