cs231n-學習筆記-01圖像分類(續)
標簽: cs231n
關于K近鄰詳解與代碼實現
本文根據 李航《統計學習方法》第三章和cs231n作業1 整理而來。
0 簡介
K近鄰法(KNN)是一種基本分類與回歸方法。
K近鄰法的三個基本要素:
①K值得選擇
②距離度量
③分類決策規則
K近鄰算法沒有顯示的學習過程
1 抽象表達
輸入:
其中為實例的特征向量,為實例的類別,
輸出:
實例x所屬的類y
(1)根據給定的距離度量,在訓練集中找出與最近鄰的個點,涵蓋著個點的領域記作。
(2)在中根據分類決策規則決定的類別:
其中為指示函數,即當時為1,否則為0
2 模型
k近鄰對應的模型實際上對應于特征空間的劃分。模型由三個基本要素①K值得選擇②距離度量③分類決策規則決定。
2.1 距離度量
特征空間中兩個實例點的距離是兩個實例點相似程度的體現。一般的距離是距離。
令,,
則的距離定義為
當時,稱為曼哈頓距離,即
當時,稱為歐氏距離,即
當時,稱為切比雪夫距離,即(可通過在二維平面的特例求極限推導出此公式)
2.2 K值得選擇
K值得選擇會對k近鄰的結果產生重大的影響。
選擇較小的K值,就相當于使整體的模型變得復雜,容易發生過擬合。
選擇較大的K值,就相當于使整體的模型變得簡單,使預測發生錯誤。
在應用中,k值一般取一個比較小的整數值,通常采用交叉驗證法來選取最優的k值。
2.3 分類決策規則
k近鄰法中的分類決策規則往往是多數表決,即由輸入實例的k個鄰近的訓練實例中的多數類決定輸入實例的類。
3 代碼實現
k近鄰代碼實現包含的三個主要步驟:
① 讀取訓練數據,本次采用的數據集為CIFAR10數據集;
②分類器通過把每張測試圖片與所有的訓練圖片集比較,并且轉化為最相似的K個訓練樣本
③交叉驗證,評估分類器的好壞
3.1 讀取數據集
讀取數據集,觀察訓練數據集和測試數據集的形狀與數量:
# 加載原始的CIFAR-10 數據集的指定路徑
cifar10_dir = 'cs231n/datasets/cifar-10-batches-py'
# 清空變量,防止多次加載引起內存泄漏
try:
del X_train, y_train
del X_test, y_test
print('之前加載的數據已清空!')
except:
pass
# 按照指定路徑加載數據集,并讀取到內存變量中
X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
# 為了便于檢查,我們輸出訓練數據集和測試數據集的大小
print('Training data shape:', X_train.shape) # (50000, 32, 32, 3)
print('Training labels shape:', y_train.shape) # (50000,)
print('Test data shape:', X_test.shape) # (10000, 32, 32, 3)
print('Test labels shape:', y_test.shape) # (10000,)對數據集進行預處理,從50000個訓練樣本中選取前5000個,從10000個訓練樣本中選取前500個:
# 在本練習中,對數據進行子采樣以實現更高效的代碼執行
num_training = 5000
mask = list(range(num_training))
X_train = X_train[mask]
y_train = y_train[mask]
num_test = 500
mask = list(range(num_test))
X_test = X_test[mask]
y_test = y_test[mask]
# 將圖像數據重新整形為行
X_train = np.reshape(X_train, (X_train.shape[0], -1))
X_test = np.reshape(X_test, (X_test.shape[0], -1))
print(X_train.shape) # (5000, 3072)
print(X_test.shape) # (500, 3072)3.2 實現K近鄰分類器
采用二重循環的方式計算測試集中圖像與所有訓練集圖像的L2歐幾里得距離。
def compute_distances_two_loops(self, X):
"""
輸入:
- X: (測試集數,每張圖像的總像素點數)---->(500, 3072)
- self.X_train: (訓練集數,每張圖像的總像素點數)---->(5000, 3072)
輸出:
- dists: (測試集數,訓練集數)---->(500, 5000)其中dists[i, j]表示測試集中的第i個樣本與訓練集中第j個樣本之間的歐幾里得距離
"""
num_test = X.shape[0] # 獲取測試集數500
num_train = self.X_train.shape[0] # 獲取訓練集數5000
dists = np.zeros((num_test, num_train)) # 用0初始化距離矩陣
for i in range(num_test):
for j in range(num_train):
dists[i, j] = np.sqrt(np.sum(np.square(self.X_train[j,:] - X[i,:])))
return dists采用單循環(測試集)的方式計算測試集中圖像與所有訓練集圖像的L2歐幾里得距離。
def compute_distances_one_loop(self, X):
num_test = X.shape[0] # 獲取測試集數500
num_train = self.X_train.shape[0] # 獲取訓練集數5000
dists = np.zeros((num_test, num_train)) # 用0初始化距離矩陣
# 采用廣播的機制批量計算
for i in range(num_test):
dists[i, :] = np.sqrt(np.sum(np.square(self.X_train - X[i, :]), axis=1))
return dists采用向量的方式計算所有測試集與所有訓練集圖像的L2歐幾里得距離。
def compute_distances_no_loops(self, X):
num_test = X.shape[0] # 獲取測試集數500
num_train = self.X_train.shape[0] # 獲取訓練集數5000
dists = np.zeros((num_test, num_train)) # 用0初始化距離矩陣
# L2距離向量化實現
# np.multiply對應元素相乘;np.dot矩陣乘法
# keepdims=True 保持其本身的維度特性
# 平方差展開公式(X-Y)^2 = X^2+Y^2-2*X*Y
dists = np.multiply(np.dot(X, self.X_train.T), -2)
sq1 = np.sum(np.square(X), axis=1, keepdims=True)
sq2 = np.sum(np.square(self.X_train), axis=1)
dists = np.add(dists, sq1)
dists = np.add(dists, sq2)
dists = np.sqrt(dists)
return dists預測標簽,給出測試集與訓練集中的距離矩陣,預測每個測試集標簽的值
def predict_labels(self, dists, k=1):
"""
輸入:
- dists: (測試數據集,訓練數據集)
- k: 預測k個最近的樣本
輸出:
- y: (測試數據集,)
"""
num_test = dists.shape[0]
y_pred = np.zeros(num_test)
for i in range(num_test):
closest_y = [] # 長度為k的列表,存儲i測試點的k個最近鄰居
# argsort返回的是從小到大的索引值
closest_y = self.y_train[np.argsort(dists[i])[:k]]
# 統計出現次數最多的標簽對應的索引值即為預測的類別
y_pred[i] = np.argmax(np.bincount(closest_y))
return y_pred3.3 交叉驗證
上面我們已經實現了K近鄰分類器,現在我們使用交叉驗證的方法找出最好的超參數的值。
num_folds = 5 # 使用5折交叉驗證
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100]
X_train_folds = []
y_train_folds = []
# 把訓練數據集分成不同的小份
X_train_folds = np.array_split(X_train, num_folds)
y_train_folds = np.array_split(y_train, num_folds)
k_to_accuracies = {}
# 執行K折交叉實現找到最好的值
classifier = KNearestNeighbor()
for k in k_choices:
accuracies = np.zeros(num_folds)
for fold in range(num_folds):
temp_X = X_train_folds[:]
temp_y = y_train_folds[:]
X_validata_fold = temp_X.pop(fold)
y_validate_fold = temp_y.pop(fold)
temp_X = np.array([y for x in temp_X for y in x])
temp_y = np.array([y for x in temp_y for y in x])
classifier.train(temp_X, temp_y)
y_test_pred = classifier.predict(X_validata_fold, k=k)
num_correct = np.sum(y_test_pred == y_validate_fold)
accuracy = float(num_correct) / num_test
accuracies[fold] = accuracy
k_to_accuracies[k] = accuracies
# 輸出計算的精確度
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f' % (k, accuracy))計算后發現圖像為:
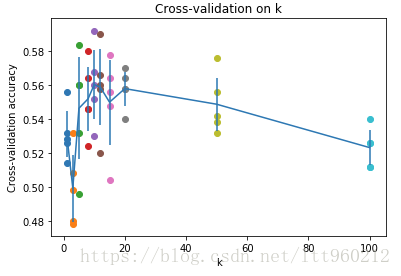
發現,當k=10,K近鄰分類器精度最高。
智能推薦

