DC學院學習筆記(二十):用特征選擇方法優化模型
特征選擇的定義:
特征選擇( Feature Selection )也稱特征子集選擇( Feature Subset Selection , FSS ),或屬性選擇( Attribute Selection )。是指從已有的M個特征(Feature)中選擇N個特征使得系統的特定指標最優化,是從原始特征中選擇出一些最有效特征以降低數據集維度的過程,是提高學習算法性能的一個重要手段,也是模式識別中關鍵的數據預處理步驟。對于一個學習算法來說,好的學習樣本是訓練模型的關鍵。
特征選擇的方法:
數據驅動:分析手上已有的訓練數據,得出哪些x里面的特征對預測y最重要的。主要的三大種類方法如下:
- 相關性:考察在我們已有的數據里面的特征x與預測值y的相關度
- 迭代刪除(增加):確定要使用哪個算法后,選擇最合適的訓練子集,從而使得模型的效果最好
- 基于模型:通過隨機森林等可以直接得出每個訓練特征的重要性的模型;或者是在進行預測時加入的一些正則化調整,引起的對特征的篩選,從而挑選出最重要的特征
領域專家:通過相關領域的專家知識、經驗來挑選特征
相關性系數:皮爾遜系數
定義:
在統計學中,皮爾遜積矩相關系數(英語:Pearson product-moment correlation coefficient,又稱作 PPMCC或PCCs, 文章中常用r或Pearson’s r表示)用于度量兩個變量X和Y之間的相關(線性相關),其值介于-1與1之間。在自然科學領域中,該系數廣泛用于度量兩個變量之間的相關程度。它是由卡爾·皮爾遜從弗朗西斯·高爾頓在19世紀80年代提出的一個相似卻又稍有不同的想法演變而來的。這個相關系數也稱作“皮爾森相關系數r”。
公式: 
Python實現:
from scipy.stats.stats import pearsonr
pearsonr(x,y)迭代特征選擇
解決的問題:假設我們已經確定了要使用哪個算法后,我們怎么知道哪個X的子集合作為特征訓練模型效果最好。
解決方案:

迭代特征選擇python實現:
import pandas
import numpy as np
from sklearn import linear_model
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import LabelEncoder
iris =pandas.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',header=None)
iris.columns=['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm','Species']
le = LabelEncoder()
le.fit(iris['Species'])
lm = linear_model.LogisticRegression()
features = ['PetalLengthCm','PetalWidthCm','SepalLengthCm','SepalWidthCm']
y = le.transform(iris['Species'])
selected_features = []
rest_features = features[:]
best_acc = 0
while len(rest_features)>0:
temp_best_i = ''
temp_best_acc = 0
for feature_i in rest_features:
temp_features = selected_features + [feature_i,]
X = iris[temp_features]
scores = cross_val_score(lm,X,y,cv=5 , scoring='accuracy')
acc = np.mean(scores)
if acc > temp_best_acc:
temp_best_acc = acc
temp_best_i = feature_i
print("select",temp_best_i,"acc:",temp_best_acc)
if temp_best_acc > best_acc:
best_acc = temp_best_acc
selected_features += [temp_best_i,]
rest_features.remove(temp_best_i)
else:
break
print("best feature set: ",selected_features,"acc: ",best_acc)select PetalWidthCm acc: 0.853333333333
select SepalWidthCm acc: 0.94
select PetalLengthCm acc: 0.953333333333
select SepalLengthCm acc: 0.96
best feature set: ['PetalWidthCm', 'SepalWidthCm', 'PetalLengthCm', 'SepalLengthCm'] acc: 0.96
ok,跟之前得到的一樣,就是三個特征都選擇了,效果最好。
最后,來認識一下什么叫特征工程
特征工程
有這么一句話在業界廣泛流傳:數據和特征決定了機器學習的上限,而模型和算法只是逼近這個上限而已。那特征工程到底是什么呢?顧名思義,其本質是一項工程活動,目的是最大限度地從原始數據中提取特征以供算法和模型使用。
引用知乎的一張圖:https://www.zhihu.com/question/29316149

