凸包-Andrew算法&&Graham掃描法
凸包簡介:
在二維平面上(二維凸包)給出若干個點,能夠包含這若干個點的面積最小的凸多邊形稱為凸包(可以想像有很多個釘子釘在墻上,然后用一個橡皮圈套在所有的釘子上,最后橡皮圈形成的就是一個凸包)。
Graham掃描法:
Graham掃描法是一種基于極角排序的進行求解的算法,其大致流程如下:
①找一個一定在凸包上的點P0(一般找縱坐標最小的點);
②將其余所有的點以P0為基準進行極角排序;
③從P0出發掃描所有的點,不斷地更新最外圍的點,是否在最外圍可由叉乘判斷。這里用個圖說明一下:

當前對點P進行判斷,P1,P2為前面加入的兩個點:
Ⅰ)若點P在內部(圖一),則有向量b叉乘向量a小于零,此時點P是凸包的頂點,應將P點加入凸包。
Ⅱ)若在點P在外部,則有向量b叉乘向量a大于零,此時應該將點P1舍棄,繼續對前兩個點進行判斷,直到P、P1、P2三個點滿足向量b叉乘向量a小于零,再將P點加入凸包。
當然網上面還有更詳細的例子,不懂得話可以再看看其余的資料( ̄▽ ̄)。
具體代碼如下:
//Graham掃描法-hdu1392
#include<iostream>
#include<cstring>
#include<string>
#include<cstdio>
#include<cmath>
#include<algorithm>
using namespace std;
const int maxn=1e6+10;
const double esp=1e-10;
struct Point{
double x,y;
Point(){}
Point(double _x,double _y){
x=_x;y=_y;
}
}P[maxn],Convexhull[maxn];
typedef Point Vector;
Vector operator + (Vector A,Vector B){
return Vector(A.x+B.x,A.y+B.y);
}
Vector operator - (Vector A,Vector B){
return Vector(A.x-B.x,A.y-B.y);
}
Vector operator * (Vector A,double d){
return Vector(A.x*d,A.y*d);
}
Vector operator / (Vector A,double d){
return Vector(A.x/d,A.y/d);
}
double Dot(Vector A,Vector B){
return A.x*B.x+A.y*B.y;
}
double Cross(Vector A,Vector B){
return A.x*B.y-A.y*B.x;
}
double Length(Vector A){
return sqrt(Dot(A,A));
}
int dcmp(double x){
return fabs(x)<esp?0:x<0?-1:1;
}
bool Angle_Cmp(Point p1,Point p2){
double res=Cross(p1-P[0],p2-P[0]);
return dcmp(res)>0||(dcmp(res)==0&&dcmp(Length(p1-P[0])-Length(p2-P[0]))<0);
}
int Graham(int n){
int k=0;
Point p0=P[0];
for(int i=1;i<n;i++){
if(p0.y>P[i].y||(p0.y==P[i].y&&p0.x>P[i].x)){
k=i;p0=P[i];
}
}
swap(P[0],P[k]);
sort(P+1,P+n,Angle_Cmp);
Convexhull[0]=P[0]; //Assume n>2
Convexhull[1]=P[1];
int top=2;
for(int i=2;i<n;i++){
while(top>1&&Cross(P[i]-Convexhull[top-2],Convexhull[top-1]-Convexhull[top-2])>=0)top--;
Convexhull[top++]=P[i];
}
return top;
}
int main(){
freopen("in.txt","r",stdin);
int n;
while(~scanf("%d",&n)&&n){
for(int i=0;i<n;i++)scanf("%lf%lf",&P[i].x,&P[i].y);
int cnt=Graham(n);
double ans=0;
if(cnt!=2)ans+=Length(Convexhull[0]-Convexhull[cnt-1]);
for(int i=0;i<cnt-1;i++)ans+=Length(Convexhull[i]-Convexhull[i+1]);
printf("%.2lf\n",ans);
}
return 0;
}
Andrew算法:
Andrew算法是一種基于水平序的算法,在許多的資料上都會發現說該算法可以看作Graham掃描法的一種變體,為什么這么說呢?我的理解就是二者都是對所有的點進行掃描得到凸包,不過掃描之前做的處理不同,Andrew算法的大致流程如下:
