SQLite3源碼學習(32) WAL日志詳細分析
在前面2篇文章講了有關WAL日志相關的一些基礎知識:
接下來分析一下在WAL日志模式下,整個事務的處理機制和流程
1.原子提交
事務管理最核心的特性就是滿足原子提交特性,之前的回滾日志模式實現了這個特性,而WAL日志模式也實現了原子提交的特性。
在WAL日志模式下有3個文件,分別是:
1.數據庫文件,文件名任意,例如"example.db"
2.WAL日志文件,在數據庫文件名后加-wal,例如"example.db-wal"
3.WAL-index文件,在數據庫文件名后加-shm,例如"example.db-shm"
WAL日志和回滾日志最大的區別是,在WAL模式下,修改過的數據并不直接寫入到數據庫,而是先寫入到WAL日志。過一段時間后,通過檢查點操作將WAL日志中修改的新頁替換數據庫文件的老頁。
WAL日志模式下,對數據庫的操作主要有4種:
1.讀數據
2.寫數據
3.檢查點操作,把WAL日志的新頁同步到數據庫
4. WAL-index文件恢復操作
所謂原子提交特性,就是在寫數據寫到一半時出現系統崩潰或斷電后,事務對數據庫的修改只能處于初始狀態或完成狀態,而不能處于中間狀態。
和回滾日志一樣,在開始一個寫事務之前,首先要有一個讀事務將要修改的頁讀到內存中。讀數據時,最新修改的還沒同步到數據庫的頁從WAL日志讀取,其他的頁在數據庫中讀取,WAL-index文件是一個共享內存文件。
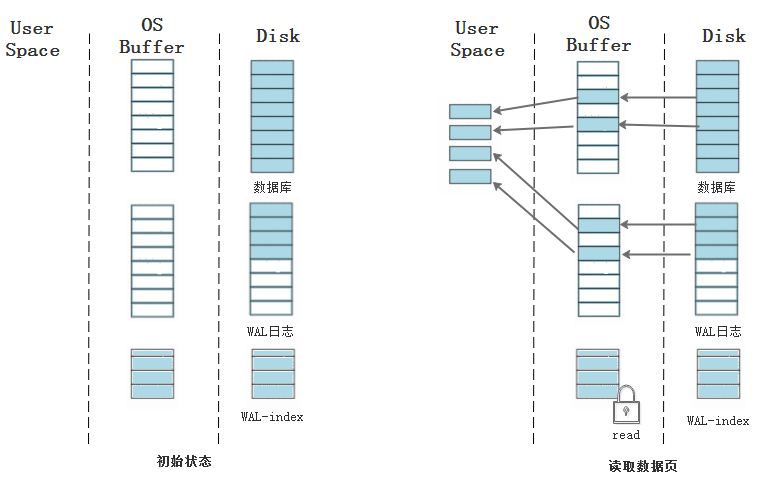
在把要修改的頁讀取到內存中后就可以對其修改,修改前需要對WAL-index文件加上寫鎖,修改完畢后將修改的頁追加到WAL日志的末尾(即第mxFrame幀之后),在提交事務時,在最后一幀寫入數據庫長度,把WAL新添加的幀索引和頁號記錄到WAL-index文件中,最后更新WAL-index頭部的mxFrame字段。
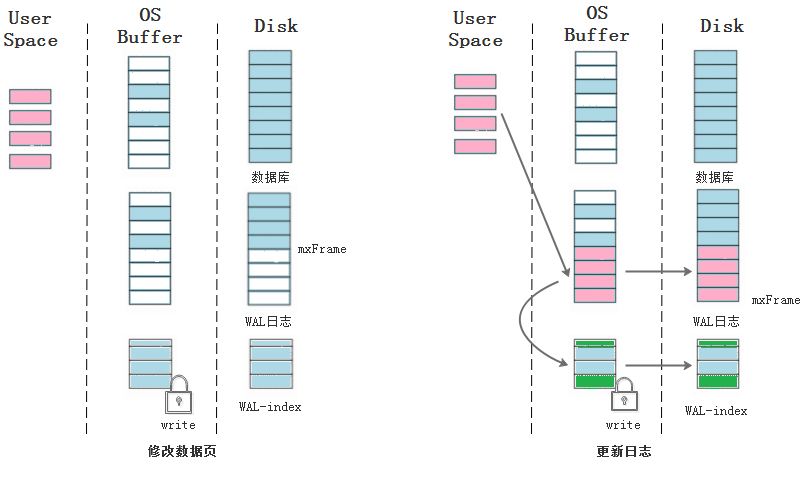
經過上一個步驟之后,事實上寫事務已經完成了。雖然這些新修改的頁沒有同步到數據庫中,但是讀取的時候會通過WAL-index文件查詢有哪些新修改的頁在WAL文件中還沒同步到數據庫,如果在WAL文件中則在WAL文件中讀取,否則從數據庫中讀取。
SQLite會定期把WAL日志中的頁回填到數據庫中,默認是WAL到了1000幀的時候執行檢查點操作,把從nBackfill到mxFrame的頁寫回到數據庫,如果寫到一半出現異常并不會影響事務繼續正常進行,因為讀事務讀取這些頁面是在WAL日志中讀取。在WAL日志和數據庫同步完畢后,如果現在沒有讀事務,WAL-index頭部字段的mxFrame復位為0,下一次向WAL日志追加數據時從頭開始。
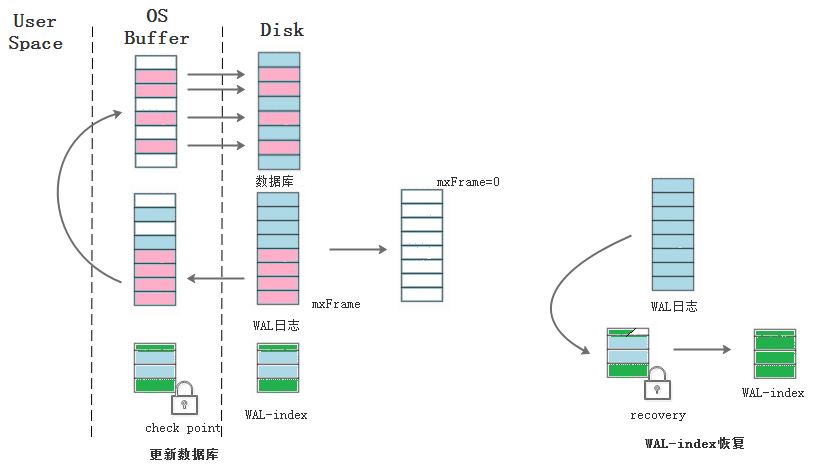
