Mysql并行復制實踐總結
mysql并行復制總結
實戰篇
Mysql5.6 并行復制
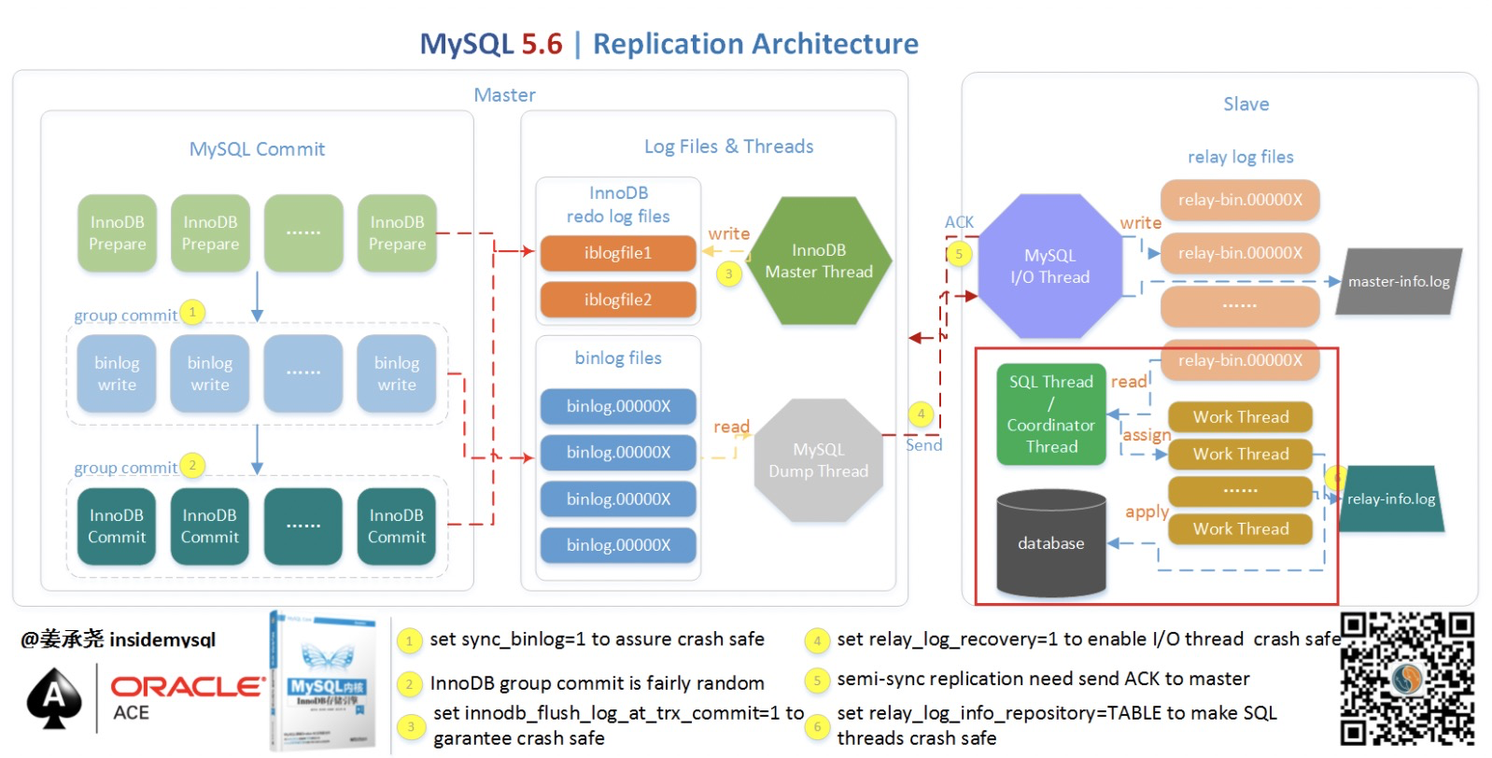
一般Mysql主從復制有三個線程參與,都是單線程:Binlog Dump(主) -> IO Thread (從) -> SQL Thread(從)。
復制出現延遲一般出在兩個地方:
- SQL線程忙不過來 (可能需要應用數據量較大,可能和從庫本身的一些操作有鎖和資源的沖突;主庫可以并發寫,SQL線程不可以;主要原因)
- 網絡抖動導致IO線程復制延遲(次要原因)。
MySQL主從復制延遲的解決辦法:MySQL從5.6開始有了SQL Thread多個的概念,可以并發還原數據,即并行復制技術。并行復制的機制,是MySQL的一個非常重要的特性,可以很好的解決MySQL主從延遲問題!
