java集合框架簡介
標簽: java基礎知識
一、集合可以看作是一種容器,用來存儲對象信息。所有集合類都位于java.util包下,但支持多線程的集合類位于java.util.concurrent包下。
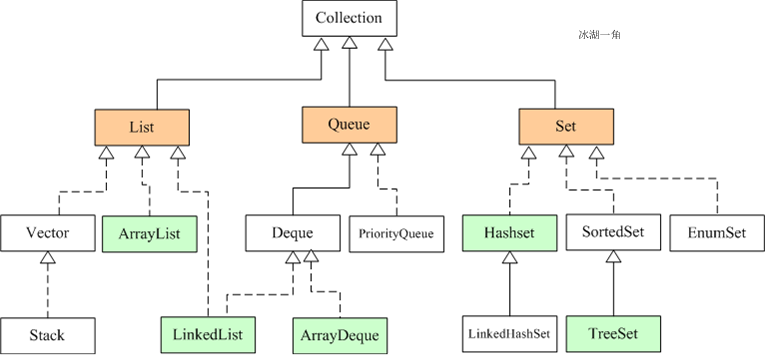
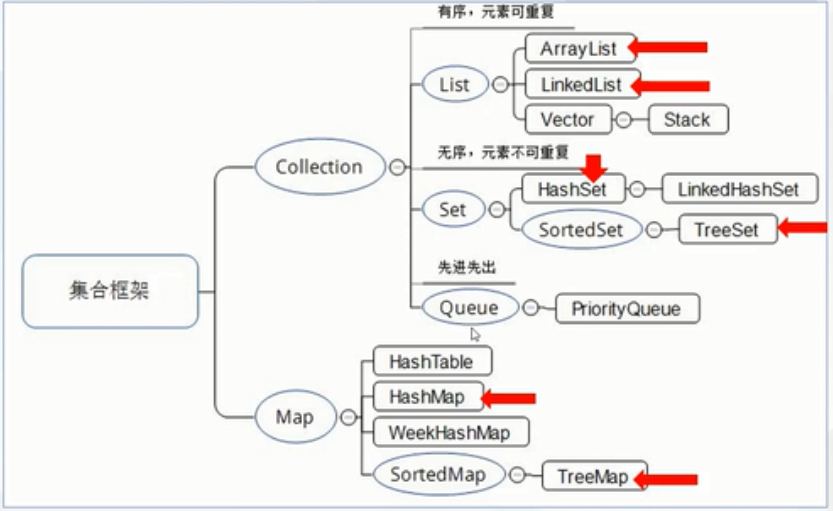
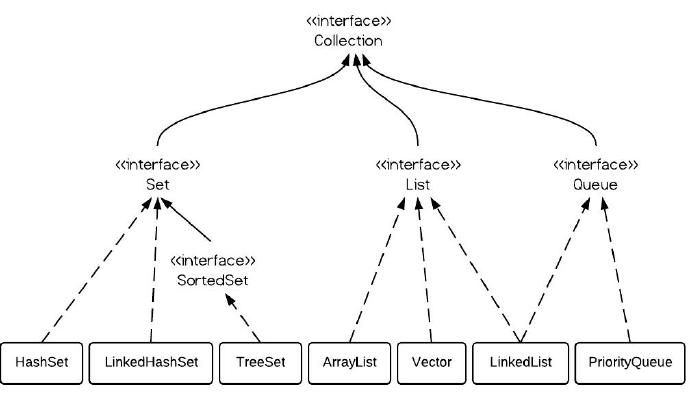
Java集合類主要由兩個根接口Collection和Map派生出來的,Collection派生出了三個子接口:List、Set、Queue(Java5新增的隊列),因此Java集合大致也可分成List、Set、Queue、Map四種接口體系,(注意:Map不是Collection的子接口)。
其中List代表了有序可重復集合,可直接根據元素的索引來訪問;Set代表無序不可重復集合,只能根據元素本身來訪問;Queue是隊列集合;Map代表的是存儲key-value對的集合,可根據元素的key來訪問value。
上圖中淡綠色背景覆蓋的是集合體系中常用的實現類,分別是ArrayList、LinkedList、ArrayQueue、HashSet、TreeSet、HashMap、TreeMap等實現類。
數組與
二、集合的區別如下:
1.數組既可以存儲基本數據類型,又可以存儲引用數據類型,基本數據類型存儲的是值,引用數據類型存儲的是地址值;集合只能存儲引用數據類型(對象)集合中也可以存儲基本數據類型,但是在存儲的時候會自動裝箱變成對象.