回寫數據庫出現異常并不影響事務的正常進行,寫WAL日志異常頁不會對事務的原子性有什么影響,事務只有在提交時才在WAL-index文件中更新mxFrame字段,如果在此前出現事務失敗,剛寫入WAL末尾的數據將會被忽略掉。如果在寫WAL-index的時候中斷,下一次開始讀事務時會檢測到頭部異常,需要根據WAL日志的對WAL-index文件進行恢復,WAL-index文件出錯會影響接下來讀寫的正確性。
2.WAL的優缺點
優點:
1.并發優勢
在WAL模式中,寫數據只是向WAL末尾添加數據,而讀事務開始前,會做一個read-mark標記,只讀read-mark之前的數據,所以寫事務和讀事務完全并發互不干擾。而回滾日志模式,在寫事務把修改提交到數據庫時會獲取獨占鎖,阻止其他讀事務的開始,一定程度影響了讀寫的并發。
2.寫速度優勢
在回滾日志中,寫數據到數據庫前需要先把原始數據寫入到日志中,并對日志刷盤,再寫記錄到日志頭,再刷盤,最后才把數據寫入到數據庫,這里出現了多次磁盤I/O操作,而WAL模式需一次向WAL日志寫入數據即可,而且也能保持事務的原子性。而且寫WAL日志都是按順序寫入的,相對于離散寫入的也更快。
缺點:
1.需要共享內存
在WAL模式下,需要額外提供一個WAL-index文件,同時需要操作系統支持對該文件的共享內存訪問,這就限制了所有進程訪問數據庫必須要在同一臺機器上。
2.不支持多文件
WAL模式下沒有回滾機制,所以一個事務處理多個文件時,并不能保證整體的原子性。而回滾日志模式,可以把多個數據庫的日志關聯到master日志里,事務恢復時可以進行整體回滾。
3.讀性能會略有下降
因為每次讀數據庫之前都會通過WAL-index文件查找要讀的頁是否在日志中,會產生一些額外的損耗。
4.WAL文件可能會很大
在讀事務一直持續進行時,一直沒有機會把WAL日志里的內容更新到數據庫,會使WAL文件變得很大。
3.讀事務的實現
在開始讀數據之前,需要通過sqlite3WalBeginReadTransaction()開啟一個讀事務,并檢查此時有沒有寫事務對數據庫進行改動,如果有改動的話,清除頁緩存。
下面來一步步分析實現,首先要獲取WAL-index文件頭
rc =walIndexReadHdr(pWal, pChanged);
在這里需要先判斷WAL-index有沒有變更,先來看一些WAL-index的頭部格式:
Bytes | Description |
0..47 | First copy of the WAL Index Information |
48..95 | Second copy of the WAL Index Information |
96..135 | Checkpoint Information and Locks |
可以看到WAL Index頭部為48字節,后面48~95偏移位置還有一份拷貝。為什么同一個頭部要記錄2次呢?
