SQLite3源碼學習(21) pcache1分析
標簽: sqlite3 page cache pcache1 緩存
學習本章之前要先復習以下2篇文章:
之前講到page cache是一種可插入式的管理方式,在sqlite3GlobalConfig.pcache2里定義了對page cache管理的一系列方法接口,并且介紹了最簡單的一種接口testpcache,現在我們來分析一下默認的接口pache1,這個要比testpcache復雜很多。
1.內存結構
一個page cache在內存中按如下格式存儲,由數據內容和頭部組成:

其中PgHdr1在pcache1.c里定義,PgHdr在pcache.c里定義,MemPage在btree.c里定義,在新建一個頁時,上述內容由sqlite3_pcache_page結構體表示
struct sqlite3_pcache_page {
void *pBuf; /* The content of the page */
void *pExtra; /* Extra information associated with the page */
};其中pBuf指向database page content和PgHdr1,pExtra指向PgHdr和MemPage,另外在PgHdr1結構體里定義了一個sqlite3_pcache_page對象。
struct PgHdr1 {
sqlite3_pcache_page page; /* Base class. Must be first. pBuf & pExtra */
……
};新建一個page cache時代碼如下:
pPg = pcache1Alloc(pCache->szAlloc);
p = (PgHdr1 *)&((u8 *)pPg)[pCache->szPage];
p->page.pBuf = pPg;
p->page.pExtra = &p[1];2.結構關系
hash表
每一次調用pcache1的接口時,需要傳入一個sqlite3_pcache*類型的對象作為連接句柄,在pcache1中被轉換為PCache1*類型。
有些時候還需要傳入頁面對象作為參數,傳入時的類型是sqlite3_pcache_page*,這是一個基類對象,如上一節所說,在pcahce1中會被擴展成PgHdr1*類型的對象。
在PCache1*類型的對象中有一張hash表,所有的page cache都存放在這張hash表里,如果page cache的key值對應的hash表的索引相同,那么相同地址的元素再建立一個鏈表。
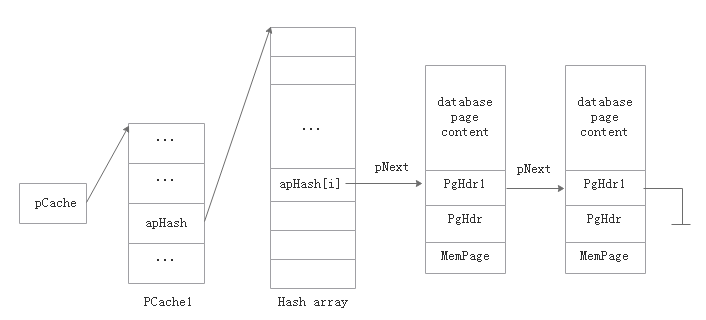
在Pcache1中與hash表相關變量如下:
struct PCache1 {
……
int szPage; /* Size of database content section */
int szExtra; /* sizeof(MemPage)+sizeof(PgHdr) */
//即szPage+szExtra+sizeof(PgHdr1)
int szAlloc; /* Total size of one pcache line */
……
//hash表中最大的關鍵字,即最大的頁面序號
unsigned int iMaxKey; /* Largest key seen since xTruncate() */
//包括hash表元素和所有鏈表元素的總個數
unsigned int nPage; /* Total number of pages in apHash */
//即apHash數組的長度
unsigned int nHash; /* Number of slots in apHash[] */
PgHdr1 **apHash; /* Hash table for fast lookup by key
};PGroup
我們把存放page cache的地址稱作slot,那么上節講到的hash表就把這些slot很好地組織在了一起,從而更容易查找對應的緩存頁。
這些需要經常用到的頁緩存我們把它標記為pinned,不常用的緩存頁我們把它標記為unpinned。我們還可以通過一種叫做PGroup的方式把這些unpinned slot組織在一起,這個是LRU算法的基礎。也就是說當緩存頁數量已經達到最大時,需要清理掉一些不常用的緩存頁來增加新的緩存頁。
PGroup的實現有2種模式:
模式1:
每一個連接的PCache擁有自己獨立的PGroup,這個時候不需要加鎖,訪問速度更快,但是占用的內存空間更大。
模式2:
所有連接的PCache共有一個PGroup,也就是說所有PCache的unppined page組成一個PGroup,這時候PGroup屬于多線程中的共享資源,需要加鎖,所以速度慢一點,但是這種模式可以回收利用更多的內存空間。
PGroup的構建方式如下圖所示:
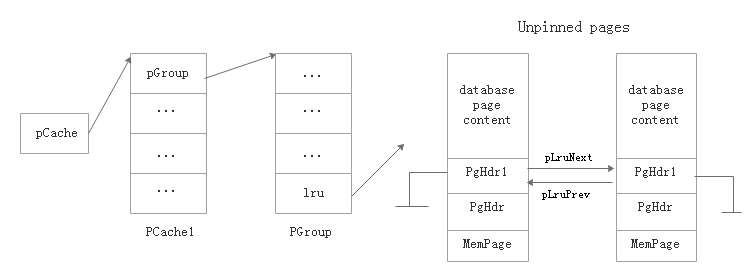
