通過DOM4J解析XML
Dom4j是一個簡單、靈活的開放源代碼的庫。Dom4j是由早期開發JDOM的人分離出來而后獨立開發的。與JDOM不同的是,dom4j使用接口和抽象基類,雖然Dom4j的API相對要復雜一些,但它提供了比JDOM更好的靈活性。 Dom4j是一個非常優秀的Java XML API,具有性能優異、功能強大和極易使用的特點。現在很多軟件采用的Dom4j,例如Hibernate,包括sun公司自己的JAXM也用了Dom4j。 使用Dom4j開發,需下載dom4j相應的jar文件。
dom4j有如下一些特征:
- JDOM的一種智能分支,它合并了許多超出基本XML文檔表示的功能。
- 它使用接口和抽象基本類方法。
- 具有性能優異、靈活性好、功能強大和極端易用的特點。
- 是一個開放源碼的文件
1.要導入dom4j包才能使用dom4j解析xml
2.創建一個xml文件
代碼如下:
<?xml version='1.0' encoding='UTF-8' ?>
<root>
<hang>
<產品唯一ID>aab產品唯一ID</產品唯一ID>
<通用名>aa通用名</通用名>
<商品名>aa商品名</商品名>
<劑型>aa劑型</劑型>
<批準文號>aa批準文號</批準文號>
<規格>aa規格</規格>
<包裝說明>aa包裝說明</包裝說明>
<包裝單位>aa包裝單位</包裝單位>
<生產企業>aa生產企業</生產企業>
<大包裝轉換比>aa大包裝轉換比</大包裝轉換比>
<中包裝轉換比>aa中包裝轉換比</中包裝轉換比>
<備注>aa備注</備注>
<庫存>aa庫存</庫存>
<供應價>aa供應價</供應價>
<是否上架>aa是否上架</是否上架>
</hang>
<hang>
<產品唯一ID>a121</產品唯一ID>
<通用名>b12</通用名>
<商品名>c231</商品名>
<劑型>dewrwer</劑型>
<批準文號>e324324</批準文號>