在MySQL 5.6中,設置參數slave_parallel_workers = 4(>1),即可有4個SQL Thread(coordinator線程)來進行并行復制,其狀態為:Waiting for an evant from Coordinator。但是其并行只是基于Schema的,也就是基于庫的。如果數據庫實例中存在多個Schema,這樣設置對于Slave復制的速度可以有比較大的提升。通常情況下單庫多表是更常見的一種情形,那基于庫的并發就沒有卵用。
其核心思想是:
不同schema下的表并發提交時的數據不會相互影響,即slave節點可以用對relay log中不同的schema各分配一個類似SQL功能的線程,來重放relay log中主庫已經提交的事務,保持數據與主庫一致。
MySQL 5.6版本支持所謂的并行復制,但是其并行只是基于schema的,也就是基于庫的
如果用戶的MySQL數據庫實例中存在多個schema,對于從機復制的速度的確可以有比較大的幫助。但是基于schema的并行復制存在兩個問題:
- crash safe功能不好做,因為可能之后執行的事務由于并行復制的關系先完成執行,那么當發生crash的時候,這部分的處理邏輯是比較復雜的。
- 最為關鍵的問題是這樣設計的并行復制效果并不高,如果用戶實例僅有一個庫,那么就無法實現并行回放,甚至性能會比原來的單線程更差。而 單庫多表是比多庫多表更為常見的一種情形 。
注意:mysql 5.6的MTS是基于庫級別的并行,當有多個數據庫時,可以將slave_parallel_workers設置為數據庫的數量,為了避免新建庫后來回修改,也可以將該參數設置的大一些。設置為庫級別的事務時,不允許這樣做,會報錯。
備庫執行:
stop slave;
set global slave_parallel_workers = 4;
start slave;
主庫上sysbench壓一個庫
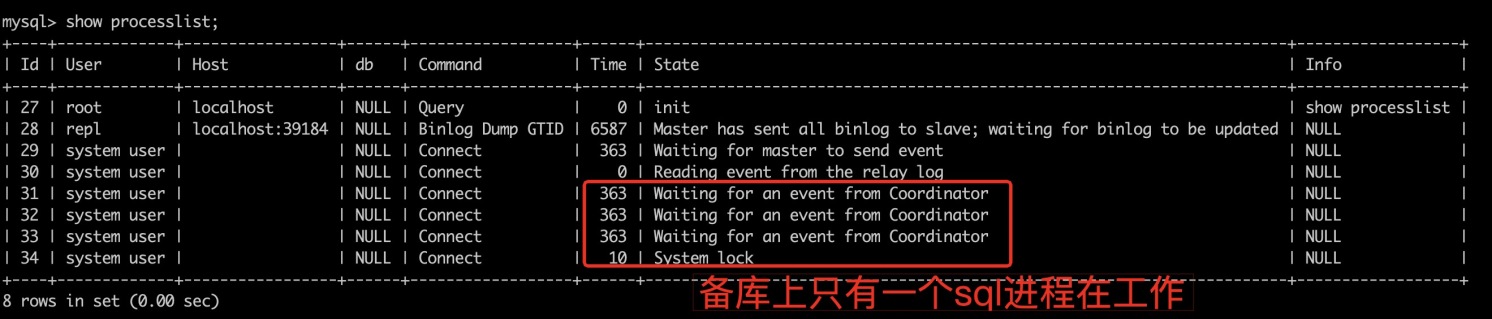
5.6的binlog內容

Mysql5.7 并行復制
測試環境搭建,70主<----雙向同步---->71備庫
grant replication slave, replication client on *.* to repl@'127.0.0.%' identified by '333';
change master to
master_host='127.0.0.1',
master_user='repl',
master_password='333',
master_port=5470,
MASTER_AUTO_POSITION=1;
/home/mingjie.gmj/bin/sysbench-1.0.16/bin/sysbench oltp_common --threads=64 --events=0 --mysql-socket=/home/mingjie.gmj/databases/data/mydata5470/mysql5470.sock --mysql-user=root --tables=10 --mysql-db=sbtest --table_size=1000 prepare
/home/mingjie.gmj/bin/sysbench-1.0.16/bin/sysbench oltp_read_write --threads=64 --events=0 --mysql-socket=/home/mingjie.gmj/databases/data/mydata5470/mysql5470.sock --mysql-user=root --mysql-db=sbtest --tables=10 --table_size=1000 --time=600 --report-interval=1 run