把前面48字節記為h1,接下來的拷貝部分記為h2,讀是先讀h1再讀h2,而寫是先寫h2再寫h1,如果讀到的h1和h2不同,就說明在寫入WAL-index頭部出現中斷或正在寫入,此時如果無法獲取寫鎖,那需要等待將文件頭寫完再開始,如果可以獲取寫鎖,說明是上一次出現損壞,需要對文件頭修復。
static int walIndexTryHdr(Wal *pWal, int *pChanged){
u32 aCksum[2]; /* Checksum on the header content */
WalIndexHdr h1, h2; /* Two copies of the header content */
WalIndexHdr volatile *aHdr; /* Header in shared memory */
//walShmBarrier(pWal);保證讀取h1和h2是嚴格按照先后次序
aHdr = walIndexHdr(pWal);
memcpy(&h1, (void *)&aHdr[0], sizeof(h1));
walShmBarrier(pWal);
memcpy(&h2, (void *)&aHdr[1], sizeof(h2));
//文件頭損壞,未初始化,校驗值不對都需要重新恢復
if( memcmp(&h1, &h2, sizeof(h1))!=0 ){
return 1; /* Dirty read */
}
if( h1.isInit==0 ){
return 1; /* Malformed header - probably all zeros */
}
walChecksumBytes(1, (u8*)&h1, sizeof(h1)-sizeof(h1.aCksum), 0, aCksum);
if( aCksum[0]!=h1.aCksum[0] || aCksum[1]!=h1.aCksum[1] ){
return 1; /* Checksum does not match */
}
……
/* The header was successfully read. Return zero. */
return 0;
}恢復WAL-index文件由walIndexRecover()函數實現
static int walIndexRecover(Wal *pWal){
//獲取全部類型的獨占鎖,此時不能進行任何其他操作
iLock = WAL_ALL_BUT_WRITE + pWal->ckptLock;
nLock = SQLITE_SHM_NLOCK - iLock;
rc = walLockExclusive(pWal, iLock, nLock);
if( rc ){
return rc;
}
//校驗WAL日志頭部,校驗不通過不恢復WAL-index的頁號索引,只初始化WAL-index頭部
……
//校驗通過時讀取WAL日志的所有幀,將其頁號和幀號寫入到WAL-index文件索引。
//這里需要注意的是校驗WAL日志每一幀的頭部時是一個循環檢驗的過程,即上一幀的校驗值輸出需要作為下一幀的校驗值輸入
for(iOffset=WAL_HDRSIZE; (iOffset+szFrame)<=nSize; iOffset+=szFrame){
u32 pgno; /* Database page number for frame */
u32 nTruncate; /* dbsize field from frame header */
/* Read and decode the next log frame. */
iFrame++;
//讀取WAL日志的幀
rc = sqlite3OsRead(pWal->pWalFd, aFrame, szFrame, iOffset);
if( rc!=SQLITE_OK ) break;
//校驗讀取的幀的頭部
isValid = walDecodeFrame(pWal, &pgno, &nTruncate, aData, aFrame);
if( !isValid ) break;
//把頁號和幀號添加到索引
rc = walIndexAppend(pWal, iFrame, pgno);
if( rc!=SQLITE_OK ) break;
……
}
//完畢后釋放鎖
walUnlockExclusive(pWal, iLock, nLock);
return rc;
}獲取WAL-index頭部信息后,還要獲取讀鎖,如果不需要從WAL日志中讀取時獲取0號讀鎖
if( !useWal && pInfo->nBackfill==pWal->hdr.mxFrame){
//此時WAL日志和數據庫已經完全同步
