Python進階之Scrapy框架入門
Python進階之Scrapy框架入門
1. Scrapy入門
1.1 什么是Scrapy
- Scrapy是一個適用爬取網站數據、提取結構性數據的應用程序框架,它可以應用在廣泛領域:Scrapy 常應用在包括數據挖掘,信息處理或存儲歷史數據等一系列的程序中。通常我們可以很簡單的通過 Scrapy 框架實現一個爬蟲,抓取指定網站的內容或圖片。
- Scrapy使用了Twisted異步網絡框架,可以大大提高數據抓取的效率
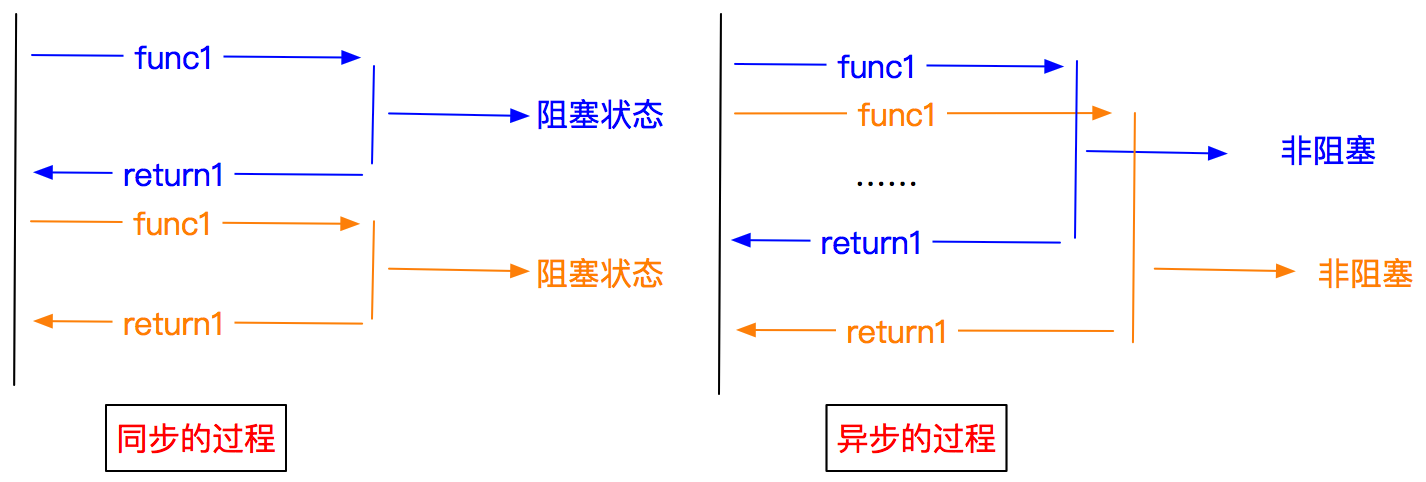
- 異步:調用在發出之后,這個調用就直接返回,不管有無結果
- 非阻塞:關注的是程序在等待調用結果時的狀態,指在不能立刻得到結果之前,該調用不會阻塞當前線程
- 異步過程使得程序充分利用了阻塞等待的時間,使得程序在同樣的時間可以干更多的事情,從而提高了執行效率
1.2 Scrapy架構
-
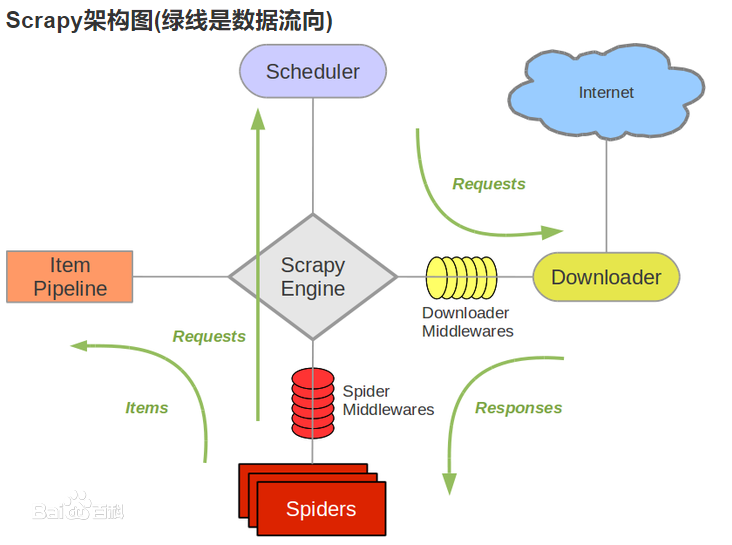
一個標準的Scrapy架構由Scrapy Engine(引擎),Scheduler(調度器),Downloader(下載器),Spider(爬蟲),Item Pipeline(管道),Downloader Middlewares(下載中間件),Spider Middlewares(Spider中間件)組成,如下圖:
-
Scrapy Engine(引擎):負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,信號、數據傳遞等。
-
Scheduler(調度器):它負責接受引擎發送過來的Request請求,并按照一定的方式進行整理排列,入隊,當引擎需要時,交還給引擎。
-
Downloader(下載器):負責下載Scrapy Engine(引擎)發送的所有Requests請求,并將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理。
-
Spider(爬蟲):它負責處理所有Responses,從中分析提取數據,獲取Item字段需要的數據,并將需要跟進的URL提交給引擎,再次進入Scheduler(調度器)。
-
Item Pipeline(管道):它負責處理Spider中獲取到的Item,并進行進行后期處理(詳細分析、過濾、存儲等)的地方。
-
Downloader Middlewares(下載中間件):一個可以自定義擴展下載功能的組件。
-
Spider Middlewares(Spider中間件):一個可以自定擴展和操作引擎和Spider中間通信的功能組件。
1.3 安裝Scrapy
-
下載:
-
安裝:
- 在windows下安裝:
- 命令行安裝:
pip install Scrapy
- whl安裝,先安裝scrapy的whl,再安裝對應的twisted的whl
pip install xxxxxxx.whl
- 安裝指南
- 在windows下安裝:
-
技術文檔
2. Scrapy項目初探
2.1 創建一個Scrapy項目
-
創建Scrapy項目,startproject后的項目名稱可以按照需要指定
scrapy startproject mySpider運行后提示:
You can start your first spider with:
cd mySpider
scrapy genspider example example.com -
創建爬蟲,命令行運行cd mySpider進入爬蟲目錄后
scrapy genspider demo "demo.cn"- demo為爬蟲項目名稱,在”./mySpider/spiders/“目錄生成一個名為demo.py的文件
- "demo.cn"為需要爬取的網站域名
運行后提示:
Created spider ‘demo’ using template ‘basic’ in module:
mySpider.spiders.demo -
完善數據,完善爬蟲項目數據,把爬蟲代碼添加到demo.py中
-
保存數據,修改pipelines.py,把數據保存的代碼添加到文件中
- 1 可能會有多個spider,不同的pipeline處理不同的item的內容
- 2 一個spider的內容可以要做不同的操作,比如存入不同的數據庫中
