實現12306全自動購票(附源碼)
標簽: Python selenium python web
干貨來了!!春運到了,你還在手動買火車票嗎?
? 在我眼里,Python一直都是一門有趣的語言,經過一段時間的系統學習,接觸到selenium自動化測試這邊突發奇想,想要實現一下自動訪問學校教務處、QQ郵箱、QQ空間等一系列登錄操作,從眾多項目中選取了12306購票網站來分享,如有不足或錯誤還請各位讀者指出,謝謝。
1、什么是selenium
在想要看懂代碼之前一定要問問自己,啥是個selenium?它能干啥?為啥要用它?
答: selenium 是一個用于Web應用程序測試的工具。Selenium測試直接運行在瀏覽器中,就像真正的用戶在操作一樣。支持的瀏覽器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。selenium 是一套完整的web應用程序測試系統,包含了測試的錄制(selenium IDE),編寫及運行(Selenium Remote Control)和測試的并行處理(Selenium Grid)。Selenium的核心Selenium Core基于JsUnit,完全由JavaScript編寫,因此可以用于任何支持JavaScript的瀏覽器上。selenium可以模擬真實瀏覽器,自動化測試工具,支持多種瀏覽器,爬蟲中主要用來解決JavaScript渲染問題。
2、selenium的常見庫及其使用
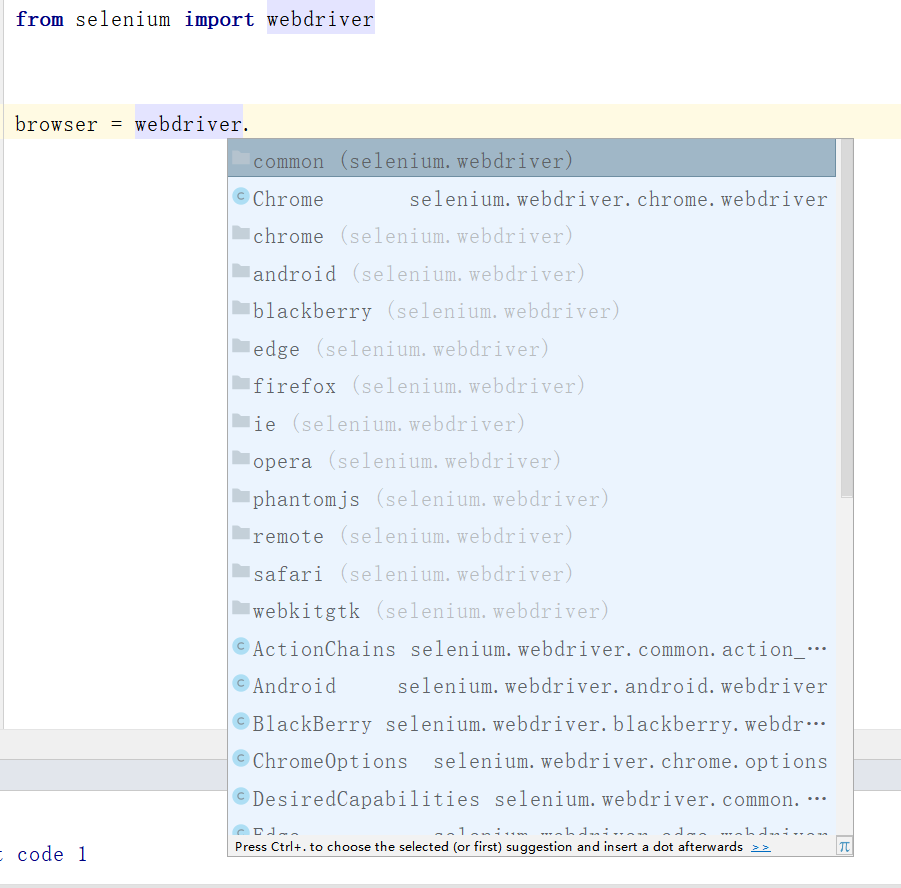
我們可以觀察到,selenium支持多種瀏覽器,本文中我將主要使用webdriver.Chrome進行自動化測試
小案例:
這里構造一個簡單的小案例方便你更好的了解它
from selenium import webdriver # 導入庫
browser = webdriver.Chrome() # 聲明瀏覽器
