機器學習入門學習筆記
注:這篇學習筆記不具原創版權。
文章目錄
一、前置技能
1. 前置硬核技能
- Python 學習筆記——入門
- Python 學習筆記——進階
- Python 學習筆記——NumPy(暫未發布)
- (Python 學習筆記——)pandas.ipynb(無法發布,私聊我以獲得筆記)
- Matplotlib 現學現賣
2. 前置硬傷技能
- 一定的高等代數知識,現學現賣
二、Recollection
主成分分析(PCA)
1. 作用
對數據矩陣中降維,數據壓縮消除冗余。在降維后再進行升維,高維空間中細碎的信息丟失了,即相當于對數據進行了降噪處理。
2. 協方差矩陣
設 表示第 條數據(共 條)的第 個維度(共 維)。設 表示第 個樣本的第 個維度與第 個維度的平均值的差,即:(稱這個過程為中心化)。
定義協方差矩陣為一個 的元素,且滿足:
可以發現:
- 若 為正,說明這兩個維度在他們各自的平均值附近的波動是一致的;
- 若 為負,說明這兩個維度在他們各自的平均值附近的波動是負相關的;
- 若 為 ,說明這兩個維度相關性差。
3. PCA 的基本思想
降維肯定意味著數據的損失,我們想讓數據的損失盡量的小。我們考慮投影這一策略:假設我們要將 條數據( 個在 維空間的點)從三維空間(為了方便理解,假設 )投影到二維空間。想要保留盡可能多的數據,我們應該找到這樣的一個投影平面,使得:
- 三維空間中的點離投影平面盡量地近,這樣顯然可以減少數據的損失;
- 三維空間中的點在投影平面盡量地分散,這樣顯然可以減少數據的損失。
可以證明,這兩種策略在數學上是等價的。
另一種情況是,如果一個維度能夠被其他維度線性表出,是否就意味著可以減少一個維度了呢?實際情況中能夠存在能夠線性表出的情況是幾乎不可能的,但是可以“接近線性表出”。比如,如果真的存在一個維度能夠被其他維度線性表出,但由于浮點誤差,我們無法在程序中劃等號。這時用 PCA 降維也能取得不錯的效果。
4. PCA 算法大致流程
輸入: 維樣本集 ,要降維到的維數 。
輸出:降維后的樣本集 。
- 對所有的樣本進行中心化(即對每維進行中心化),得到 (一條數據是一列);
- 計算樣本的協方差矩陣 ;
- 對矩陣 進行特征值分解(特征向量的那個特征值,)(雅克比迭代法,對角化 維實對稱矩陣);
- 取出最大的 個特征值對應的特征向量,將所有的特征向量標準化后,組成特征向量矩陣 ( 行 列);
- 對樣本集中的每一個樣本 ,轉化為新的樣本 ( 和 都是列向量);
- 得到輸出樣本集 。
奇異值分解(SVD)
1. 特征向量與特征值
特征向量與特征值:。
求出特征值和特征向量有什么好處呢? 就是我們可以將矩陣 特征分解。如果我們求出了矩陣 的 個特征值 ,以及這 個特征值所對應的特征向量 ,如果這 個特征向量線性無關,那么矩陣 就可以用下式的特征分解表示:
其中 是這 個特征向量所張成的 維矩陣,而 為這 個特征值為主對角線的 維矩陣。
一般我們會把 的這 個特征向量標準化,即滿足 ,或者說 ,此時 的 個特征向量為標準正交基,滿足 ,即 。
要進行特征分解,矩陣 必須是方陣。如果 不是方陣,就要用到 SVD。
2. SVD 的定義
假設我們的矩陣 是一個 的矩陣,那么定義矩陣 的 SVD 為:
其中 是一個 的矩陣, 是一個 的矩陣,除了主對角線上的元素以外全為 ,主對角線上的每個元素都稱為奇異值, 是一個 的矩陣。 和 都滿足 ,。
3. 求法
是 的特征向量組成的矩陣,稱 中的每個特征向量為 的右奇異向量。
是 的特征向量組成的矩陣,稱 中的每個特征向量為 的左奇異向量。
求奇異值:
另外還有 。
4. 性質
