01---爬蟲簡介
爬蟲簡介
1.通訊協議
1.1端口
我們想要進行數據通訊分幾步?
1.找到對方ip
2.數據要發送到對方指定的應用程序上。為了標識這些應用程序,所以給這些網絡應用程序都用數字進行了標識。為了方便稱呼這個數字,就把這個數字叫做”端口“,這里的端口我們一般叫做邏輯端口。
3.定義通訊規則。這個通訊規則我們一般稱之為協議。
1.2通訊協議
。國際組織定義了通用的通訊協議TCP/IP協議
。所謂協議就是指計算機通訊網絡中兩臺計算機之間進行通訊所必須共同遵守的規則或規定
。HTTP又叫做超文本傳輸協議(是一種通訊協議)HTTP的端口是80
2.網絡模型
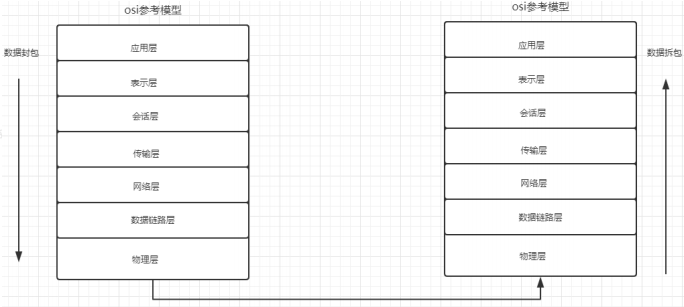
更新了新的參考模型TCP/IP參考模型
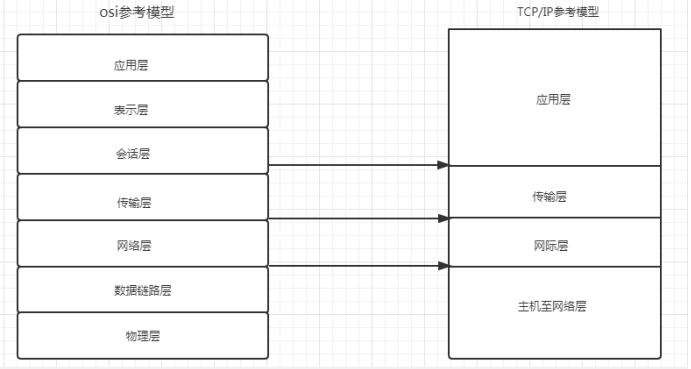
2.1 HTTPS是什么呢?
。https=http+ssl,顧名思義https是在http的基礎上加上了ssl保護殼,信息的加密過程就是在ssl中完成的
。https,是以安全為目標的HTTP通道,簡單的講是HTTP的安全版。即HTTP下加入SSL層,HTTPS的安全基礎是SSL
2.2 SLL怎么理解

2.3 HTTP請求與響應
HTTP通訊由兩部分組成:客戶端請求信息與服務器響應消息

1.當用戶在瀏覽器的地址欄中輸入一個URL并按回車鍵之后,瀏覽器會向HTTP服務器發送HTTP請求。HTTP請求主要分為”Get“和”Post"兩種方法。
2當我們在瀏覽器中輸入URL http://www.baidu.com的時候,瀏覽器會發送一個Request請求去獲取 http://www.baidu.com 的html文件,服務器把Response文件對象發送回給瀏覽器。
3.瀏覽器分析Response中的html,發現其中引用了很多其他文件,比如images文件,CSS文件,JS文件,瀏覽器會自動再次發送Request去獲取圖片,CSS文件,或者JS文件。
4.當所有的文件都下載成功后,網頁會根據HTML語法結構,完整的顯示出來。
2.4 客戶端的HTTP請求
URL只是標識資源的位置,而HTTP是用來提交和獲取資源,客戶端發送一個HTTP請求到服務器請求信息,包括以下格式:
請求行、請求頭部、空行、請求數據四個部分組成下圖給出了請求報文的一般格式

一個典型的HTTP請求示例
1 GET / HTTP/1.1
2 Host: www.baidu.com
3 Connection: keep-alive
4 Cache-Control: max-age=0
5 Upgrade-Insecure-Requests: 1
6 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKi
t/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Safari/537.36
7 Sec-Fetch-Mode: navigate
8 Sec-Fetch-User: ?1
9 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,ima