注意:- pipeline的權重越小優先級越高
- pipeline中process_item方法名不能修改為其他的名稱
2.2 運行爬蟲
-
在命令中運行爬蟲, # xxx是爬蟲的名字,與爬蟲項目名保持一致
scrapy crawl XXX -
在pycharm中運行爬蟲,
from scrapy import cmdline cmdline.execute("scrapy crawl xxx".split())
3. Scrapy抓取豆瓣數據實例
- 通過一個抓取豆瓣的scrapy項目,簡單介紹scrapy項目的開發邏輯
3.1 創建項目和爬蟲
- 創建scrapy項目
scrapy startproject spider
- 進入項目目錄
cd spider
- 創建爬蟲項目
scrapy genspider douban “douban.com”
3.2 douban.py
- 注意:
- parse中的response是一個可以使用xpath的對象,可以直接獲取html數據
- 利用Scrapy里邊的extract_first()或get()取數據
- get()獲取有標簽的數據
- extract_first()獲取文本數據,注意加(),否則會輸出錯誤數據
- bound method SelectorList.get of - 抓取結果保存成字典方便引用和保存
- 返回數據用生成器形式yield返回,盡量不用return.這樣可以節省內存資源
import scrapy
# from scrapy.http.response.html import HtmlResponse
class DoubanSpider(scrapy.Spider):
name = 'douban'
# 允許的域名范圍,不需要加協議名
allowed_domains = ['douban.com']
# 可以修改
start_urls = ['http://douban.com/']
def parse(self, response):
# print('-' * 50)
# print(response)
# print(type(response))
# print('-' * 50)
# response狀態碼200,說明已經抓到了html
li_list = response.xpath('//div[@class="side-links nav-anon"]/ul//li')
# 定義字典收集數據
item = {}
for li in li_list:
# 利用Scrapy里邊的extract_first()和get()取數據
# get()獲取有標簽的數據
# extract_first()獲取文本數據,注意加(),否則會輸出錯
# bound method SelectorList.get of
# 發現輸出缺少購書單,購書單在em標簽下
item['name'] = li.xpath('a/em/text()').extract_first()
# 增加判斷,如果找不到則執行下邊的代碼
if item['name'] == None:
# 其他標簽都在a標簽下
item['name'] = li.xpath('a/text()').extract_first()
# print(item)
# 用yield生成器返回數據,節省內存資源
yield item
# print(li_list)
3.3 settings.py
- 注意:
- 設定LOG-LEVEL可以簡化日志輸出內容,調試時更為方便
- 設定DEFAULT_REQUEST_HEADERS請求頭
- 根據實際需要確定ROBOTSTXT_OBEY = True是否要注釋掉
- 使用pipeline的時候要在settings里把# Configure item pipelines下邊的ITEM_PIPELINES代碼打開
BOT_NAME = 'spider'
SPIDER_MODULES = ['spider.spiders']
NEWSPIDER_MODULE = 'spider.spiders'
# 日志輸出簡化
LOG_LEVEL = 'WARNING'
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3820.400 QQBrowser/10.6.4255.400',