2.數組長度不可變化而且無法保存具有映射關系的數據;集合類用于保存數量不確定的數據,以及保存具有映射關系的數據。
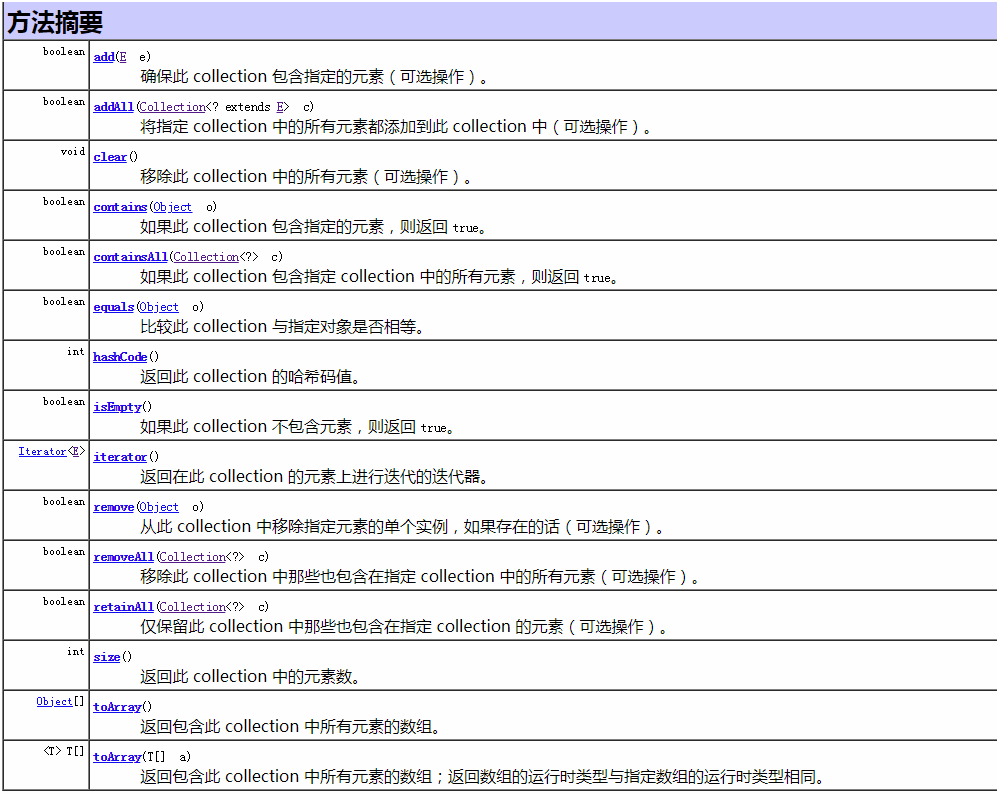
三、 Collection接口常見方法(來源于Java API)
四、set
1.Set集合與Collection的方法相同,由于Set集合不允許存儲相同的元素,所以如果把兩個相同元素添加到同一個Set集合,則添加操作失敗,新元素不會被加入,add()方法返回false。
2.HashSet類
HashSet是Set集合最常用實現類,是其經典實現。HashSet是按照hash算法來存儲元素的,因此具有很好的存取和查找性能。
HashSet具有如下特點:
不能保證元素的順序。
HashSet不是線程同步的,如果多線程操作HashSet集合,則應通過代碼來保證其同步。
集合元素值可以是null。
Set的底層實現是HashMap(這個后面講Map時也會講它的源碼), 當我們在HashSet中添加一個新元素時, 其實這個值是存儲在底層Map的key中,而眾所周知,HashMap的key值是不能重復的, 所以這里就可以達到去重的目的了。
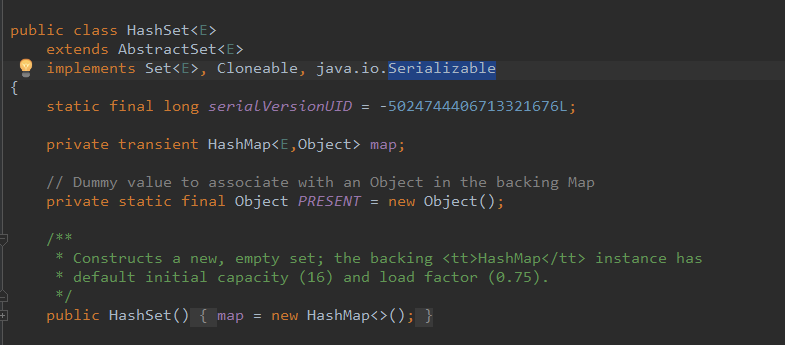
放入HashSet中的集合元素實際上由HashMap的key來保存,而HashMap的value則存儲了一個PRESENT,它是一個靜態的Object對象。
HashSet存儲原理如下:
當向HashSet集合存儲一個元素時,HashSet會調用該對象的hashCode()方法得到其hashCode值,然后根據hashCode值決定該對象的存儲位置。HashSet集合判斷兩個元素相等的標準是(1)兩個對象通過equals()方法比較返回true;(2)兩個對象的hashCode()方法返回值相等。因此,如果(1)和(2)有一個不滿足條件,則認為這兩個對象不相等,可以添加成功。如果兩個對象的hashCode()方法返回值相等,但是兩個對象通過equals()方法比較返回false,HashSet會以鏈式結構將兩個對象保存在同一位置,這將導致性能下降,因此在編碼時應避免出現這種情況。
HashSet查找原理如下:
基于HashSet以上的存儲原理,在查找元素時,HashSet先計算元素的HashCode值(也就是調用對象的hashCode方法的返回值),然后直接到hashCode值對應的位置去取出元素即可,這就是HashSet速度很快的原因。
重寫hashCode()方法的基本原則如下:
在程序運行過程中,同一個對象的hashCode()方法返回值應相同。
當兩個對象通過equals()方法比較返回true時,這兩個對象的hashCode()方法返回值應該相等。
對象中用作equals()方法比較標準的實例變量,都應該用于計算hashCode值。
2)LinkedHashSet類
由于LinkedHashSet是一個哈希表和鏈表的結合,且是一個雙向鏈表,那么我們來看一下什么是雙向連邊?
雙向鏈表是鏈表的一種,他的每個數據節點都有兩個指針分別指向直接后繼和直接前驅,所以從雙向鏈表的任意一個節點開始都可以很方便的訪問它的前驅節點和后繼節點。這是雙向鏈表的優點,那么有優點就有缺點,缺點是每個節點都需要保存當前節點的next和prev兩個屬性,這樣才能保證優點。所以需要更多的內存開銷,并且刪除和添加也會比較費時間。
