python編程從入門到實踐
1、計算機核心基礎
1.1 什么是語言?什么是編程語言?為何要有編程語言?
語言其實就是人與人之間溝通的介質,如英語,漢語,俄語等。
編程語言則是人與計算機之間溝通的介質,
編程的目的就是為了讓計算機按照人類的思維邏輯(程序)自發地去工作從而把人力解放出來
二 計算機組成原理
2.1、什么是計算機?
俗稱電腦,即通電的大腦,電腦二字蘊含了人類對計算機的終極期望,希望它能真的像人腦一樣去工作,從而解放人力。
2.2、為什么要用計算機?
世界是由聰明的懶人統治的,任何時期,總有一群聰明的懶人想要奴隸別人。在奴隸制社會,聰明的懶人奴役的是真正的人,而人是無法不吃、不喝、不睡覺一直工作的,但是計算機作為一臺機器是可以做到的,所以把計算機當奴隸是上上之選
2.3、計算機的五大組成部分
1.控制器
:控制器是計算機的指揮系統,用來控制計算機其他組件的運行,相當于人類的大腦
2.運算器
:運算器是計算機的運算功能,用來做算術運算和邏輯運算,相當于人腦
ps:控制器+運算器=CPU,cpu相當于人的大腦
3.存儲器
:存儲器是計算機的記憶功能,用來存取數據。
存儲器主要分為內存與外存:
? 內存相當于人的短期記憶。斷電數據丟失
? 外存(如磁盤),相當于記事的本子,斷電數據不會丟失,是用來永久保存數據的
? ps:內存的存取速度要遠遠高于外存
4.輸入設備input
:輸入設備是計算接收外界輸入數據的工具,如鍵盤、鼠標,相當于人的眼睛或耳朵。
5.輸出設備output
:輸出設備是計算機向外輸出數據的工具,如顯示器、打印機,相當于人說的話,寫出的文章。
ps:存儲器如內存、磁盤等既是輸入設備又是輸出設備,統稱為IO設備
三大核心硬件為CPU、內存、硬盤。
程序最先是存放于硬盤中的,程序的運行是先從硬盤把代碼加載到內存中,然后cpu是從內存中讀取指令運行。
三 操作系統概述
3.1、操作系統的由來
操作系統的功能就是幫我們把復雜的硬件的控制封裝成簡單的接口,對于開發應用程序來說只需要調用操作系統提供給我們的接口即可
3.2、系統軟件與應用軟件
硬件以上運行的都是軟件,而軟件分為兩類:
一、應用軟件(例如qq、word、暴風影音,我們學習python就是為了開發應用軟件的)
二、操作系統,操作系統應用軟件與硬件之間的一個橋梁,是協調、管理、控制計算機硬件與應用軟件資源的控制程序。
3.3、計算機系統三層結構
應用程序
操作系統
計算機硬件
硬件 + 操作系統 == 平臺
2、編程語言與Python介紹
編程語言分類:
機器語言
機器語言是站在計算機(奴隸)的角度,說計算機能聽懂/理解的語言,而計算機能直接理解的就是二進制指令,所以機器語言就是直接用二進制編程,這意味著機器語言是直接操作硬件的,因此機器語言屬于低級語言,此處的低級指的是底層、貼近計算機硬件
#機器語言
用二進制代碼0和1描述的指令稱為機器指令,由于計算機內部是基于二進制指令工作的,所以機器語言是直接控制計算機硬件。
用機器語言編寫程序,編程人員要首先熟記所用計算機的全部指令代碼以及代碼的含義,然后在編寫程序時,程序員得自己處理每條指令和每一數據的存儲分配和輸入輸出,還得記住編程過程中每步所使用的工作單元處在何種狀態。這是一件十分繁瑣的工作。編寫程序花費的時間往往是實際運行時間的幾十倍或幾百倍。而且,編出的程序全是些0和1的指令代碼,直觀性差,不便閱讀和書寫,還容易出錯,且依賴于具體的計算機硬件型號,局限性很大。除了計算機生產廠家的專業人員外,絕大多數的程序員已經不再去學習機器語言了。
機器語言是被微處理器理解和使用的,存在有多至100000種機器語言的指令,下述是一些簡單示例
#指令部份的示例
0000 代表 加載(LOAD)
0001 代表 存儲(STORE)
...
#暫存器部份的示例
0000 代表暫存器 A
0001 代表暫存器 B
...
#存儲器部份的示例
000000000000 代表地址為 0 的存儲器
000000000001 代表地址為 1 的存儲器
000000010000 代表地址為 16 的存儲器
100000000000 代表地址為 2^11 的存儲器
#集成示例
0000,0000,000000010000 代表 LOAD A, 16
0000,0001,000000000001 代表 LOAD B, 1
0001,0001,000000010000 代表 STORE B, 16
0001,0001,000000000001 代表 STORE B, 1[1]
總結機器語言
# 1、執行效率最高
編寫的程序可以被計算機無障礙理解、直接運行,執行效率高 。
# 2、開發效率最低
復雜,開發效率低
# 3、跨平臺性差
貼近\依賴具體的硬件,跨平臺性差
匯編語言
匯編語言僅僅是用一個英文標簽代表一組二進制指令,毫無疑問,比起機器語言,匯編語言是一種進步,但匯編語言的本質仍然是直接操作硬件,因此匯編語言仍是比較低級/底層的語言、貼近計算機硬件
#匯編語言
匯編語言的實質和機器語言是相同的,都是直接對硬件操作,只不過指令采用了英文縮寫的標識符,更容易識別和記憶。它同樣需要編程者將每一步具體的操作用命令的形式寫出來。匯編程序的每一句指令只能對應實際操作過程中的一個很細微的動作。例如移動、自增,因此匯編源程序一般比較冗長、復雜、容易出錯,而且使用匯編語言編程需要有更多的計算機專業知識,但匯編語言的優點也是顯而易見的,用匯編語言所能完成的操作不是一般高級語言所能夠實現的,而且源程序經匯編生成的可執行文件不僅比較小,而且執行速度很快。
匯編的hello world,打印一句hello world, 需要寫十多行,如下
; hello.asm
section .data ; 數據段聲明
msg db "Hello, world!", 0xA ; 要輸出的字符串
len equ $ - msg ; 字串長度
section .text ; 代碼段聲明
global _start ; 指定入口函數
_start: ; 在屏幕上顯示一個字符串
mov edx, len ; 參數三:字符串長度
mov ecx, msg ; 參數二:要顯示的字符串
mov ebx, 1 ; 參數一:文件描述符(stdout)
mov eax, 4 ; 系統調用號(sys_write)
int 0x80 ; 調用內核功能
; 退出程序
mov ebx, 0 ; 參數一:退出代碼
mov eax, 1 ; 系統調用號(sys_exit)
int 0x80 ; 調用內核功能
總結匯編語言
# 1、執行效率高
相對于機器語言,使用英文標簽編寫程序相對簡單,執行效率高,但較之機器語言稍低,
# 2、開發效率低:
仍然是直接操作硬件,比起機器語言來說,復雜度稍低,但依舊居高不下,所以開發效率依舊較低
# 3、跨平臺性差
同樣依賴具體的硬件,跨平臺性差
高級語言
高級語言是站在人(奴隸主)的角度,說人話,即用人類的字符去編寫程序,而人類的字符是在向操作系統發送指令,而非直接操作硬件,所以高級語言是與操作系統打交道的,此處的高級指的是高層、開發者無需考慮硬件細節,因而開發效率可以得到極大的提升,但正因為高級語言離硬件較遠,更貼近人類語言,人類可以理解,而計算機則需要通過翻譯才能理解,所以執行效率會低于低級語言。
按照翻譯的方式的不同,高級語言又分為兩種:
編譯型(如C語言):
類似谷歌翻譯,是把程序所有代碼編譯成計算機能識別的二進制指令,之后操作系統會拿著編譯好的二進制指令直接操作硬件,詳細如下
# 1、執行效率高
編譯是指在應用源程序執行之前,就將程序源代碼“翻譯”成目標代碼(即機器語言),
因此其目標程序可以脫離其語言環境獨立執行,使用比較方便,執行效率較高。
# 2、開發效率低:
應用程序一旦需要修改,必須先修改源代碼,然后重新編譯、生成新的目標文件才能執行,
而在只有目標文件而沒有源代碼,修改會很不方便。所以開發效率低于解釋型
# 3、跨平臺性差
編譯型代碼是針對某一個平臺翻譯的,當前平臺翻譯的結果無法拿到不同的平臺使用,針對不同的平臺必須重新編譯,即跨平臺性差
# 其他
現在大多數的編程語言都是編譯型的。
編譯程序將源程序翻譯成目標程序后保存在另一個文件中,該目標程序可脫離編譯程序直接在計算機上多次運行。
大多數軟件產品都是以目標程序形式發行給用戶的,不僅便于直接運行,同時又使他人難于盜用其中的技術。
C、C++、Ada、Pascal都是編譯實現的
解釋型(如python):
類似同聲翻譯,需要有一個解釋器,解釋器會讀取程序代碼,一邊翻譯一邊執行,詳細如下
# 1、執行效率低
解釋型語言的實現中,翻譯器并不產生目標機器代碼,而是產生易于執行的中間代碼。
這種中間代碼與機器代碼是不同的,中間代碼的解釋是由軟件支持的,不能直接使用硬件,
軟件解釋器通常會導致執行效率較低。
# 2、開發效率高
用解釋型語言編寫的程序是由另一個可以理解中間代碼的解釋程序執行的,與編譯程序不同的是,
解釋程序的任務是逐一將源程序的語句解釋成可執行的機器指令,不需要將源程序翻譯成目標代碼再執行。
解釋程序的優點是當語句出現語法錯誤時,可以立即引起程序員的注意,而程序員在程序開發期間就能進行校正。
# 3、跨平臺性強
代碼運行是依賴于解釋器,不同平臺有對應版本的解釋器,所以解釋型的跨平臺性強
# 其他
對于解釋型Basic語言,需要一個專門的解釋器解釋執行Basic程序,每條語句只有在執行時才被翻譯,
這種解釋型語言每執行一次就翻譯一次,因而效率低下。一般地,動態語言都是解釋型的,
例如:Tcl、Perl、Ruby、VBScript、JavaScript等
ps:混合型語言
java是一類特殊的編程語言,Java程序也需要編譯,但是卻沒有直接編譯為機器語言,而是編譯為字節碼,
然后在Java虛擬機上以解釋方式執行字節碼。
總結
綜上選擇不同編程語言來開發應用程序對比
#1、執行效率:機器語言>匯編語言>高級語言(編譯型>解釋型)
#2、開發效率:機器語言<匯編語言<高級語言(編譯型<解釋型)
#3、跨平臺性:解釋型具有極強的跨平臺型
三 python介紹
談及python,涉及兩層意思,一層代表的是python這門語言的語法風格,另外一層代表的則是專門用來解釋該語法風格的應用程序:python解釋器。
Python崇尚優美、清晰、簡單,是一個優秀并廣泛使用的語言
Python解釋器的發展史
從一出生,Python已經具有了:類,函數,異常處理,包含表和詞典在內的核心數據類型,以及模塊為基礎的拓展系統。
Python解釋器有哪些種類?
官方的Python解釋器本質就是基于C語言開發的一個軟件,該軟件的功能就是讀取以.py結尾的文件內容,然后按照Guido定義好的語法和規則去翻譯并執行相應的代碼。
# Jython
JPython解釋器是用JAVA編寫的python解釋器,可以直接把Python代碼編譯成Java字節碼并執行,它不但使基于java的項目之上嵌入python腳本成為可能,同時也可以將java程序引入到python程序之中。
# IPython
IPython是基于CPython之上的一個交互式解釋器,也就是說,IPython只是在交互方式上有所增強,但是執行Python代碼的功能和CPython是完全一樣的。這就好比很多國產瀏覽器雖然外觀不同,但內核其實都是調用了IE。
CPython用>>>作為提示符,而IPython用In [序號]:作為提示符。
# PyPy
PyPy是Python開發者為了更好地Hack Python而用Python語言實現的Python解釋器。PyPy提供了JIT編譯器和沙盒功能,對Python代碼進行動態編譯(注意不是解釋),因此運行速度比CPython還要快。
# IronPython
IronPython和Jython類似,只不過IronPython是運行在微軟.Net平臺上的Python解釋器,可以直接把Python代碼編譯成.Net的字節碼。
四 安裝Cpython解釋器
Python解釋器目前已支持所有主流操作系統,在Linux,Unix,Mac系統上自帶Python解釋器,在Windows系統上需要安裝一下,具體步驟如下。
4.1、下載python解釋器
https://www.python.org
4.2、安裝python解釋器
4.3、測試安裝是否成功
windows --> 運行 --> 輸入cmd ,然后回車,彈出cmd程序,輸入python,如果能進入交互環境 ,代表安裝成功。
五 第一個python程序
5.1 運行python程序有兩種方式
方式一: 交互式模式
方式二:腳本文件
# 1、打開一個文本編輯工具,寫入下述代碼,并保存文件,此處文件的路徑為D:\test.py。強調:python解釋器執行程序是解釋執行,解釋的根本就是打開文件讀內容,因此文件的后綴名沒有硬性限制,但通常定義為.py結尾
print('hello world')
# 2、打開cmd,運行命令,如下圖
總結:
#1、交互式模式下可以即時得到代碼執行結果,調試程序十分方便
#2、若想將代碼永久保存下來,則必須將代碼寫入文件中
#3、我們以后主要就是在代碼寫入文件中,偶爾需要打開交互式模式調試某段代碼、驗證結果
5.2 注釋
在正式學習python語法前,我們必須事先介紹一個非常重要的語法:注釋
1、什么是注釋
注釋就是就是對代碼的解釋說明,注釋的內容不會被當作代碼運行
2、為什么要注釋
增強代碼的可讀性
3、怎么用注釋?
