XML學習---XML文檔解析
Java對XML文檔進行解析
解析XML的幾種方式的概述;
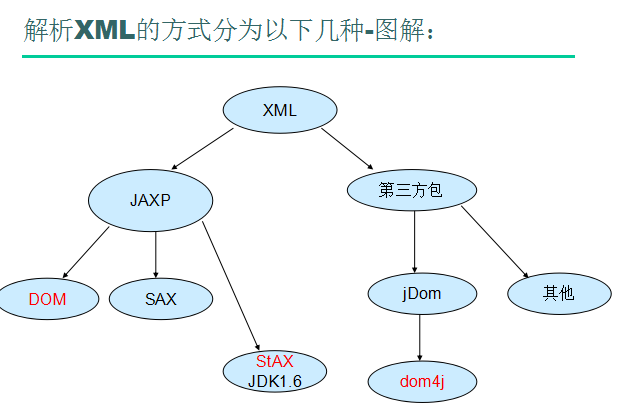
JAXP(JavaApi for Xml Programming) – sun公司的一套操作XML的API.
- DOM解析-一次性的將數據全部裝入內存。
- SAX解析-邊讀取邊解析
Dom4j(Document For Java)-第三方開源,是從jdom分裂出來的解析技術。目前jdom已經完全被dom4j替代。
- jDom – Dom4j的前身。
- Dom4j在性能和速度上都比sun公司的要快,而且支持Xpath快速查找,目前像Spring,Hibernate這些大型的框架,都是用的dom4j.
StAX – JDK1.6新特性,做為JAXP的新成員已經集成在了JDK6當中
DOM解析學習實例:
主要用來解析下面這個文檔:
<?xml version="1.0" encoding="UTF-8"?>
<users>
<user id="A001">
<name>Jack</name>
<age>22</age>
</user>
<user id="A002">
<name>張三</name>
<age>24</age>
</user>
</users>第一步:是獲取DOM 對象。 (w3c的document)
// w3c僅僅提供標準、java 提供創建方法
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document dom = db.parse("./xml/users.xml");第二部:獲取DOM下面的節點:
Node root = dom.getFirstChild();
System.out.println("NodeName:"+root.getNodeName());
System.out.println("---------------------");演示結果:成功拿到users節點

看看他有哪些子節點: 應該是 兩個 user 才對
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document dom = db.parse(new File("./xml/users.xml"));
Node root = dom.getFirstChild();
System.out.println("NodeName:"+root.getNodeName());
System.out.println("---------------------");
NodeList list = root.getChildNodes();
for(int i=0;i<list.getLength();i++){
System.out.println(list.item(i).getNodeName());
}演示結果: 換行符也是子節點!!!
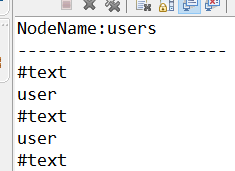
接下來拿name標簽的值
方式一:通過孩子節點
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document dom = db.parse(new File("./xml/users.xml"));
Node root = dom.getFirstChild();
System.out.println("NodeName:"+root.getNodeName());
System.out.println("---------------------");
NodeList list = root.getChildNodes();
for(int i=0;i<list.getLength();i++){
System.out.println(list.item(i).getNodeName());
}
System.out.println("---------------------");
//不建議采用的方式(理由見后面的講解)---Node.getChildNodes()
NodeList nodeList = root.getChildNodes();
System.out.println("節點數:"+nodeList.getLength());
Node node = nodeList.item(1);
System.out.println("NodeName:"+node.getNodeName());
Node nameNode = node.getChildNodes().item(1);
String name = nameNode.getTextContent();
System.out.println("name="+name);演示結果:

方式二:通過標簽明
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document dom = db.parse(new File("./xml/users.xml"));