智能推薦
DC學院學習筆記(十二):數據分析—探索型數據分析
終于學習到課程的核心部分了——數據分析了! 數據分析三大類型 探索型數據分析 驗證型數據分析 預測型數據分析 數據科學的流程: 探索型數據分析的作用 與數據清理相輔相成 支持驗證型數據分析、預測型數據分析 探索型數據分析的常用圖表 條形圖、直方圖 餅圖(餅圖在探索型數據分析中使用較少,原因是肉眼對于角度之間的大小差別沒有對高度之間的差別敏感) 折線圖、散點圖 箱形圖 下面仔...

DC學院數據分析學習筆記(二):爬蟲需要的HTML
關于html,之前也稍微了解過一些,又碰到了,那么就系統的學習一下 HTML 超文本標記語言(HyperText Markup Language,簡稱:HTML)是一種用于創建網頁的標準標記語言。 什么是 HTML? HTML 是用來描述網頁的一種語言。 HTML 指的是超文本標記語言 (Hyper Text Markup Language) HTML 不是一種編程語...
DC學院數據分析學習筆記(三):基于HTML的網頁爬蟲
終于可以用python實踐一下html的爬蟲了,之前零散的也學過一些,這次希望能通過在DC學院的學習慢慢深入的了解爬蟲的理論知識。 OK,來看今天的數據分析學習筆記! 希望能有所收獲( ̄︶ ̄) 使用BeautifulSoup解析HTML文檔示例 “html_doc”表示這個文檔名稱,在上面的代碼中已經定義,“html_parser”是解析網頁所需的...
用深度學習模型提取特征
用途 有時候需要從圖片(或文本)中提取出數值型特征,供各種模型使用。深度學習模型不僅可以用于分類回歸,還能用于提取特征。通常使用訓練好的模型,輸入圖片,輸出為提取到的特征向量。 加入特征之后,結果往往不盡如人意,大致有以下原因: 深度學習模型一般有N層結構,不能確定求取哪一層輸出更合適。 深度學習模型很抽象——幾十層的卷積、池化、信息被分散在網絡參數之中。提取自然語言的特征...
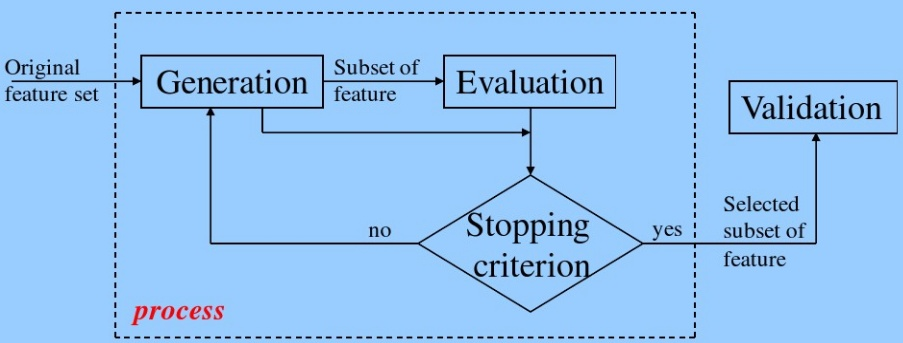
機器學習筆記八——特征工程之特征選擇
特征選擇 1、概述 2、特征選擇過程 3、特征選擇方法 3.1 過濾式(filter)特征選擇 3.1.1 Pearson相關系數法 3.1.2卡方經驗 3.1.3 互信息法 3.1.4 方差選擇法 3.2包裹式(wrapper)特征選擇 3.2.1 遞歸特征消除法 3.3 嵌入式(Embedded)特征選擇 3.3.1 基于懲罰項的特征選擇法 3.3.2 基于學習模型的特征排序 1、概述 1、為...
猜你喜歡


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...