①將所有的點按照橫坐標從小到大進行排序,橫坐標相同則按縱坐標從小到大排;
②將P[0]和P[1]加入凸包,然后從P[2]開始判斷,判斷方式同Graham算法中的判斷一致;
③將所有的點掃描一遍以后,我們便可以得到一個“下凸包”(為什么?畫個圖就懂了--橫坐標不會減小);
④同理,我們從P[n-2]開始(P[n-1]已經判過了),反著掃描一遍,便可以得到一個“上凸包”;
⑤將兩個“半凸包”合在一起就是一個完整的凸包,注意的是由于起點P[0]在正著掃描和反著掃描時都會將其加入凸包,故需要將最后一個點(P[0])去掉才為最終結果。
具體代碼如下:
#include<iostream>
#include<cstring>
#include<string>
#include<cstdio>
#include<cmath>
#include<algorithm>
using namespace std;
const int maxn=1e6+10;
const double esp=1e-10;
struct Point{
double x,y;
Point(){}
Point(double _x,double _y){
x=_x;y=_y;
}
}P[maxn],Convexhull[maxn];
typedef Point Vector;
Vector operator + (Vector A,Vector B){
return Vector(A.x+B.x,A.y+B.y);
}
Vector operator - (Vector A,Vector B){
return Vector(A.x-B.x,A.y-B.y);
}
Vector operator * (Vector A,double d){
return Vector(A.x*d,A.y*d);
}
Vector operator / (Vector A,double d){
return Vector(A.x/d,A.y/d);
}
double Dot(Vector A,Vector B){
return A.x*B.x+A.y*B.y;
}
double Cross(Vector A,Vector B){
return A.x*B.y-A.y*B.x;
}
double Length(Vector A){
return sqrt(Dot(A,A));
}
int dcmp(double x){
return fabs(x)<esp?0:x<0?-1:1;
}
bool operator <(Point p1,Point p2){
return dcmp(p1.x-p2.x)<0||(dcmp(p1.x-p2.x)==0&&dcmp(p1.y-p2.y)<0);
}
int Andrew(int n){ //Assume n>2
sort(P,P+n);
int top=0;
for(int i=0;i<n;i++){
while(top>1&&dcmp(Cross(P[i]-Convexhull[top-2],Convexhull[top-1]-Convexhull[top-2]))>=0)top--;
Convexhull[top++]=P[i];
}
int k=top;
for(int i=n-2;i>=0;i--){
while(top>k&&dcmp(Cross(P[i]-Convexhull[top-2],Convexhull[top-1]-Convexhull[top-2]))>=0)top--;
Convexhull[top++]=P[i];
}
return top-1;
}
int main(){
freopen("in.txt","r",stdin);
int n;
while(~scanf("%d",&n)&&n){
for(int i=0;i<n;i++)scanf("%lf%lf",&P[i].x,&P[i].y);
int cnt=Andrew(n);
double ans=0;
if(cnt!=2)ans+=Length(Convexhull[0]-Convexhull[cnt-1]);
for(int i=0;i<cnt-1;i++)ans+=Length(Convexhull[i]-Convexhull[i+1]);
printf("%.2lf\n",ans);
}
return 0;
}
小結:
顯然兩種算法的復雜度均為O(nlogn),若輸入有序的話時間復雜度就均為O(n),但是紫薯上說“和原始的Graham算法相比,Andrew算法更快,且數值穩定性更好”,或許是因為排序二者排序過程中的差異--Graham算法中的極角排序需要進行大量的叉乘計算。
智能推薦

C++this關鍵字&amp;Static&amp;Const&amp;友元函數&amp;友元
this Static 1,Static數據成員 static用來修飾類的成員,控制成員的存儲方式。靜態數據成員是該類所有對象共有的。靜態數據成員只分配一次內存,供所有對象共用。 靜態數據初始化格式:數據類型 類名::靜態數據成員 = 值 訪問靜態數據成員的方式: 類對象名.靜態數據成員名 類類型名::靜態數據成員名 2,Static函數成員 Const const用來定義常量,就是值...