url = 'https:www.baidu.com'
browser.get(url) # 打開瀏覽器預設網址
print(browser.page_source) # 打印網頁源代碼
browser.close() # 關閉瀏覽器
注: 如果想要進行一點完善的話可以添加time模塊
查找
selenium最方便的地方在于,你可以通過多種方法來定位頁面信息,這里我列舉一些常用方法:
find_element_by_name
find_element_by_id
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
至于每一種的效果如何或者是使用情況,請依照個人需求靈活選擇。
獲取文本值
browser.get("http://www.zhihu.com/explore")
logo = browser.find_element_by_css_selector('.zu-top-link-logo')
print(logo)
print(logo.text)
運行代碼我們可以得到標簽下的文本值:
<selenium.webdriver.remote.webelement.WebElement (session="ce8814d69f8e1291c88ce6f76b6050a2", element="0.9868611170776878-1")>
知乎
模擬點擊
這里內容比較多,我們可以通過selenium下的 ActionChains 類,由于篇幅過長這里只截取部分
class ActionChains(object):
"""
ActionChains are a way to automate low level interactions such as
mouse movements, mouse button actions, key press, and context menu interactions.
This is useful for doing more complex actions like hover over and drag and drop.
Generate user actions.
When you call methods for actions on the ActionChains object,
the actions are stored in a queue in the ActionChains object.
When you call perform(), the events are fired in the order they
are queued up.
ActionChains can be used in a chain pattern::
menu = driver.find_element_by_css_selector(".nav")
hidden_submenu = driver.find_element_by_css_selector(".nav #submenu1")
ActionChains(driver).move_to_element(menu).click(hidden_submenu).perform()
Or actions can be queued up one by one, then performed.::
menu = driver.find_element_by_css_selector(".nav")
hidden_submenu = driver.find_element_by_css_selector(".nav #submenu1")
actions = ActionChains(driver)
actions.move_to_element(menu)