<規格>f45645</規格>
<包裝說明>g4543</包裝說明>
<包裝單位>hq324e2</包裝單位>
<生產企業>i76</生產企業>
<大包裝轉換比>j453</大包裝轉換比>
<中包裝轉換比>k4r43r</中包裝轉換比>
<備注>le4tr4</備注>
<庫存>mq3e2</庫存>
<供應價>nefrw</供應價>
<是否上架>o56</是否上架>
</hang>
</root>
注:xml文件要要用ie瀏覽器打開驗證一下,編碼是否正確,如下圖所示。

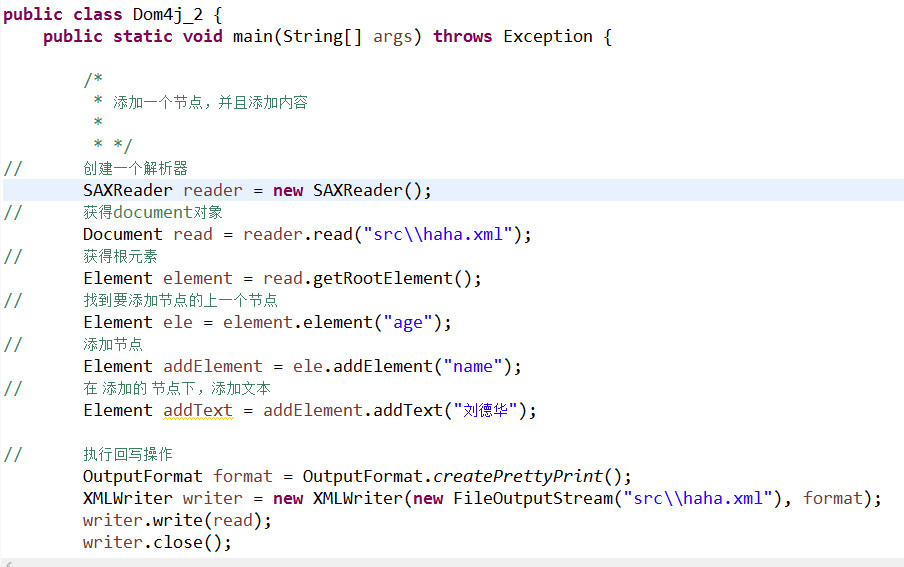
2.編寫java代碼解析xml
源代碼如下:
import java.io.File;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
/**
* DOM4J 方式解析XML
*/
public class DOM4JTest {
public static void main(String[] args) {
// 解析123.xml文件
SAXReader reader = new SAXReader();// 創建SAXReader的對象reader
try {
Document document = reader.read(new File("F://123.xml"));// 通過reader對象的read方法加載books.xml文件,獲取docuemnt對象。
Element bookStore = document.getRootElement();// 通過document對象獲取根節點bookstore
Iterator it = bookStore.elementIterator();// 通過element對象的elementIterator方法獲取迭代器
// 遍歷迭代器,獲取根節點中的信息(產品)