代碼注釋分單行和多行注釋
1、單行注釋用#號,可以跟在代碼的正上方或者正后方
2、多行注釋可以用三對雙引號""" """
4、代碼注釋的原則:
1、不用全部加注釋,只需要為自己覺得重要或不好理解的部分加注釋即可
2、注釋可以用中文或英文,但不要用拼音
六 IDE工具pycharm的使用
在編寫第一個python程序時,存在以下問題,嚴重影響開發效率
問題一:我們了解到一個python程序從開發到運行需要操作至少兩個軟件
1、打開一個軟件:文本編輯器,創建文本來編寫程序
2、打開cmd,然后輸入命令執行pyton程序
問題二:在開發過程中,并沒代碼提示以及糾錯功能
綜上,如果能有一款工具能夠集成n個軟件的功能,同時又代碼提示以及糾錯等功能,那么將會極大地提升程序員的開發效率,這就是IDE的由來,IDE全稱Integrated Development Environment,即集成開發環境,最好的開發Python程序的IDE就是PyCharm。
6.2、pychram安裝
# 下載地址: https://www.jetbrains.com/pycharm/download 選擇Professional專業版
6.3、Pycharm創建文件夾
6.4、如何創建文件并編寫程序執行
創建py文件test.py
在test.py中寫代碼,輸入關鍵字的開頭可以用tab鍵補全后續,并且會有代碼的錯誤提示
3、Python語法入門之變量
一 引入
我們學習python語言是為了控制計算機、讓計算機能夠像人一樣去工作,所以在python這門語言中,所有語法存在的意義都是為了讓計算機具備人的某一項技能,這句話是我們理解后續所有python語法的根本。
二 變量
一、什么是變量?
# 變量就是可以變化的量,量指的是事物的狀態,比如人的年齡、性別,游戲角色的等級、金錢等等
二、為什么要有變量?
# 為了讓計算機能夠像人一樣去記憶事物的某種狀態,并且狀態是可以發生變化的
# 詳細地說:
# 程序執行的本質就是一系列狀態的變化,變是程序執行的直接體現,所以我們需要有一種機制能夠反映或者說是保存下來程序執行時狀態,以及狀態的變化。
三、怎么使用變量(先定義、后使用)
3.1、變量的定義與使用
定義變量示范如下
name = 'harry' # 記下人的名字為'harry'
sex = '男' # 記下人的性別為男性
age = 18 # 記下人的年齡為18歲
salary = 30000.1 # 記下人的薪資為30000.1元
解釋器執行到變量定義的代碼時會申請內存空間存放變量值,然后將變量值的內存地址綁定給變量名,以變量的定義age=18為例,如下圖
插圖:定義變量申請內存
通過變量名即可引用到對應的值
# 通過變量名即可引用到值,我們可以結合print()功能將其打印出來
print(age) # 通過變量名age找到值18,然后執行print(18),輸出:18
# 命名規范
1. 變量名只能是 字母、數字或下劃線的任意組合
2. 變量名的第一個字符不能是數字
3. 關鍵字不能聲明為變量名,常用關鍵字如下
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from','global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
年齡=18 # 強烈建議不要使用中文命名
3.3、變量名的命名風格
# 風格一:駝峰體
AgeOfTony = 56
NumberOfStudents = 80
# 風格二:純小寫下劃線(在python中,變量名的命名推薦使用該風格)
age_of_tony = 56
number_of_students = 80
3.4、變量值的三大特性
#1、id
反應的是變量在內存中的唯一編號,內存地址不同id肯定不同
#2、type
變量值的類型
#3、value
變量值
三、常量
3.1、什么是常量?
常量指在程序運行過程中不會改變的量
3.2、為什么要有常量?
在程序運行過程中,有些值是固定的、不應該被改變,比如圓周率 3.141592653…
3.3、怎么使用常量?
在Python中沒有一個專門的語法定義常量,約定俗成是用全部大寫的變量名表示常量。如:PI=3.14159。所以單從語法層面去講,常量的使用與變量完全一致。
4、Python語法入門之基本數據類型
一 引入
變量值也有不同的類型
salary = 3.1 # 用浮點型去記錄薪資
age = 18 # 用整型去記錄年齡
name = 'lili' # 用字符串類型去記錄人名
二 數字類型
2.1 int整型
2.1.1 作用
用來記錄人的年齡,出生年份,學生人數等整數相關的狀態
2.1.2 定義
age=18
birthday=1990
student_count=48
2.2 float浮點型
2.2.1 作用
用來記錄人的身高,體重,薪資等小數相關的狀態
2.2.2 定義
height=172.3
weight=103.5
salary=15000.89
2.3 數字類型的使用
1 、數學運算
>>> a = 1
>>> b = 3
>>> c = a + b
>>> c
4
2、比較大小
>>> x = 10
>>> y = 11
>>> x > y
False
三 字符串類型str
3.1 作用
用來記錄人的名字,家庭住址,性別等描述性質的狀態
3.2 定義
name = 'harry'
address = '上海市浦東新區'
sex = '男'
用單引號、雙引號、多引號,都可以定義字符串,本質上是沒有區別的,但是
#1、需要考慮引號嵌套的配對問題
msg = "My name is Tony , I'm 18 years old!" #內層有單引號,外層就需要用雙引號
#2、多引號可以寫多行字符串
msg = '''
天下只有兩種人。比如一串葡萄到手,一種人挑最好的先吃,另一種人把最好的留到最后吃。
照例第一種人應該樂觀,因為他每吃一顆都是吃剩的葡萄里最好的;第二種人應該悲觀,因為他每吃一顆都是吃剩的葡萄里最壞的。
不過事實卻適得其反,緣故是第二種人還有希望,第一種人只有回憶。
'''
3.3 使用
數字可以進行加減乘除等運算,字符串呢?也可以,但只能進行"相加"和"相乘"運算。
>>> name = 'tony'
>>> age = '18'
>>> name + age #相加其實就是簡單的字符串拼接
'tony18'
>>> name * 5 #相乘就相當于將字符串相加了5次
'tonytonytonytonytony'
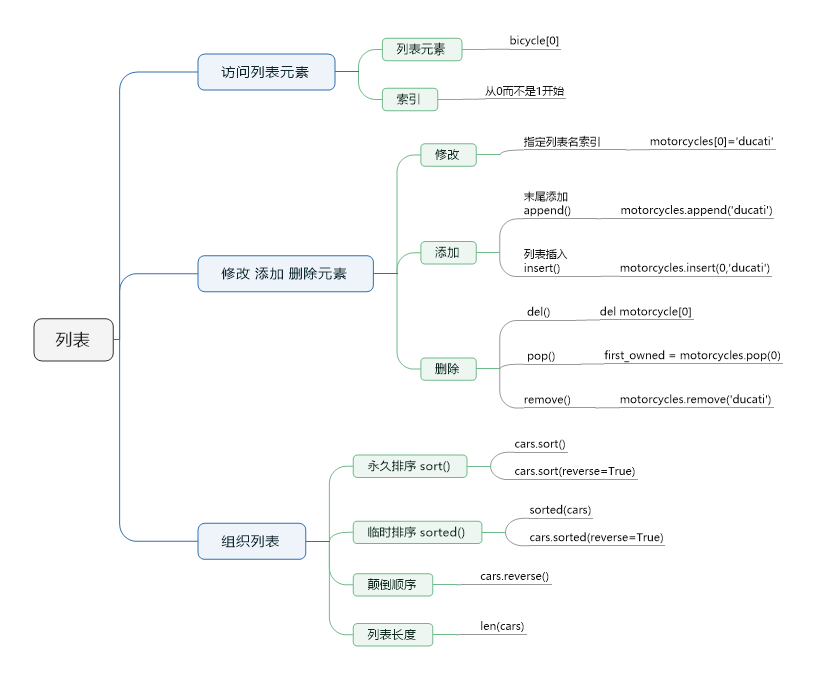
四 列表list
4.1 作用
如果我們需要用一個變量記錄多個學生的姓名,用數字類型是無法實現,字符串類型確實可以記錄下來,比如
stu_names=‘張三 李四 王五’,但存的目的是為了取,此時若想取出第二個學生的姓名實現起來相當麻煩,而列表類型就是專門用來記錄多個同種屬性的值(比如同一個班級多個學生的姓名、同一個人的多個愛好等),并且存取都十分方便
4.2 定義
>>> stu_names=['張三','李四','王五']
4.3 使用
# 1、列表類型是用索引來對應值,索引代表的是數據的位置,從0開始計數
>>> stu_names=['張三','李四','王五']
>>> stu_names[0]
'張三'
>>> stu_names[1]
'李四'
>>> stu_names[2]
'王五'
# 2、列表可以嵌套,嵌套取值如下
>>> students_info=[['tony',18,['jack',]],['jason',18,['play','sleep']]]
>>> students_info[0][2][0] #取出第一個學生的第一個愛好
'play'
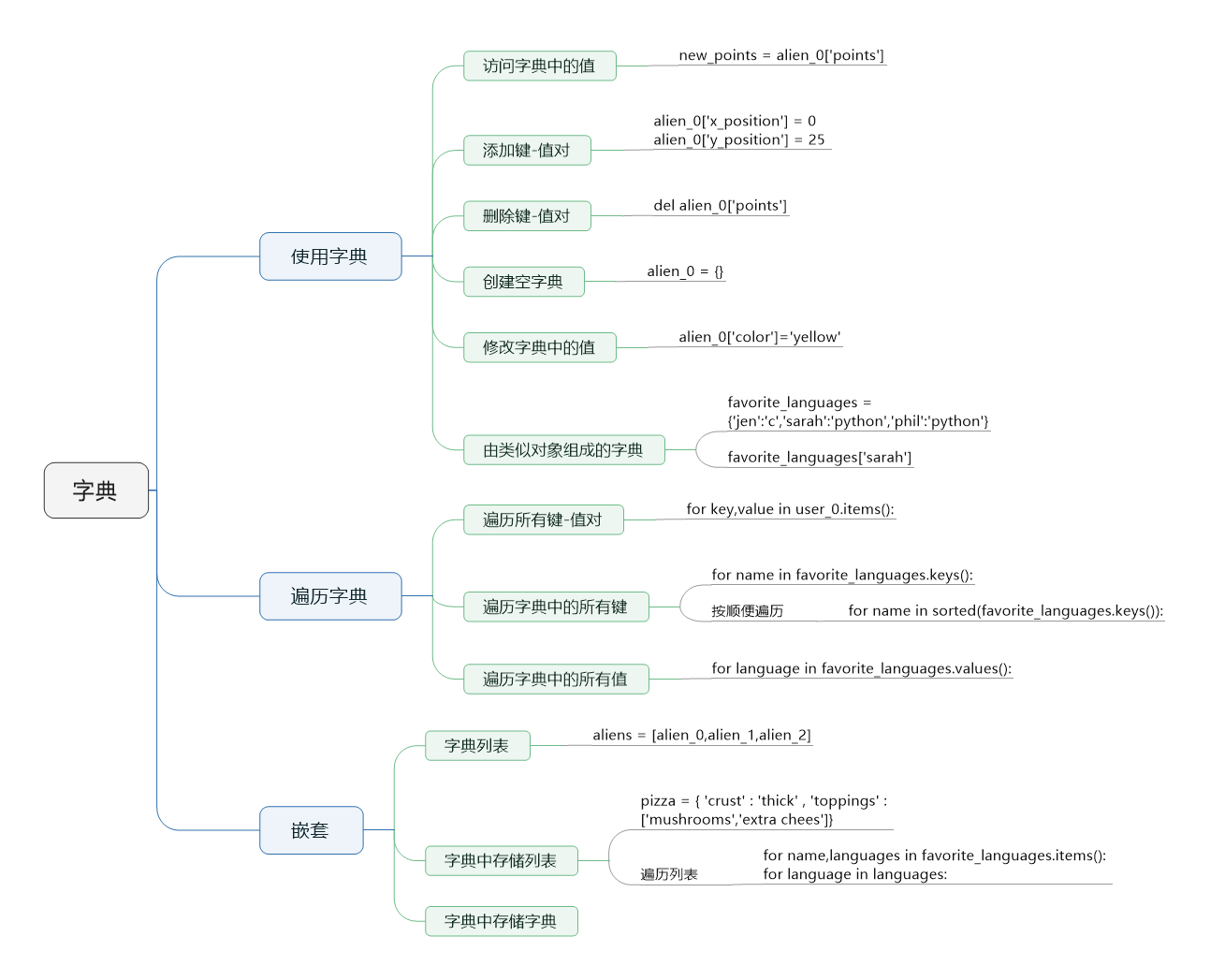
五 字典dict
5.1 作用
如果我們需要用一個變量記錄多個值,但多個值是不同屬性的,比如人的姓名、年齡、身高,用列表可以存,但列表是用索引對應值的,而索引不能明確地表示值的含義,這就用到字典類型,字典類型是用key:value形式來存儲數據,其中key可以對value有描述性的功能
5.2 定義
>>> person_info={'name':'tony','age':18,'height':185.3}
5.3 使用
# 1、字典類型是用key來對應值,key可以對值有描述性的功能,通常為字符串類型
>>> person_info={'name':'tony','age':18,'height':185.3}
>>> person_info['name']
'tony'
>>> person_info['age']
18
>>> person_info['height']
185.3
# 2、字典可以嵌套,嵌套取值如下
>>> students=[
... {'name':'tony','age':38,'hobbies':['play','sleep']},
... {'name':'jack','age':18,'hobbies':['read','sleep']},
... {'name':'rose','age':58,'hobbies':['music','read','sleep']},
... ]
>>> students[1]['hobbies'][1] #取第二個學生的第二個愛好
'sleep'
六 布爾bool
6.1 作用
用來記錄真假這兩種狀態
6.2 定義
>>> is_ok = True
>>> is_ok = False
6.3 使用
通常用來當作判斷的條件,我們將在if判斷中用到它
5、Python語法入門之垃圾回收機制
一 引入
解釋器在執行到定義變量的語法時,會申請內存空間來存放變量的值,而內存的容量是有限的,這就涉及到變量值所占用內存空間的回收問題,當一個變量值沒有用了(簡稱垃圾)就應該將其占用的內存給回收掉,那什么樣的變量值是沒有用的呢?
? 單從邏輯層面分析,我們定義變量將變量值存起來的目的是為了以后取出來使用,而取得變量值需要通過其綁定的直接引用(如x=10,10被x直接引用)或間接引用(如l=[x,],x=10,10被x直接引用,而被容器類型l間接引用),所以當一個變量值不再綁定任何引用時,我們就無法再訪問到該變量值了,該變量值自然就是沒有用的,就應該被當成一個垃圾回收。
? 毫無疑問,內存空間的申請與回收都是非常耗費精力的事情,而且存在很大的危險性,稍有不慎就有可能引發內存溢出問題,好在Cpython解釋器提供了自動的垃圾回收機制來幫我們解決了這件事。
二、什么是垃圾回收機制?
垃圾回收機制(簡稱GC)是Python解釋器自帶一種機,專門用來回收不可用的變量值所占用的內存空間
三、為什么要用垃圾回收機制?