rc = walLockShared(pWal, WAL_READ_LOCK(0));
……
}如果日志和數據沒有完全同步,那么需要從1~4號讀鎖中獲取一把,每一種鎖都對應一個pInfo->aReadMark[i],這個讀標記記錄了擁有該鎖的讀事務在WAL中所能讀取的最大幀。
如果有一個鎖空閑,將該鎖的ReadMark設為mxFrame,并獲取該鎖。如果沒有鎖空閑,那么找到ReadMark最大的鎖并獲取。
最終讀取頁面時,只查看pInfo->nBackfill+1~pInfo->aReadMark[i]的幀是否在WAL日志中,pInfo->nBackfill之前的幀在數據庫中讀取。在檢查點操作時,不能將pInfo->aReadMark[i]之后的幀同步到數據庫,否則會影響讀事務的正確性。
這部分加鎖的代碼比較繁瑣,就不再貼出。
4.寫事務的實現
寫事務的實現基本全在sqlite3WalFrames()函數里,首先要獲取一把獨占的寫鎖。在開始寫事務之前必定開始了一個讀事務,讀取數據庫的第一頁。下面通過注釋來說明代碼的關鍵地方,很多細節的地方略去
int sqlite3WalFrames(
Wal *pWal, /* Wal handle to write to */
int szPage, /* Database page-size in bytes */
PgHdr *pList, /* List of dirty pages to write */
Pgno nTruncate, /* Database size after this commit */
int isCommit, /* True if this is a commit */
int sync_flags /* Flags to pass to OsSync() (or 0) */
){
//檢查WAL日志和數據庫是否完全同步,
//如果已經完全同步,獲取0號讀鎖
//將mxFrame的值設為0,即從頭開始寫WAL日志
if( SQLITE_OK!=(rc = walRestartLog(pWal)) ){
return rc;
}
iFrame = pWal->hdr.mxFrame;
//如果這是第一幀,寫入WAL日志頭
if( iFrame==0 ){
…….
}
//為了便于理解把這塊代碼從頭移到這里
// iFirst初始為0,如果WAL-index頭被改變
//則為當前事務WAL添加的第一幀
pLive = (WalIndexHdr*)walIndexHdr(pWal);
if( memcmp(&pWal->hdr, (void *)pLive, sizeof(WalIndexHdr))!=0 ){
iFirst = pLive->mxFrame+1;
}
//遍歷所有的臟頁,寫入數據
for(p=pList; p; p=p->pDirty){
int nDbSize; /* 0 normally. Positive == commit flag */
//在當前的寫事務內,可能會多次調用寫數據函數
//如果這一幀在之前寫過,則只寫入幀數據
//不寫入幀頭
if( iFirst && (p->pDirty || isCommit==0) ){
u32 iWrite = 0;
VVA_ONLY(rc =) sqlite3WalFindFrame(pWal, p->pgno, &iWrite);
assert( rc==SQLITE_OK || iWrite==0 );
if( iWrite>=iFirst ){
//這里非常關鍵,記下所有重寫的幀中最小的一個
// iReCksum為開始校驗的幀,幀頭是一個連續的循環校驗
if( pWal->iReCksum==0 || iWrite<pWal->iReCksum ){
pWal->iReCksum = iWrite;
}
//覆蓋已經寫入的數據幀,暫時不修改幀頭,之后統一修改
……
p->flags &= ~PGHDR_WAL_APPEND;
continue;
}
}
//如果該幀沒寫過,幀號+1
iFrame++;
assert( iOffset==walFrameOffset(iFrame, szPage) );
nDbSize = (isCommit && p->pDirty==0) ? nTruncate : 0;
//這里會寫入幀頭
rc = walWriteOneFrame(&w, p, nDbSize, iOffset);
if( rc ) return rc;
pLast = p;
iOffset += szFrame;
p->flags |= PGHDR_WAL_APPEND;
}
/* Recalculate checksums within the wal file if required. */