所有的unpinned page組成一個雙向的循環鏈表,pGroup->lru作為這個鏈表的表頭。其實這相當于一個隊列,新插入的page加入到隊列頭部,在隊列尾部的page是最早的,所以回收時先回收隊列尾部的page。用循環列表就不用查找操作,只要知道了pGroup->lru,就能定位到隊列的頭部和尾部。
pGroup相關數據結構如下:
struct PCache1 {
/* Cache configuration parameters. Page size (szPage) and the purgeable
** flag (bPurgeable) are set when the cache is created. nMax may be
** modified at any time by a call to the pcache1Cachesize() method.
** The PGroup mutex must be held when accessing nMax.
*/
PGroup *pGroup; /* PGroup this cache belongs to */
……
/* 如果該值為0,那么該PCache的所有page都不可回收利用 */
int bPurgeable; /* True if cache is purgeable */
//每個PCache預留的slot數量,當前為10
unsigned int nMin; /* Minimum number of pages reserved */
//每個PCache配置的最大slot數量
unsigned int nMax; /* Configured "cache_size" value */
unsigned int n90pct; /* nMax*9/10 */
unsigned int nRecyclable; /* Number of pages in the LRU list */
……
};
struct PGroup {
//在模式1時鎖為空
sqlite3_mutex *mutex; /* MUTEX_STATIC_LRU or NULL */
//所有pCache.nMax之和
unsigned int nMaxPage; /* Sum of nMax for purgeable caches */
//所有pCache.nMin之和
unsigned int nMinPage; /* Sum of nMin for purgeable caches */
//在createFlag==1時,最大使用的slot數量
//預留nMaxpage- mxPinned= nMinPage-10數量的slot
unsigned int mxPinned; /* nMaxpage + 10 - nMinPage */
unsigned int nCurrentPage; /* Number of purgeable pages allocated */
PgHdr1 lru; /* The beginning and end of the LRU list */
};3.內存申請
在page cache中,申請內存主要由以下3種方式:
1.PCache-local bulk分配器
這個針對pGroup的模式1,也就是先申請一個大的zBulk空間,然后將其分割成一個個slot,每個slot按照內存結構關系定義好,再把這些slot組成一個鏈表,使用時只要從頭部摘下即可,不用了放回頭部。
2.頁緩存內存分配器
這個針對pGroup的模式2,缺省時是關閉的,需要調用 sqlite3_config(SQLITE_CONFIG_PAGECACHE, pBuf, sz, N)接口來配置
其中pBuf是申請的空間地址,sz是slot大小,N是slot個數,申請的空間再通過sqlite3PcacheBufferSetup()函數配置,這里也是把一大塊地址分割成許多個slot再組成鏈表,放到pcache1.pFree,但是slot的格式并沒有定義,這是因為針對不同的PCache,每個頁緩存的szAlloc可能會有所不同。
3.普通內存分配器
當以上2種方式都沒有申請到內存時,調用sqlite3Malloc()
4.Page的讀取
如果pGroup是模式1,那么調用pcache1FetchWithMutex()加鎖,如果pGroup是模式2,那么直接調用pcache1FetchNoMutex()。
讀取一個page按照以下流程:
1.根據頁號(iKey)搜索hash表
static PgHdr1 *pcache1FetchNoMutex(
sqlite3_pcache *p,
unsigned int iKey,
int createFlag
){
……
PCache1 *pCache = (PCache1 *)p;
PgHdr1 *pPage = 0;
pPage = pCache->apHash[iKey % pCache->nHash];
while( pPage && pPage->iKey!=iKey ){ pPage = pPage->pNext; }
……
}2.如果頁面找到了,那么返回這個頁面;如果沒找到,并且createFlag是0,那么返回異常;如果沒找到,但是createFlag不為0,繼續以下步驟。