程序運行過程中會申請大量的內存空間,而對于一些無用的內存空間如果不及時清理的話會導致內存使用殆盡(內存溢出),導致程序崩潰,因此管理內存是一件重要且繁雜的事情,而python解釋器自帶的垃圾回收機制把程序員從繁雜的內存管理中解放出來。
四、理解GC原理需要儲備的知識
4.1、堆區與棧區
在定義變量時,變量名與變量值都是需要存儲的,分別對應內存中的兩塊區域:堆區與棧區
# 1、變量名與值內存地址的關聯關系存放于棧區
# 2、變量值存放于堆區,內存管理回收的則是堆區的內容,
4.2 直接引用與間接引用
直接引用指的是從棧區出發直接引用到的內存地址。
間接引用指的是從棧區出發引用到堆區后,再通過進一步引用才能到達的內存地址。
如
l2 = [20, 30] # 列表本身被變量名l2直接引用,包含的元素被列表間接引用
x = 10 # 值10被變量名x直接引用
l1 = [x, l2] # 列表本身被變量名l1直接引用,包含的元素被列表間接引用
五、垃圾回收機制原理分析
Python的GC模塊主要運用了“引用計數”(reference counting)來跟蹤和回收垃圾。在引用計數的基礎上,還可以通過“標記-清除”(mark and sweep)解決容器對象可能產生的循環引用的問題,并且通過“分代回收”(generation collection)以空間換取時間的方式來進一步提高垃圾回收的效率。
5.1、引用計數
引用計數就是:變量值被變量名關聯的次數
如:age=18
變量值18被關聯了一個變量名age,稱之為引用計數為1
引用計數增加:
age=18 (此時,變量值18的引用計數為1)
m=age (把age的內存地址給了m,此時,m,age都關聯了18,所以變量值18的引用計數為2)
引用計數減少:
age=10(名字age先與值18解除關聯,再與3建立了關聯,變量值18的引用計數為1)
del m(del的意思是解除變量名x與變量值18的關聯關系,此時,變量18的引用計數為0)
值18的引用計數一旦變為0,其占用的內存地址就應該被解釋器的垃圾回收機制回收
5.2、引用計數的問題與解決方案
5.2.1 問題一:循環引用
引用計數機制存在著一個致命的弱點,即循環引用(也稱交叉引用)
# 如下我們定義了兩個列表,簡稱列表1與列表2,變量名l1指向列表1,變量名l2指向列表2
>>> l1=['xxx'] # 列表1被引用一次,列表1的引用計數變為1
>>> l2=['yyy'] # 列表2被引用一次,列表2的引用計數變為1
>>> l1.append(l2) # 把列表2追加到l1中作為第二個元素,列表2的引用計數變為2
>>> l2.append(l1) # 把列表1追加到l2中作為第二個元素,列表1的引用計數變為2
# l1與l2之間有相互引用
# l1 = ['xxx'的內存地址,列表2的內存地址]
# l2 = ['yyy'的內存地址,列表1的內存地址]
>>> l1
['xxx', ['yyy', [...]]]
>>> l2
['yyy', ['xxx', [...]]]
>>> l1[1][1][0]
'xxx'
python引入了“標記-清除” 與“分代回收”來分別解決引用計數的循環引用與效率低的問題
5.2.2 解決方案:標記-清除
容器對象(比如:list,set,dict,class,instance)都可以包含對其他對象的引用,所以都可能產生循環引用。而“標記-清除”計數就是為了解決循環引用的問題。
標記/清除算法的做法是當應用程序可用的內存空間被耗盡的時,就會停止整個程序,然后進行兩項工作,第一項則是標記,第二項則是清除
5.2.3 問題二:效率問題
基于引用計數的回收機制,每次回收內存,都需要把所有對象的引用計數都遍歷一遍,這是非常消耗時間的,于是引入了分代回收來提高回收效率,分代回收采用的是用“空間換時間”的策略。
5.2.4 解決方案:分代回收
代:
分代回收的核心思想是:在歷經多次掃描的情況下,都沒有被回收的變量,gc機制就會認為,該變量是常用變量,gc對其掃描的頻率會降低,具體實現原理如下:
分代指的是根據存活時間來為變量劃分不同等級(也就是不同的代)
新定義的變量,放到新生代這個等級中,假設每隔1分鐘掃描新生代一次,如果發現變量依然被引用,那么該對象的權重(權重本質就是個整數)加一,當變量的權重大于某個設定得值(假設為3),會將它移動到更高一級的青春代,青春代的gc掃描的頻率低于新生代(掃描時間間隔更長),假設5分鐘掃描青春代一次,這樣每次gc需要掃描的變量的總個數就變少了,節省了掃描的總時間,接下來,青春代中的對象,也會以同樣的方式被移動到老年代中。也就是等級(代)越高,被垃圾回收機制掃描的頻率越低
回收:
回收依然是使用引用計數作為回收的依據
雖然分代回收可以起到提升效率的效果,但也存在一定的缺點:
例如一個變量剛剛從新生代移入青春代,該變量的綁定關系就解除了,該變量應該被回收,但青春代的掃描頻率低于新生代,這就到導致了應該被回收的垃圾沒有得到及時地清理。
沒有十全十美的方案:
毫無疑問,如果沒有分代回收,即引用計數機制一直不停地對所有變量進行全體掃描,可以更及時地清理掉垃圾占用的內存,但這種一直不停地對所有變量進行全體掃描的方式效率極低,所以我們只能將二者中和。
綜上
垃圾回收機制是在清理垃圾&釋放內存的大背景下,允許分代回收以極小部分垃圾不會被及時釋放為代價,以此換取引用計數整體掃描頻率的降低,從而提升其性能,這是一種以空間換時間的解決方案目錄
6、Python語法入門之與用戶交互、運算符
一 程序與用戶交互
1.1、什么是與用戶交互
用戶交互就是人往計算機中input/輸入數據,計算機print/輸出結果
1.2、為什么要與用戶交互?
為了讓計算機能夠像人一樣與用戶溝通交流
1.3、如何與用戶交互
交互的本質就是輸入、輸出
1.3.1 輸入input:
# 在python3中input功能會等待用戶的輸入,用戶輸入任何內容,都存成字符串類型,然后賦值給等號左邊的變量名
>>> username=input('請輸入您的用戶名:')
請輸入您的用戶名:jack # username = "jack"
>>> password=input('請輸入您的密碼:')
請輸入您的密碼:123 # password = "123"
# 了解知識:
# 1、在python2中存在一個raw_input功能與python3中的input功能一模一樣
# 2、在python2中還存在一個input功能,需要用戶輸入一個明確的數據類型,輸入什么類型就存成什么類型
>>> l=input('輸入什么類型就存成什么類型: ')
輸入什么類型就存成什么類型: [1,2,3]
>>> type(l)
<type 'list'>
1.3.2 輸出print:
>>> print('hello world') # 只輸出一個值
hello world
>>> print('first','second','third') # 一次性輸出多個值,值用逗號隔開
first second third
# 默認print功能有一個end參數,該參數的默認值為"\n"(代表換行),可以將end參數的值改成任意其它字符
print("aaaa",end='')
print("bbbb",end='&')
print("cccc",end='@')
#整體輸出結果為:aaaabbbb&cccc@
1.3.3 輸出之格式化輸出
(1)什么是格式化輸出?
把一段字符串里面的某些內容替換掉之后再輸出,就是格式化輸出。
(2)為什么要格式化輸出?
我們經常會輸出具有某種固定格式的內容,比如:'親愛的xxx你好!你xxx月的話費是xxx,余額是xxx‘,我們需要做的就是將xxx替換為具體的內容。
(3)如何格式化輸出?
這就用到了占位符,如:%s、%d:
# %s占位符:可以接收任意類型的值
# %d占位符:只能接收數字
>>> print('親愛的%s你好!你%s月的話費是%d,余額是%d' %('tony',12,103,11))
親愛的tony你好!你12月的話費是103,余額是11
# 練習1:接收用戶輸入,打印成指定格式
name = input('your name: ')
age = input('your age: ') #用戶輸入18,會存成字符串18,無法傳給%d
print('My name is %s,my age is %s' %(name,age))
# 練習2:用戶輸入姓名、年齡、工作、愛好 ,然后打印成以下格式
------------ info of Tony -----------
Name : Tony
Age : 22
Sex : male
Job : Teacher
------------- end -----------------
二 基本運算符
2.1 算術運算符
python支持的算數運算符與數學上計算的符號使用是一致的,我們以x=9,y=2為例來依次介紹它們
2.2 比較運算符
比較運算用來對兩個值進行比較,返回的是布爾值True或False,我們以x=9,y=2為例來依次介紹它們
2.3 賦值運算符
python語法中除了有=號這種簡單的賦值運算外,還支持增量賦值、鏈式賦值、交叉賦值、解壓賦值,這些賦值運算符存在的意義都是為了讓我們的代碼看起來更加精簡。我們以x=9,y=2為例先來介紹一下增量賦值
2.3.1 增量賦值
2.3.2 鏈式賦值
如果我們想把同一個值同時賦值給多個變量名,可以這么做
>>> z=10
>>> y=z
>>> x=y
>>> x,y,z
(10, 10, 10)
鏈式賦值指的是可以用一行代碼搞定這件事
>>> x=y=z=10
>>> x,y,z
(10, 10, 10)
2.3.3 交叉賦值
我們定義兩個變量m與n
如果我們想將m與n的值交換過來,可以這么做
>>> temp=m
>>> m=n
>>> n=temp
>>> m,n
(20, 10)
交叉賦值指的是一行代碼可以搞定這件事
>>> m=10
>>> n=20
>>> m,n=n,m # 交叉賦值
>>> m,n
(20, 10)
2.3.4 解壓賦值
如果我們想把列表中的多個值取出來依次賦值給多個變量名,可以這么做
>>> nums=[11,22,33,44,55]
>>>
>>> a=nums[0]
>>> b=nums[1]
>>> c=nums[2]
>>> d=nums[3]
>>> e=nums[4]
>>> a,b,c,d,e
(11, 22, 33, 44, 55)
解壓賦值指的是一行代碼可以搞定這件事
>>> a,b,c,d,e=nums # nums包含多個值,就好比一個壓縮包,解壓賦值因此得名
>>> a,b,c,d,e
(11, 22, 33, 44, 55)
注意,上述解壓賦值,等號左邊的變量名個數必須與右面包含值的個數相同,否則會報錯
#1、變量名少了
>>> a,b=nums
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: too many values to unpack (expected 2)
#2、變量名多了
>>> a,b,c,d,e,f=nums
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: not enough values to unpack (expected 6, got 5)
但如果我們只想取頭尾的幾個值,可以用*_匹配
>>> a,b,*_=nums
>>> a,b
(11, 22)
ps:字符串、字典、元組、集合類型都支持解壓賦值
2.4 邏輯運算符
邏輯運算符用于連接多個條件,進行關聯判斷,會返回布爾值True或False
2.4.1 連續多個and
可以用and連接多個條件,會按照從左到右的順序依次判斷,一旦某一個條件為False,則無需再往右判斷,可以立即判定最終結果就為False,只有在所有條件的結果都為True的情況下,最終結果才為True。
>>> 2 > 1 and 1 != 1 and True and 3 > 2 # 判斷完第二個條件,就立即結束,得的最終結果為False
False
2.4.2 連續多個or
可以用or連接多個條件,會按照從左到右的順序依次判斷,一旦某一個條件為True,則無需再往右判斷,可以立即判定最終結果就為True,只有在所有條件的結果都為False的情況下,最終結果才為False
>>> 2 > 1 or 1 != 1 or True or 3 > 2 # 判斷完第一個條件,就立即結束,得的最終結果為True
True
2.4.3 優先級not>and>or
#1、三者的優先級關系:not>and>or,同一優先級默認從左往右計算。
>>> 3>4 and 4>3 or 1==3 and 'x' == 'x' or 3 >3
False
#2、最好使用括號來區別優先級,其實意義與上面的一樣
'''
原理為:
(1) not的優先級最高,就是把緊跟其后的那個條件結果取反,所以not與緊跟其后的條件不可分割
(2) 如果語句中全部是用and連接,或者全部用or連接,那么按照從左到右的順序依次計算即可
(3) 如果語句中既有and也有or,那么先用括號把and的左右兩個條件給括起來,然后再進行運算
'''
>>> (3>4 and 4>3) or (1==3 and 'x' == 'x') or 3 >3
False
#3、短路運算:邏輯運算的結果一旦可以確定,那么就以當前處計算到的值作為最終結果返回
>>> 10 and 0 or '' and 0 or 'abc' or 'egon' == 'dsb' and 333 or 10 > 4
我們用括號來明確一下優先級
>>> (10 and 0) or ('' and 0) or 'abc' or ('egon' == 'dsb' and 333) or 10 > 4
短路: 0 '' 'abc'
假 假 真
返回: 'abc'
#4、短路運算面試題:
>>> 1 or 3
1
>>> 1 and 3
3
>>> 0 and 2 and 1
0
>>> 0 and 2 or 1
1
>>> 0 and 2 or 1 or 4
1
>>> 0 or False and 1
False
2.5 成員運算符
注意:雖然下述兩種判斷可以達到相同的效果,但我們推薦使用第二種格式,因為not in語義更加明確
>>> not 'lili' in ['jack','tom','robin']
True
>>> 'lili' not in ['jack','tom','robin']
True
2.6 身份運算符
需要強調的是:==雙等號比較的是value是否相等,而is比較的是id是否相等
#1. id相同,內存地址必定相同,意味著type和value必定相同
#2. value相同type肯定相同,但id可能不同,如下
>>> x='Info Tony:18'
>>> y='Info Tony:18'
>>> id(x),id(y) # x與y的id不同,但是二者的值相同
(4327422640, 4327422256)
>>> x == y # 等號比較的是value
True
>>> type(x),type(y) # 值相同type肯定相同
(<class 'str'>, <class 'str'>)
>>> x is y # is比較的是id,x與y的值相等但id可以不同
False
7、Python語法入門之流程控制
一 引子:
流程控制即控制流程,具體指控制程序的執行流程,而程序的執行流程分為三種結構:順序結構(之前我們寫的代碼都是順序結構)、分支結構(用到if判斷)、循環結構(用到while與for)
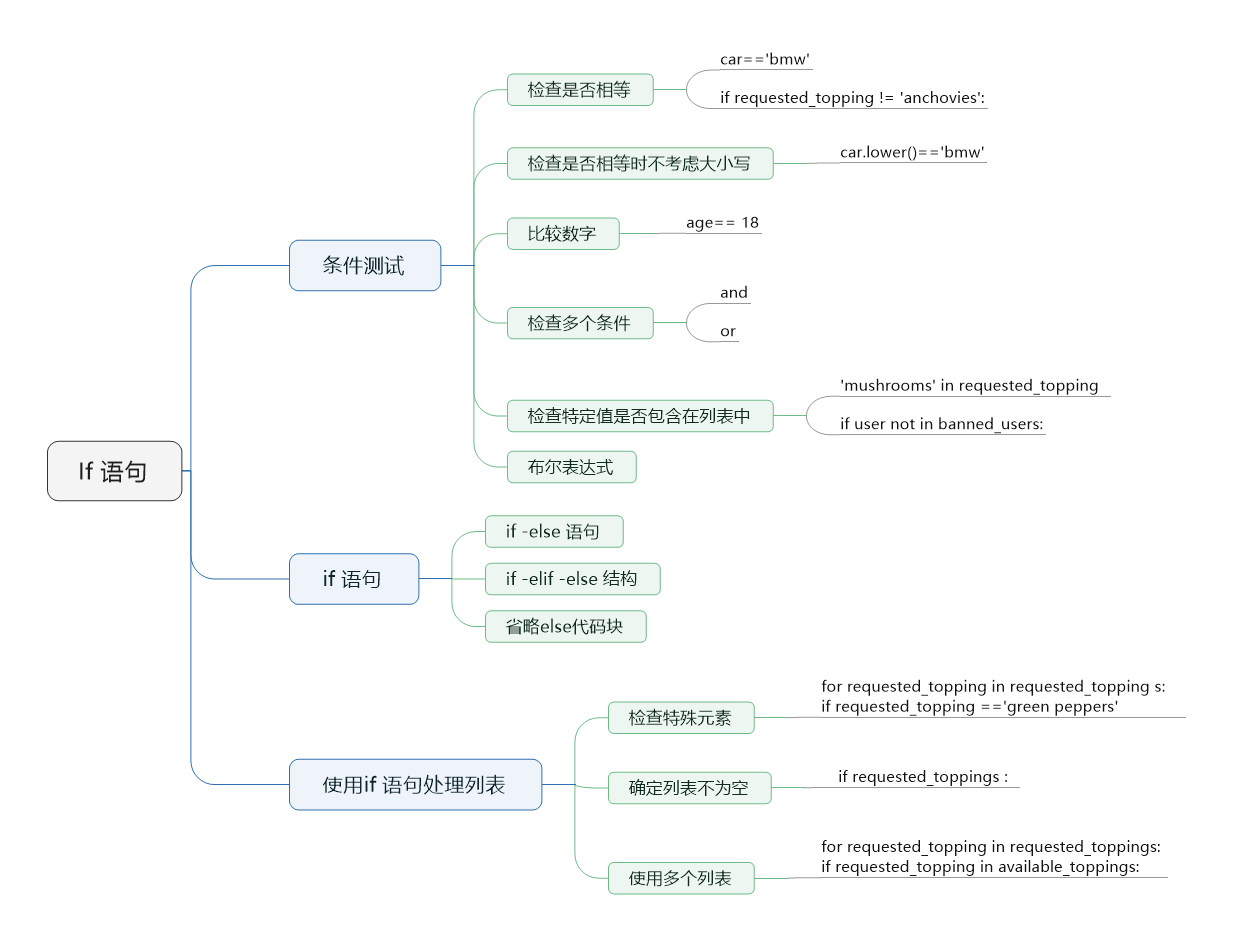
二 分支結構
2.1 什么是分支結構
分支結構就是根據條件判斷的真假去執行不同分支對應的子代碼
2.2 為什么要用分支結構
人類某些時候需要根據條件來決定做什么事情,比如:如果今天下雨,就帶傘
所以程序中必須有相應的機制來控制計算機具備人的這種判斷能力
2.3 如何使用分支結構
2.3.1 if語法
用if關鍵字來實現分支結構,完整語法如下
if 條件1: # 如果條件1的結果為True,就依次執行:代碼1、代碼2,......