LinkedHashSet是HashSet的一個子類,具有HashSet的特性,也是根據元素的hashCode值來決定元素的存儲位置。但它使用鏈表維護元素的次序,元素的順序與添加順序一致。由于LinkedHashSet需要維護元素的插入順序,因此性能略低于HashSet,但在迭代訪問Set里的全部元素時由很好的性能。
3)TreeSet類
TreeSet時SortedSet接口的實現類,TreeSet可以保證元素處于排序狀態,它采用紅黑樹的數據結構來存儲集合元素。TreeSet支持兩種排序方法:自然排序和定制排序,默認采用自然排序。不允許放入null值
自然排序
TreeSet會調用集合元素的compareTo(Object obj)方法來比較元素的大小關系,然后將元素按照升序排列,這就是自然排序。如果試圖將一個對象添加到TreeSet集合中,則該對象必須實現Comparable接口,否則會拋出異常。當一個對象調用方法與另一個對象比較時,例如obj1.compareTo(obj2),如果該方法返回0,則兩個對象相等;如果返回一個正數,則obj1大于obj2;如果返回一個負數,則obj1小于obj2。
Java常用類中已經實現了Comparable接口的類有以下幾個:
BigDecimal、BigDecimal以及所有數值型對應的包裝類:按照它們對應的數值大小進行比較。
Charchter:按照字符的unicode值進行比較。
Boolean:true對應的包裝類實例大于false對應的包裝類實例。
String:按照字符串中的字符的unicode值進行比較。
Date、Time:后面的時間、日期比前面的時間、日期大。
還有:Interger,Short,Long,Byte,Double,Float
對于TreeSet集合而言,它判斷兩個對象是否相等的標準是:兩個對象通過compareTo(Object obj)方法比較是否返回0,如果返回0則相等。
定制排序
想要實現定制排序,需要在創建TreeSet集合對象時,提供一個Comparator對象與該TreeSet集合關聯,由Comparator對象負責集合元素的排序邏輯。
綜上:自然排序實現的是Comparable接口,定制排序實現的是Comparator接口。
4)EnumSet類
EnumSet是一個專為枚舉類設計的集合類,不允許添加null值。EnumSet的集合元素也是有序的,它以枚舉值在Enum類內的定義順序來決定集合元素的順序。
5)各Set實現類的性能分析
HashSet的性能比TreeSet的性能好(特別是添加,查詢元素時),因為TreeSet需要額外的紅黑樹算法維護元素的次序,如果需要一個保持排序的Set時才用TreeSet,否則應該使用HashSet。
LinkedHashSet是HashSet的子類,由于需要鏈表維護元素的順序,所以插入和刪除操作比HashSet要慢,但遍歷比HashSet快。
EnumSet是所有Set實現類中性能最好的,但它只能 保存同一個枚舉類的枚舉值作為集合元素。
以上幾個Set實現類都是線程不安全的,如果多線程訪問,必須手動保證集合的同步性,這在后面的章節中會講到。
五、List集合