斯坦福cs231n學習筆記(4)------線性分類器最優化
在上一篇文章中,我們介紹了求解全部損失的兩種方式和過程: 也就是說,loss是有兩部分組成的,一部分是數據損失項,另一部分是正則項,而正則化只作用于w,不作用于數據。損失值反映了分類器工作的好壞,若損失值很低,說明我們對訓練集的分類做的很好。那么如何求到最小化損失的w,策略就是使用梯度下降的方式處理。 我們計算每個方向的斜率,這也是一個我們從初中就接觸到的求導過程,梯度可以告訴你是向上還是向下,若...

斯坦福cs231n學習筆記(3)------線性分類器損失函數
在上一篇中,我們介紹了線性分類器的結構和具體原理,那么這篇我們將介紹如何定義損失函數來衡量在訓練數據時的“不理想”程度,進而在這些隨機權重中找到比較理想的權重,這也是線性分類器最優化的過程。 如上圖所示,不同的權重在不同的圖像上的作用效果可好可壞。上圖中的貓的權重是2.9,效果不是很好,說明w是有損失的;汽車的權重是6.04,能夠正確地將圖片進行分類,說明w是沒有損失的;而...
【cs231n學習筆記(2017)】——— KNN
好久沒寫博客了,最近有點忙,然后自己也有點懶。。。。。。 最近確定自己要搞計算機視覺方向,然后就開始看斯坦福的cs231n課程,準備寫系列博客記錄自己的學習過程及心得。 ———————————–————以下是...
CS231n課程學習筆記(四)——反向傳播
相關文章:Coursera 機器學習(by Andrew Ng)課程學習筆記 Week 5——神經網絡(二) 轉載自:CS231n課程筆記翻譯:反向傳播筆記 簡介 目標:本節將幫助讀者對反向傳播形成直觀而專業的理解。反向傳播是利用鏈式法則遞歸計算表達式的梯度的方法。理解反向傳播過程及其精妙之處,對于理解、實現、設計和調試神經網絡非常關鍵。 問題陳述:這節的核心問題是:給定函...

cs231n訓練營學習筆記(4)
知道了W是什么之后的問題是怎樣選出W:先用損失函數衡量W的好壞,然后用優化方法選出最好的W 目錄 損失函數和優化 1. Hinge Loss 表達式 二元SVM或叫二分類SVM的推導(待寫) 2. 加正則的目的 3. Softmax 與交叉熵損失公式 softmax softmax如何在編程計算的時候穩定 交叉熵 交叉熵損失的...
猜你喜歡


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...