代碼1
代碼2
......
elif 條件2: # 如果條件2的結果為True,就依次執行:代碼3、代碼4,......
代碼3
代碼4
......
elif 條件3: # 如果條件3的結果為True,就依次執行:代碼5、代碼6,......
代碼5
代碼6
......
else: # 其它情況,就依次執行:代碼7、代碼8,......
代碼7
代碼8
......
# 注意:
# 1、python用相同縮進(4個空格表示一個縮進)來標識一組代碼塊,同一組代碼會自上而下依次運行
# 2、條件可以是任意表達式,但執行結果必須為布爾類型
# 在if判斷中所有的數據類型也都會自動轉換成布爾類型
# 2.1、None,0,空(空字符串,空列表,空字典等)三種情況下轉換成的布爾值為False
# 2.2、其余均為True
2.3.2 if應用案例
案例1:
如果:女人的年齡>30歲,那么:叫阿姨
age_of_girl=31
if age_of_girl > 30:
print('阿姨好')
案例2:
如果:女人的年齡>30歲,那么:叫阿姨,否則:叫小姐
age_of_girl=18
if age_of_girl > 30:
print('阿姨好')
else:
print('小姐好')
案例3:
如果:女人的年齡>=18并且<22歲并且身高>170并且體重<100并且是漂亮的,那么:表白,否則:叫阿姨**
age_of_girl=18
height=171
weight=99
is_pretty=True
if age_of_girl >= 18 and age_of_girl < 22 and height > 170 and weight < 100 and is_pretty == True:
print('表白...')
else:
print('阿姨好')
案例4:
如果:成績>=90,那么:優秀
如果成績>=80且<90,那么:良好
如果成績>=70且<80,那么:普通
其他情況:很差
score=input('>>: ')
score=int(score)
if score >= 90:
print('優秀')
elif score >= 80:
print('良好')
elif score >= 70:
print('普通')
else:
print('很差')
案例 5:if 嵌套
#在表白的基礎上繼續:
#如果表白成功,那么:在一起
#否則:打印。。。
age_of_girl=18
height=171
weight=99
is_pretty=True
success=False
if age_of_girl >= 18 and age_of_girl < 22 and height > 170 and weight < 100 and is_pretty == True:
if success:
print('表白成功,在一起')
else:
print('什么愛情不愛情的,愛nmlgb的愛情,愛nmlg啊...')
else:
print('阿姨好')
練習1: 登陸功能
name=input('請輸入用戶名字:').strip()
password=input('請輸入密碼:').strip()
if name == 'tony' and password == '123':
print('tony login success')
else:
print('用戶名或密碼錯誤')
練習2:
#!/usr/bin/env python
#根據用戶輸入內容打印其權限
'''
egon --> 超級管理員
tom --> 普通管理員
jack,rain --> 業務主管
其他 --> 普通用戶
'''
name=input('請輸入用戶名字:')
if name == 'egon':
print('超級管理員')
elif name == 'tom':
print('普通管理員')
elif name == 'jack' or name == 'rain':
print('業務主管')
else:
print('普通用戶')
三 循環結構
3.1 什么是循環結構
循環結構就是重復執行某段代碼塊
3.2 為什么要用循環結構
人類某些時候需要重復做某件事情
所以程序中必須有相應的機制來控制計算機具備人的這種循環做事的能力
3.3 如何使用循環結構
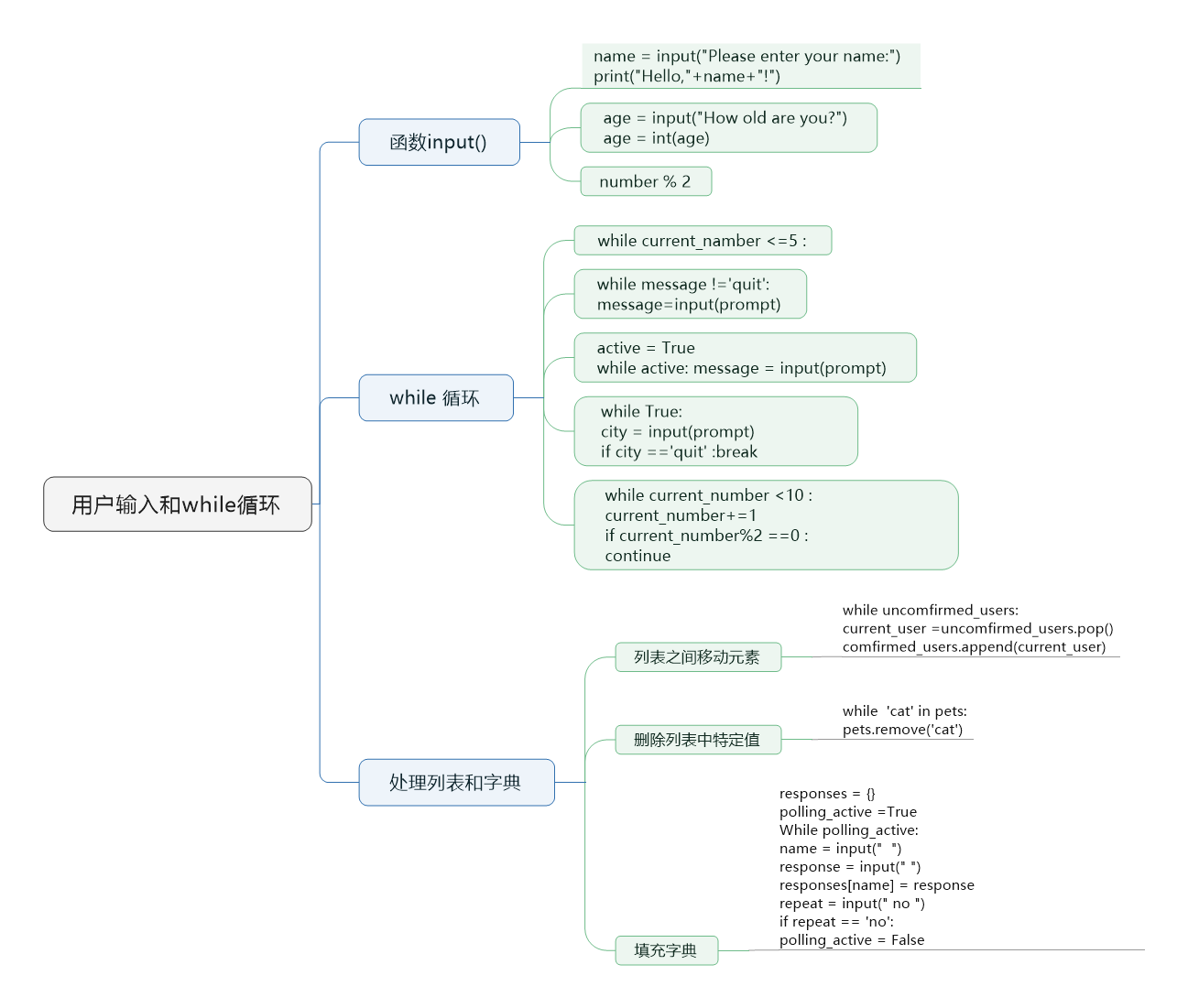
3.3.1 while循環語法
python中有while與for兩種循環機制,其中while循環稱之為條件循環,語法如下
while 條件:
代碼1
代碼2
代碼3
while的運行步驟:
步驟1:如果條件為真,那么依次執行:代碼1、代碼2、代碼3、......
步驟2:執行完畢后再次判斷條件,如果條件為True則再次執行:代碼1、代碼2、代碼3、......,如果條件為False,則循環終止
3.3.2 while循環應用案例
案例一:while循環的基本使用
用戶認證程序
#用戶認證程序的基本邏輯就是接收用戶輸入的用戶名密碼然后與程序中存放的用戶名密碼進行判斷,判斷成功則登陸成功,判斷失敗則輸出賬號或密碼錯誤
username = "jason"
password = "123"
inp_name = input("請輸入用戶名:")
inp_pwd = input("請輸入密碼:")
if inp_name == username and inp_pwd == password:
print("登陸成功")
else:
print("輸入的用戶名或密碼錯誤!")
#通常認證失敗的情況下,會要求用戶重新輸入用戶名和密碼進行驗證,如果我們想給用戶三次試錯機會,本質就是將上述代碼重復運行三遍,你總不會想著把代碼復制3次吧。。。。
username = "jason"
password = "123"
# 第一次驗證
inp_name = input("請輸入用戶名:")
inp_pwd = input("請輸入密碼:")
if inp_name == username and inp_pwd == password:
print("登陸成功")
else:
print("輸入的用戶名或密碼錯誤!")
# 第二次驗證
inp_name = input("請輸入用戶名:")
inp_pwd = input("請輸入密碼:")
if inp_name == username and inp_pwd == password:
print("登陸成功")
else:
print("輸入的用戶名或密碼錯誤!")
# 第三次驗證
inp_name = input("請輸入用戶名:")
inp_pwd = input("請輸入密碼:")
if inp_name == username and inp_pwd == password:
print("登陸成功")
else:
print("輸入的用戶名或密碼錯誤!")