奇異值很多時候減少得特別地快。在很多情況下,前 10% 甚至 1% 的奇異值的和就占了全部奇異值之和的 99% 以上。我們可以用最大的 個奇異值和對應的左右奇異向量來近似描述矩陣。也就是說:
有一些 SVD 的實現算法可以不求先求出協方差矩陣 ,也能求出我們的右奇異矩陣 。也就是說,我們的 PCA 算法可以不用做特征分解,而是做 SVD 來完成。
以上,都是可以拿來降維(壓縮、降噪)的。
三、機器學習概念
機器學習簡單地說就是對數據建模。大致的步驟:
- 選擇模型;
- 通過對數據的“觀測學習”讓模型得到合適的“參數”從而使模型“個性化”,能更好地與觀察數據“吻合(fit)”;
- 然后用得到的模型對同類未觀察到的數據進行“預測”。
機器學習可以大致分為兩類:
- 有監督學習(Supervised learning):對有標記數據進行學習。
- 學習對數據的有目標性的認知——標注;
- 常見算法:貝葉斯分類器、SVM、CRF、……
- 無監督學習(Unsupervised learning):直接在無標數據上進行學習。
- 學習對當前數據集的一種更加抽象簡明的表達——泛華和降噪;
- 常見算法:線性回歸、K-means、SVD、EM、……
四、開始入門
1. 一個庫
scikit-learn 是一個包含了眾多機器學習算法的庫,包含分類(Classification)、回歸(Regression)、聚類(Clustering)、數據降維(Dimensionality reduction)、模型選擇(Model selection)和數據預處理(Preprocessing)六個主要模塊。
import sklearn
2. 第二個庫
訓練數據的一般組織形式
對于訓練數據的矩陣(稱為關聯矩陣、特征矩陣(Feature Matrix)),我們一般認為:一行代表一個記錄,一列代表一個特征。而目標向量(Target Vector)是一個單列的向量,每一行代表一個記錄的目標值。
一般而言,訓練數據的初始形態的每一列對應的特征是有具體指向的。要快速獲取這些特征的分布情況,可以借助數據的可視化。例如,人的身高體重分布怎么看呢?可以將身高作為橫坐標,將體重作為縱坐標,畫出散點圖來,數據的特征就一目了然了。
高維數據可視化
然而,真實的原始數據通常不會只有兩維(2 種特征),為了方便,我們可以只看其中的兩個特征,并畫出散點圖來,相當于只研究在某兩個特征下原始數據的分布問題。如果我們將特征兩兩組合、并一一觀察,我們或許也能得到有用的信息。
可以使用一個叫做 seaborn 的庫,它是一個基于 matplotlib 的數據可視化庫。
import seaborn as sns
想手動安上太復雜了,直接使用 Anaconda!
3. 一些例子
使用 sklearn 進行線性回歸
import matplotlib.pyplot as plt
import numpy as np
from IPython.display import display
from sklearn.linear_model import LinearRegression
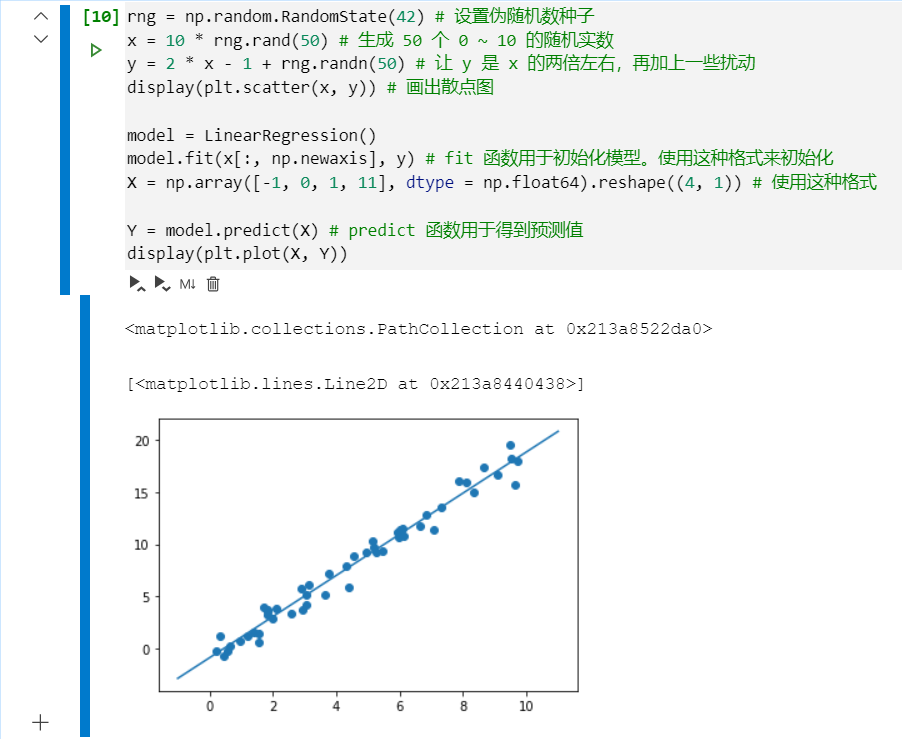
rng = np.random.RandomState(42) # 設置偽隨機數種子
x = 10 * rng.rand(50) # 生成 50 個 0 ~ 10 的隨機實數
y = 2 * x - 1 + rng.randn(50) # 讓 y 是 x 的兩倍左右,再加上一些擾動
display(plt.scatter(x, y)) # 畫出散點圖
model = LinearRegression()
model.fit(x[:, np.newaxis], y) # fit 函數用于初始化模型。使用這種格式來初始化