一個組提交的事務都是可以并行回放,因為這些事務都已進入到事務的 Prepare 階段,則說明事務之間沒有任何沖突(否則就不可能提交)。
為了兼容 MySQL 5.6 基于庫的并行復制,5.7 引入了新的變量 slave-parallel-type,其可以配置的值有:
- DATABASE:默認值,基于庫的并行復制方式。
- LOGICAL_CLOCK:基于組提交的并行復制方式。
**其核心思想:**一個組提交的事務都是可以并行回放(配合binary log group commit);slave機器的relay log中 last_committed相同的事務(sequence_num不同)可以并發執行。其中,變量slave-parallel-type可以有兩個值:1)DATABASE 默認值,基于庫的并行復制方式;2)LOGICAL_CLOCK,基于組提交的并行復制方式;
MySQL 5.7開啟Enhanced Multi-Threaded Slave很簡單,只需要在Slave從數據庫的my.cnf文件中如下配置即可:
# slave
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=8 #一般建議設置4-8,太多的線程會增加線程之間的同步開銷
master_info_repository=TABLE
relay_log_info_repository=TABLE
relay_log_recovery=ON
主庫也需要配置,MySQL5.7的并行復制,期望最大化還原主庫的并行度,實現方式是在binlog event中增加必要的信息,以便slave節點根據這些信息實現并行復制。
MySQL5.7的并行復制建立在group commit的基礎上,所有在主庫上能夠完成prepared的語句表示沒有數據沖突,就可以在slave節點并行復制。所以在并行復制環境中,除了在Slace從數據庫中配置之外,還需要在Master主數據庫上的my.cnf文件中添加binlog_group_commit配置,否則從庫無法做到基于事物的并行復制:
# master
binlog_group_commit_sync_delay = 100
binlog_group_commit_sync_no_delay_count = 10
binlog_group_commit_sync_delay,這個參數控制著日志在刷盤前日志提交要等待的時間,默認是0也就是說提交后立即刷盤,但是并不代表是關閉了組提交,當設置為0以上的時候,就允許多個事物的日志同時間一起提交刷盤,也就是我們說的組提交。組提交是并行復制的基礎,我們設置這個值的大于0就代表打開了組提交的延遲功能,而組提交是默認開啟的。最大值只能設置為1000000微妙。binlog_group_commit_sync_no_delay_count,這個參數表示我們在binlog_group_commit_sync_delay等待時間內,如果事物數達到這個參數的設定值,就會觸動一次組提交,如果這個值設為0的話就不會有任何的影響。如果到達時間但是事物數并沒有達到的話,也是會進行一次組提交操作的。
MySQL 5.7并行復制的思想簡單易懂,一言以蔽之: 一個組提交的事務都是可以并行回放 ,因為這些事務都已進入到事務的prepare階段,則說明事務之間沒有任何沖突(否則就不可能提交)。為了兼容MySQL 5.6基于庫的并行復制,5.7引入了新的變量slave-parallel-type,其可以配置的值有:
- DATABASE:默認值,基于庫的并行復制方式
- LOGICAL_CLOCK:基于組提交的并行復制方式
組提交下BINLOG的區別
show global variables like '%group_commit%';