3.如果createFlag==1,并且使用的page已經超過最大限制,或者內存緊缺,那么直接返回0。
unsigned int nPinned;
PGroup *pGroup = pCache->pGroup;
if( createFlag==1 && (
nPinned>=pGroup->mxPinned
|| nPinned>=pCache->n90pct
|| (pcache1UnderMemoryPressure(pCache) && pCache->nRecyclable<nPinned)
)){
return 0;
}
因為通常步驟3以后是不需要的,所以把以后的步驟單獨放在pcache1FetchStage2()函數里,并且設置強制不內聯,以減少函數堆棧的初始化,加快讀取速度。
4.如果滿足條件,回收利用unpinned page
if( pCache->bPurgeable//可回收
//循環鏈表的表頭不能被回收
&& !pGroup->lru.pLruPrev->isAnchor
//當使用的page超過了設置的最大值或者內存不足才回收
&& ((pCache->nPage+1>=pCache->nMax) || pcache1UnderMemoryPressure(pCache))
){
PCache1 *pOther;
pPage = pGroup->lru.pLruPrev;//回收隊列尾部的page
assert( pPage->isPinned==0 );
pcache1RemoveFromHash(pPage, 0);//把它從原來的hash表中移除
pcache1PinPage(pPage);//標記為pinned
pOther = pPage->pCache;
if( pOther->szAlloc != pCache->szAlloc ){
//回收的slot長度不符合要求
pcache1FreePage(pPage);
pPage = 0;
}else{
//其實相當于bPurgeable為0,那么nCurrentPage++
pGroup->nCurrentPage -= (pOther->bPurgeable - pCache->bPurgeable);
}
}5.經過上面步驟還沒找到page,那么重新申請一個page cache
5.函數說明
? void sqlite3PCacheBufferSetup(void *pBuf, int sz, int n)
配置頁緩存內存分配器。
? static int pcache1InitBulk(PCache1 *pCache)
初始化bulk內存分配器
? static void *pcache1Alloc(int nByte)
為一個緩存頁申請nByte大小的空間,先使用頁緩存內存分配器,如果內存不夠分配,再使用通用內存分配器。
? static void pcache1Free(void *p)
釋放緩存頁
? static int pcache1MemSize(void *p)
獲取申請內存的長度
? static PgHdr1 *pcache1AllocPage(PCache1 *pCache, int benignMalloc)
創建一個新的緩存頁,如果不是通過bulk內存分配器獲得內存,那么需要對申請的slot定義緩存頁的內存結構
? void *sqlite3PageMalloc(int sz)
pcache1Alloc()的一個對外接口
? static void pcache1FreePage(PgHdr1 *p)
pcache1Free()的一個對外接口
? static void pcache1ResizeHash(PCache1 *p)
當pCache->nPage>=pCache->nHash時,把hash表長度擴大1倍,并重新調整hash表結構
? static PgHdr1 *pcache1PinPage(PgHdr1 *pPage)
把剛創建或剛回收的緩存頁標記為pinned
? static void pcache1RemoveFromHash(PgHdr1 *pPage, int freeFlag)
將pPage從hash表中移除,如果freeFlag置1,那么釋放內存
? static void pcache1EnforceMaxPage(PCache1 *pCache)
如果pGroup->nCurrentPage>pGroup->nMaxPage,那么移除LRU隊列中多余的page
? static void pcache1TruncateUnsafe(
PCache1 *pCache, /* The cache to truncate */
unsigned int iLimit /* Drop pages with this pgno or larger */
)
釋放頁號大于iLimit的頁,如果pCache->iMaxKey - iLimit < pCache->nHash,那么不用掃描整個hash表,否則從pCache->nHash/2處開始掃描整個hash表。
? static int pcache1Init(void *NotUsed)
設置PGroup模式,如果是模式2,初始化鎖。