List集合代表一個有序、可重復集合,集合中每個元素都有其對應的順序索引。List集合默認按照元素的添加順序設置元素的索引,可以通過索引(類似數組的下標)來訪問指定位置的集合元素。
實現List接口的集合主要有:ArrayList、LinkedList、Vector、Stack。
1)ArrayList
ArrayList是一個動態數組,也是我們最常用的集合,是List類的典型實現。它允許任何符合規則的元素插入甚至包括null。每一個ArrayList都有一個初始容量(10),該容量代表了數組的大小。隨著容器中的元素不斷增加,容器的大小也會隨著增加。在每次向容器中增加元素的同時都會進行容量檢查,當快溢出時,就會進行擴容操作。所以如果我們明確所插入元素的多少,最好指定一個初始容量值,避免過多的進行擴容操作而浪費時間、效率。
ArrayList擅長于隨機訪問。同時ArrayList是非同步的。
2)LinkedList
LinkedList是List接口的另一個實現,除了可以根據索引訪問集合元素外,LinkedList還實現了Deque接口,可以當作雙端隊列來使用,也就是說,既可以當作“棧”使用,又可以當作隊列使用。
LinkedList的實現機制與ArrayList的實現機制完全不同,ArrayLiat內部以數組的形式保存集合的元素,所以隨機訪問集合元素有較好的性能;LinkedList內部以鏈表的形式保存集合中的元素,所以隨機訪問集合中的元素性能較差,但在插入刪除元素時有較好的性能。
3)Vector
與ArrayList相似,但是Vector是同步的。所以說Vector是線程安全的動態數組。它的操作與ArrayList幾乎一樣。
4)Stack
Stack繼承自Vector,實現一個后進先出的堆棧。Stack提供5個額外的方法使得Vector得以被當作堆棧使用。基本的push和pop 方法,還有peek方法得到棧頂的元素,empty方法測試堆棧是否為空,search方法檢測一個元素在堆棧中的位置。Stack剛創建后是空棧。
5)Iterator接口和ListIterator接口
Iterator是一個接口,它是集合的迭代器。集合可以通過Iterator去遍歷集合中的元素。Iterator提供的API接口如下:
boolean hasNext():判斷集合里是否存在下一個元素。如果有,hasNext()方法返回 true。
Object next():返回集合里下一個元素。
void remove():刪除集合里上一次next方法返回的元素。
ListIterator接口繼承Iterator接口,提供了專門操作List的方法。ListIterator接口在Iterator接口的基礎上增加了以下幾個方法:
boolean hasPrevious():判斷集合里是否存在上一個元素。如果有,該方法返回 true。
Object previous():返回集合里上一個元素。
void add(Object o):在指定位置插入一個元素。
以上兩個接口相比較,不難發現,ListIterator增加了向前迭代的功能(Iterator只能向后迭代),ListIterator還可以通過add()方法向List集合中添加元素(Iterator只能刪除元素)。
- Map集合