X = np.array([-1, 0, 1, 11], dtype = np.float64).reshape((4, 1)) # 使用這種格式
Y = model.predict(X) # predict 函數用于得到預測值
display(plt.plot(X, Y))
聚類問題處理方法
我們使用一個 Iris 數據集,里面的數據大概長這樣:

我們要根據中間的四個特征進行分類,答案是 Species。所以需要將 Species 分離。
import seaborn as sns
iris = pd.read_csv('Iris.csv')
display(iris.head())
from sklearn.decomposition import PCA
model = PCA(n_components = 2)
X_iris = iris.drop('Species', axis = 1) # 扔去 Species 列
y_iris = iris.loc[:, 'Species'] # 只留下 Species 列
PCA 降維代碼
接著上面的例子。
from sklearn.decomposition import PCA
model = PCA(n_components = 2) # 降成 2 維
model.fit(X_iris) # 先要執行 fit 操作
X_2D = model.transform(X_iris) # 執行降維操作
display(X_2D)
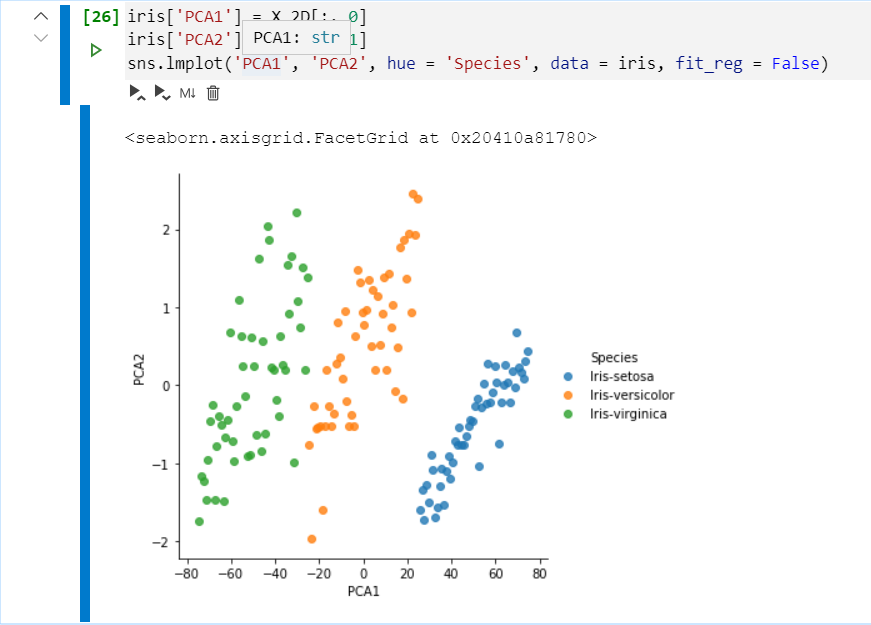
實現數據可視化
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot('PCA1', 'PCA2', hue = 'Species', data = iris, fit_reg = False) # 分別是:橫坐標數據索引,縱坐標數據索引,hue:用于分類的,data:數據集,fit_reg:自動為 x、y 回歸,這里沒用
五、實戰——推薦系統:協同過濾
1. 原始數據形態:
user_id movie_id rating timestamp
0 196 242 3 881250949
1 186 302 3 891717742
2 22 377 1 878887116
3 244 51 2 880606923
4 166 346 1 886397596
是 Pandas 的 DataFrame 呢。
2. 拆分訓練集/測試集
為了評估測試效果,我們可以這樣做:將訓練集分組,對于其中的一個組 ,我們用其余組生成的經驗(其余組作訓練集)來預測 ( 作測試集),然后比對吻合程度,便可大致估計訓練效果。
scikit-learn 中有這樣的函數,為我們拆分訓練集測試集,叫做 model_selection.train_test_split。使用 test_size 指定測試集占比,默認 0.25。
Help on function train_test_split in module sklearn.model_selection._split:
train_test_split(*arrays, **options)
Split arrays or matrices into random train and test subsets
Quick utility that wraps input validation and
``next(ShuffleSplit().split(X, y))`` and application to input data
into a single call for splitting (and optionally subsampling) data in a
oneliner.
