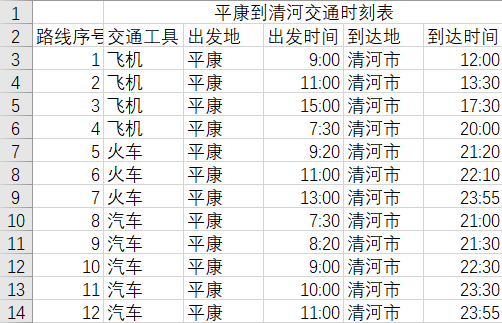
最近需要用到Python來操作excel表,讀取表格內容到數據庫。所以就搜索了相關資料。
查找了一下,可以操作excel表的幾個庫有以下幾個:
- openpyxl
這個是推薦使用的庫,可以讀寫Excel 2010以上格式,以.xlsx結尾的文件。
- xlsxwriter
這個支持.xlsx,但是只支持寫入,格式化等操作,不支持讀取。
- xlrd
這個支持讀取數據,支持以xls結尾的文件,也就是比較老的格式。
- xlwt
這個和上面的相對應,支持寫入書和格式化數據,支持xls結尾的文件格式。
- xlutils
這個是整合了xlrd和xlwt兩個庫的功能。
經過對比我還是選擇了openpyxl這個庫,下面針對這個庫的使用進行說明
公眾號【智能制造專欄】,以后技術類文章會發在專欄。
以下參考官方文檔
本文代碼托管在github上,點擊鏈接
- 創建一個工作簿
from openpyxl import Workbook
wb = Workbook()
ws = wb.active #默認創建第一個表,默認名字為sheet
ws1 = wb.create_sheet() #創建第二個表
ws1.title = "New Title" #為第二個表設置名字
ws2 = wb.get_sheet_by_name(
New Title") #通過名字獲取表,和第二個表示一個表
ws1.save('your_name.xlsx') #保存
- 讀取一個工作簿中的內容
from openpyxl import load_workbook
wb = load_workbook('myname.xlsx') #加載一個工作簿
print wb.get_sheet_names() #獲取各個sheet的名字- 簡單的用法
from openpyxl import Workbook
from openpyxl.compat import range
from openpyxl.cell import get_column_letter
wb = Workbook()
dest_filename = 'empty_book.xlsx'
ws1 = wb.active #第一個表
ws1.title = "range names" #第一個表命名
#遍歷第一個表的1到39行,每行賦值從1到599.
for row in range(1,40):
ws1.append(range(600))
ws2 = wb.create_sheet(title="Pi") # 創建第二個表
ws2['F5'] = 3.14 #為第二個表的F5單元格賦值為3.14
ws3 = wb.create_sheet(title="Data") #創建第三個表
/* 下面遍歷第三個表的10到19行,27到53列,并對每一行的單元格賦一個當前列名的名字如下圖 */
for row in range(10,20):
for col in range(27,54):
_=ws3.cell(column=col,row=row,value="%s" % get_column_letter(col)) #_當作一個普通的變量,一般表示后邊不再使用
wb.save(filename=dest_filename) #保存