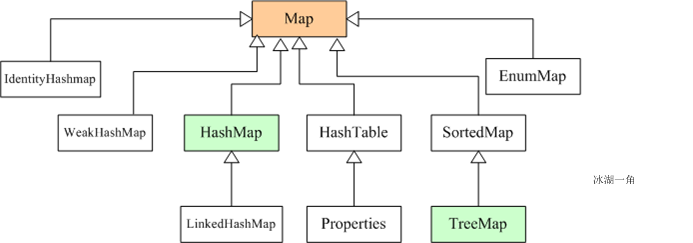
Map接口采用鍵值對Map<K,V>的存儲方式,保存具有映射關系的數據,因此,Map集合里保存兩組值,一組值用于保存Map里的key,另外一組值用于保存Map里的value,key和value可以是任意引用類型的數據。key值不允許重復,可以為null。如果添加key-value對時Map中已經有重復的key,則新添加的value會覆蓋該key原來對應的value。常用實現類有HashMap、LinkedHashMap、TreeMap等。
六、map
Map接口采用鍵值對Map<K,V>的存儲方式,保存具有映射關系的數據,因此,Map集合里保存兩組值,一組值用于保存Map里的key,另外一組值用于保存Map里的value,key和value可以是任意引用類型的數據。key值不允許重復,可以為null。如果添加key-value對時Map中已經有重復的key,則新添加的value會覆蓋該key原來對應的value。常用實現類有HashMap、LinkedHashMap、TreeMap等。
Map常見方法(來源于API)如下:
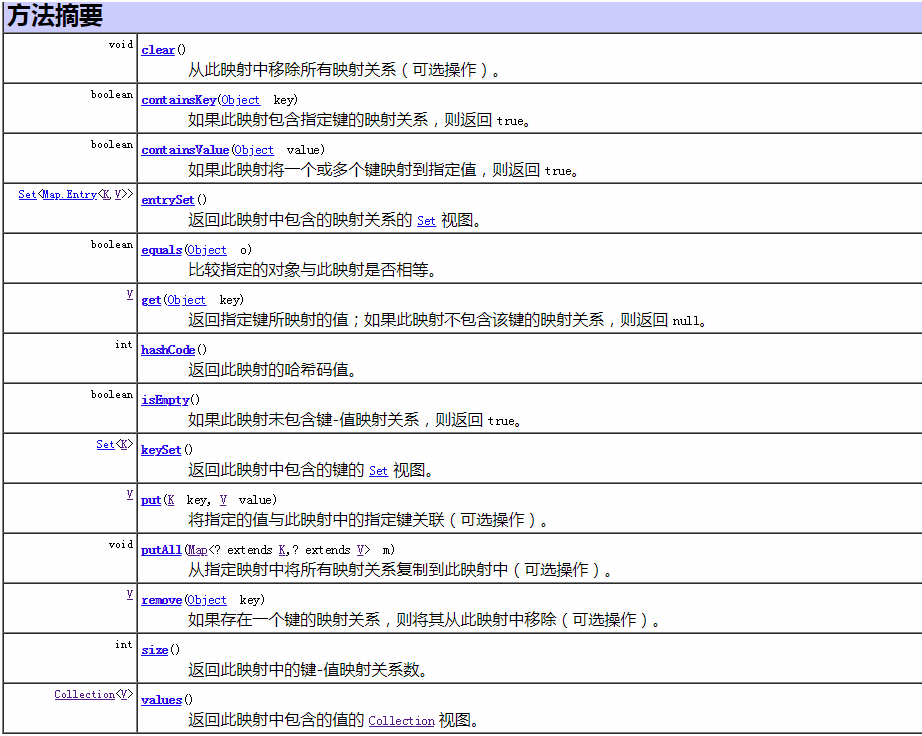
1)HashMap與Hashtable
HashMap與Hashtable是Map接口的兩個典型實現,它們之間的關系完全類似于ArrayList與Vertor。HashTable是一個古老的Map實現類,它提供的方法比較繁瑣,目前基本不用了,HashMap與Hashtable主要存在以下兩個典型區別:
HashMap是線程不安全,HashTable是線程安全的。
HashMap可以使用null值最為key或value;Hashtable不允許使用null值作為key和value,如果把null放進HashTable中,將會發生空指針異常。
為了成功的在HashMap和Hashtable中存儲和獲取對象,用作key的對象必須實現hashCode()方法和equals()方法。
HashMap工作原理如下:
HashMap基于hashing原理,通過put()和get()方法存儲和獲取對象。當我們將鍵值對傳遞給put()方法時,它調用建對象的hashCode()方法來計算hashCode值,然后找到bucket位置來儲存值對象。當獲取對象時,通過建對象的equals()方法找到正確的鍵值對,然后返回對象。HashMap使用鏈表來解決碰撞問題,當發生碰撞了,對象將會存儲在鏈表的下一個節點中。
2)LinkedHashMap實現類
LinkedHashMap使用雙向鏈表來維護key-value對的次序(其實只需要考慮key的次序即可),該鏈表負責維護Map的迭代順序,與插入順序一致,因此性能比HashMap低,但在迭代訪問Map里的全部元素時有較好的性能。
3)Properties
Properties類時Hashtable類的子類,它相當于一個key、value都是String類型的Map,主要用于讀取配置文件。
4)TreeMap實現類
TreeMap是SortedMap的實現類,是一個紅黑樹的數據結構,每個key-value對作為紅黑樹的一個節點。TreeMap存儲key-value對時,需要根據key對節點進行排序。TreeMap也有兩種排序方式:
自然排序:TreeMap的所有key必須實現Comparable接口,而且所有的key應該是同一個類的對象,否則會拋出ClassCastException。
定制排序:創建TreeMap時,傳入一個Comparator對象,該對象負責對TreeMap中的所有key進行排序。
5)各Map實現類的性能分析
HashMap通常比Hashtable(古老的線程安全的集合)要快
TreeMap通常比HashMap、Hashtable要慢,因為TreeMap底層采用紅黑樹來管理key-value。
LinkedHashMap比HashMap慢一點,因為它需要維護鏈表來爆出key-value的插入順序。
智能推薦
Java 集合與映射 簡介
Java集合總結 (只是想有基本的概念,請看這里;想了解具體內容,請從第二塊開始) 集合就是將若干用途,性質形同或相近的數據組合而成的一個整體 Java集合可以分為Set,List和Map三種體系 Set:不區分元素的順序,不允許出現重復元素 List:區分元素的順序,且允許包含重復元素 Map:鍵-值(Key-Value)映射中保存成對的鍵-值信息,映射中不能包含重復的鍵盤,每個鍵只能映射一個值...

Java中Connection集合簡介
一、Connection概括 1. Connection繼承關系 2. Connection架構 (圖片來自網絡) 3.說明 Connection是一個接口,是高度抽象的集合,它包含了集合的基本操作:對集合元素的增、刪、改、查、判斷是否為空,獲取大小、遍歷等操作; 根據Connection接口規范的建議:Collection接口的所有子類(直接子類和間接子類)都必須實現2種構造函數:不帶參數的構造...
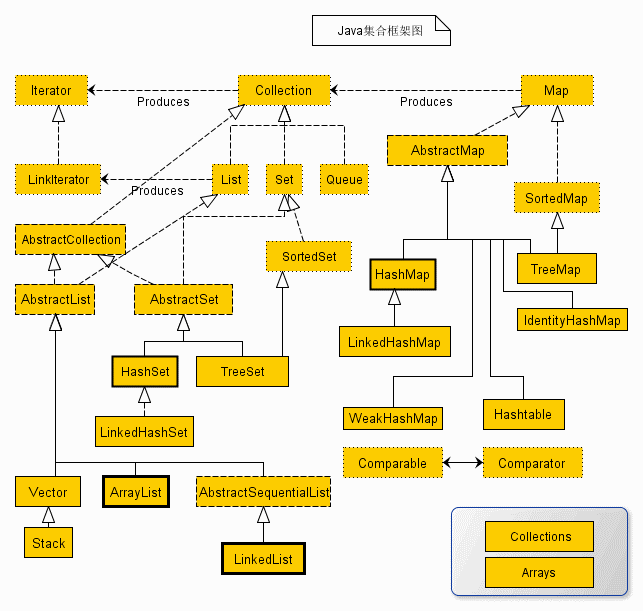
Java 集合框架
早在 Java 2 中之前,Java 就提供了特設類。比如:Dictionary, Vector, Stack, 和 Properties 這些類用來存儲和操作對象組。 雖然這些類都非常有用,但是它們缺少一個核心的,統一的主題。由于這個原因,使用 Vector 類的方式和使用 Properties 類的方式有著很大不同。 集合框架被設計成要滿足以下幾個目標。 該框架必須是高性能的。基本集合(動態數...
Java集合框架
文章目錄 1 兩大接口Collection與Map 1.1 Collection 1.2 Map 2 集合框架的使用 2.1 ArrayList的遍歷 2.1.1 迭代器遍歷 2.1.2 索引值遍歷 2.1.3 forEach循環遍歷 2.2 HashSet的遍歷(與List一致) 2.4 HashMap的遍歷 2.4.1 通過Map.keySet遍歷key和value 2.4.2 通過Map.e...

Java基礎——集合框架
一、集合 Java集合類存放于 java.util 包中,是一個用來存放對象的容器。Java 集合框架主要包括兩種類型的容器,一種是集合(Collection),存儲一個元素集合,另一種是圖(Map),存儲鍵/值對映射。 1)集合中只能存放對象; 2)...
猜你喜歡


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...