while (it.hasNext()) {
System.out.println("=====開始遍歷某一個產品=====");
Element book = (Element) it.next();
List<Attribute> bookAttrs = book.attributes(); // 獲取book的屬性名以及 屬性值
for (Attribute attr : bookAttrs) {
System.out.println("屬性名:" + attr.getName() + "--屬性值:" + attr.getValue());
}
//解析子節點的信息
Iterator itt = book.elementIterator();
while (itt.hasNext()) {
Element bookChild = (Element) itt.next();
System.out.println("節點名:" + bookChild.getName() + "--節點值:" + bookChild.getStringValue());
}
System.out.println("=====結束遍歷某一個產品=====");
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
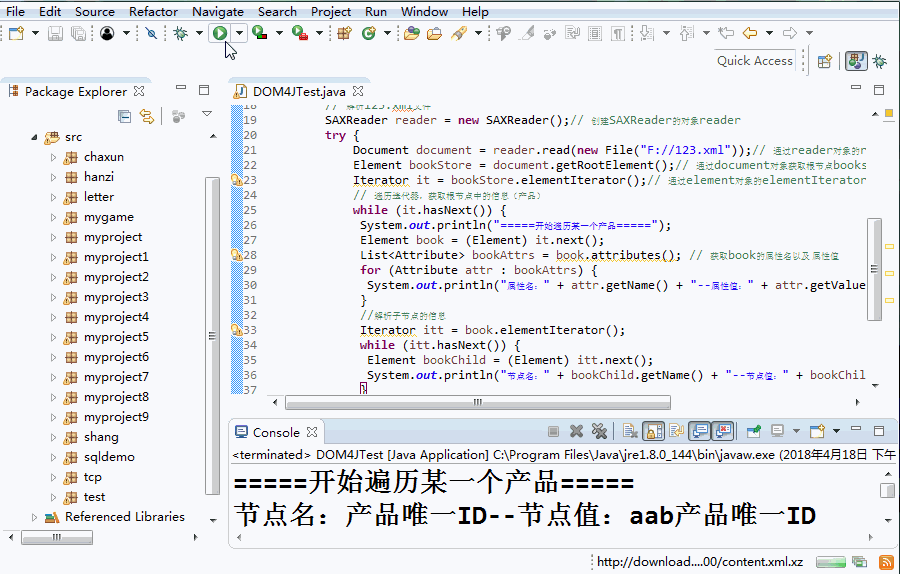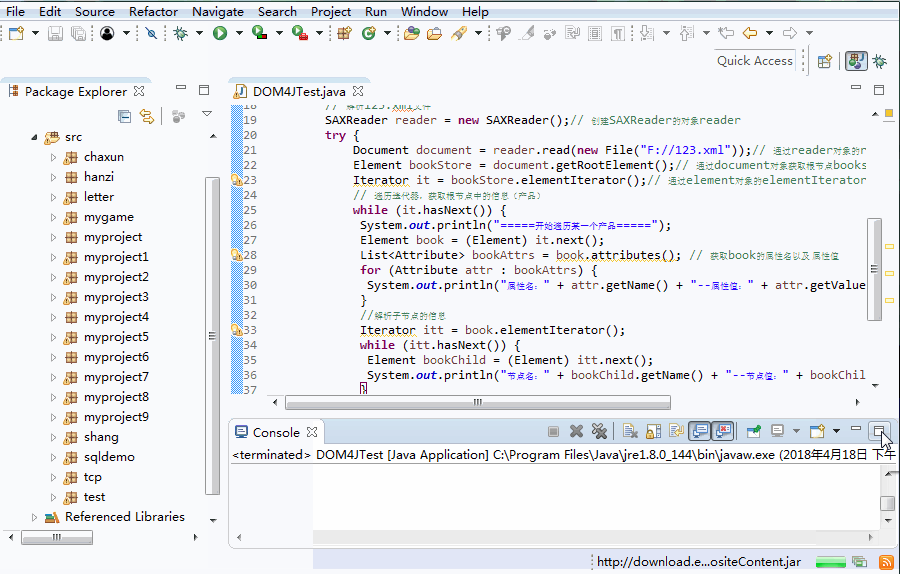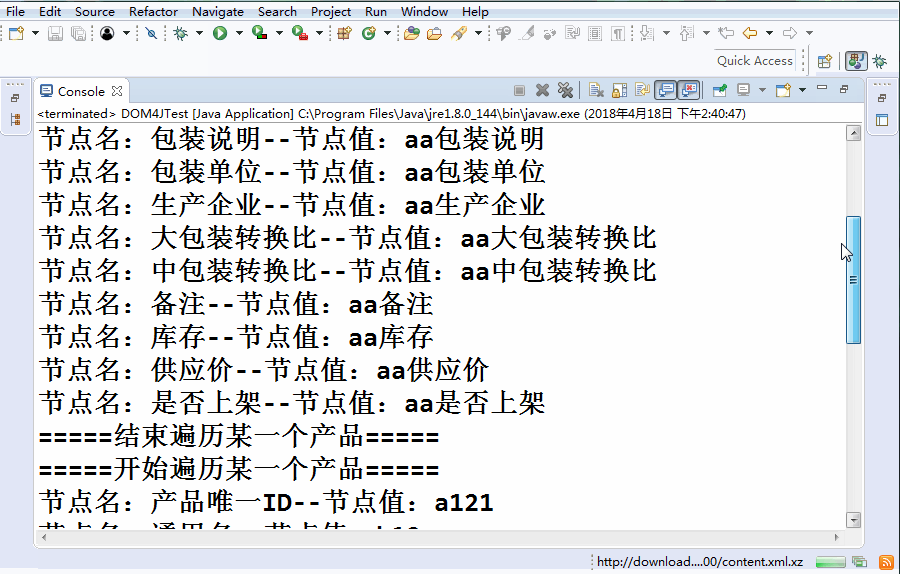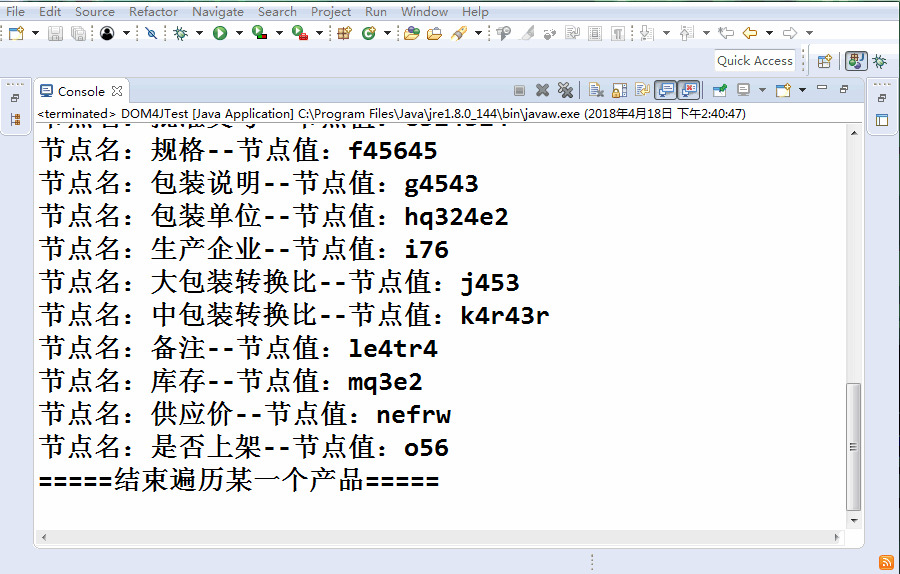
運行結果如下:
=====開始遍歷某一個產品=====
節點名:產品唯一ID--節點值:aab產品唯一ID
節點名:通用名--節點值:aa通用名
節點名:商品名--節點值:aa商品名
節點名:劑型--節點值:aa劑型