#即使是小白的你,也覺得的太low了是不是,以后要修改功能還得修改3次,因此記住,寫重復的代碼是程序員最不恥的行為。
#那么如何做到不用寫重復代碼又能讓程序重復一段代碼多次呢? 循環語句就派上用場啦(使用while循環實現)
username = "jason"
password = "123"
# 記錄錯誤驗證的次數
count = 0
while count < 3:
inp_name = input("請輸入用戶名:")
inp_pwd = input("請輸入密碼:")
if inp_name == username and inp_pwd == password:
print("登陸成功")
else:
print("輸入的用戶名或密碼錯誤!")
count += 1
案例二:while+break的使用
使用了while循環后,代碼確實精簡多了,但問題是用戶輸入正確的用戶名密碼以后無法結束循環,那如何結束掉一個循環呢?這就需要用到break了!
username = "jason"
password = "123"
# 記錄錯誤驗證的次數
count = 0
while count < 3:
inp_name = input("請輸入用戶名:")
inp_pwd = input("請輸入密碼:")
if inp_name == username and inp_pwd == password:
print("登陸成功")
break # 用于結束本層循環
else:
print("輸入的用戶名或密碼錯誤!")
count += 1
案例三:while循環嵌套+break
如果while循環嵌套了很多層,要想退出每一層循環則需要在每一層循環都有一個break
username = "jason"
password = "123"
count = 0
while count < 3: # 第一層循環
inp_name = input("請輸入用戶名:")
inp_pwd = input("請輸入密碼:")
if inp_name == username and inp_pwd == password:
print("登陸成功")
while True: # 第二層循環
cmd = input('>>: ')
if cmd == 'quit':
break # 用于結束本層循環,即第二層循環
print('run <%s>' % cmd)
break # 用于結束本層循環,即第一層循環
else:
print("輸入的用戶名或密碼錯誤!")
count += 1
案例四:while循環嵌套+tag的使用
針對嵌套多層的while循環,如果我們的目的很明確就是要在某一層直接退出所有層的循環,其實有一個竅門,就讓所有while循環的條件都用同一個變量,該變量的初始值為True,一旦在某一層將該變量的值改成False,則所有層的循環都結束
username = "jason"
password = "123"
count = 0
tag = True
while tag:
inp_name = input("請輸入用戶名:")
inp_pwd = input("請輸入密碼:")
if inp_name == username and inp_pwd == password:
print("登陸成功")
while tag:
cmd = input('>>: ')
if cmd == 'quit':
tag = False # tag變為False, 所有while循環的條件都變為False
break
print('run <%s>' % cmd)
break # 用于結束本層循環,即第一層循環
else:
print("輸入的用戶名或密碼錯誤!")
count += 1
案例五:while+continue的使用
break代表結束本層循環,而continue則用于結束本次循環,直接進入下一次循環
# 打印1到10之間,除7以外的所有數字
number=11
while number>1:
number -= 1
if number==7:
continue # 結束掉本次循環,即本次循環continue之后的代碼都不會運行了,而是直接進入下一次循環
print(number)
案例五:while+else的使用
在while循環的后面,我們可以跟else語句,當while 循環正常執行完并且中間沒有被break 中止的話,就會執行else后面的語句,所以我們可以用else來驗證,循環是否正常結束
count = 0
while count <= 5 :
count += 1
print("Loop",count)
else:
print("循環正常執行完啦")
print("-----out of while loop ------")
輸出
Loop 1
Loop 2
Loop 3
Loop 4
Loop 5
Loop 6
循環正常執行完啦 #沒有被break打斷,所以執行了該行代碼
-----out of while loop ------
如果執行過程中被break,就不會執行else的語句
count = 0
while count <= 5 :
count += 1
if count == 3:
break
print("Loop",count)
else:
print("循環正常執行完啦")
print("-----out of while loop ------")
輸出
Loop 1
Loop 2
-----out of while loop ------ #由于循環被break打斷了,所以不執行else后的輸出語句
練習1:
尋找1到100之間數字7最大的倍數(結果是98)
number = 100
while number > 0:
if number %7 == 0:
print(number)
break
number -= 1
練習2:
age=18
count=0
while count<3:
count+=1
guess = int(input(">>:"))
if guess > age :
print("猜的太大了,往小里試試...")
elif guess < age :
print("猜的太小了,往大里試試...")
else:
print("恭喜你,猜對了...")
3.3.3 for循環語法
循環結構的第二種實現方式是for循環,for循環可以做的事情while循環都可以實現,之所以用for循環是因為在循環取值(即遍歷值)時for循環比while循環的使用更為簡潔,
for循環語法如下
for 變量名 in 可迭代對象: # 此時只需知道可迭代對象可以是字符串\列表\字典,我們之后會專門講解可迭代對象
代碼一
代碼二
...
#例1
for item in ['a','b','c']:
print(item)
# 運行結果
a
b
c
# 參照例1來介紹for循環的運行步驟
# 步驟1:從列表['a','b','c']中讀出第一個值賦值給item(item=‘a’),然后執行循環體代碼
# 步驟2:從列表['a','b','c']中讀出第二個值賦值給item(item=‘b’),然后執行循環體代碼
# 步驟3: 重復以上過程直到列表中的值讀盡
3.3.4 for循環應用案例
# 簡單版:for循環的實現方式
for count in range(6): # range(6)會產生從0-5這6個數
print(count)
# 復雜版:while循環的實現方式
count = 0
while count < 6:
print(count)
count += 1
案例二:遍歷字典
# 簡單版:for循環的實現方式
for k in {'name':'jason','age':18,'gender':'male'}: # for 循環默認取的是字典的key賦值給變量名k
print(k)
# 復雜版:while循環確實可以遍歷字典,后續將會迭代器部分詳細介紹
案例三:for循環嵌套
#請用for循環嵌套的方式打印如下圖形:
*****
*****
*****
for i in range(3):
for j in range(5):
print("*",end='')
print() # print()表示換行
注意:break 與 continue也可以用于for循環,使用語法同while循環
練習一:
打印九九乘法表
for i in range(1,10):
for j in range(1,i+1):
print('%s*%s=%s' %(i,j,i*j),end=' ')
print()
練習二:
打印金字塔
# 分析
'''
#max_level=5
* # current_level=1,空格數=4,*號數=1
*** # current_level=2,空格數=3,*號數=3
***** # current_level=3,空格數=2,*號數=5
******* # current_level=4,空格數=1,*號數=7
********* # current_level=5,空格數=0,*號數=9
# 數學表達式
空格數=max_level-current_level
*號數=2*current_level-1
'''
# 實現:
max_level=5
for current_level in range(1,max_level+1):
for i in range(max_level-current_level):
print(' ',end='') #在一行中連續打印多個空格
for j in range(2*current_level-1):
print('*',end='') #在一行中連續打印多個空格
print()
8、基本數據類型及內置方法
一 引子
數據類型是用來記錄事物狀態的,而事物的狀態是不斷變化的(如:一個人年齡的增長(操作int類型) ,單個人名的修改(操作str類型),學生列表中增加學生(操作list類型)等),這意味著我們在開發程序時需要頻繁對數據進行操作,為了提升我們的開發效率, python針對這些常用的操作,為每一種數據類型內置了一系列方法。本章的主題就是帶大家詳細了解下它們,以及每種數據類型的詳細定義、類型轉換。
二 數字類型int與float
2.1 定義
# 1、定義:
# 1.1 整型int的定義
age=10 # 本質age = int(10)
# 1.2 浮點型float的定義
salary=3000.3 # 本質salary=float(3000.3)
# 注意:名字+括號的意思就是調用某個功能,比如
# print(...)調用打印功能
# int(...)調用創建整型數據的功能
# float(...)調用創建浮點型數據的功能
2.2 類型轉換
# 1、數據類型轉換
# 1.1 int可以將由純整數構成的字符串直接轉換成整型,若包含其他任意非整數符號,則會報錯
>>> s = '123'
>>> res = int(s)
>>> res,type(res)
(123, <class 'int'>)
>>> int('12.3') # 錯誤演示:字符串內包含了非整數符號.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: '12.3'
# 1.2 進制轉換
# 十進制轉其他進制
>>> bin(3)
'0b11'
>>> oct(9)
'0o11'
>>> hex(17)
'0x11'
# 其他進制轉十進制
>>> int('0b11',2)
3
>>> int('0o11',8)
9
>>> int('0x11',16)
17
# 1.3 float同樣可以用來做數據類型的轉換
>>> s = '12.3'
>>> res=float(s)
>>> res,type(res)
(12.3, <class 'float'>)
2.3 使用
數字類型主要就是用來做數學運算與比較運算,因此數字類型除了與運算符結合使用之外,并無需要掌握的內置方法
三 字符串
3.1 定義:
# 定義:在單引號\雙引號\三引號內包含一串字符
name1 = 'jason' # 本質:name = str('任意形式內容')
name2 = "lili" # 本質:name = str("任意形式內容")
name3 = """ricky""" # 本質:name = str("""任意形式內容""")
3.2 類型轉換
# 數據類型轉換:str()可以將任意數據類型轉換成字符串類型,例如
>>> type(str([1,2,3])) # list->str
<class 'str'>
>>> type(str({"name":"jason","age":18})) # dict->str
<class 'str'>
>>> type(str((1,2,3))) # tuple->str
<class 'str'>
>>> type(str({1,2,3,4})) # set->str
<class 'str'>
3.3 使用
3.3.1 優先掌握的操作
>>> str1 = 'hello python!'
# 1.按索引取值(正向取,反向取):
# 1.1 正向取(從左往右)
>>> str1[6]
p
# 1.2 反向取(負號表示從右往左)
>>> str1[-4]
h
# 1.3 對于str來說,只能按照索引取值,不能改
>>> str1[0]='H' # 報錯TypeError
# 2.切片(顧頭不顧尾,步長)
# 2.1 顧頭不顧尾:取出索引為0到8的所有字符
>>> str1[0:9]
hello pyt
# 2.2 步長:0:9:2,第三個參數2代表步長,會從0開始,每次累加一個2即可,所以會取出索引0、2、4、6、8的字符
>>> str1[0:9:2]
hlopt
# 2.3 反向切片
>>> str1[::-1] # -1表示從右往左依次取值
!nohtyp olleh
# 3.長度len
# 3.1 獲取字符串的長度,即字符的個數,但凡存在于引號內的都算作字符)
>>> len(str1) # 空格也算字符
13
# 4.成員運算 in 和 not in
# 4.1 int:判斷hello 是否在 str1里面
>>> 'hello' in str1
True
# 4.2 not in:判斷tony 是否不在 str1里面
>>> 'tony' not in str1
True
# 5.strip移除字符串首尾指定的字符(默認移除空格)
# 5.1 括號內不指定字符,默認移除首尾空白字符(空格、\n、\t)
>>> str1 = ' life is short! '
>>> str1.strip()
life is short!
# 5.2 括號內指定字符,移除首尾指定的字符
>>> str2 = '**tony**'
>>> str2.strip('*')
tony
# 6.切分split
# 6.1 括號內不指定字符,默認以空格作為切分符號
>>> str3='hello world'
>>> str3.split()
['hello', 'world']
# 6.2 括號內指定分隔字符,則按照括號內指定的字符切割字符串
>>> str4 = '127.0.0.1'
>>> str4.split('.')
['127', '0', '0', '1'] # 注意:split切割得到的結果是列表數據類型
# 7.循環
>>> str5 = '今天你好嗎?'
>>> for line in str5: # 依次取出字符串中每一個字符
... print(line)
...
今
天
你
好
嗎
?
3.3.2 需要掌握的操作
1. strip, lstrip, rstrip
>>> str1 = '**tony***'
>>> str1.strip('*') # 移除左右兩邊的指定字符
'tony'
>>> str1.lstrip('*') # 只移除左邊的指定字符
tony***
>>> str1.rstrip('*') # 只移除右邊的指定字符
**tony
2. lower(),upper()
>>> str2 = 'My nAme is tonY!'
>>> str2.lower() # 將英文字符串全部變小寫
my name is tony!
>>> str2.upper() # 將英文字符串全部變大寫
MY NAME IS TONY!
3. startswith,endswith
>>> str3 = 'tony jam'
# startswith()判斷字符串是否以括號內指定的字符開頭,結果為布爾值True或False
>>> str3.startswith('t')
True
>>> str3.startswith('j')
False
# endswith()判斷字符串是否以括號內指定的字符結尾,結果為布爾值True或False
>>> str3.endswith('jam')
True
>>> str3.endswith('tony')
False
4.格式化輸出之format
之前我們使用%s來做字符串的格式化輸出操作,在傳值時,必須嚴格按照位置與%s一一對應,而字符串的內置方法format則提供了一種不依賴位置的傳值方式
案例:
# format括號內在傳參數時完全可以打亂順序,但仍然能指名道姓地為指定的參數傳值,name=‘tony’就是傳給{name}
>>> str4 = 'my name is {name}, my age is {age}!'.format(age=18,name='tony')
>>> str4
'my name is tony, my age is 18!'
>>> str4 = 'my name is {name}{name}{name}, my age is {name}!'.format(name='tony', age=18)
>>> str4
'my name is tonytonytony, my age is tony!'
format的其他使用方式(了解)
# 類似于%s的用法,傳入的值會按照位置與{}一一對應
>>> str4 = 'my name is {}, my age is {}!'.format('tony', 18)
>>> str4
my name is tony, my age is 18!
# 把format傳入的多個值當作一個列表,然后用{索引}取值
>>> str4 = 'my name is {0}, my age is {1}!'.format('tony', 18)
>>> str4
my name is tony, my age is 18!
>>> str4 = 'my name is {1}, my age is {0}!'.format('tony', 18)
>>> str4
my name is 18, my age is tony!
>>> str4 = 'my name is {1}, my age is {1}!'.format('tony', 18)
>>> str4
my name is 18, my age is 18!
5.split,rsplit
# split會按照從左到右的順序對字符串進行切分,可以指定切割次數
>>> str5='C:/a/b/c/d.txt'
>>> str5.split('/',1)
['C:', 'a/b/c/d.txt']
# rsplit剛好與split相反,從右往左切割,可以指定切割次數
>>> str5='a|b|c'
>>> str5.rsplit('|',1)
['a|b', 'c']
6. join
# 從可迭代對象中取出多個字符串,然后按照指定的分隔符進行拼接,拼接的結果為字符串
>>> '%'.join('hello') # 從字符串'hello'中取出多個字符串,然后按照%作為分隔符號進行拼接
'h%e%l%l%o'
>>> '|'.join(['tony','18','read']) # 從列表中取出多個字符串,然后按照*作為分隔符號進行拼接
'tony|18|read'
7. replace
# 用新的字符替換字符串中舊的字符
>>> str7 = 'my name is tony, my age is 18!' # 將tony的年齡由18歲改成73歲
>>> str7 = str7.replace('18', '73') # 語法:replace('舊內容', '新內容')
>>> str7
my name is tony, my age is 73!
# 可以指定修改的個數
>>> str7 = 'my name is tony, my age is 18!'
>>> str7 = str7.replace('my', 'MY',1) # 只把一個my改為MY
>>> str7
'MY name is tony, my age is 18!'
8.isdigit
# 判斷字符串是否是純數字組成,返回結果為True或False
>>> str8 = '5201314'
>>> str8.isdigit()
True
>>> str8 = '123g123'
>>> str8.isdigit()
False
3.3.3 了解操作
# 1.find,rfind,index,rindex,count
# 1.1 find:從指定范圍內查找子字符串的起始索引,找得到則返回數字1,找不到則返回-1
>>> msg='tony say hello'
>>> msg.find('o',1,3) # 在索引為1和2(顧頭不顧尾)的字符中查找字符o的索引
1
# 1.2 index:同find,但在找不到時會報錯
>>> msg.index('e',2,4) # 報錯ValueError
# 1.3 rfind與rindex:略
# 1.4 count:統計字符串在大字符串中出現的次數
>>> msg = "hello everyone"
>>> msg.count('e') # 統計字符串e出現的次數
4
>>> msg.count('e',1,6) # 字符串e在索引1~5范圍內出現的次數
1
# 2.center,ljust,rjust,zfill
>>> name='tony'
>>> name.center(30,'-') # 總寬度為30,字符串居中顯示,不夠用-填充
-------------tony-------------
>>> name.ljust(30,'*') # 總寬度為30,字符串左對齊顯示,不夠用*填充
tony**************************
>>> name.rjust(30,'*') # 總寬度為30,字符串右對齊顯示,不夠用*填充
**************************tony
>>> name.zfill(50) # 總寬度為50,字符串右對齊顯示,不夠用0填充
0000000000000000000000000000000000000000000000tony
# 3.expandtabs
>>> name = 'tony\thello' # \t表示制表符(tab鍵)
>>> name
tony hello
>>> name.expandtabs(1) # 修改\t制表符代表的空格數
tony hello
# 4.captalize,swapcase,title
# 4.1 captalize:首字母大寫
>>> message = 'hello everyone nice to meet you!'