actions.click(hidden_submenu)
actions.perform()
Either way, the actions are performed in the order they are called, one after
another.
"""
def __init__(self, driver):
"""
Creates a new ActionChains.
:Args:
- driver: The WebDriver instance which performs user actions.
"""
self._driver = driver
self._actions = []
if self._driver.w3c:
self.w3c_actions = ActionBuilder(driver)
def perform(self):
"""
Performs all stored actions.
"""
if self._driver.w3c:
self.w3c_actions.perform()
else:
for action in self._actions:
action()
def reset_actions(self):
"""
Clears actions that are already stored on the remote end.
"""
if self._driver.w3c:
self._driver.execute(Command.W3C_CLEAR_ACTIONS)
else:
self._actions = []
....
3、操作實戰
在實現登錄過程中,首先需要逐步解析頁面,通過xpath工具、頁面審查等方式定位到相應的標簽下,通過模擬點擊、輸入文本等方式進行信息輸入、表單選擇等過程。
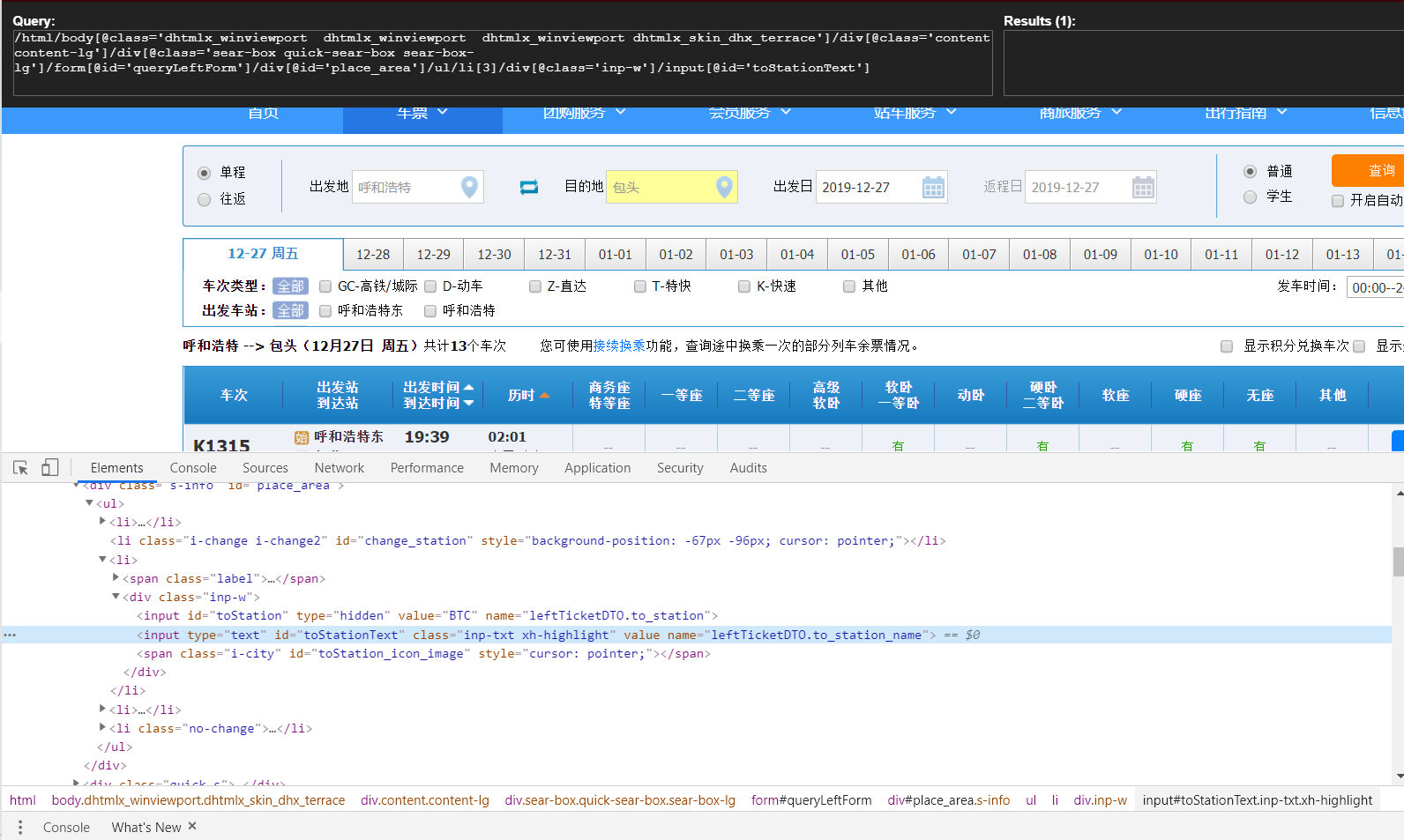
例如我們從上圖中,定位到了下拉表單中的始發地/目的地信息,只有這樣我們才可以對其中的數據進行修改,直到達到我們所預期的效果
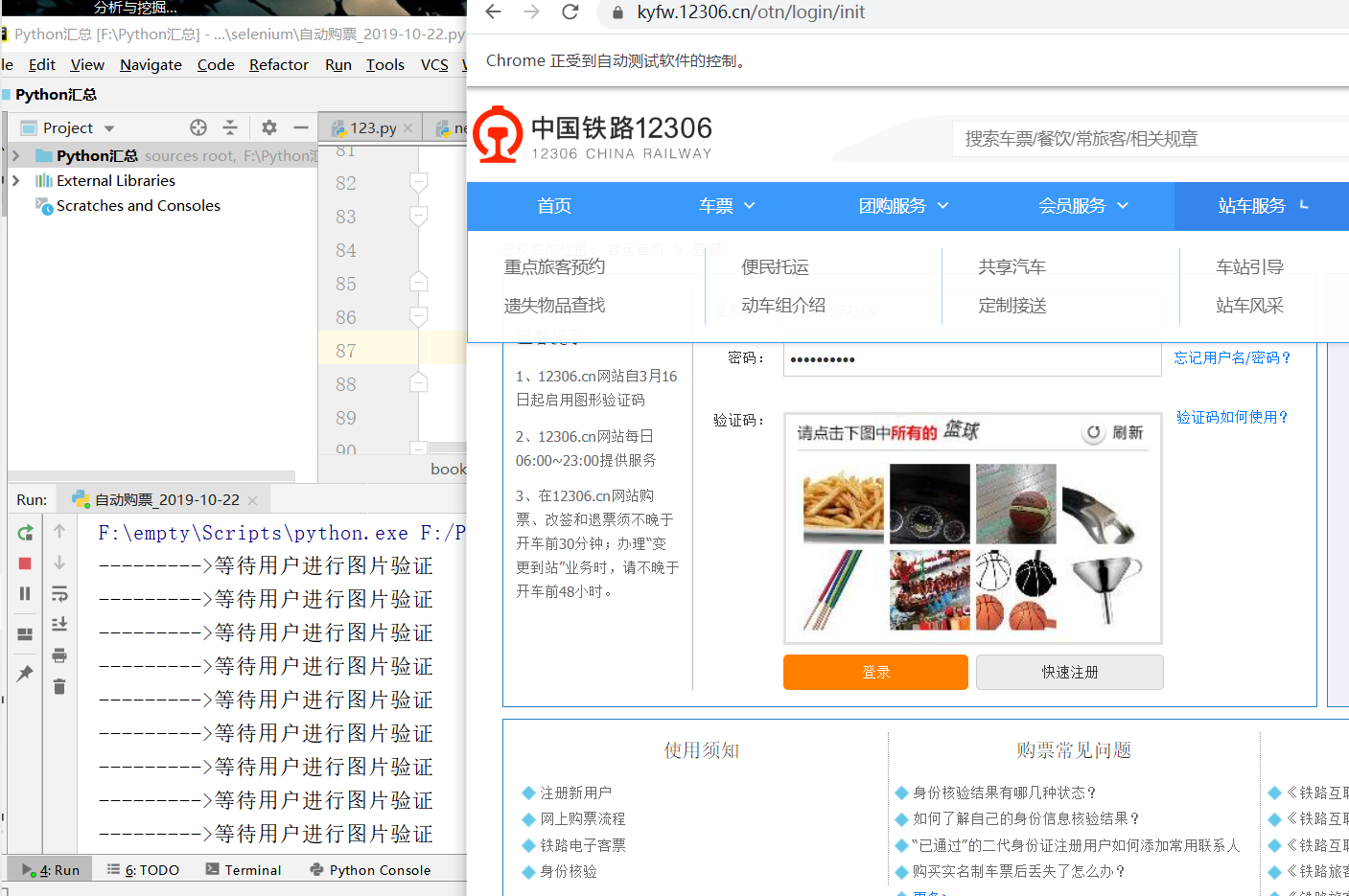
美中不足的是,12306特有的圖片驗證碼還未找到合適的方法實現自動**,只能通過人工識別完成這一步驟。
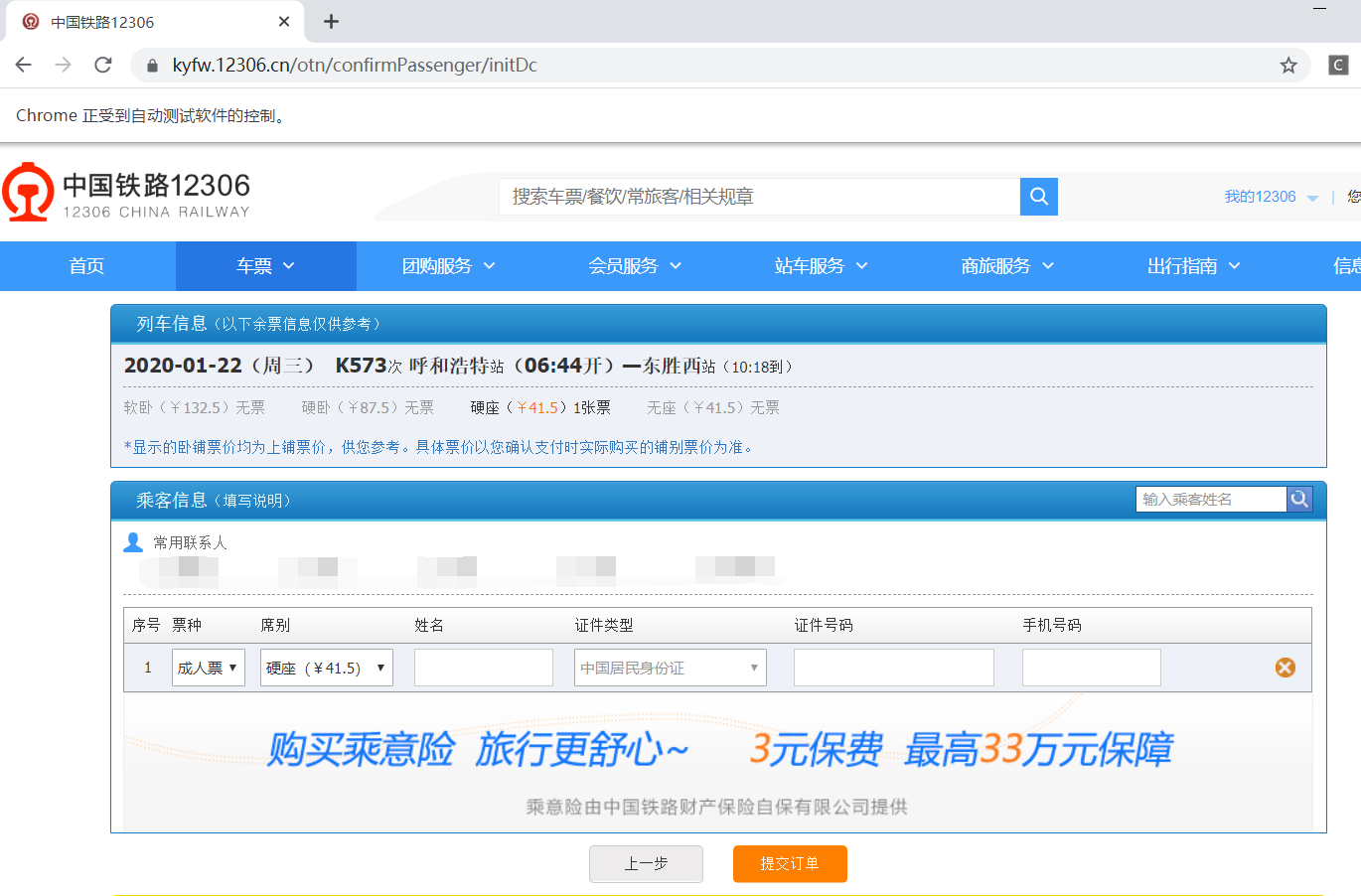
至此我們的測試就已經結束,可以看到效果還是很不錯的,避免了反復通過輸入密碼、選擇站點等操作,極大程度的減少了不必要的操作!只需將常用的站點xpath路徑保存好即可。
4、代碼上場
下面附贈本次實驗中的部分代碼,希望能給各位讀者一些幫助!
from selenium import webdriver
import time
def main():
login_text()
search_ticket()
book_ticket()
def login_text():
d.get(url)
d.implicitly_wait(30)
# 登陸賬號
username_ele = d.find_element_by_id('username')
username_ele.clear()
username_ele.send_keys(username)
# 登陸密碼
pwd_ele = d.find_element_by_id('password')
pwd_ele.clear()
pwd_ele.send_keys(pwd)
while True: # 手動進行圖片驗證,并登錄
curpage_url = d.current_url
if curpage_url != url:
if curpage_url[:-1] != url:
print('.......登陸成功........')