節點名:批準文號--節點值:aa批準文號
節點名:規格--節點值:aa規格
節點名:包裝說明--節點值:aa包裝說明
節點名:包裝單位--節點值:aa包裝單位
節點名:生產企業--節點值:aa生產企業
節點名:大包裝轉換比--節點值:aa大包裝轉換比
節點名:中包裝轉換比--節點值:aa中包裝轉換比
節點名:備注--節點值:aa備注
節點名:庫存--節點值:aa庫存
節點名:供應價--節點值:aa供應價
節點名:是否上架--節點值:aa是否上架
=====結束遍歷某一個產品=====
=====開始遍歷某一個產品=====
節點名:產品唯一ID--節點值:a121
節點名:通用名--節點值:b12
節點名:商品名--節點值:c231
節點名:劑型--節點值:dewrwer
節點名:批準文號--節點值:e324324
節點名:規格--節點值:f45645
節點名:包裝說明--節點值:g4543
節點名:包裝單位--節點值:hq324e2
節點名:生產企業--節點值:i76
節點名:大包裝轉換比--節點值:j453
節點名:中包裝轉換比--節點值:k4r43r
節點名:備注--節點值:le4tr4
節點名:庫存--節點值:mq3e2
節點名:供應價--節點值:nefrw
節點名:是否上架--節點值:o56
=====結束遍歷某一個產品=====
智能推薦
XML解析之dom4j
使用dom4j解析xml dom4j是一個組織,針對xml解析,提供了解析器dom4j 導入dom4j的jar包 創建一個文件夾lib 把jar包復制到lib下 右鍵點擊jar包,選擇添加到path 看到jar包變成奶瓶的形狀就可以了 常用的類: SAXReader類 使用這個 類創建一個解析器 new SAXReader() Document read(String systemId) 使用這個...
使用DOM4J解析XML
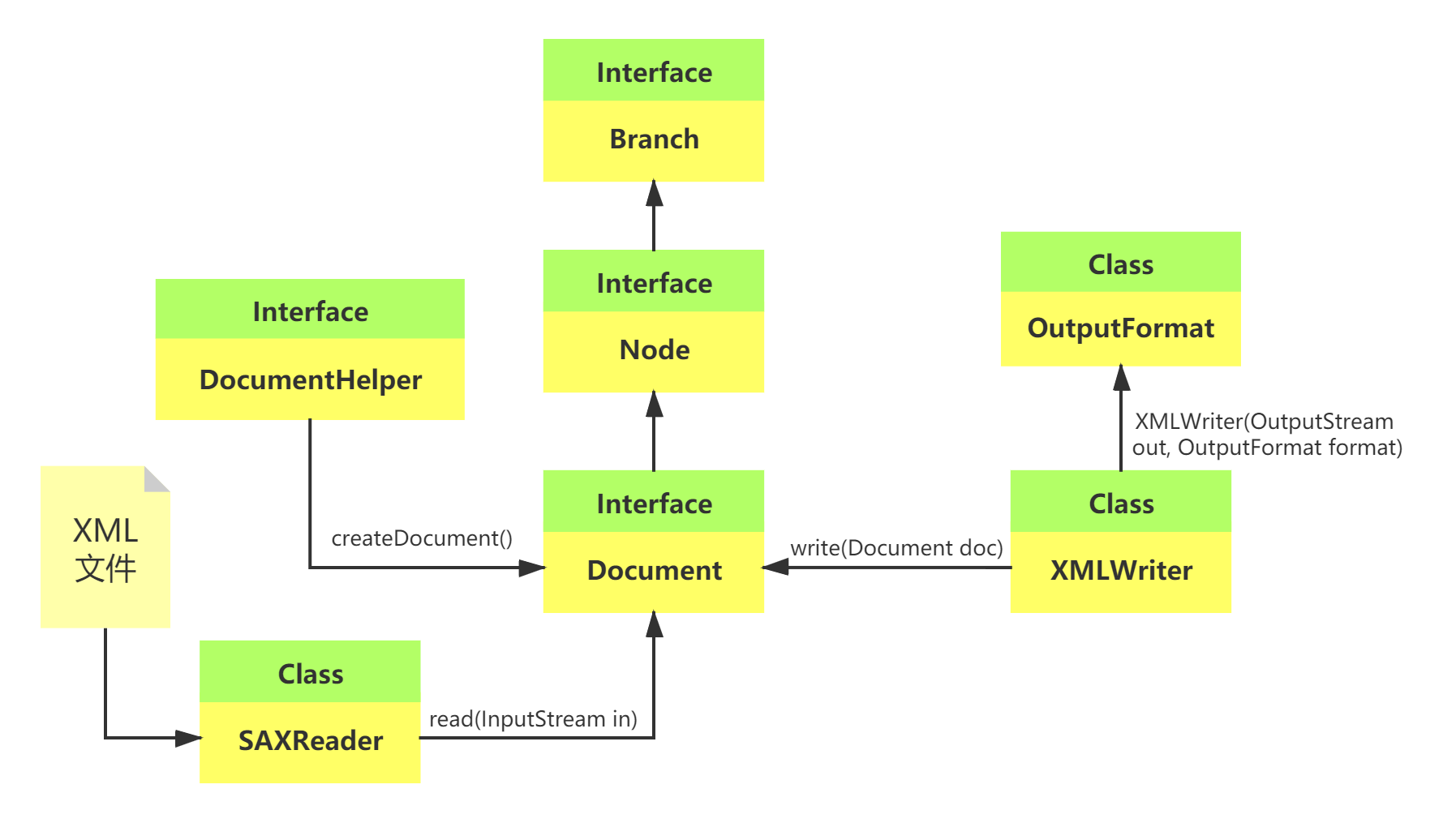
