前言
最近在搞一些大數據方面產品的開發工作,運用的都是公司已經搭建好的大數據計算相關環境:比如 hive、hbase、storm等。要想更深入的了解這些計算框架,準備自己搭建一套大數據計算開發環境。
目前的大數據計算相關體系,基本都是建立在hadoop基礎上,比如hive、hbase、spark、flume等。所以準備先自己搭建一套hadoop環境。以下是我的搭建流程,以及遇到的問題等。
前期準備
1、hadoop2.7.3 下載地址 http://hadoop.apache.org/releases.html

2.jdk 1.8 linux 版 下載地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
3、VMware 虛擬機下載、以及centos 7鏡像下載
安裝步驟
我是一臺筆記本,win7操作系統,內存是8G。準備安裝好vmware中虛擬出三臺機器,部署1個master、2個slaves的hadoop環境:
1、首先安裝好vmware虛擬機,并在虛擬機中安裝好centos。注意虛擬機內存一定要設置為2G以上,否則執行MapReduce任務會卡住。
2、在centos中進行jdk1.8安裝,參考http://www.cnblogs.com/shihaiming/p/5809553.html
3、通過vmware的clone功能,克隆出另外兩臺虛擬機
參考:http://jingyan.baidu.com/article/6b97984d9798f11ca2b0bfcd.html
我的創建結果如下:

準備用 CentOS1 作為master,這三臺機器的ip分別為:192.168.26.129、192.168.26.130、192.168.26.131
4、安裝 hadoop,參考http://www.cnblogs.com/lavezhang/p/5237042.html
特別說明下,他這里安裝配置文件(hdfs-site.xml、slaves等幾個配置文件)里都是用的ip,需要在三臺機器上配置host(ip換成自己的):
192.168.26.129 hadoop1
192.168.26.130 hadoop2
192.168.26.131 hadoop3
否則會出現異常:
2017-01-24 04:25:33,929 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool BP-7673552-127.0.0.1-1485202915222 (Datanode Uuid null) service to /192.168.26.128:9000 Datanode denied communication with namenode because hostname cannot be resolved (ip=192.168.26.129, hostname=192.168.26.129): DatanodeRegistration(0.0.0.0:50010, datanodeUuid=170341fa-ef80-4279-a4a3-dca3663b89b7, infoPort=50075, infoSecurePort=0, ipcPort=50020, storageInfo=lv=-56;cid=CID-9bcf1a8a-449a-4238-9c5c-b2bb0eadd947;nsid=506479924;c=0)
at org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager.registerDatanode(DatanodeManager.java:873)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.registerDatanode(FSNamesystem.java:4529)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.registerDatanode(NameNodeRpcServer.java:1286)
at org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolServerSideTranslatorPB.registerDatanode(DatanodeProtocolServerSideTranslatorPB.java:96)