//事務提交時,需要從pWal->iReCksum開始重新校驗
if( isCommit && pWal->iReCksum ){
rc = walRewriteChecksums(pWal, iFrame);
if( rc ) return rc;
}
//如果最后一幀需要在幀頭寫入數據庫大小代表事務提交了
//此后如果需要提交事務,要做的事情為:
//1.將WAL日志刷入磁盤
//2.將所有新增的幀的頁號和幀號寫入WAL-index文件
//3.更新WAL-index文件頭
……
}4.檢查點的實現
檢查點就是把WAL日志中最新的幀同步到數據庫,默認為1000幀之后同步。在同步之后可以選擇是否將日志文件的長度截斷為0。
檢查點需要更新的幀從從nBackfill開始到pInfo->aReadMark[i]結束,這里代碼通過一個迭代器,把WAL-index的每一塊記錄的幀都按照頁號排序,按照頁號從小到大更新到數據庫,如果頁號相同,選擇后面的幀,因為后面的幀比前面要新。
static int walCheckpoint(
Wal *pWal, /* Wal connection */
sqlite3 *db, /* Check for interrupts on this handle */
int eMode, /* One of PASSIVE, FULL or RESTART */
int (*xBusy)(void*), /* Function to call when busy */
void *pBusyArg, /* Context argument for xBusyHandler */
int sync_flags, /* Flags for OsSync() (or 0) */
u8 *zBuf /* Temporary buffer to use */
){
//只有nBackfill比最大有效幀小時才更新數據庫
if( pInfo->nBackfill<pWal->hdr.mxFrame ){
/* Allocate the iterator */
//迭代器把每一塊的幀按照頁號排序
//如果J<K,那么aPgno [aList[J]] < aPgno [aList[K]]
rc = walIteratorInit(pWal, &pIter);
if( rc!=SQLITE_OK ){
return rc;
}
//獲取所有讀鎖中,最大的aReadMark的值mxSafeFrame
……
if( pInfo->nBackfill<mxSafeFrame
&& (rc = walBusyLock(pWal, xBusy, pBusyArg, WAL_READ_LOCK(0),1))==SQLITE_OK
){
//在更新數據庫時需要持有0號鎖的獨占鎖
//0號鎖的讀事務只在數據庫中讀取數據
/* Iterate through the contents of the WAL, copying data to the db file */
while( rc==SQLITE_OK && 0==walIteratorNext(pIter, &iDbpage, &iFrame) ){
//遍歷迭代器的每一個元素,找到符號要求的頁將其更新到數據庫
……
}
……
walUnlockExclusive(pWal, WAL_READ_LOCK(0), 1);
}
}
}
5.迭代器
下面來簡要說明一下迭代器,初始化中有一個歸并排序,比較難理解,這里稍微講一下,之前講的歸并排序是關于鏈表的,而這里是數組元素的排序:
// 排序目標是,如果J<K,那么
//aContent [aList[J]] < aContent [aList[K]]
static void walMergesort(
const u32 *aContent, /* Pages in wal */
ht_slot *aBuffer, /* Buffer of at least *pnList items to use */
ht_slot *aList, /* IN/OUT: List to sort */
int *pnList /* IN/OUT: Number of elements in aList[] */
){
//遍歷迭代器的數組元素,將每個元素都劃分到子數組里
for(iList=0; iList<nList; iList++){
nMerge = 1;
aMerge = &aList[iList];
// aSub[i]. aList中存的是子數組的首地址
// aSub[i].nList中存的是子元素的個數