+-----------------------------------------+-------+
| Variable_name | Value |
+-----------------------------------------+-------+
| binlog_group_commit_sync_delay | 0 |
| binlog_group_commit_sync_no_delay_count | 0 |
+-----------------------------------------+-------+
測試發現binlog_group_commit_sync_delay參數為0也會有組提交
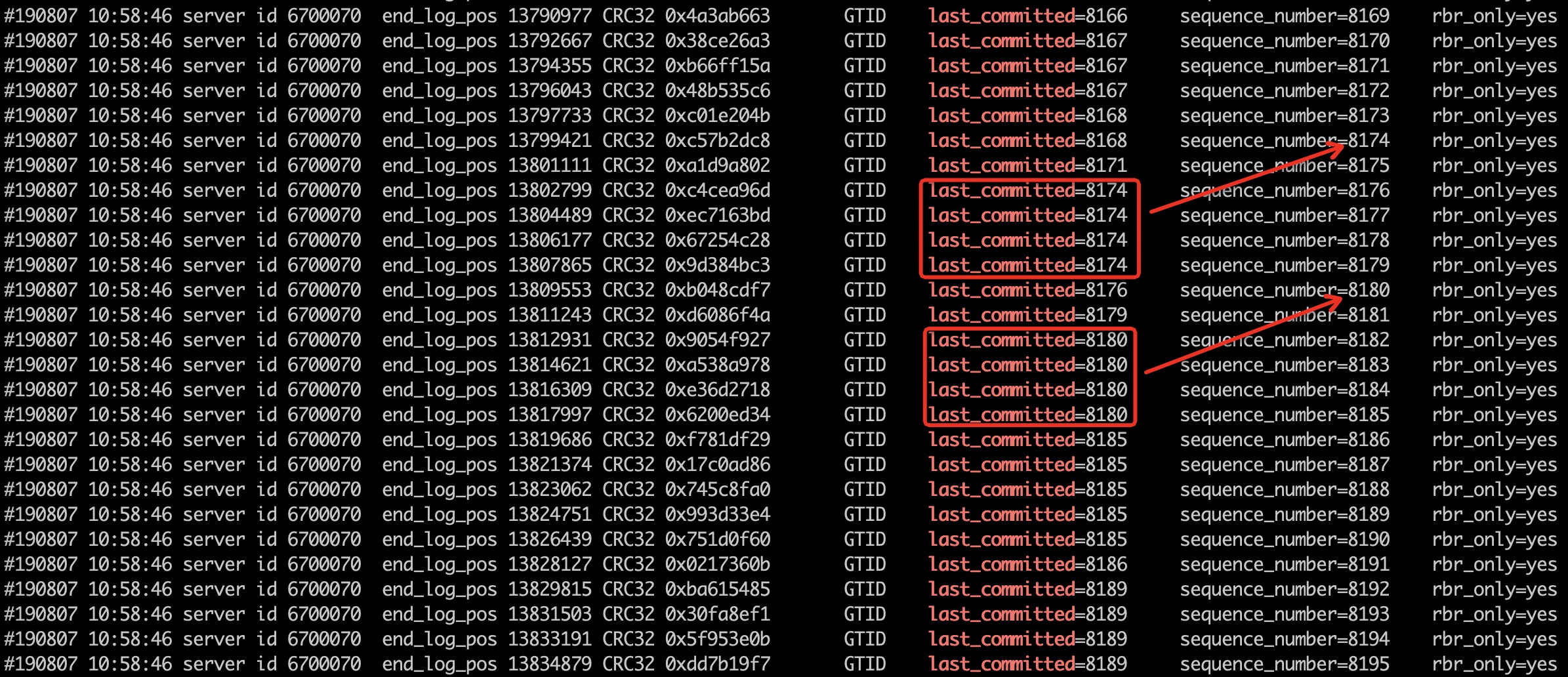
mysqlbinlog mysql-bin.000077 | grep last_committed
并行復制測試
主庫
binlog_group_commit_sync_delay = 100
binlog_group_commit_sync_no_delay_count = 10
# 或者不配置也可以有分組提交
備庫
# slave
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=8 #一般建議設置4-8,太多的線程會增加線程之間的同步開銷
master_info_repository=TABLE
relay_log_info_repository=TABLE
relay_log_recovery=ON
sysbench
[ 141s ] thds: 64 tps: 744.00 qps: 15858.06
[ 142s ] thds: 64 tps: 719.00 qps: 15138.03
[ 143s ] thds: 64 tps: 722.99 qps: 15201.86
[ 144s ] thds: 64 tps: 760.00 qps: 16014.07
[ 145s ] thds: 64 tps: 622.97 qps: 13209.31
[ 146s ] thds: 64 tps: 785.04 qps: 16453.84
[ 147s ] thds: 64 tps: 795.00 qps: 16679.90
[ 148s ] thds: 64 tps: 905.01 qps: 19056.13
[ 149s ] thds: 64 tps: 739.01 qps: 15643.13
打開并行復制后,并行SQL線程并發工作,備庫無延遲(關閉并行復制延遲高)
理論篇
MySQL 5.7并行復制引入了兩個值last_committed和sequence_number。
last_committed表示事務提交的時候,上次事務提交的編號,在主庫上同時提交的事務設置成相同的last_committed。
如果事務具有相同的last_committed,表示這些事務都在一組內,可以進行并行的回放。這個機制也是Commit-Parent-Based SchemeWL#6314中的實現方式。不過之后,官方對這種模式做了改進,所以最新的并行回放機制和WL#6314有了不同,詳情見Lock-Based SchemeWL#7165。
下面介紹一下舊模式Commit-Parent-Based SchemeWL#6314和新模式Lock-Based SchemeWL#7165的不同之處,以及改進的地方。
Commit-Parent-Based Scheme WL#6314
Commit-Parent-Based Scheme簡介
- 在master上,有一個全局計數器(global counter)。在每一次存儲引擎提交之前,計數器值就會增加。