Read more in the :ref:`User Guide <cross_validation>`.
Parameters
----------
*arrays : sequence of indexables with same length / shape[0]
Allowed inputs are lists, numpy arrays, scipy-sparse
matrices or pandas dataframes.
test_size : float, int or None, optional (default=None)
If float, should be between 0.0 and 1.0 and represent the proportion
of the dataset to include in the test split. If int, represents the
absolute number of test samples. If None, the value is set to the
complement of the train size. If ``train_size`` is also None, it will
be set to 0.25.
train_size : float, int, or None, (default=None)
If float, should be between 0.0 and 1.0 and represent the
proportion of the dataset to include in the train split. If
int, represents the absolute number of train samples. If None,
the value is automatically set to the complement of the test size.
random_state : int, RandomState instance or None, optional (default=None)
If int, random_state is the seed used by the random number generator;
If RandomState instance, random_state is the random number generator;
If None, the random number generator is the RandomState instance used
by `np.random`.
shuffle : boolean, optional (default=True)
Whether or not to shuffle the data before splitting. If shuffle=False
then stratify must be None.
stratify : array-like or None (default=None)
If not None, data is split in a stratified fashion, using this as
the class labels.
Returns
-------
splitting : list, length=2 * len(arrays)
List containing train-test split of inputs.
.. versionadded:: 0.16
If the input is sparse, the output will be a
``scipy.sparse.csr_matrix``. Else, output type is the same as the
input type.
Examples
--------
>>> import numpy as np
>>> from sklearn.model_selection import train_test_split
>>> X, y = np.arange(10).reshape((5, 2)), range(5)
>>> X
array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>> list(y)
[0, 1, 2, 3, 4]
>>> X_train, X_test, y_train, y_test = train_test_split(
... X, y, test_size=0.33, random_state=42)
...
>>> X_train
array([[4, 5],
[0, 1],
[6, 7]])
>>> y_train
[2, 0, 3]
>>> X_test
array([[2, 3],
[8, 9]])
>>> y_test
[1, 4]
>>> train_test_split(y, shuffle=False)
[[0, 1, 2], [3, 4]]
3. 一堆騷操作
相似度矩陣
from sklearn.metrics.pairwise import pairwise_distances
user_similarity = pairwise_distances(train_data_matrix, metric='cosine')
item_similarity = pairwise_distances(train_data_matrix.T, metric='cosine')
利用 metrics.pairwise.pairwise_distances 函數可以計算特征向量(數據的一條記錄對應的所有特征構成的向量)之間的距離。例如,以上代碼計算了特征向量兩兩之間的余弦距離。(打印出來看,發現自己對自己不是 ,而是 )
智能推薦

機器學習入門
機器學習入門 一、認識機器學習 1. 定義 2. 分類 2.1 有監督學習 2.1.1 分類問題 2.1.2 回歸問題 2.2 無監督學習 二、機器學習基本流程 機器學習三要素: 1. 模型: 2. 策略: 3. 算法: 梯度下降算法: 批量梯度下降BGD: 隨機梯度下降SGD: 小批量梯度下降MBGD: 梯度下降調優: 一、認識機器學習 1. 定義 機器學習(Machine Learning)簡...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...
猜你喜歡


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...

統計學習方法 - 樸素貝葉斯
引入問題:一機器在良好狀態生產合格產品幾率是 90%,在故障狀態生產合格產品幾率是 30%,機器良好的概率是 75%。若一日第一件產品是合格品,那么此日機器良好的概率是多少。 貝葉斯模型 生成模型與判別模型 判別模型,即要判斷這個東西到底是哪一類,也就是要求y,那就用給定的x去預測。 生成模型,是要生成一個模型,那就是誰根據什么生成了模型,誰就是類別y,根據的內容就是x 以上述例子,判斷一個生產出...

styled-components —— React 中的 CSS 最佳實踐
https://zhuanlan.zhihu.com/p/29344146 Styled-components 是目前 React 樣式方案中最受關注的一種,它既具備了 css-in-js 的模塊化與參數化優點,又完全使用CSS的書寫習慣,不會引起額外的學習成本。本文是 styled-components 作者之一 Max Stoiber 所寫,首先總結了前端組件化樣式中的最佳實踐原則,然后在此基...