>>> message.capitalize()
Hello everyone nice to meet you!
# 4.2 swapcase:大小寫翻轉
>>> message1 = 'Hi girl, I want make friends with you!'
>>> message1.swapcase()
hI GIRL, i WANT MAKE FRIENDS WITH YOU!
#4.3 title:每個單詞的首字母大寫
>>> msg = 'dear my friend i miss you very much'
>>> msg.title()
Dear My Friend I Miss You Very Much
# 5.is數字系列
#在python3中
num1 = b'4' #bytes
num2 = u'4' #unicode,python3中無需加u就是unicode
num3 = '四' #中文數字
num4 = 'Ⅳ' #羅馬數字
#isdigt:bytes,unicode
>>> num1.isdigit()
True
>>> num2.isdigit()
True
>>> num3.isdigit()
False
>>> num4.isdigit()
False
#isdecimal:uncicode(bytes類型無isdecimal方法)
>>> num2.isdecimal()
True
>>> num3.isdecimal()
False
>>> num4.isdecimal()
False
#isnumberic:unicode,中文數字,羅馬數字(bytes類型無isnumberic方法)
>>> num2.isnumeric()
True
>>> num3.isnumeric()
True
>>> num4.isnumeric()
True
# 三者不能判斷浮點數
>>> num5 = '4.3'
>>> num5.isdigit()
False
>>> num5.isdecimal()
False
>>> num5.isnumeric()
False
'''
總結:
最常用的是isdigit,可以判斷bytes和unicode類型,這也是最常見的數字應用場景
如果要判斷中文數字或羅馬數字,則需要用到isnumeric。
'''
# 6.is其他
>>> name = 'tony123'
>>> name.isalnum() #字符串中既可以包含數字也可以包含字母
True
>>> name.isalpha() #字符串中只包含字母
False
>>> name.isidentifier()
True
>>> name.islower() # 字符串是否是純小寫
True
>>> name.isupper() # 字符串是否是純大寫
False
>>> name.isspace() # 字符串是否全是空格
False
>>> name.istitle() # 字符串中的單詞首字母是否都是大寫
False
四 列表
4.1 定義
# 定義:在[]內,用逗號分隔開多個任意數據類型的值
l1 = [1,'a',[1,2]] # 本質:l1 = list([1,'a',[1,2]])
4.2 類型轉換
# 但凡能被for循環遍歷的數據類型都可以傳給list()轉換成列表類型,list()會跟for循環一樣遍歷出數據類型中包含的每一個元素然后放到列表中
>>> list('wdad') # 結果:['w', 'd', 'a', 'd']
>>> list([1,2,3]) # 結果:[1, 2, 3]
>>> list({"name":"jason","age":18}) #結果:['name', 'age']
>>> list((1,2,3)) # 結果:[1, 2, 3]
>>> list({1,2,3,4}) # 結果:[1, 2, 3, 4]
4.3 使用
4.3.1 優先掌握的操作
# 1.按索引存取值(正向存取+反向存取):即可存也可以取
# 1.1 正向取(從左往右)
>>> my_friends=['tony','jason','tom',4,5]
>>> my_friends[0]
tony
# 1.2 反向取(負號表示從右往左)
>>> my_friends[-1]
5
# 1.3 對于list來說,既可以按照索引取值,又可以按照索引修改指定位置的值,但如果索引不存在則報錯
>>> my_friends = ['tony','jack','jason',4,5]
>>> my_friends[1] = 'martthow'
>>> my_friends
['tony', 'martthow', 'jason', 4, 5]
# 2.切片(顧頭不顧尾,步長)
# 2.1 顧頭不顧尾:取出索引為0到3的元素
>>> my_friends[0:4]
['tony', 'jason', 'tom', 4]
# 2.2 步長:0:4:2,第三個參數2代表步長,會從0開始,每次累加一個2即可,所以會取出索引0、2的元素
>>> my_friends[0:4:2]
['tony', 'tom']
# 3.長度
>>> len(my_friends)
5
# 4.成員運算in和not in
>>> 'tony' in my_friends
True
>>> 'xxx' not in my_friends
True
# 5.添加
# 5.1 append()列表尾部追加元素
>>> l1 = ['a','b','c']
>>> l1.append('d')
>>> l1
['a', 'b', 'c', 'd']
# 5.2 extend()一次性在列表尾部添加多個元素
>>> l1.extend(['a','b','c'])
>>> l1
['a', 'b', 'c', 'd', 'a', 'b', 'c']
# 5.3 insert()在指定位置插入元素
>>> l1.insert(0,"first") # 0表示按索引位置插值
>>> l1
['first', 'a', 'b', 'c', 'alisa', 'a', 'b', 'c']
# 6.刪除
# 6.1 del
>>> l = [11,22,33,44]
>>> del l[2] # 刪除索引為2的元素
>>> l
[11,22,44]
# 6.2 pop()默認刪除列表最后一個元素,并將刪除的值返回,括號內可以通過加索引值來指定刪除元素
>>> l = [11,22,33,22,44]
>>> res=l.pop()
>>> res
44
>>> res=l.pop(1)
>>> res
22
# 6.3 remove()括號內指名道姓表示要刪除哪個元素,沒有返回值
>>> l = [11,22,33,22,44]
>>> res=l.remove(22) # 從左往右查找第一個括號內需要刪除的元素
>>> print(res)
None
# 7.reverse()顛倒列表內元素順序
>>> l = [11,22,33,44]
>>> l.reverse()
>>> l
[44,33,22,11]
# 8.sort()給列表內所有元素排序
# 8.1 排序時列表元素之間必須是相同數據類型,不可混搭,否則報錯
>>> l = [11,22,3,42,7,55]
>>> l.sort()
>>> l
[3, 7, 11, 22, 42, 55] # 默認從小到大排序
>>> l = [11,22,3,42,7,55]
>>> l.sort(reverse=True) # reverse用來指定是否跌倒排序,默認為False
>>> l
[55, 42, 22, 11, 7, 3]
# 8.2 了解知識:
# 我們常用的數字類型直接比較大小,但其實,字符串、列表等都可以比較大小,原理相同:都是依次比較對應位置的元素的大小,如果分出大小,則無需比較下一個元素,比如
>>> l1=[1,2,3]
>>> l2=[2,]
>>> l2 > l1
True
# 字符之間的大小取決于它們在ASCII表中的先后順序,越往后越大
>>> s1='abc'
>>> s2='az'
>>> s2 > s1 # s1與s2的第一個字符沒有分出勝負,但第二個字符'z'>'b',所以s2>s1成立
True
# 所以我們也可以對下面這個列表排序
>>> l = ['A','z','adjk','hello','hea']
>>> l.sort()
>>> l
['A', 'adjk', 'hea', 'hello','z']
# 9.循環
# 循環遍歷my_friends列表里面的值
for line in my_friends:
print(line)
'tony'
'jack'
'jason'
4
5
4.3.2 了解操作
>>> l=[1,2,3,4,5,6]
>>> l[0:3:1]
[1, 2, 3] # 正向步長
>>> l[2::-1]
[3, 2, 1] # 反向步長
# 通過索引取值實現列表翻轉
>>> l[::-1]
[6, 5, 4, 3, 2, 1]
五 元組
5.1 作用
元組與列表類似,也是可以存多個任意類型的元素,不同之處在于元組的元素不能修改,即元組相當于不可變的列表,用于記錄多個固定不允許修改的值,單純用于取
5.2 定義方式
# 在()內用逗號分隔開多個任意類型的值
>>> countries = ("中國","美國","英國") # 本質:countries = tuple("中國","美國","英國")
# 強調:如果元組內只有一個值,則必須加一個逗號,否則()就只是包含的意思而非定義元組
>>> countries = ("中國",) # 本質:countries = tuple("中國")
5.3 類型轉換
# 但凡能被for循環的遍歷的數據類型都可以傳給tuple()轉換成元組類型
>>> tuple('wdad') # 結果:('w', 'd', 'a', 'd')
>>> tuple([1,2,3]) # 結果:(1, 2, 3)
>>> tuple({"name":"jason","age":18}) # 結果:('name', 'age')
>>> tuple((1,2,3)) # 結果:(1, 2, 3)
>>> tuple({1,2,3,4}) # 結果:(1, 2, 3, 4)
# tuple()會跟for循環一樣遍歷出數據類型中包含的每一個元素然后放到元組中
5.4 使用
>>> tuple1 = (1, 'hhaha', 15000.00, 11, 22, 33)
# 1、按索引取值(正向取+反向取):只能取,不能改否則報錯!
>>> tuple1[0]
1
>>> tuple1[-2]
22
>>> tuple1[0] = 'hehe' # 報錯:TypeError:
# 2、切片(顧頭不顧尾,步長)
>>> tuple1[0:6:2]
(1, 15000.0, 22)
# 3、長度
>>> len(tuple1)
6
# 4、成員運算 in 和 not in
>>> 'hhaha' in tuple1
True
>>> 'hhaha' not in tuple1
False
# 5、循環
>>> for line in tuple1:
... print(line)
1
hhaha
15000.0
11
22
33
六 字典
6.1 定義方式
# 定義:在{}內用逗號分隔開多元素,每一個元素都是key:value的形式,其中value可以是任意類型,而key則必須是不可變類型,詳見第八小節,通常key應該是str類型,因為str類型會對value有描述性的功能
info={'name':'tony','age':18,'sex':'male'} #本質info=dict({....})
# 也可以這么定義字典
info=dict(name='tony',age=18,sex='male') # info={'age': 18, 'sex': 'male', 'name': 'tony'}
6.2 類型轉換
# 轉換1:
>>> info=dict([['name','tony'],('age',18)])
>>> info
{'age': 18, 'name': 'tony'}
# 轉換2:fromkeys會從元組中取出每個值當做key,然后與None組成key:value放到字典中
>>> {}.fromkeys(('name','age','sex'),None)
{'age': None, 'sex': None, 'name': None}
6.3 使用
6.3.1 優先掌握的操作
# 1、按key存取值:可存可取
# 1.1 取
>>> dic = {
... 'name': 'xxx',
... 'age': 18,
... 'hobbies': ['play game', 'basketball']
... }
>>> dic['name']
'xxx'
>>> dic['hobbies'][1]
'basketball'
# 1.2 對于賦值操作,如果key原先不存在于字典,則會新增key:value
>>> dic['gender'] = 'male'
>>> dic
{'name': 'tony', 'age': 18, 'hobbies': ['play game', 'basketball'],'gender':'male'}
# 1.3 對于賦值操作,如果key原先存在于字典,則會修改對應value的值
>>> dic['name'] = 'tony'
>>> dic
{'name': 'tony', 'age': 18, 'hobbies': ['play game', 'basketball']}
# 2、長度len
>>> len(dic)
3
# 3、成員運算in和not in
>>> 'name' in dic # 判斷某個值是否是字典的key
True
# 4、刪除
>>> dic.pop('name') # 通過指定字典的key來刪除字典的鍵值對
>>> dic
{'age': 18, 'hobbies': ['play game', 'basketball']}
# 5、鍵keys(),值values(),鍵值對items()
>>> dic = {'age': 18, 'hobbies': ['play game', 'basketball'], 'name': 'xxx'}
# 獲取字典所有的key
>>> dic.keys()
dict_keys(['name', 'age', 'hobbies'])
# 獲取字典所有的value
>>> dic.values()
dict_values(['xxx', 18, ['play game', 'basketball']])
# 獲取字典所有的鍵值對
>>> dic.items()
dict_items([('name', 'xxx'), ('age', 18), ('hobbies', ['play game', 'basketball'])])
# 6、循環
# 6.1 默認遍歷的是字典的key
>>> for key in dic:
... print(key)
...
age
hobbies
name
# 6.2 只遍歷key
>>> for key in dic.keys():
... print(key)
...
age
hobbies
name
# 6.3 只遍歷value
>>> for key in dic.values():
... print(key)
...
18
['play game', 'basketball']
xxx
# 6.4 遍歷key與value
>>> for key in dic.items():
... print(key)
...