'Accept-Language': 'en',
}
# Obey robots.txt rules
# 注釋掉了遵守robots協議
# ROBOTSTXT_OBEY = True
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'spider.pipelines.SpiderPipeline': 300,
}
3.4 pipeline.py
- 注意:
- 使用pipeline的時候要在settings里把# Configure item pipelines下邊的ITEM_PIPELINES代碼打開
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
# 注意使用pipeline要在設置里邊打開ITEM_PIPELINES setting
class SpiderPipeline:
def process_item(self, item, spider):
print(item)
return item
3.5 start.py
- 可以通過windows命令行輸入scrapy crawl douban運行程序
- 也可以調用scrapy中的cmdline.execute()創建python啟動程序,注意后邊有個.split()分隔
# !/usr/bin/python
# Filename: start.py
# Data : 2020/08/25
# Author : --king--
# ctrl+alt+L自動加空格格式化
from scrapy import cmdline
# cmdline.execute(['scrapy','crawl','douban'])
cmdline.execute('scrapy crawl douban'.split())
智能推薦
Python 爬蟲:Scrapy 框架入門初探【 Xpath 改寫】
目錄 安裝 Scrapy 初試 Scrapy 第1步:創建項目 第2步:編寫代碼 第3步:運行爬蟲 第4步:保存數據 結果展示 Scrapy 是一種用于抓取網站和提取結構化數據的應用程序框架,可用于廣泛的有用應用程序,如數據挖掘、信息處理或歷史存檔等。 安裝 Scrapy 從 PyPI 安裝: 使用 Anaconda 或 Miniconda 安裝: 安裝后可在命令行查看是否成功: 初試 Scrap...
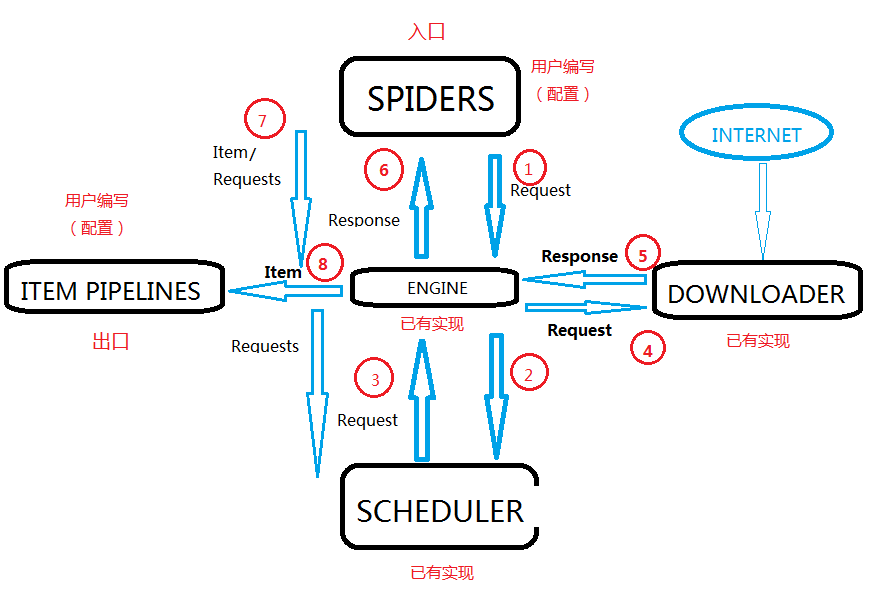
python——爬蟲學習——Scrapy爬蟲框架入門-(6)
Scrapy,Python開發的一個快速,高層次的屏幕抓取和web抓取框架,用于抓取web站點并從頁面中提取結構化的數據。Scrapy用途廣泛,可以用于數據挖掘、監測和自動化測試。 一、”5+2”結構 1.Engine(引擎) 不需要用戶修改 2.Downloader(下載器) 不需要用戶修改 3.Scheduler(調度器) 不需要用戶修改 4.Downloader Mi...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...
猜你喜歡

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...

統計學習方法 - 樸素貝葉斯
引入問題:一機器在良好狀態生產合格產品幾率是 90%,在故障狀態生產合格產品幾率是 30%,機器良好的概率是 75%。若一日第一件產品是合格品,那么此日機器良好的概率是多少。 貝葉斯模型 生成模型與判別模型 判別模型,即要判斷這個東西到底是哪一類,也就是要求y,那就用給定的x去預測。 生成模型,是要生成一個模型,那就是誰根據什么生成了模型,誰就是類別y,根據的內容就是x 以上述例子,判斷一個生產出...

styled-components —— React 中的 CSS 最佳實踐
https://zhuanlan.zhihu.com/p/29344146 Styled-components 是目前 React 樣式方案中最受關注的一種,它既具備了 css-in-js 的模塊化與參數化優點,又完全使用CSS的書寫習慣,不會引起額外的學習成本。本文是 styled-components 作者之一 Max Stoiber 所寫,首先總結了前端組件化樣式中的最佳實踐原則,然后在此基...