break
else:
time.sleep(3)
print('------細心點老鐵!慢慢來!-----')
def search_ticket():
time.sleep(2)
d.find_element_by_link_text('車票').click()
d.find_element_by_link_text('單程').click()
time.sleep(3)
# 輸入出發地
d.add_cookie({"name": "_jc_save_fromStation", "value": '%u547C%u548C%u6D69%u7279%2CHHC'}) # 鄂爾多斯
# 選擇目的地
d.add_cookie({"name": "_jc_save_toStation", "value": '%u9102%u5C14%u591A%u65AF%2CEEC'}) # 呼和浩特
# 選擇出發日期
d.add_cookie({"name": "_jc_save_fromDate", "value": '2019-11-06'})
d.refresh()
def book_ticket():
query_time = 0
time_begin = time.time()
# 循環查詢
while True:
time.sleep(1)
search_btn = d.find_element_by_link_text('查詢')
search_btn.click()
# 掃描查詢結果
try:
d.implicitly_wait(3)
# 鄂爾多斯到呼和浩特的D6963的PATH:(//*[@id="ZE_33000D696300"])
ticket_ele = d.find_element_by_xpath('//*[@id="ZE_33000D696300"]') # 所搶車次對應的座位等級的xpath,這里是二等座
ticket_info = ticket_ele.text
except:
search_btn.click()
d.implicitly_wait(3)
ticket_ele = d.find_element_by_xpath('//*[@id="ZE_33000D696300"]')
ticket_info = ticket_ele.text
print('可能您的xpath選擇錯誤')
if ticket_info == '無' or ticket_info == '*':
query_time += 1
cur_time = time.time()
print('第%d次查詢,用時%s秒' % (query_time, cur_time - time_begin))
else:
d.find_element_by_xpath('//*[@id="ticket_33000D696300"]/td[13]/a').click()
break
cust_url = 'https://kyfw.12306.cn/otn/confirmPassenger/initDc'
while True:
if (d.current_url == cust_url):
print('頁面跳至選擇乘客信息 成功')
break
else:
time.sleep(1)
print('等待頁面跳轉')
while True:
try:
time.sleep(2)
d.find_element_by_xpath('//*[@id="normalPassenger_0"]').click() # _0是聯系人列表里的第一個 ,依此類推
break
except:
print('等待常用聯系人列表')
# 提交訂單
d.find_element_by_xpath('//*[@id="submitOrder_id"]').click()
# 確認訂票信息
while True:
try:
d.switch_to.frame(d.find_element_by_xpath('/html/body/iframe[2]'))
d.find_element_by_xpath('//*[@id="qr_submit_id"]')
print('pass')
except:
print('請手動選座和點擊確認信息')
time.sleep(5)
print('請完成購票,再見。')
break
if __name__ == '__main__':
d = webdriver.Chrome()
url = 'https://kyfw.12306.cn/otn/login/init'
username = '這里是你的用戶名'
pwd = '這里是你的密碼'
main()
希望各位讀者可以學到一些什么,而不是單純地復制粘貼。Python的魅力在于,你可以使用它實現很多有趣而實用的案例,我想我會繼續研究下去,如有不足或錯誤之處還請各位讀者指出,謝謝!
智能推薦


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...

猜你喜歡

Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...

統計學習方法 - 樸素貝葉斯
引入問題:一機器在良好狀態生產合格產品幾率是 90%,在故障狀態生產合格產品幾率是 30%,機器良好的概率是 75%。若一日第一件產品是合格品,那么此日機器良好的概率是多少。 貝葉斯模型 生成模型與判別模型 判別模型,即要判斷這個東西到底是哪一類,也就是要求y,那就用給定的x去預測。 生成模型,是要生成一個模型,那就是誰根據什么生成了模型,誰就是類別y,根據的內容就是x 以上述例子,判斷一個生產出...

styled-components —— React 中的 CSS 最佳實踐
https://zhuanlan.zhihu.com/p/29344146 Styled-components 是目前 React 樣式方案中最受關注的一種,它既具備了 css-in-js 的模塊化與參數化優點,又完全使用CSS的書寫習慣,不會引起額外的學習成本。本文是 styled-components 作者之一 Max Stoiber 所寫,首先總結了前端組件化樣式中的最佳實踐原則,然后在此基...

19.vue中封裝echarts組件
19.vue中封裝echarts組件 1.效果圖 2.echarts組件 3.使用組件 按照組件格式整理好數據格式 傳入組件 home.vue 4.接口返回數據格式...