Node root = dom.getFirstChild();
System.out.println("NodeName:"+root.getNodeName());
System.out.println("---------------------");
//采用建議的方式---Element中的getElementsByTagName(String name)
//為了使用Element中的方法,必須得強轉成Element類型
Element eRoot = (Element)root;
NodeList userList= eRoot.getElementsByTagName("user");
Element eUser1 = (Element) userList.item(0);
NodeList nameList = eUser1.getElementsByTagName("name");
Node nameNode = nameList.item(0);
String name = nameNode.getTextContent();
System.out.println(name);演示結果:
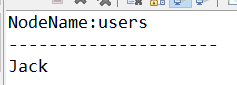
同樣的也可以拿到年齡
DocumentBuilder db = DocumentBuilderFactory.newInstance().newDocumentBuilder();
Document dom = db.parse(“./xml/users.xml”);
Element root = (Element) dom.getFirstChild();
Element eUser = (Element) root.getElementsByTagName(“user”).item(1);
Node eName=eUser.getElementsByTagName(“age”).item(0);
String strAge = eName.getTextContent();
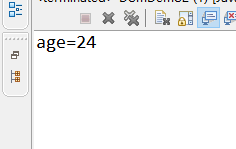
System.out.println(“age=”+strAge);
演示結果:
整片學習代碼:
package cn.hncu.jaxp.dom;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.junit.Test;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
/*
* JDK中有兩個專用于進行dom編程的包:
* 1) org.w3c.dom ----w3c是制定標準
* 2) javax.xml.parsers ----sun公司開發出來給我們解析用的
*
*
* 入口: Document接口(來自w3c,org.w3c.dom包) --> 要用工廠方法獲得該dom對象 ---工廠方法來自sun公司(javax.xml.parsers包)
*
*/
public class DomDemo {
@Test
public void getDom() throws Exception{
//獲取dom對象
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document dom = db.parse("./xml/users.xml");
System.out.println(dom);
}
//需求:讀取第一個<user>節點中的<name>值
@Test
public void getName() throws Exception{
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document dom = db.parse(new File("./xml/users.xml"));
Node root = dom.getFirstChild();
System.out.println("NodeName:"+root.getNodeName());
System.out.println("---------------------");
//不建議采用的方式(理由見后面的講解)---Node.getChildNodes()
NodeList nodeList = root.getChildNodes();
System.out.println("節點數:"+nodeList.getLength());
Node node = nodeList.item(1);
System.out.println("NodeName:"+node.getNodeName());
Node nameNode = node.getChildNodes().item(1);
String name = nameNode.getTextContent();
System.out.println("name="+name);