//aSub[0]存1個,aSub[1]存2個,aSub[2]存2^2個元素
//依次類推
//假如當前iList是9(0b1001),那么只有在aSub[0]和aSub[3]
//中存有子數組
for(iSub=0; iList & (1<<iSub); iSub++){
struct Sublist *p;
assert( iSub<ArraySize(aSub) );
p = &aSub[iSub];
// p->aList為子數組的第一個元素
//歸并后,p->aList的內容經過了重新去重和排序
//結束后p->aList本身的地址賦值給了aMerge,
// nMerge為歸并后的元素個數
walMerge(aContent, p->aList, p->nList, &aMerge, &nMerge, aBuffer);
}
// aMerge是上一個子數組的首地址
//雖然歸并后的內容經過了重新排序,但是地址沒變
aSub[iSub].aList = aMerge;
aSub[iSub].nList = nMerge;
}
//經過簡單分析,不難得出aMerge是第一個子數組的首地址
//aMerge和接下來的aSub[iSub]繼續歸并,歸并后數組的
//首地址仍然輸出給aMerge,p->aList更新的是內容
//排序后它的地址已經不重要了
for(iSub++; iSub<ArraySize(aSub); iSub++){
if( nList & (1<<iSub) ){
struct Sublist *p;
p = &aSub[iSub];
walMerge(aContent, p->aList, p->nList, &aMerge, &nMerge, aBuffer);
}
}
//輸出迭代器的大小
*pnList = nMerge;
}遍歷迭代器時需要遍歷所有的塊,每一塊初始化是都已經根據頁號排好序了,找出所有塊中最小的元素
static int walIteratorNext(
WalIterator *p, /* Iterator */
u32 *piPage, /* OUT: The page number of the next page */
u32 *piFrame /* OUT: Wal frame index of next page */
){
u32 iMin; /* Result pgno must be greater than iMin */
u32 iRet = 0xFFFFFFFF; /* 0xffffffff is never a valid page number */
int i; /* For looping through segments */
iMin = p->iPrior;
assert( iMin<0xffffffff );
//這里遍歷所有塊
for(i=p->nSegment-1; i>=0; i--){
struct WalSegment *pSegment = &p->aSegment[i];
while( pSegment->iNext<pSegment->nEntry ){
u32 iPg = pSegment->aPgno[pSegment->aIndex[pSegment->iNext]];
//在當前塊內找到大于上一次迭代的頁號
//找到之后先別急著增加pSegment->iNext
//可能iPg并不是所有塊內最小的頁,需要遍歷
//完所有的塊才知道
if( iPg>iMin ){
if( iPg<iRet ){
iRet = iPg;
*piFrame = pSegment->iZero + pSegment->aIndex[pSegment->iNext];
}
break;
}
pSegment->iNext++;
}
}
*piPage = p->iPrior = iRet;
//遍歷迭代器所有元素后返回1
return (iRet==0xFFFFFFFF);
}6.參考資料
《SQLite Database System Design andImplementation》p.249~p.252
智能推薦
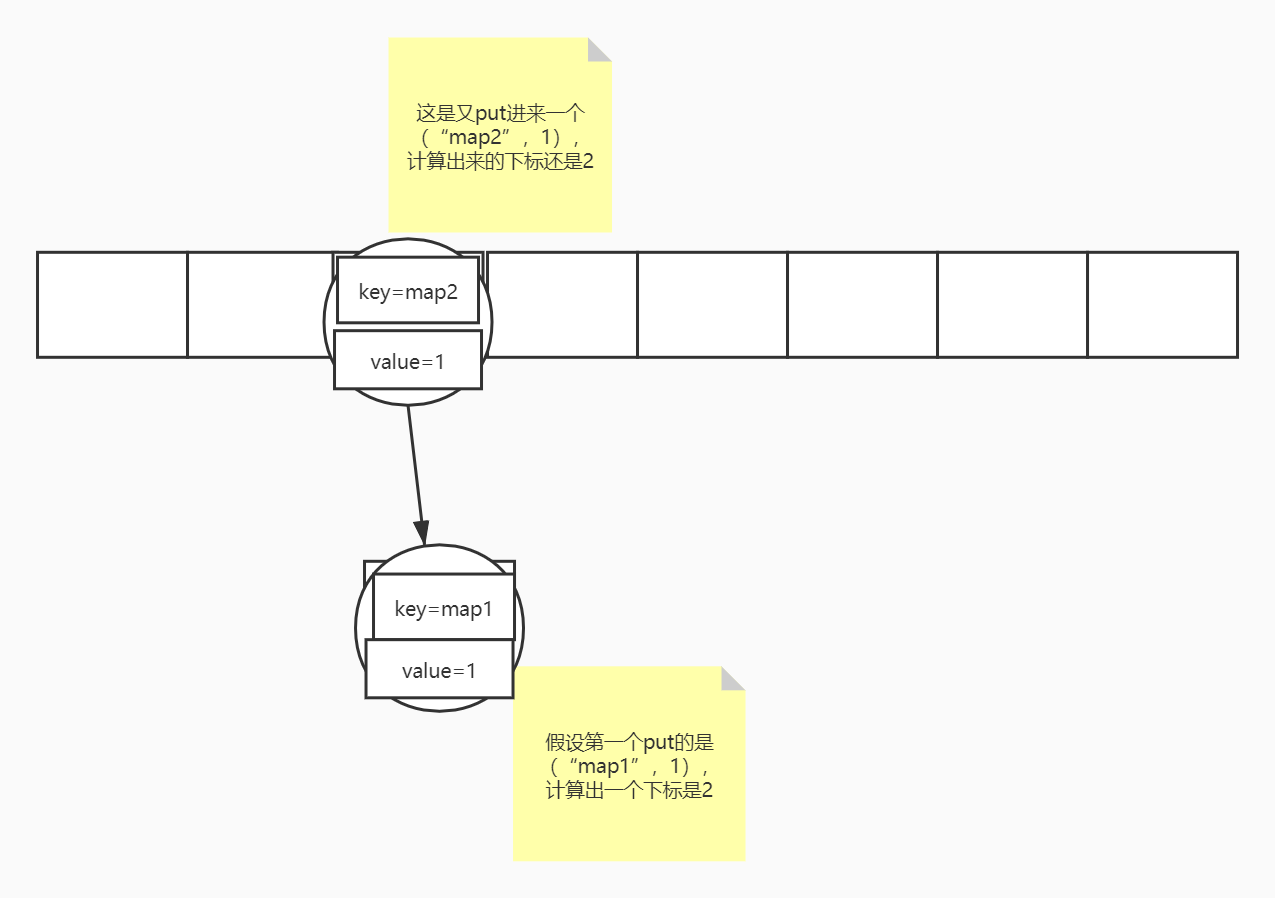
詳細分析jdk1.7的HashMap源碼
先看一段代碼 結果 我們知道map中一個key只能對應一個value,我們再put這個key,會把原來的value返回回來。 為什么jdk1.7 HashMap 的實現原理:數組+鏈表 我們要向一個數組中存入一個值,我們必須知道你要存的下標 jdk是如何實現的呢 可以看到它通過hash()這個方法計算了一個hash值,再通過indexFor()這個方法根據hash值和數組長度算出索引值i 采用鏈表...