? static sqlite3_pcache *pcache1Create(int szPage, int szExtra, int bPurgeable)
創建一個pCache,并初始化相關參數
? static void pcache1Cachesize(sqlite3_pcache *p, int nMax)
設置pCache->nMax
? static void pcache1Shrink(sqlite3_pcache *p)
把所有unpinned page都釋放掉
? static int pcache1Pagecount(sqlite3_pcache *p)
獲得當前緩存頁的數量
? static SQLITE_NOINLINE PgHdr1 *pcache1FetchStage2(
PCache1 *pCache,
unsigned int iKey,
int createFlag
)
讀取緩存頁,見上節分析
? static PgHdr1 *pcache1FetchNoMutex(
sqlite3_pcache *p,
unsigned int iKey,
int createFlag
)
讀取緩存頁,見上節分析
? static PgHdr1 *pcache1FetchWithMutex(
sqlite3_pcache *p,
unsigned int iKey,
int createFlag
)
讀取緩存頁,需要先加鎖
? static sqlite3_pcache_page *pcache1Fetch(
sqlite3_pcache *p,
unsigned int iKey,
int createFlag
)
讀取緩存頁的對外接口
? static void pcache1Unpin(
sqlite3_pcache *p,
sqlite3_pcache_page *pPg,
int reuseUnlikely
)
把page插入到LRU隊列里
? static void pcache1Rekey(
sqlite3_pcache *p,
sqlite3_pcache_page *pPg,
unsigned int iOld,
unsigned int iNew
)
重新設置page的頁號
? static void pcache1Truncate(sqlite3_pcache *p, unsigned int iLimit)
加鎖后再調用pcache1TruncateUnsafe()
? static void pcache1Destroy(sqlite3_pcache *p)
釋放pCache中的所有頁
? void sqlite3PCacheSetDefault(void)
設置pcache1的對外接口到sqlite3GlobalConfig.pcache2
? int sqlite3PcacheReleaseMemory(int nReq)
從PGroup里釋放nReq大小的空間
智能推薦
Dagger2分析學習
Dagger學習筆記 1.概要 Dagger是為Android和Java平臺提供的一個完全靜態的,在編譯時進行依賴注入的框架,原來是由Square公司維護的然后現在把這堆東西扔給 Google維護了 控制反轉(Inversion of Control,縮寫Ioc),是面向對象編程中的一種設計原則,可以用來減少計算機代碼之間的耦合度,其中最常見的方式是依賴注入 (Dependency Injecti...
PAT乙級 1074 宇宙無敵加法器 (20分)【外加測試點1、3、5分析】
地球人習慣使用十進制數,并且默認一個數字的每一位都是十進制的。而在 PAT 星人開掛的世界里,每個數字的每一位都是不同進制的,這種神奇的數字稱為“PAT數”。每個 PAT 星人都必須熟記各位數字的進制表,例如“……0527”就表示最低位是 7 進制數、第 2 位是 2 進制數、第 3 位是 5 進制數、第 4 位是 10 ...
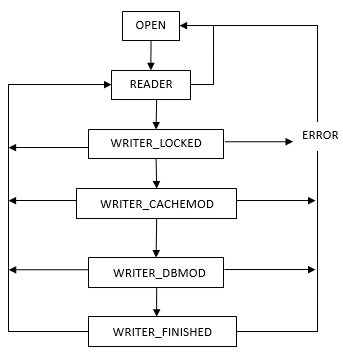
SQLite3源碼學習(28) Pager模塊之事務管理
事務管理是Pager模塊中最核心的要素,所有對數據庫數據的讀寫操作都在事務中進行。一個數據庫需要在多線程的使用環境下保持數據的一致性,雖然操作系統對磁盤的讀寫操作并不是原子,但是通過事務以及日志的回滾機制使每一個事務的執行都是原子的,所以即使出現系統崩潰或斷電,數據庫并不會因此而損壞。 在一...
SQLite3源碼學習(25) Pager模塊之事務鎖的實現2
在上一篇文章中介紹了SQLite怎么用Linux中的記錄鎖來實現每一種類型的事務鎖。但這只適合多進程間的互斥,不適合多線程,在Linux中每一個進程只能擁有一把鎖,也就是說一個進程里的多個線程共用一把鎖,這時會出現一個線程擁有共享鎖,另一個線程再獲取獨占鎖時并不會出現排斥,僅僅是把當前進程的鎖改為獨占鎖,還有當一個線程占有鎖的時候可能被另一個線程釋放等等,這就破壞了數據庫中多事務的隔離性。所以SQ...

猜你喜歡

freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...