DFS&amp;BFS總結
DFS&BFS總結 目錄..........................................................................................1 B - LakeCounting.............................1 C - Red and Black...............................

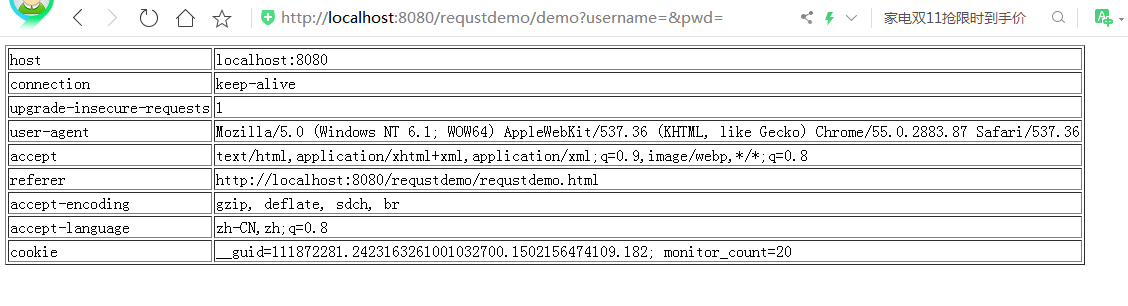
HttpServletRequest&amp;&amp;HttpServletResponse參數的接收和響應
一、請求頭信息: 二、獲取前臺傳值: 1、表單的action請求(id用于js,class用于css,name用于后臺): (1、)req.getParameter(arg)方法,參數為name值。例: (2、)req.getParameterNames()獲取所有的name值,然后再利用上面(1、)中的方法獲取value值。例: (3、)req.getParameterValues(arg);用...

Google Amp學習筆記
學習源網址:https://amp.dev/zh_cn/documentation/courses/ 原文是英文版,且比較長。 筆記中簡化了一些,記錄我們常用的組件以及一些要點。 關于 AMP 加速的原因 1、Inline 的 CSS 所有的CSS都只能Inline;在本頁內的css不能>75k 2、禁用了大部分的JS 在AMP模式下是不能運行JavaScript,也是禁止運行JavaScd...
猜你喜歡
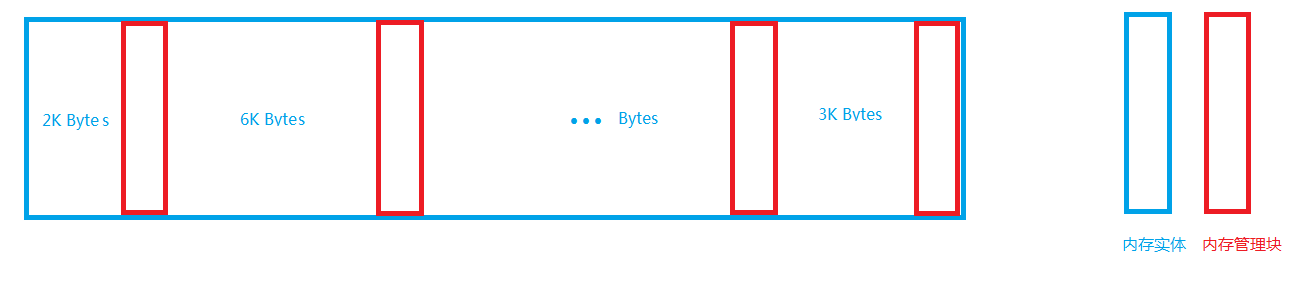
單片機上內存管理(重定義malloc &amp;amp;amp; free)de實現
在單片機上經常會需要用到像標準c庫中的內存分配,可是單片機并沒有內存管理機制,如果直接調用庫函數(malloc,free...),會導致內存碎片越用越多,很容易使系統崩潰掉,這里分享一個自己寫的適用于單片機的內存分配方法,具備輕量級的內存管理能力,有效減少內存碎片,提高單片機系統工作穩定性。 如下圖,heap_start開始的地方,是我們存放用戶...