- 在master上,在事務進入prepare階段之前,全局計數器的當前值會被儲存在事務中。這個值稱為此事務的
commit-parent。 - 在master上,
commit-parent會在事務的開頭被儲存在binlog中。 - 在slave上,如果兩個事務有同一個
commit-parent,他們就可以并行被執行。
此commit-parent就是我們在binlog中看到的last_committed。如果commit-parent相同,即last_committed相同,則被視為同一組,可以并行回放。
Commit-Parent-Based Scheme的問題
一句話:Commit-Parent-Based Scheme會降低復制的并行程度。
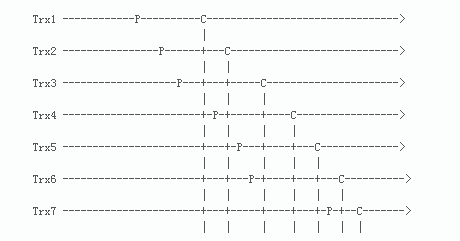
- 水平虛線表示事務按時間順序往后走。
- P表示事務在進入prepare階段之前讀到的
commit-parent值的那個時間點。可以簡單的視為加鎖時間點。 - C表示事務增加了全局計數器(global counter)的值的那個時間點。可以簡單的視為釋放鎖的時間點
- P對應的
commit-parent(last_commited)是取自所有已經執行完的事務的最大的C對應的sequence_number。舉例來說:- Trx4的P對應的
commit-parent(last_commited)取自所有已經執行完的事務的最大的C對應的sequence_number,也就是Trx1的C對應的sequence_number。因為這個時候Trx1已經執行完,但是Trx2還未執行完。 - Trx5的P對應的
commit-parent(last_commited)取自所有已經執行完的事務的最大的C對應的sequence_number,也就是Trx2的C對應的sequence_number;Trx6的P對應的commit-parent(last_commited)取自所有已經執行完的事務的最大的C對應的sequence_number,也就是Trx2的C對應的sequence_number。所以Trx5和Trx6具有相同的commit-parent(last_commited),在進行回放的時候,Trx5和Trx6可以并行回放。
- Trx4的P對應的
由圖可見,Trx5 和 Trx6可以并發執行,因為他們的commit-parent是相同的,都是由Trx2設定的。但是,Trx4和Trx5不能并發執行, Trx6和Trx7也不能并發執行。
我們可以注意到,在同一時段,Trx4和Trx5、Trx6和Trx7分別持有他們各自的鎖,事務互不沖突。所以,如果在slave上并發執行,也是不會有問題的。
根據以上例子,可以得知:
- Trx4、Trx5和Trx6在同一時間持有各自的鎖,但Trx4無法并發執行。
- Trx6和Trx7在同一時間持有各自的鎖,但Trx7無法并發執行。
但是,實際上,Trx4是可以和Trx5、Trx6并行執行,Trx6可以和Trx7并行執行。
如果能實現這個,那么并行復制的效果會更好。所以官方對并行復制的機制做了改進,提出了一種新的并行復制的方式:Lock-Based Scheme。
智能推薦

mysql主從復制 | 級聯方式復制 | 并行復制 | 半同步復制 | 全同步
兩種模式 注意: 去中心化server3找server2,server2找server1 -------級聯,這樣降低了server1的負載 配置mysql是,很多問題直接看報錯日志就可以解決!!!!! 主從復制是單向的,不能在從機直接操作數據庫寫數據 主從復制的基礎是在底層數據一致上才能搭建,如果不一致,一定要先同步數據在slave上 /////////////////...