ge/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
10 Sec-Fetch-Site: same-origin
11 Referer: https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&
tn=baidu&wd=Python%20%20%E6%89%8B%E5%8A%A8%E5%9B%9E%E6%94%B6%E5%9
E%83%E5%9C%BE&oq=Python%2520%25E6%2594%25B6%25E5%2588%25B0%25E5%2
59B%259E%25E6%2594%25B6%25E5%259E%2583%25E5%259C%25BE&rsv_pq=f5ba
abda0010c033&rsv_t=1323wLC5312ORKIcfWo4JroXu16WSW5HqZ183yRWRnjWHa
eeseiUUPIDun4&rqlang=cn&rsv_enter=1&rsv_dl=tb&inputT=2315&rsv_sug
3=48&rsv_sug2=0&rsv_sug4=2736
12 Accept-Encoding: gzip, deflate, br
13 Accept-Language: zh-CN,zh;q=0.9
14 Cookie: BIDUPSID=4049831E3DB8DE890DFFCA6103FF02C1;
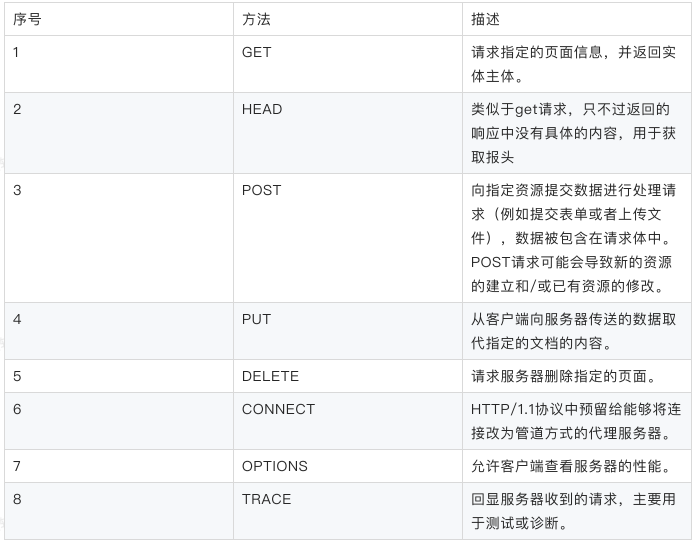
請求方法
根據HTTP標準,HTTP請求可以使用多種請求方法。
HTTP 0.9:只有基本的?本 GET 功能。
HTTP 1.0:完善的請求/響應模型,并將協議補充完整,定義了三種請求?法:
GET, POST 和 HEAD?法。
HTTP 1.1:在 1.0 基礎上進?更新,新增了五種請求?法:OPTIONS, PUT,
DELETE, TRACE 和 CONNECT ?法。
HTTP 2.0(未普及):請求/響應?部的定義基本沒有改變,只是所有?部鍵
必須全部?寫,?且請求?要獨?為 :method、:scheme、:host、:path這些
鍵值對。
3.爬蟲介紹
3.1 什么是爬蟲
。簡單的一句話就是代替人去模擬瀏覽器進行網頁操作
3.2.為什么需要爬蟲呢
。為其他程序提供數據源,如搜索引擎(百度、Google等)、數據分析、大數據等
3.3企業獲取數據的方式
。1.公司自有數據
。2.第三方平臺購買數據(百度指數、數據堂)
。3.爬蟲爬取的數據
3.4 Python做爬蟲的優勢
。PHP:對多線程,異步支持不太好
。Java:代碼量大,代碼笨重
。C/C++:代碼量大,難以編寫
。Python:支持模塊多,代碼簡潔,開發效率高(scrapy框架)
3.5 爬蟲的分類
。通??絡爬? 例如 baidu google yahu
。聚焦?絡爬?: 根據既定的?標有選擇的抓取某?特定主題內容
。增量式?絡爬?: 指對下載??采取增量式的更新和只爬?新產?的或者已經
發?變化的??爬?
。深層?絡爬?: 指那些?部分內容不能通過靜態鏈接獲取的、隱藏在搜索表單
后的,只有?戶提交?些關鍵詞才能獲得的web?? 例如 ?戶登錄注冊才能
訪問的??