}
/*
* 以后要遍歷文檔,最好的選擇方式是:
* 采用Element中的getElementsByTagName(String name),
* 返回類型為:NodeList, 獲取當前元素下面的所有對應標簽的那些子元素(
* 僅僅是標簽節點---能夠去除文本內容尤其是空白符的干擾)。
*
* 建議不要采用如下兩種方式:
* 1)通過Node中的 getChildNodes(),返回類型為:NodeList, 獲取當前節點的所有
* 子節點(包括文本內容和標簽節點)----不選擇的理由:文本內容尤其是空白符也是其中的孩子節點,會產生干擾
* 2)通過Document的getElementById(String elementId), 返回Element節點,
* 這種方式在browse-dom中用起來是非常方便的,但在Java-dom中必須得給
* DocumentBuilderFactory對象設置schema
*
*/
//需求:讀取第一個<user>節點中的<name>值
@Test //OOOOOOKKKKKK
public void getName2() throws Exception{
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document dom = db.parse(new File("./xml/users.xml"));
Node root = dom.getFirstChild();
System.out.println("NodeName:"+root.getNodeName());
System.out.println("---------------------");
//采用建議的方式---Element中的getElementsByTagName(String name)
//為了使用Element中的方法,必須得強轉成Element類型
Element eRoot = (Element)root;
NodeList userList= eRoot.getElementsByTagName("user");
Element eUser1 = (Element) userList.item(0);
NodeList nameList = eUser1.getElementsByTagName("name");
Node nameNode = nameList.item(0);
String name = nameNode.getTextContent();
System.out.println(name);
}
//需求:讀取第二個<user>節點中的<age>值
@Test //OOOOOOKKKKKK
public void getAge() throws Exception{
DocumentBuilder db = DocumentBuilderFactory.newInstance().newDocumentBuilder();
Document dom = db.parse("./xml/users.xml");
Element root = (Element) dom.getFirstChild();
Element eUser = (Element) root.getElementsByTagName("user").item(1);
Node eName=eUser.getElementsByTagName("age").item(0);
String strAge = eName.getTextContent();
System.out.println("age="+strAge);
}
}
智能推薦
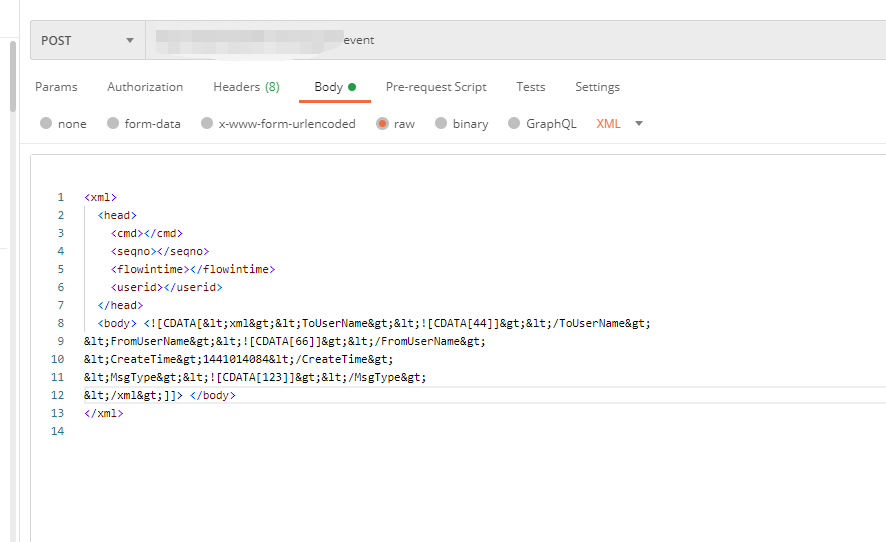
java 進行xml文檔解析
這份是對于postman請求時候,進行對于報文解析 圖一為報文發送的內容 引入相關依賴 調用這個方法后,所有的尖括號的值都已經存在,直接使用map.get 獲取對應的key即可獲取相關的value,進行封裝對象操作: 獲取所有的map的值...
XML文檔
注:本內容為個人拉勾教育大數據訓練營學習課程筆記 XML 基本概念 XML即可擴展標記語言(Extensible Markup Language) W3C在1998年2月發布1.0版本,2004年2月又發布1.1版本,但因為1.1版本不能向下兼容1.0版 本,所以1.1沒有人用 同時,在2004年2月W3C又發布了1.0版本的第三版。我們要學習的還是 1.0版本 ! 特點 可擴展的, 標簽都是自定...

java用DOM方法解析xml文檔
步驟: 1、創建DocumentBuliderFactory對象 2、創建DocumentBuilder對象(方法會拋出異常) 3、創建Document對象,用parse方法加載要解析的xml文件 這樣DOM解析xml文檔的準備工作就完成啦 下面是一些常用的節點類型的介紹 DOM操作中常用的對象: 1、節點對象:Node(包含元素節點,屬性節點,文本節點) getAttributes():獲取節點...