at org.apache.hadoop.hdfs.protocol.proto.DatanodeProtocolProtos$DatanodeProtocolService$2.callBlockingMethod(DatanodeProtocolProtos.java:28752)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:616)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:982)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2049)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2045)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2043)
最好 把配置文件(hdfs-site.xml、slaves等幾個配置文件)中ip全部替換成 hostname(我的是hadoop1、hadoop2、hadoop3)。
啟動hadoop:
bin/hadoop namenode -format
sbin/start-hdfs.sh
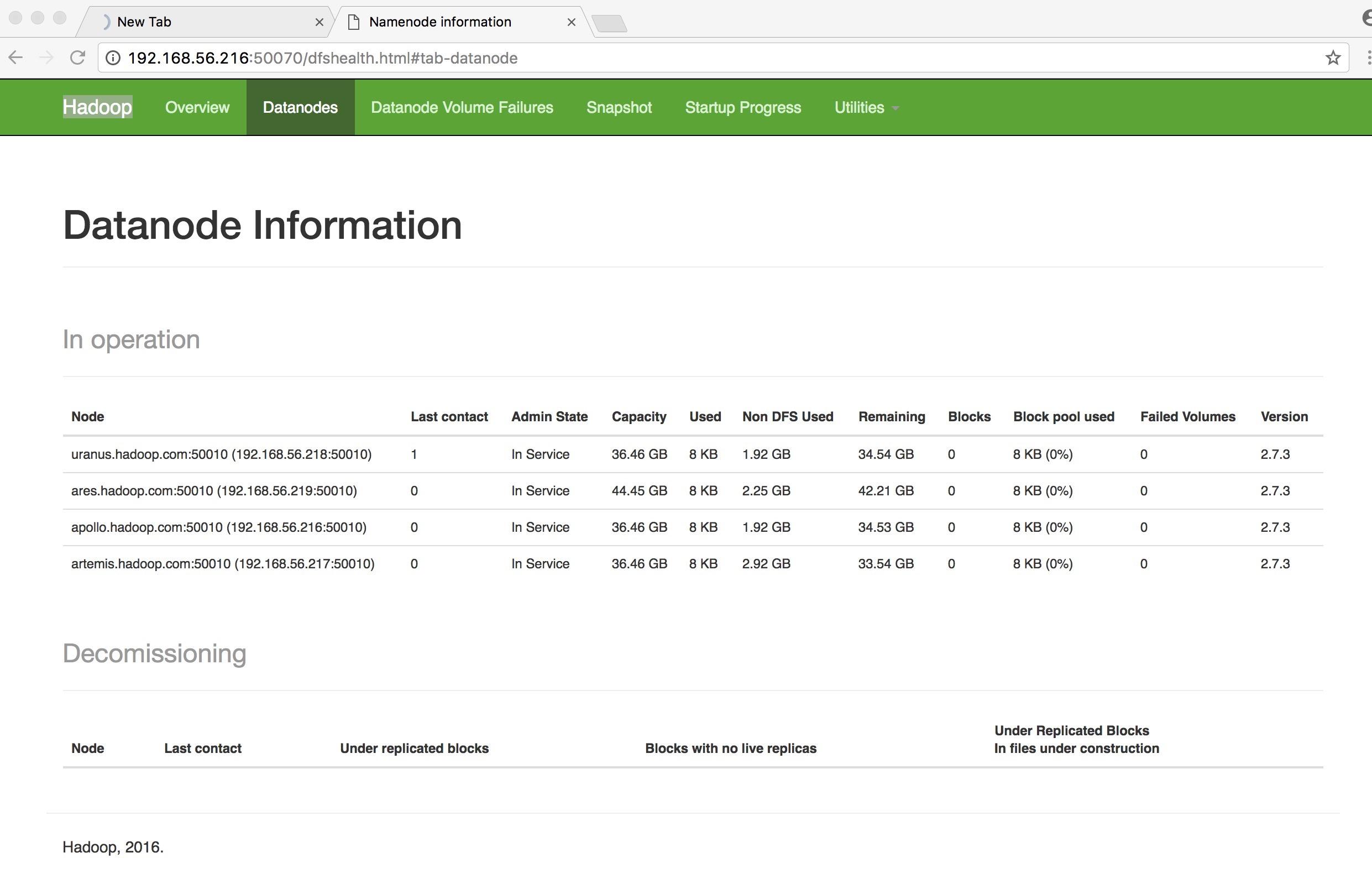
sbin/start-yarn.sh 執行jps查看是否啟動成功
5.傳入一個本地文件,測試下
bin/hadoop fs -mkdir /test
bin/hadoop fs -copyFormLocal README.txt /test
bin/hadoop fs -cat /test/README.txt
如果線上出 README.txt中的文件內容,說明成功了。
如果執行:bin/hadoop fs -copyFormLocal README.txt /test,報如下錯誤:
2017-01-24 01:48:58,282 INFO org.apache.hadoop.ipc.Server: IPC Server handler 5 on 9000, call org.apache.hadoop.hdfs.protocol.ClientProtocol.addBlock from 192.168.26.128:32964 Call#5 Retry#0
java.io.IOException: File /test/README.txt._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode(s) running and no node(s) are excluded in this operation. at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1571)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getNewBlockTargets(FSNamesystem.java:3107)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3031)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:725)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:492)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:616)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:982)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2049)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2045)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2043)
說明啟動失敗了,檢查下hadoop的日志,根據日志分析下是哪個配置錯了。主要檢查幾個配置文件,已經host設置。
ok,本機hadoop已經跑起來啦,接下來準備用idea搭建一個win的開發環境,運行mapreduc程序。
<!--[if !supportLists]-->