使用DOM4J解析XML DOM4J同時具備了DOM寫入和SAX讀取的操作,并做了存儲優化,使用DOM4J時要導入dom4j的開發包dom4j-x.x.x.jar。 DOM4J提供有自己的一堆實現類庫: DocumentHelper工具類:org.dom4j.DocumentHelper No 返回值 方法名 描述 1 Document createDocument() 創建新的文檔 2 Elem...

dom4j解析xml
一.什么是XML xml:extensive markup language 可擴展的標記語言。如下,就是xml 二.如何解析xml 這邊我使用dom4j解析 1.將dom4j和jaxen架包導進項目 第一步:找到這個標志,并且點擊 第二步: 第三步:選擇jar包 然后點擊apply再點確認jar包就導入完成。 2.建一個類和xml中內容對應 3.寫一個轉換的類 4.最后測試一下...

dom4j解析.xml文件
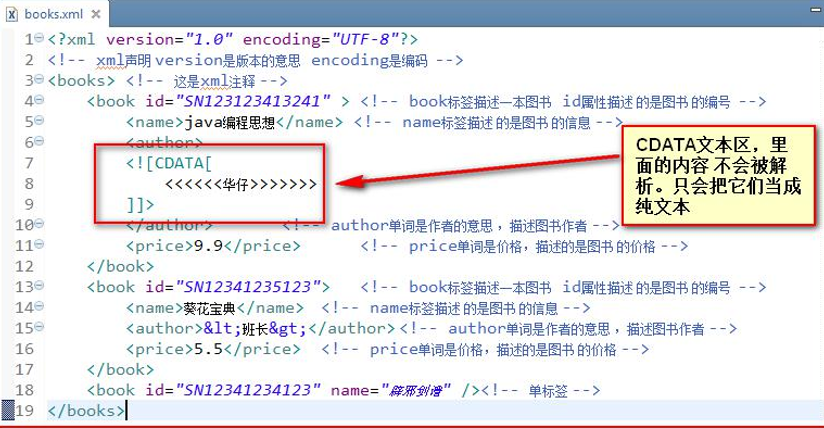
xml 是可擴展的標記性語言。xml 的主要作用有: 1、用來保存數據,而且這些數據具有自我描述性 2、它還可以做為項目或者模塊的配置文件 3、還可以做為網絡傳輸數據的格式(現在 JSON 為主)。 CDATA 語法可以告訴 xml 解析器,我 CDATA 里的文本內容,只是純文本,不需要 xml 語法解析 CDATA 格式: <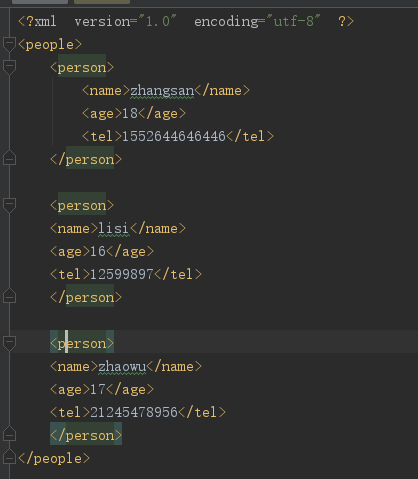
dom4j解析xml
新建java 工程,然后新建lib文件夾,將dom4j的jar包和dtd約束拷貝進來, 然后在src下添加web.xml,添加過程中選擇約束 新建java 類 web.xml ...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...