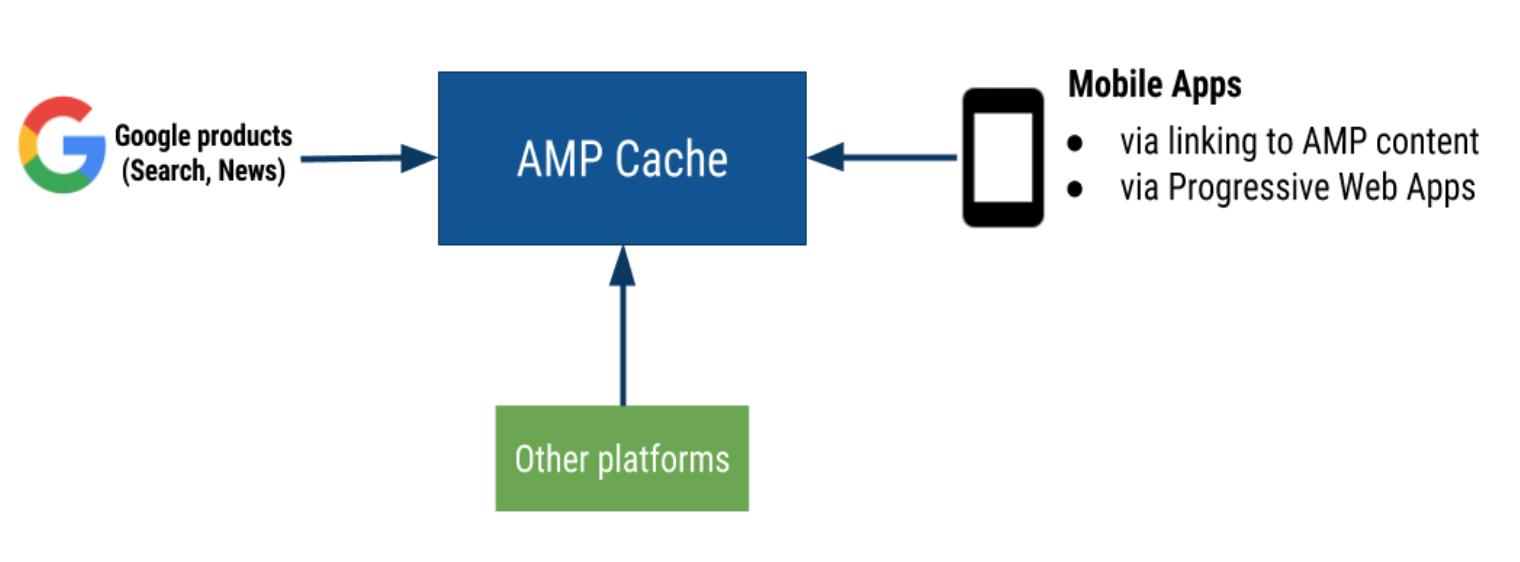
Google AMP 知識分享
AMP 是什么 AMP,全稱是 Accelerated Mobile Pages, 是 Google 推出的開源前端框架。AMP 最明顯的特征就是 性能,被稱為目前 WEB 屆最快的框架毫不夸張。 Google 對 AMP 的性能進行了極致的優化,比如 JS 和網頁數據放在緩存( 具體可看這篇文章:AMP 如何提升性能)。 是否有必要做 AMP 當然有必要做了。理由有 2 個:首先,是快...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...