layui源碼詳細分析系列之流加載模塊
前言 所謂的流加載實際上是第一種優化手段,通常用于圖片豐富的網站,目的是為了提供更好的用戶體驗。 具體的體現是在頁面初始化時,先加載一小部分內容,當用戶下拉頁面到一定的距離,開始加載另一小部分的內容,直至將所有資源加載呈現,體現的是化整為零的思想,具有較好地用戶體現效果。 自實現流加載以及圖片懶加載功能 流加載功能和圖片懶加載功能是分開實現的,使用原生的JavaScript開發(所有涉及交互效果的...
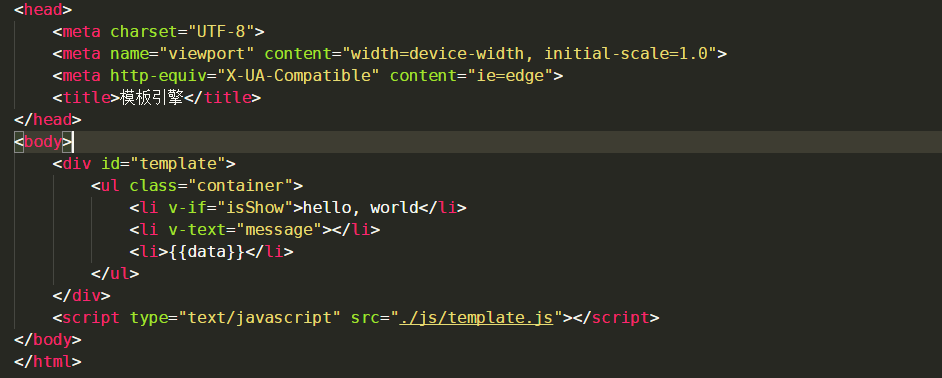
layui源碼詳細分析系列之模板引擎
前言 所謂的模板引擎,其實最早接觸該形式的應該是jsp,在html代碼中嵌套java代碼,使用形式與模板很相似,實際上jsp就是一種模板語言,對于模板語言我的了解并不多,此處就不再詳細的描述了。 當我看見layui內置的模板引擎模塊laytpl.js時,我首先想起的是Vue中{{}}模板的使用,但是Vue中還有雙向綁定的概念(你可已使用get/set方法來實現),laytpl.js中提供的模板類型...

layui源碼詳細分析之樹形菜單
前言 今天分析的是layui框架內置模塊tree.js,該模塊的功能是構建樹形菜單,具體的形式(layui官網該模塊的具體形式)如下: 自實現樹形菜單 使用html+css+js實現了樹形菜單,具體的實現思路如下: html中定義包含樹形菜單的容器節點 規劃好樹形菜單的樣式以及圖標 使用js構建html結構以及綁定事件,實現樹形菜單的點擊折疊 實現效果圖如下: 核心的實現是構建html結構,組織樹...