('age', 18)
('hobbies', ['play game', 'basketball'])
('name', 'xxx')
6.3.2 需要掌握的操作
1. get()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> dic.get('k1')
'jason' # key存在,則獲取key對應的value值
>>> res=dic.get('xxx') # key不存在,不會報錯而是默認返回None
>>> print(res)
None
>>> res=dic.get('xxx',666) # key不存在時,可以設置默認返回的值
>>> print(res)
666
# ps:字典取值建議使用get方法
2. pop()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> v = dic.pop('k2') # 刪除指定的key對應的鍵值對,并返回值
>>> dic
{'k1': 'jason', 'kk2': 'JY'}
>>> v
'Tony'
3. popitem()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> item = dic.popitem() # 隨機刪除一組鍵值對,并將刪除的鍵值放到元組內返回
>>> dic
{'k3': 'JY', 'k2': 'Tony'}
>>> item
('k1', 'jason')
4. update()
# 用新字典更新舊字典,有則修改,無則添加
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> dic.update({'k1':'JN','k4':'xxx'})
>>> dic
{'k1': 'JN', 'k3': 'JY', 'k2': 'Tony', 'k4': 'xxx'}
5. fromkeys()
>>> dic = dict.fromkeys(['k1','k2','k3'],[])
>>> dic
{'k1': [], 'k2': [], 'k3': []}
6. setdefault()
# key不存在則新增鍵值對,并將新增的value返回
>>> dic={'k1':111,'k2':222}
>>> res=dic.setdefault('k3',333)
>>> res
333
>>> dic # 字典中新增了鍵值對
{'k1': 111, 'k3': 333, 'k2': 222}
# key存在則不做任何修改,并返回已存在key對應的value值
>>> dic={'k1':111,'k2':222}
>>> res=dic.setdefault('k1',666)
>>> res
111
>>> dic # 字典不變
{'k1': 111, 'k2': 222}
七 集合
7.1 作用
集合、list、tuple、dict一樣都可以存放多個值,但是集合主要用于:去重、關系運算
7.2 定義
"""
定義:在{}內用逗號分隔開多個元素,集合具備以下三個特點:
1:每個元素必須是不可變類型
2:集合內沒有重復的元素
3:集合內元素無序
"""
s = {1,2,3,4} # 本質 s = set({1,2,3,4})
# 注意1:列表類型是索引對應值,字典是key對應值,均可以取得單個指定的值,而集合類型既沒有索引也沒有key與值對應,所以無法取得單個的值,而且對于集合來說,主要用于去重與關系元素,根本沒有取出單個指定值這種需求。
# 注意2:{}既可以用于定義dict,也可以用于定義集合,但是字典內的元素必須是key:value的格式,現在我們想定義一個空字典和空集合,該如何準確去定義兩者?
d = {} # 默認是空字典
s = set() # 這才是定義空集合
7.3 類型轉換
# 但凡能被for循環的遍歷的數據類型(強調:遍歷出的每一個值都必須為不可變類型)都可以傳給set()轉換成集合類型
>>> s = set([1,2,3,4])
>>> s1 = set((1,2,3,4))
>>> s2 = set({'name':'jason',})
>>> s3 = set('egon')
>>> s,s1,s2,s3
{1, 2, 3, 4} {1, 2, 3, 4} {'name'} {'e', 'o', 'g', 'n'}
7.4 使用
7.4.1 關系運算
我們定義兩個集合friends與friends2來分別存放兩個人的好友名字,然后以這兩個集合為例講解集合的關系運算
>>> friends1 = {"zero","kevin","jason","egon"} # 用戶1的好友們
>>> friends2 = {"Jy","ricky","jason","egon"} # 用戶2的好友們
兩個集合的關系如下圖所示
# 1.合集/并集(|):求兩個用戶所有的好友(重復好友只留一個)
>>> friends1 | friends2
{'kevin', 'ricky', 'zero', 'jason', 'Jy', 'egon'}
# 2.交集(&):求兩個用戶的共同好友
>>> friends1 & friends2
{'jason', 'egon'}
# 3.差集(-):
>>> friends1 - friends2 # 求用戶1獨有的好友
{'kevin', 'zero'}
>>> friends2 - friends1 # 求用戶2獨有的好友
{'ricky', 'Jy'}
# 4.對稱差集(^) # 求兩個用戶獨有的好友們(即去掉共有的好友)
>>> friends1 ^ friends2
{'kevin', 'zero', 'ricky', 'Jy'}
# 5.值是否相等(==)
>>> friends1 == friends2
False
# 6.父集:一個集合是否包含另外一個集合
# 6.1 包含則返回True
>>> {1,2,3} > {1,2}
True
>>> {1,2,3} >= {1,2}
True
# 6.2 不存在包含關系,則返回False
>>> {1,2,3} > {1,3,4,5}
False
>>> {1,2,3} >= {1,3,4,5}
False
# 7.子集
>>> {1,2} < {1,2,3}
True
>>> {1,2} <= {1,2,3}
True
7.4.2 去重
集合去重復有局限性
# 1. 只能針對不可變類型
# 2. 集合本身是無序的,去重之后無法保留原來的順序
示例如下
>>> l=['a','b',1,'a','a']
>>> s=set(l)
>>> s # 將列表轉成了集合
{'b', 'a', 1}
>>> l_new=list(s) # 再將集合轉回列表
>>> l_new
['b', 'a', 1] # 去除了重復,但是打亂了順序
# 針對不可變類型,并且保證順序則需要我們自己寫代碼實現,例如
l=[
{'name':'lili','age':18,'sex':'male'},
{'name':'jack','age':73,'sex':'male'},
{'name':'tom','age':20,'sex':'female'},
{'name':'lili','age':18,'sex':'male'},
{'name':'lili','age':18,'sex':'male'},
]
new_l=[]
for dic in l:
if dic not in new_l:
new_l.append(dic)
print(new_l)
# 結果:既去除了重復,又保證了順序,而且是針對不可變類型的去重
[
{'age': 18, 'sex': 'male', 'name': 'lili'},
{'age': 73, 'sex': 'male', 'name': 'jack'},
{'age': 20, 'sex': 'female', 'name': 'tom'}
]
7.4.3 其他操作
# 1.長度
>>> s={'a','b','c'}
>>> len(s)
3
# 2.成員運算
>>> 'c' in s
True
# 3.循環
>>> for item in s:
... print(item)
...
c
a
b
7.5 練習
"""
一.關系運算
有如下兩個集合,pythons是報名python課程的學員名字集合,linuxs是報名linux課程的學員名字集合
pythons={'jason','egon','kevin','ricky','gangdan','biubiu'}
linuxs={'kermit','tony','gangdan'}
1. 求出即報名python又報名linux課程的學員名字集合
2. 求出所有報名的學生名字集合
3. 求出只報名python課程的學員名字
4. 求出沒有同時這兩門課程的學員名字集合
"""
# 求出即報名python又報名linux課程的學員名字集合
>>> pythons & linuxs
# 求出所有報名的學生名字集合
>>> pythons | linuxs
# 求出只報名python課程的學員名字
>>> pythons - linuxs
# 求出沒有同時這兩門課程的學員名字集合
>>> pythons ^ linuxs
八 可變類型與不可變類型
**可變數據類型:**值發生改變時,內存地址不變,即id不變,證明在改變原值
**不可變類型:**值發生改變時,內存地址也發生改變,即id也變,證明是沒有在改變原值,是產生了新的值
數字類型:
>>> x = 10
>>> id(x)
1830448896
>>> x = 20
>>> id(x)
1830448928
# 內存地址改變了,說明整型是不可變數據類型,浮點型也一樣
字符串
>>> x = "Jy"
>>> id(x)
938809263920
>>> x = "Ricky"
>>> id(x)
938809264088
# 內存地址改變了,說明字符串是不可變數據類型
列表
>>> list1 = ['tom','jack','egon']
>>> id(list1)
486316639176
>>> list1[2] = 'kevin'
>>> id(list1)
486316639176
>>> list1.append('lili')
>>> id(list1)
486316639176
# 對列表的值進行操作時,值改變但內存地址不變,所以列表是可變數據類型
元組
>>> t1 = ("tom","jack",[1,2])
>>> t1[0]='TOM' # 報錯:TypeError
>>> t1.append('lili') # 報錯:TypeError
# 元組內的元素無法修改,指的是元組內索引指向的內存地址不能被修改
>>> t1 = ("tom","jack",[1,2])
>>> id(t1[0]),id(t1[1]),id(t1[2])
(4327403152, 4327403072, 4327422472)
>>> t1[2][0]=111 # 如果元組中存在可變類型,是可以修改,但是修改后的內存地址不變
>>> t1
('tom', 'jack', [111, 2])
>>> id(t1[0]),id(t1[1]),id(t1[2]) # 查看id仍然不變
(4327403152, 4327403072, 4327422472)
字典
>>> dic = {'name':'egon','sex':'male','age':18}
>>>
>>> id(dic)
4327423112
>>> dic['age']=19
>>> dic
{'age': 19, 'sex': 'male', 'name': 'egon'}
>>> id(dic)
4327423112
# 對字典進行操作時,值改變的情況下,字典的id也是不變,即字典也是可變數據類型
九 數據類型總結
1、數字類型:
2、字符串類型
3、列表類型
4、元組類型
5、字典類型
6、集合類型
',‘age’:73,‘sex’:‘male’},
{‘name’:‘tom’,‘age’:20,‘sex’:‘female’},
{‘name’:‘lili’,‘age’:18,‘sex’:‘male’},
{‘name’:‘lili’,‘age’:18,‘sex’:‘male’},
]
new_l=[]
for dic in l:
if dic not in new_l:
new_l.append(dic)
print(new_l)
結果:既去除了重復,又保證了順序,而且是針對不可變類型的去重
[
{‘age’: 18, ‘sex’: ‘male’, ‘name’: ‘lili’},
{‘age’: 73, ‘sex’: ‘male’, ‘name’: ‘jack’},
{‘age’: 20, ‘sex’: ‘female’, ‘name’: ‘tom’}
]
### 7.4.3 其他操作
```python
# 1.長度
>>> s={'a','b','c'}
>>> len(s)
3
# 2.成員運算
>>> 'c' in s
True
# 3.循環
>>> for item in s:
... print(item)
...
c
a
b
7.5 練習
"""
一.關系運算
有如下兩個集合,pythons是報名python課程的學員名字集合,linuxs是報名linux課程的學員名字集合
pythons={'jason','egon','kevin','ricky','gangdan','biubiu'}
linuxs={'kermit','tony','gangdan'}
1. 求出即報名python又報名linux課程的學員名字集合
2. 求出所有報名的學生名字集合
3. 求出只報名python課程的學員名字
4. 求出沒有同時這兩門課程的學員名字集合
"""
# 求出即報名python又報名linux課程的學員名字集合
>>> pythons & linuxs
# 求出所有報名的學生名字集合
>>> pythons | linuxs
# 求出只報名python課程的學員名字
>>> pythons - linuxs
# 求出沒有同時這兩門課程的學員名字集合
>>> pythons ^ linuxs
八 可變類型與不可變類型
**可變數據類型:**值發生改變時,內存地址不變,即id不變,證明在改變原值
**不可變類型:**值發生改變時,內存地址也發生改變,即id也變,證明是沒有在改變原值,是產生了新的值
數字類型:
>>> x = 10
>>> id(x)
1830448896
>>> x = 20
>>> id(x)
1830448928
# 內存地址改變了,說明整型是不可變數據類型,浮點型也一樣
[外鏈圖片轉存中…(img-tFqCXMEe-1591518506013)]
字符串
>>> x = "Jy"
>>> id(x)
938809263920
>>> x = "Ricky"
>>> id(x)
938809264088
# 內存地址改變了,說明字符串是不可變數據類型
[外鏈圖片轉存中…(img-RxG2CT3N-1591518506014)]
列表
>>> list1 = ['tom','jack','egon']
>>> id(list1)
486316639176
>>> list1[2] = 'kevin'
>>> id(list1)
486316639176
>>> list1.append('lili')
>>> id(list1)
486316639176
# 對列表的值進行操作時,值改變但內存地址不變,所以列表是可變數據類型
[外鏈圖片轉存中…(img-09sBZFjD-1591518506015)]
元組
>>> t1 = ("tom","jack",[1,2])
>>> t1[0]='TOM' # 報錯:TypeError
>>> t1.append('lili') # 報錯:TypeError
# 元組內的元素無法修改,指的是元組內索引指向的內存地址不能被修改
>>> t1 = ("tom","jack",[1,2])
>>> id(t1[0]),id(t1[1]),id(t1[2])
(4327403152, 4327403072, 4327422472)
>>> t1[2][0]=111 # 如果元組中存在可變類型,是可以修改,但是修改后的內存地址不變
>>> t1
('tom', 'jack', [111, 2])
>>> id(t1[0]),id(t1[1]),id(t1[2]) # 查看id仍然不變
(4327403152, 4327403072, 4327422472)
[外鏈圖片轉存中…(img-7lZK6ehv-1591518506016)]
字典
>>> dic = {'name':'egon','sex':'male','age':18}
>>>
>>> id(dic)
4327423112
>>> dic['age']=19
>>> dic
{'age': 19, 'sex': 'male', 'name': 'egon'}
>>> id(dic)
4327423112
# 對字典進行操作時,值改變的情況下,字典的id也是不變,即字典也是可變數據類型
[外鏈圖片轉存中…(img-zHZ9Kj43-1591518506017)]
九 數據類型總結
[外鏈圖片轉存中…(img-WvuuT9Ax-1591518506018)]
1、數字類型:
2、字符串類型
3、列表類型
4、元組類型
5、字典類型
6、集合類型
10、文件處理
應用程序運行過程中產生的數據最先都是存放于內存中的,若想永久保存下來,必須要保存于硬盤中。應用程序若想操作硬件必須通過操作系統,而文件就是操作系統提供給應用程序來操作硬盤的虛擬概念,用戶或應用程序對文件的操作,就是向操作系統發起調用,然后由操作系統完成對硬盤的具體操作。
二 文件操作的基本流程
2.1 基本流程
有了文件的概念,我們無需再去考慮操作硬盤的細節,只需要關注操作文件的流程:
# 1. 打開文件,由應用程序向操作系統發起系統調用open(...),操作系統打開該文件,對應一塊硬盤空間,并返回一個文件對象賦值給一個變量f
f=open('a.txt','r',encoding='utf-8') #默認打開模式就為r
# 2. 調用文件對象下的讀/寫方法,會被操作系統轉換為讀/寫硬盤的操作
data=f.read()
# 3. 向操作系統發起關閉文件的請求,回收系統資源
f.close()
2.2 資源回收與with上下文管理
打開一個文件包含兩部分資源:應用程序的變量f和操作系統打開的文件。在操作完畢一個文件時,必須把與該文件的這兩部分資源全部回收,回收方法為:
1、f.close() #回收操作系統打開的文件資源
2、del f #回收應用程序級的變量
其中del f一定要發生在f.close()之后,否則就會導致操作系統打開的文件無法關閉,白白占用資源, 而python自動的垃圾回收機制決定了我們無需考慮del f,這就要求我們,在操作完畢文件后,一定要記住f.close(),雖然我們如此強調,但是大多數讀者還是會不由自主地忘記f.close(),考慮到這一點,python提供了with關鍵字來幫我們管理上下文