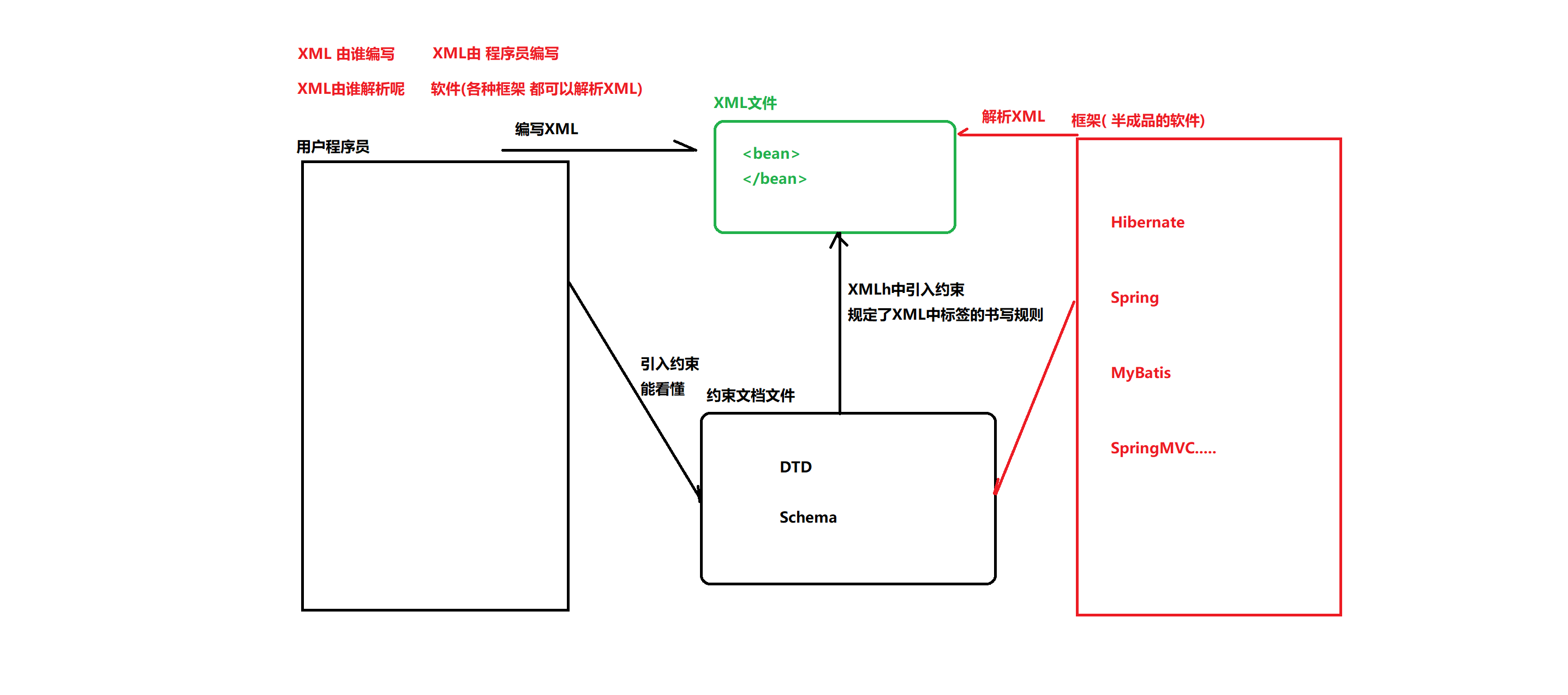
XML學習---XML文檔類型定義~DTD學習
寫這篇博客主要是為了更加深刻的鞏固學的DTD。同時也是為了以后復習. 主要學習DTD的以下幾部分 DTD的作用 DTD的元素 DTD的屬性 DTD的實體 DTD的使用 DTD的作用 我們在學習XML的時候知道XML是可拓展語言,所以呢,寫XML文檔的時候我們可以任意寫,xml是用來共享、存儲數據。如果我們大家都任意寫XML文檔,那么就不好互相共享數據。所以就需要一個規范,來控制我們寫的XML文檔,...
猜你喜歡



freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...