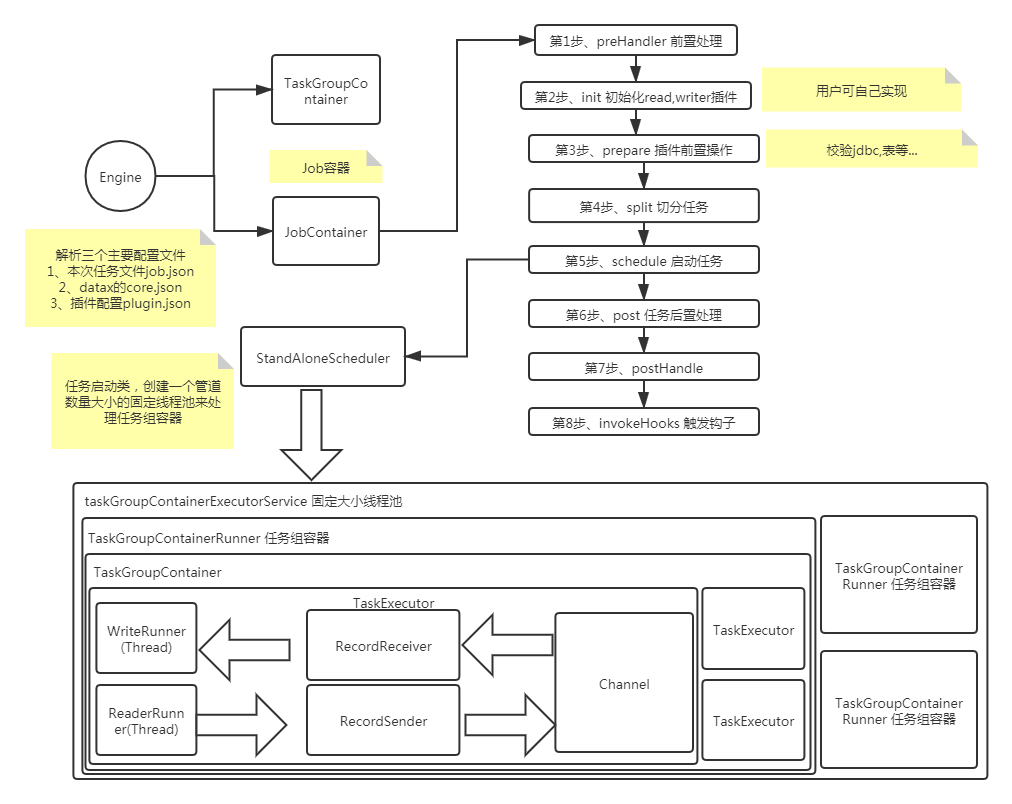
詳細分析DataX源碼,剖析流程結構
DataX類圖 整個流程大致如下 先看下官方的介紹,了解下功能和結構。再進行源碼的剖析 DataX 是一個異構數據源離線同步工具,致力于實現包括關系型數據庫(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各種異構數據源之間穩定高效的數據同步功能 DataX本身作為離線數據同步框架,采用Framework + plugin架構構建。將數據源讀取和寫入抽象成為Read...
猜你喜歡
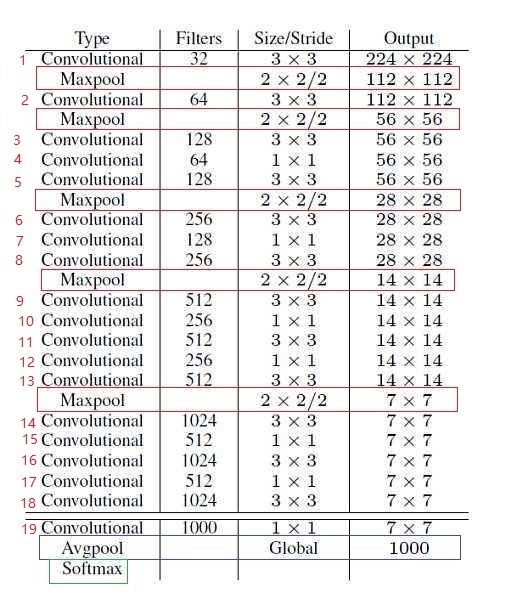
『Yolo_v3』項目詳細分析
一.前言 最近在學習yolo_v3項目,該項目是深度學習發展到現階段最受歡迎的大項目之一,是多目標識別跟蹤框架集大成者。 yolo_v3是yolo系列之一神經網絡,同時也是發展到的最優美的網絡。當然,隨著系列發展,yolo_v3也保留和yolo_v1和yolo_v2神經網絡的部分優點,同時,也拋棄了yolo_v1和yolo_v2中大多數缺點。下面就yolo_v3進行理論和代碼信息分析。同學完全可以...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...