# 1、在執行完子代碼塊后,with 會自動執行f.close()
with open('a.txt','w') as f:
pass
# 2、可用用with同時打開多個文件,用逗號分隔開即可
with open('a.txt','r') as read_f,open('b.txt','w') as write_f:
data = read_f.read()
write_f.write(data)
2.3 指定操作文本文件的字符編碼
f = open(...)是由操作系統打開文件,如果打開的是文本文件,會涉及到字符編碼問題,如果沒有為open指定編碼,那么打開文本文件的默認編碼很明顯是操作系統說了算了,操作系統會用自己的默認編碼去打開文件,在windows下是gbk,在linux下是utf-8。
這就用到了上節課講的字符編碼的知識:若要保證不亂碼,文件以什么方式存的,就要以什么方式打開。
f = open('a.txt','r',encoding='utf-8')
三 文件的操作模式
3.1 控制文件讀寫操作的模式
r(默認的):只讀
w:只寫
a:只追加寫
3.1.1 案例一:r 模式的使用
# r只讀模式: 在文件不存在時則報錯,文件存在文件內指針直接跳到文件開頭
with open('a.txt',mode='r',encoding='utf-8') as f:
res=f.read() # 會將文件的內容由硬盤全部讀入內存,賦值給res
# 小練習:實現用戶認證功能
inp_name=input('請輸入你的名字: ').strip()
inp_pwd=input('請輸入你的密碼: ').strip()
with open(r'db.txt',mode='r',encoding='utf-8') as f:
for line in f:
# 把用戶輸入的名字與密碼與讀出內容做比對
u,p=line.strip('\n').split(':')
if inp_name == u and inp_pwd == p:
print('登錄成功')
break
else:
print('賬號名或者密碼錯誤')
3.1.2 案例二:w 模式的使用
# w只寫模式: 在文件不存在時會創建空文檔,文件存在會清空文件,文件指針跑到文件開頭
with open('b.txt',mode='w',encoding='utf-8') as f:
f.write('你好\n')
f.write('我好\n')
f.write('大家好\n')
f.write('111\n222\n333\n')
#強調:
# 1 在文件不關閉的情況下,連續的寫入,后寫的內容一定跟在前寫內容的后面
# 2 如果重新以w模式打開文件,則會清空文件內容
3.1.3 案例三:a 模式的使用
# a只追加寫模式: 在文件不存在時會創建空文檔,文件存在會將文件指針直接移動到文件末尾
with open('c.txt',mode='a',encoding='utf-8') as f:
f.write('44444\n')
f.write('55555\n')
#強調 w 模式與 a 模式的異同:
# 1 相同點:在打開的文件不關閉的情況下,連續的寫入,新寫的內容總會跟在前寫的內容之后
# 2 不同點:以 a 模式重新打開文件,不會清空原文件內容,會將文件指針直接移動到文件末尾,新寫的內容永遠寫在最后
# 小練習:實現注冊功能:
name=input('username>>>: ').strip()
pwd=input('password>>>: ').strip()
with open('db1.txt',mode='a',encoding='utf-8') as f:
info='%s:%s\n' %(name,pwd)
f.write(info)
3.1.4 案例四:+ 模式的使用(了解)
# r+ w+ a+ :可讀可寫
#在平時工作中,我們只單純使用r/w/a,要么只讀,要么只寫,一般不用可讀可寫的模式
3.2 控制文件讀寫內容的模式
大前提: tb模式均不能單獨使用,必須與r/w/a之一結合使用
t(默認的):文本模式
1. 讀寫文件都是以字符串為單位的
2. 只能針對文本文件
3. 必須指定encoding參數
b:二進制模式:
1.讀寫文件都是以bytes/二進制為單位的
2. 可以針對所有文件
3. 一定不能指定encoding參數
3.2.1 案例一:t 模式的使用
# t 模式:如果我們指定的文件打開模式為r/w/a,其實默認就是rt/wt/at
with open('a.txt',mode='rt',encoding='utf-8') as f:
res=f.read()
print(type(res)) # 輸出結果為:<class 'str'>
with open('a.txt',mode='wt',encoding='utf-8') as f:
s='abc'
f.write(s) # 寫入的也必須是字符串類型
#強調:t 模式只能用于操作文本文件,無論讀寫,都應該以字符串為單位,而存取硬盤本質都是二進制的形式,當指定 t 模式時,內部幫我們做了編碼與解碼
3.2.2 案例二: b 模式的使用
# b: 讀寫都是以二進制位單位
with open('1.mp4',mode='rb') as f:
data=f.read()
print(type(data)) # 輸出結果為:<class 'bytes'>
with open('a.txt',mode='wb') as f:
msg="你好"
res=msg.encode('utf-8') # res為bytes類型
f.write(res) # 在b模式下寫入文件的只能是bytes類型
#強調:b模式對比t模式
1、在操作純文本文件方面t模式幫我們省去了編碼與解碼的環節,b模式則需要手動編碼與解碼,所以此時t模式更為方便
2、針對非文本文件(如圖片、視頻、音頻等)只能使用b模式
# 小練習: 編寫拷貝工具
src_file=input('源文件路徑: ').strip()
dst_file=input('目標文件路徑: ').strip()
with open(r'%s' %src_file,mode='rb') as read_f,open(r'%s' %dst_file,mode='wb') as write_f:
for line in read_f:
# print(line)
write_f.write(line)
四 操作文件的方法
4.1 重點
# 讀操作
f.read() # 讀取所有內容,執行完該操作后,文件指針會移動到文件末尾
f.readline() # 讀取一行內容,光標移動到第二行首部
f.readlines() # 讀取每一行內容,存放于列表中
# 強調:
# f.read()與f.readlines()都是將內容一次性讀入內容,如果內容過大會導致內存溢出,若還想將內容全讀入內存,則必須分多次讀入,有兩種實現方式:
# 方式一
with open('a.txt',mode='rt',encoding='utf-8') as f:
for line in f:
print(line) # 同一時刻只讀入一行內容到內存中
# 方式二
with open('1.mp4',mode='rb') as f:
while True:
data=f.read(1024) # 同一時刻只讀入1024個Bytes到內存中
if len(data) == 0:
break
print(data)
# 寫操作
f.write('1111\n222\n') # 針對文本模式的寫,需要自己寫換行符
f.write('1111\n222\n'.encode('utf-8')) # 針對b模式的寫,需要自己寫換行符
f.writelines(['333\n','444\n']) # 文件模式
f.writelines([bytes('333\n',encoding='utf-8'),'444\n'.encode('utf-8')]) #b模式
4.2 了解
f.readable() # 文件是否可讀
f.writable() # 文件是否可讀
f.closed # 文件是否關閉
f.encoding # 如果文件打開模式為b,則沒有該屬性
f.flush() # 立刻將文件內容從內存刷到硬盤
f.name
五 主動控制文件內指針移動
#大前提:文件內指針的移動都是Bytes為單位的,唯一例外的是t模式下的read(n),n以字符為單位
with open('a.txt',mode='rt',encoding='utf-8') as f:
data=f.read(3) # 讀取3個字符
with open('a.txt',mode='rb') as f:
data=f.read(3) # 讀取3個Bytes
# 之前文件內指針的移動都是由讀/寫操作而被動觸發的,若想讀取文件某一特定位置的數據,則則需要用f.seek方法主動控制文件內指針的移動,詳細用法如下:
# f.seek(指針移動的字節數,模式控制):
# 模式控制:
# 0: 默認的模式,該模式代表指針移動的字節數是以文件開頭為參照的
# 1: 該模式代表指針移動的字節數是以當前所在的位置為參照的
# 2: 該模式代表指針移動的字節數是以文件末尾的位置為參照的
# 強調:其中0模式可以在t或者b模式使用,而1跟2模式只能在b模式下用
5.1 案例一: 0模式詳解
# a.txt用utf-8編碼,內容如下(abc各占1個字節,中文“你好”各占3個字節)
abc你好
# 0模式的使用
with open('a.txt',mode='rt',encoding='utf-8') as f:
f.seek(3,0) # 參照文件開頭移動了3個字節
print(f.tell()) # 查看當前文件指針距離文件開頭的位置,輸出結果為3
print(f.read()) # 從第3個字節的位置讀到文件末尾,輸出結果為:你好
# 注意:由于在t模式下,會將讀取的內容自動解碼,所以必須保證讀取的內容是一個完整中文數據,否則解碼失敗
with open('a.txt',mode='rb') as f:
f.seek(6,0)
print(f.read().decode('utf-8')) #輸出結果為: 好
5.2 案例二: 1模式詳解
# 1模式的使用
with open('a.txt',mode='rb') as f:
f.seek(3,1) # 從當前位置往后移動3個字節,而此時的當前位置就是文件開頭
print(f.tell()) # 輸出結果為:3
f.seek(4,1) # 從當前位置往后移動4個字節,而此時的當前位置為3
print(f.tell()) # 輸出結果為:7
5.3 案例三: 2模式詳解
# a.txt用utf-8編碼,內容如下(abc各占1個字節,中文“你好”各占3個字節)
abc你好
# 2模式的使用
with open('a.txt',mode='rb') as f:
f.seek(0,2) # 參照文件末尾移動0個字節, 即直接跳到文件末尾
print(f.tell()) # 輸出結果為:9
f.seek(-3,2) # 參照文件末尾往前移動了3個字節
print(f.read().decode('utf-8')) # 輸出結果為:好
# 小練習:實現動態查看最新一條日志的效果
import time
with open('access.log',mode='rb') as f:
f.seek(0,2)
while True:
line=f.readline()
if len(line) == 0:
# 沒有內容
time.sleep(0.5)
else:
print(line.decode('utf-8'),end='')
六 文件的修改
# 文件a.txt內容如下
張一蛋 山東 179 49 12344234523
李二蛋 河北 163 57 13913453521
王全蛋 山西 153 62 18651433422
# 執行操作
with open('a.txt',mode='r+t',encoding='utf-8') as f:
f.seek(9)
f.write('<婦女主任>')
# 文件修改后的內容如下
張一蛋<婦女主任> 179 49 12344234523
李二蛋 河北 163 57 13913453521
王全蛋 山西 153 62 18651433422
# 強調:
# 1、硬盤空間是無法修改的,硬盤中數據的更新都是用新內容覆蓋舊內容
# 2、內存中的數據是可以修改的
文件對應的是硬盤空間,硬盤不能修改對應著文件本質也不能修改, 那我們看到文件的內容可以修改,是如何實現的呢? 大致的思路是將硬盤中文件內容讀入內存,然后在內存中修改完畢后再覆蓋回硬盤 具體的實現方式分為兩種:
6.1 文件修改方式一
# 實現思路:將文件內容發一次性全部讀入內存,然后在內存中修改完畢后再覆蓋寫回原文件
# 優點: 在文件修改過程中同一份數據只有一份
# 缺點: 會過多地占用內存
with open('db.txt',mode='rt',encoding='utf-8') as f:
data=f.read()
with open('db.txt',mode='wt',encoding='utf-8') as f:
f.write(data.replace('kevin','SB'))
6.1 文件修改方式二
# 實現思路:以讀的方式打開原文件,以寫的方式打開一個臨時文件,一行行讀取原文件內容,修改完后寫入臨時文件...,刪掉原文件,將臨時文件重命名原文件名
# 優點: 不會占用過多的內存
# 缺點: 在文件修改過程中同一份數據存了兩份
import os
with open('db.txt',mode='rt',encoding='utf-8') as read_f,\
open('.db.txt.swap',mode='wt',encoding='utf-8') as wrife_f:
for line in read_f:
wrife_f.write(line.replace('SB','kevin'))
os.remove('db.txt')
os.rename('.db.txt.swap','db.txt')
11、函數的基本使用
一 引入
在程序中,具備某一功能的‘工具’指的就是函數,‘事先準備工具’的過程即函數的定義,‘拿來就用’即函數的調用。
二 定義函數
函數的使用必須遵循’先定義,后調用’的原則。函數的定義就相當于事先將函數體代碼保存起來,然后將內存地址賦值給函數名,函數名就是對這段代碼的引用,這和變量的定義是相似的。沒有事先定義函數而直接調用,就相當于在引用一個不存在的’變量名’。
定義函數的語法
def 函數名(參數1,參數2,...):
"""文檔描述"""
函數體
return 值
- def: 定義函數的關鍵字;
- 函數名:函數名指向函數內存地址,是對函數體代碼的引用。函數的命名應該反映出函數的功能;
- 括號:括號內定義參數,參數是可有可無的,且無需指定參數的類型;
- 冒號:括號后要加冒號,然后在下一行開始縮進編寫函數體的代碼;
- “”“文檔描述”"": 描述函數功能,參數介紹等信息的文檔,非必要,但是建議加上,從而增強函數的可讀性;
- 函數體:由語句和表達式組成;
- return 值:定義函數的返回值,return是可有可無的。
參數是函數的調用者向函數體傳值的媒介,若函數體代碼邏輯依賴外部傳來的參數時則需要定義為參函數,
def my_min(x,y):
res=x if x < y else y
return res
否則定義為無參函數
def interactive():
user=input('user>>: ').strip()
pwd=input('password>>: ').strip()
return (user,pwd)
函數體為pass代表什么都不做,稱之為空函數。定義空函數通常是有用的,因為在程序設計的開始,往往是先想好程序都需要完成什么功能,然后把所有功能都列舉出來用pass充當函數體“占位符”,這將使得程序的體系結構立見,清晰且可讀性強。例如要編寫一個ftp程序,我們可能想到的功能有用戶認證,下載,上傳,瀏覽,切換目錄等功能,可以先做出如下定義:
def auth_user():
"""user authentication function"""
pass
def download_file():
"""download file function"""
pass
def upload_file():
"""upload file function"""
pass
def ls():
"""list contents function"""
pass
def cd():
"""change directory"""
pass
之后我們便可以統籌安排編程任務,有選擇性的去實現上述功能來替換掉pass,從而提高開發效率。
三 調用函數與函數返回值
函數的使用分為定義階段與調用階段,定義函數時只檢測語法,不執行函數體代碼,函數名加括號即函數調用,只有調用函數時才會執行函數體代碼
#定義階段
def foo():
print('in the foo')
bar()
def bar():
print('in the bar')
#調用階段
foo()
執行結果:
in the foo
in the bar
定義階段函數foo與bar均無語法錯誤,而在調用階段調用foo()時,函數foo與bar都早已經存在于內存中了,所以不會有任何問題。
按照在程序出現的形式和位置,可將函數的調用形式分為三種
#1、語句形式:
foo()
#2、表達式形式:
m=my_min(1,2) #將調用函數的返回值賦值給x
n=10*my_min(1,2) #將調用函數的返回值乘以10的結果賦值給n
#3、函數調用作為參數的形式:
# my_min(2,3)作為函數my_min的第二個參數,實現了取1,2,3中的較小者賦值給m
m=my_min(1,my_min(2,3))
若需要將函數體代碼執行的結果返回給調用者,則需要用到return。return后無值或直接省略return,則默認返回None,return的返回值無類型限制,且可以將多個返回值放到一個元組內。
>>> def test(x,y,z):
... return x,y,z #等同于return (x,y,z)
...
>>> res=test(1,2,3)
>>> print(res)
(1, 2, 3)
return是一個函數結束的標志,函數內可以有多個return,但只執行一次函數就結束了,并把return后定義的值作為本次調用的結果返回。
智能推薦

猜你喜歡

python基礎(《Python編程從入門到實踐》筆記)K
python基礎語法 本筆記是對這本書的基礎語法部分進行了學習: 因為本身有其他語言的編程基礎,所以筆記僅僅對我自不熟悉的部分進行了記錄 函數...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...