4.幾個概念
4.1 get和post
。GET : 查詢參數都會在URL上顯示出來
。POST : 查詢參數和需要提交數據是隱藏在Form表單?的,不會在URL地址上
顯示出來
4.2 URL組成部分
。URL: 統?資源定位符
。https://new.qq.com/omn/TWF20200/TWF2020032502924000.html
。https: 協議
。new.qq.com: 主機名可以將主機理解為?臺名叫 news.qq.com 的機器。這
臺主機在 qq.com 域名下
。port 端?號: 80 /new.qq.com 在他的后?有個 :80 可以省略
。TWF20200/TWF2020032502924000.html 訪問資源的路徑
。#anchor: 錨點?前端在做??定位的
。注意 : 在瀏覽器請求?個url,瀏覽器會對這個url進??個編碼。(除英?字
?、數字和部分標識其他的全部使?% 加 ?六進制碼進?編碼)
例如 : https://tieba.baidu.com/f?ie=utf8&kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&fr=search
%E6%B5%B7%E8%B4%BC%E7%8E%8B = 海賊王
4.3 User-Agent 用戶代理
。作?:記錄?戶的瀏覽器、操作系統等,為了讓?戶更好的獲取HTML??效果
User-Agent:
Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36
Mozilla Firefox:(Gecko內核)
4.4 Refer
表明當前這個請求是從哪個url過來的。?般情況下可以?來做反爬的技術
4.5 狀態碼
。200:請求成功
。301:永久重定向
。302:臨時重定向
。403:服務器拒絕請求
。404:請求失敗(服務器無法根據客戶端的請求找到資源(網頁))
。500:服務器內部請求
5. 抓包工具

。Elements : 元素 ??源代碼,提取數據和分析數據(有些數據是經過特殊處
理的所以并不是都是準確的)
。Console : 控制臺 (打印信息)
。Sources : 信息來源 (整個?站加載的?件)
。NetWork : ?絡?作(信息抓包) 能夠看到很多的??請求
智能推薦
01.node簡介
node是什么玩意? 簡單的說 Node.js 就是運行在服務端的 JavaScript。 Node.js 是一個基于Chrome JavaScript 運行時建立的一個平臺。 Node.js是一個事件驅動I/O服務端JavaScript環境,基于Google的V8引擎,V8引擎執行Javascript的速度非常快,性能非常好。 怎么玩? 1、安裝node https://nodejs.org/z...
mybatis01-簡介
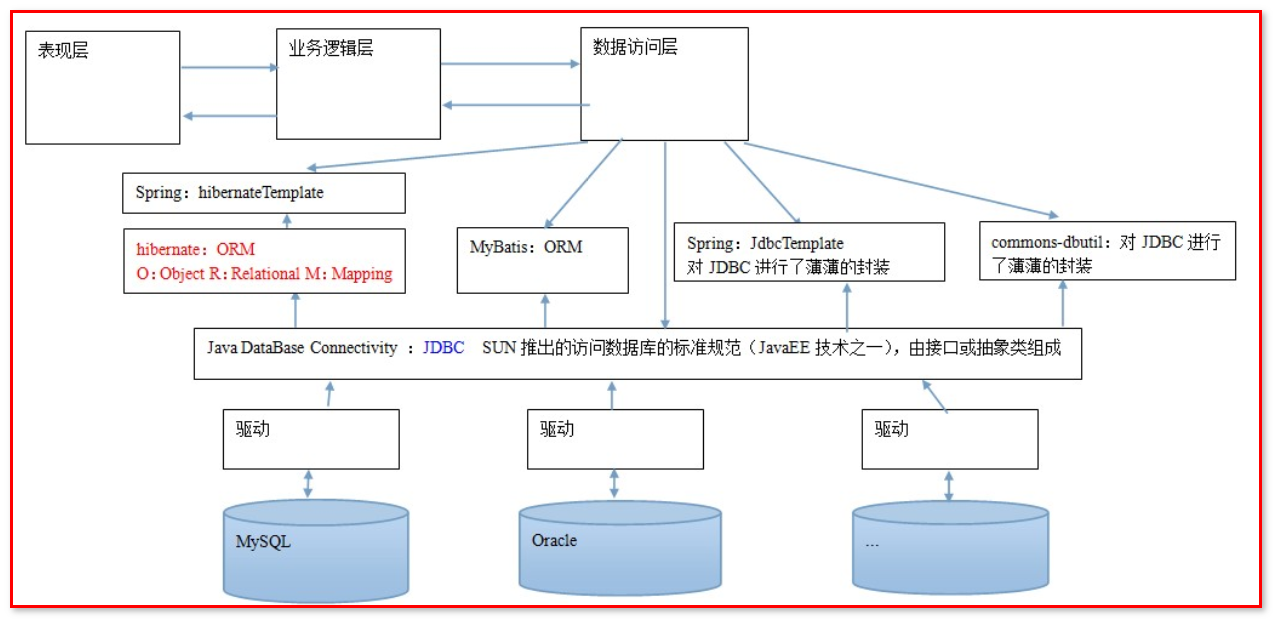
文章目錄 0.拓展 1.jdbc操作數據庫 1.1 maven依賴 1.2 java代碼 1.3 傳統 JDBC 的弊端 2.現階段數據訪問層框架 2.什么是mybatis 2.1 參考手冊 2.2 mybatis架構 3.helloword(xml) 4.mybatis全局注解詳解 5.mybatis注解實現 5.1 mybatis-config.xml 5.2 UserMapper 6.Myb...

