Python爬蟲極簡入門-單網頁版
如果你也聽說過炫酷的爬蟲,卻一直沒有成功實現自制的想法,這篇教程會幫上忙。
今天,咱們先來看一下如何制作一個能運行的極簡爬蟲。做中學。
DIY骨干爬蟲-單網頁版
首先下載 python 2,我們將制作一個名為骨干爬蟲的Python爬蟲程序:
爬蟲是干嘛的?
是用來自動下載網絡上東西的程序,不詳細舉例了。
爬蟲的運行步驟
- 獲取指定的網頁的地址對應網頁數據X
- 從X中用正則匹配出你需要的信息:
- 新網址Y:訪問goto 1或保存(簡單爬蟲就不管啦,哈哈哈)
- 你需要的內容T:保存
- 需要獲取的文件的路徑P:保存
概念上的難點
- 如何爬?-遍歷新網頁保存本網頁連接們的方式
- 獲取信息-如何保存圖片或者其他文件?有API,直接調用
你需要做的事情
- 找到你需要的文件(圖片,rar隨便什么)在網頁中的地址
- 設計一個正則表達式匹配它
行動
無論你使用python2還是3,我給出兩個版本的代碼,你可以看到他們的區別很小
復制下面的內容到python2的編輯器里,運行。查看images里面的內容如果成功它里面會有一些圖片:
#python 2.*的代碼
from urlparse import urlsplit
from os.path import basename
import urllib2
import re
import requests
import os
import json
url = 'http://www.juemei.com/mm/'#你的網址
if not os.path.exists('images'):
os.mkdir("images")
#1. 偽裝啊
header = {
'User-Agent': "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0",
'Host': "www.baidu.com",#偽裝來源,斗智斗勇
'Referer': url
}
#下載一個網頁
url_content = urllib2.urlopen(url).read()
#正則匹配你要下載的文件網址
img_urls = re.findall('img .*?src="(.*?.jpg)"',url_content)
#循環處理匹配到文件網址
for img_url in img_urls:
try:
#獲取循環網址之一的遠程文件的數據
img_data = urllib2.urlopen(img_url).read()
#讓它在本地的名字也是服務器上的名字
file_name = basename(urlsplit(img_url)[2])
#保存
output = open('images/' + file_name, 'wb')
output.write(img_data)
output.close()
#try except 一旦下載某個文件失敗就跳過這個文件
except:
passPython3
#python 3.*
from urllib.parse import urlsplit
from os.path import basename
import urllib.request
import re
import requests
import os
import json
url = 'http://www.juemei.com/mm/'#你的網址
if not os.path.exists('images'):
os.mkdir("images")
#1. 偽裝啊
header = {
'User-Agent': "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0",
'Host': "www.baidu.com",#偽裝來源,斗智斗勇
'Referer': url
}
#下載一個網頁
url_content = urllib.request.urlopen(url).read()
url_content = url_content.decode('utf-8')
#正則匹配你要下載的文件網址
img_urls = re.findall('img .*?src="(.*?.jpg)"',url_content)
#循環處理匹配到文件網址
for img_url in img_urls:
try:
#獲取循環網址之一的遠程文件的數據
img_data = urllib.request.urlopen(img_url).read()
#讓它在本地的名字也是服務器上的名字
file_name = basename(urlsplit(img_url)[2])
#保存
output = open('images/' + file_name, 'wb')
output.write(img_data)
output.close()
#try except 一旦下載某個文件失敗就跳過這個文件
except:
pass
可能遇到的障礙
- 找不到requests