linux mysql的主從復制(GTID)/并行復制/無損復制
安裝mysql 本次使用五個rpm包安裝 安裝后修改密碼即可 密碼默認在log中 初始化修改即可 開啟mysql二進制日志 可以設定徐亞同步的數據庫或不需要的數據庫 進入mysql創建備份賬戶 查看日至位置以及pos在備份機使用 grant replication slave on *.* to 'bobo'@'172.25.15....
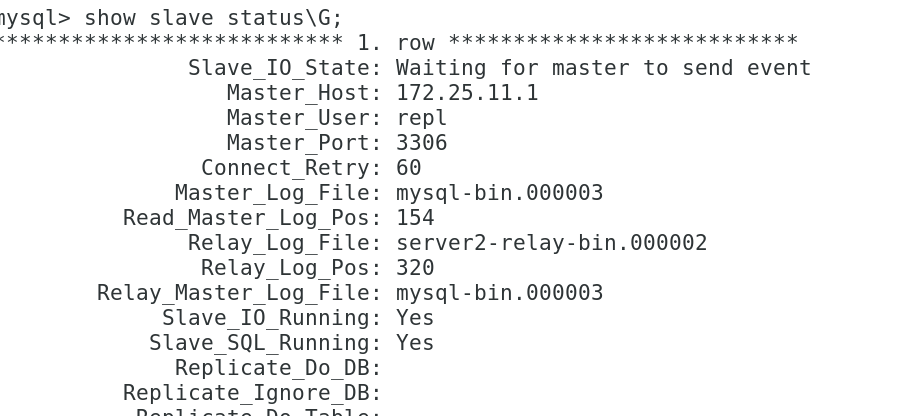
mysql基于GTID主從復制+并行復制+增強半同步復制+讀寫分離
GTID即全局事務ID(global transaction identifier),GTID實際上是由UUID+TID組成的。其中UUID是一個MySQL實例的唯一標識。TID代表了該實例上已經提交的事務數量,并且隨著事務提交單調遞增,所以GTID能夠保證每個MySQL實例事務的執行(不會重復執行同一個事務,并且會補全沒有執行的事務)。下面是一個GTID的具體形式: 4e659069-3cd8-...
mysql主從復制、基于gtid的主從復制、并行復制、半同步
主從復制用途以及條件 主從部署的必要條件 主從復制原理 主從復制存在的問題以及解決辦法 解決方法: 1. mysql 的 AB主從復制 實驗環境: 注: mysql 數據庫的版本,兩個數據庫版本要相同,或者 slave 比 master 版本高! master配置 配置完成后重新啟動mysqld服務然后連接到數據庫 創建同步帳戶,并給予權限 slave 配置 vim /etc/my.cnf 只需要...

減少主從延時---并行復制
減少主從延時—并行復制 學習檢測 主從延遲的主要問題是什么? 主從復制的流程說一下? mysql5.5 5.6的并行復制策略說一下 mariaDB的并行策略說一下 mysql 5.7的并行復制策略說一下 5.7.22的writeset 事務兩階段提交簡述 學習總結 主從延遲問題,主要是從的SQL——thread線程的賦值速度遠小于主機的寫入速度,造成了主從數據延...
猜你喜歡


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...