01 ElasticSearch簡介
01 ElasticSearch簡介 1.1什么是ElasticSearch Elaticsearch,簡稱為es, es是一個開源的高擴展的分布式全文檢索引擎,它可以近乎實時的存儲、檢索數據;本 身擴展性很好,可以擴展到上百臺服務器,處理PB級別的數據。es也使用Java開發并使用Lucene作為其核心來實 現所有索引和搜索的功能,但是它的目的是通過簡單的RESTful API來隱藏Lucene...

【01】Git簡介
簡介 Git是一個分布式版本控制系統(Distributed Version Control System,簡稱 DVCS)。 特點 直接記錄快照,而非差異比較 近乎所有操作都是本地操作 Git保證完整性 git數據庫中保存的信息都是以文件內容的哈希值來索引,而不是文件名。 Git一般只添加數據 三種狀態 狀態 描述 已提交(committed) 數據已經安全的保存在本地數據庫中 已修改(modi...
01.JVM簡介
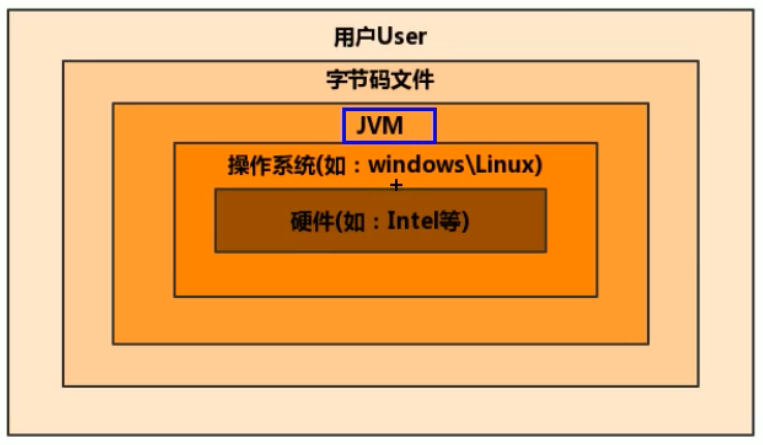
01.JVM簡介 計算機系統當中JVM所處的位置 Java一次編譯,到處運行 Java代碼的執行流程 JVM體系結構概覽 棧的指令集架構和寄存器的指令集架構 jvm生命周期 1.啟動 2.執行 3.退出 jvm發展歷程 Android虛擬機 DVM 計算機系統當中JVM所處的位置 JVM是運行在操作系統之上的,并沒有和硬件有直接的交互 JVM屬于系統虛擬機 Java一次編譯,到處運行 Java代碼...
猜你喜歡
Qt基礎簡介-01
一、常用快捷鍵 ctrl + /:注釋 ctrl + r:運行 ctrl + b:編譯 ctrl + f:查找 F1:選擇目標后幫助文檔 ctrl +i:代碼自動對齊 F4:同名文件.h和.cpp之間的切換 二、創建Qt項目 1、選擇桌面應用程序 2、在Qt Creator中來創建項目時選擇MinGW編譯套件,MSVC2017是在VS中創建項目時的編譯器 3、類信息的設置 1)QWidget是 Q...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...