執行下面命令,來安裝requests:
C:\Python27>python.exe -m pip install requests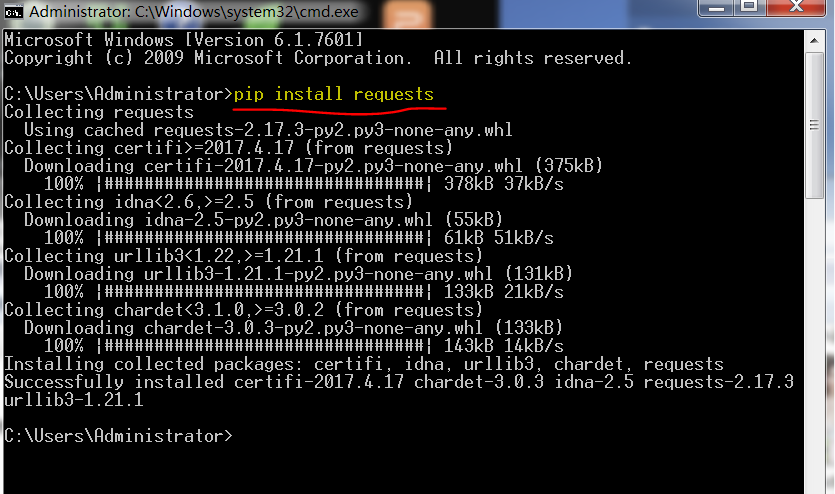
如果你連pip都沒有安裝,你需要重新安裝python2,并選中所有的勾。
- 找不到文件夾images
它在你保存的py文件的同目錄下.
效果
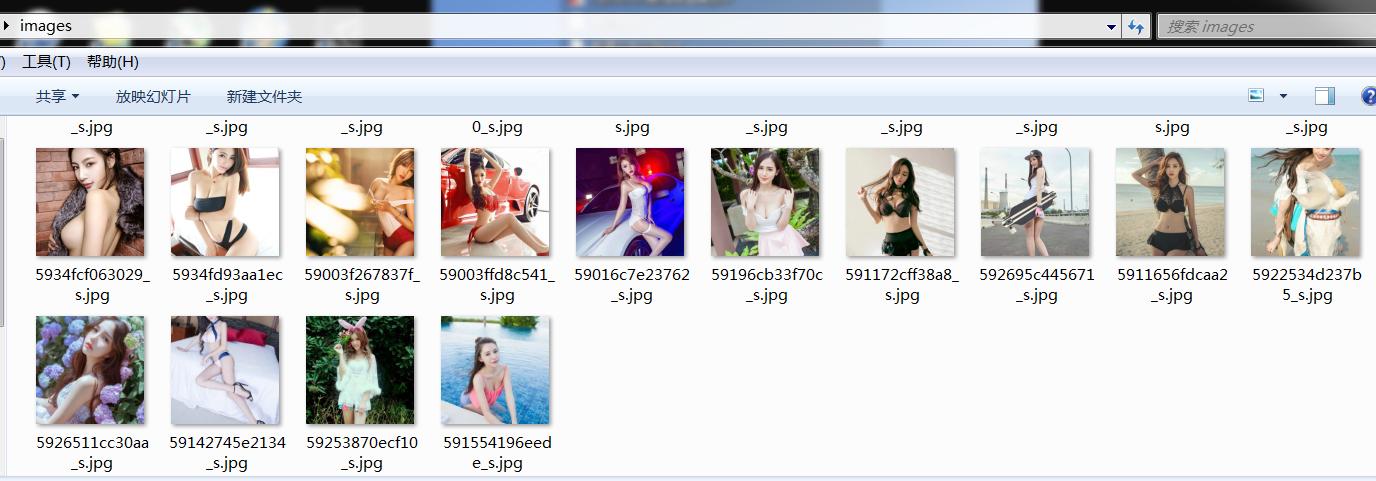
下一節我們將探索以下內容:
骨干爬蟲-真爬蟲-多頁面
骨干爬蟲-反屏蔽-代理
骨干爬蟲-高性能-異步
智能推薦
Elasticsearch 極簡入門
1. 單機部署 考慮到阿里云 Elasticsearch 使用 6.7.X 版本,本小節我們基于 6.7.2 版本進行安裝部署。 前置準備: 1、安裝 JDK 。 2、修改 /etc/security/limits.conf ,在此配置中增加以下內容。 如果服務器已經配置好,可以不用重復配置。需要在 Root 下執行。 修改完成后同時使用命令修改配置: 這些配置主要...
JApiDocs 極簡入門
JApiDocs java api接口文檔 源碼地址: https://github.com/YeDaxia/JApiDocs 1 、引入依賴 2 、創建 JApiDocs 配置 創建 TestJApiDocs 類,作為 JApiDocs 的配置,生成接口文檔 : 2 、代碼注釋 JApiDocs 是通過解析 Controller 源碼上的 Java 注釋,所以我們需要在相關的類、方法、屬性上,進...

Dockerfile極簡入門
Docker會依據Dockerfile內部的指令來在基礎鏡像上構建新的內容。 1. FROM 指明構建的新鏡像是來自于哪個基礎鏡像,例如: 2. MAINTAINER 指明鏡像維護著及其聯系方式(一般是郵箱地址),例如: 不過,MAINTAINER并不推薦使用,更推薦使用LABEL來指定鏡像作者,例如:LABEL maintainer="edisonzhou.cn" 3. RU...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
猜你喜歡
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...

統計學習方法 - 樸素貝葉斯
引入問題:一機器在良好狀態生產合格產品幾率是 90%,在故障狀態生產合格產品幾率是 30%,機器良好的概率是 75%。若一日第一件產品是合格品,那么此日機器良好的概率是多少。 貝葉斯模型 生成模型與判別模型 判別模型,即要判斷這個東西到底是哪一類,也就是要求y,那就用給定的x去預測。 生成模型,是要生成一個模型,那就是誰根據什么生成了模型,誰就是類別y,根據的內容就是x 以上述例子,判斷一個生產出...