統計學習方法之樸素貝葉斯理解和代碼復現
標簽: 機器學習
樸素貝葉斯
聯合概率 P(A,B) = P(B|A)*P(A) = P(A|B)*P(B)將右邊兩個式子聯合得到下面的式子:
P(A|B)表示在B發生的情況下A發生的概率。P(A|B) = [P(B|A)*P(A)] / P(B)
直觀理解一下這個式子,如下圖,問題A在我們知道B信息之后概率發生了變化(圖片來自于小白之通俗易懂的貝葉斯定理(Bayes’ Theorem)
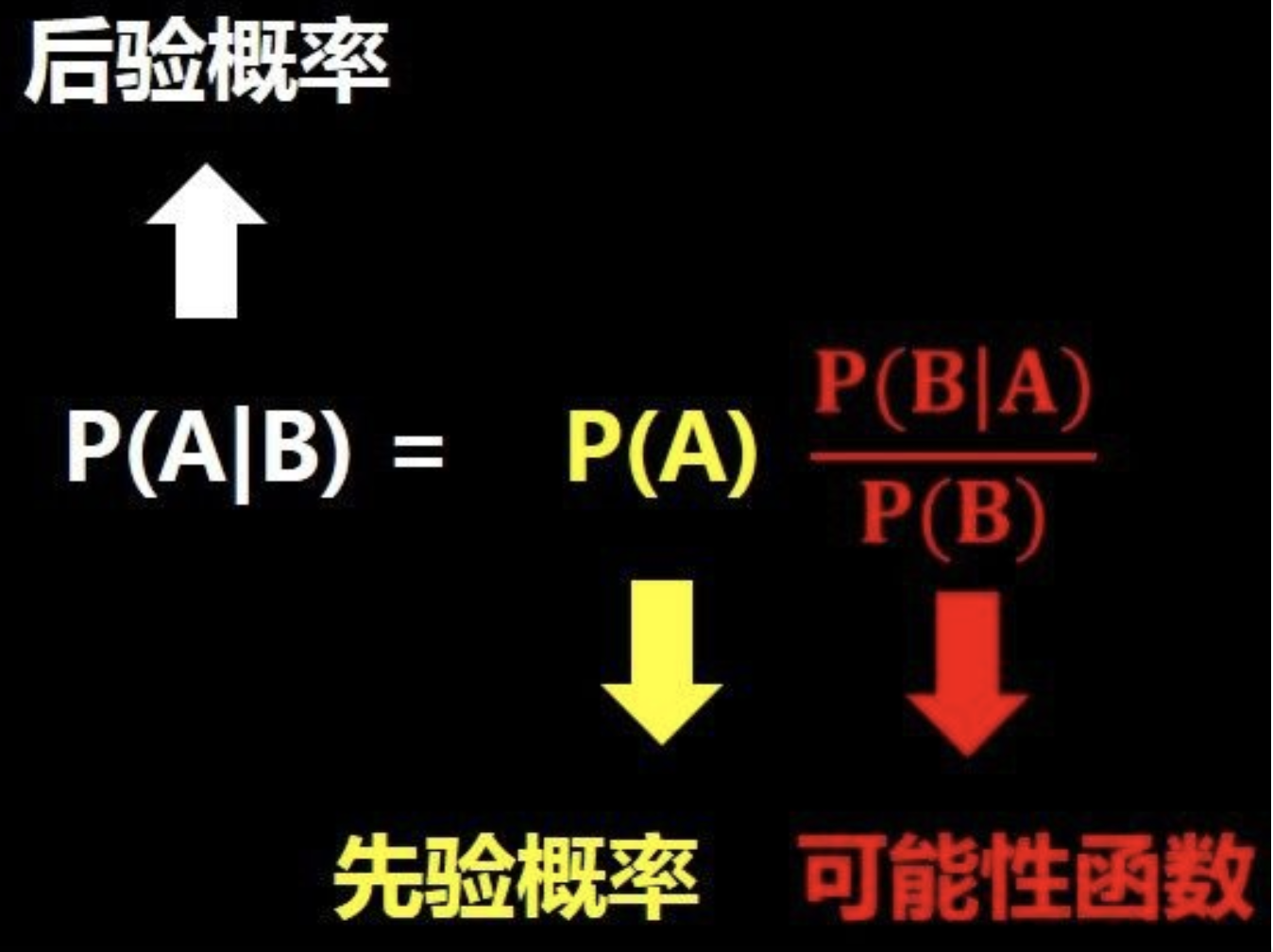
1.后驗概率推導

? 樸素貝葉斯條件:向量X的每一個特征項是獨立同分布,這個條件過于寬泛,但是為了計算簡便,我們嘗試使用一下,用了之后發現效果還不錯,那就用著吧
2.極大似然估計求取分類器y值

? 還記得原先求不同類別下的最大概率這一式子嗎(分類器y)?里面有很多的連乘記得嗎?
? 這里提出了一個問題,那么多概率連乘,如果其中有一個概率為0怎么辦?那整個式子直接就是0了,這樣不對。所以我們連乘中的每一項都得想辦法讓它保證不是0,哪怕它原先是0,(如果原先是0,表示在所有連乘項中它概率最小,那么轉換完以后只要仍然保證它的值最小,對于結果的大小來說沒有影響)這里就使用到了貝葉斯估計。

? 做這種變換是為了每一個概率不為0,從而對于y這個連乘的式子沒有影響,但是為了保持概率值之和依舊為1,才演變成上面的式子
3.例題理解
3.1樸素貝葉斯
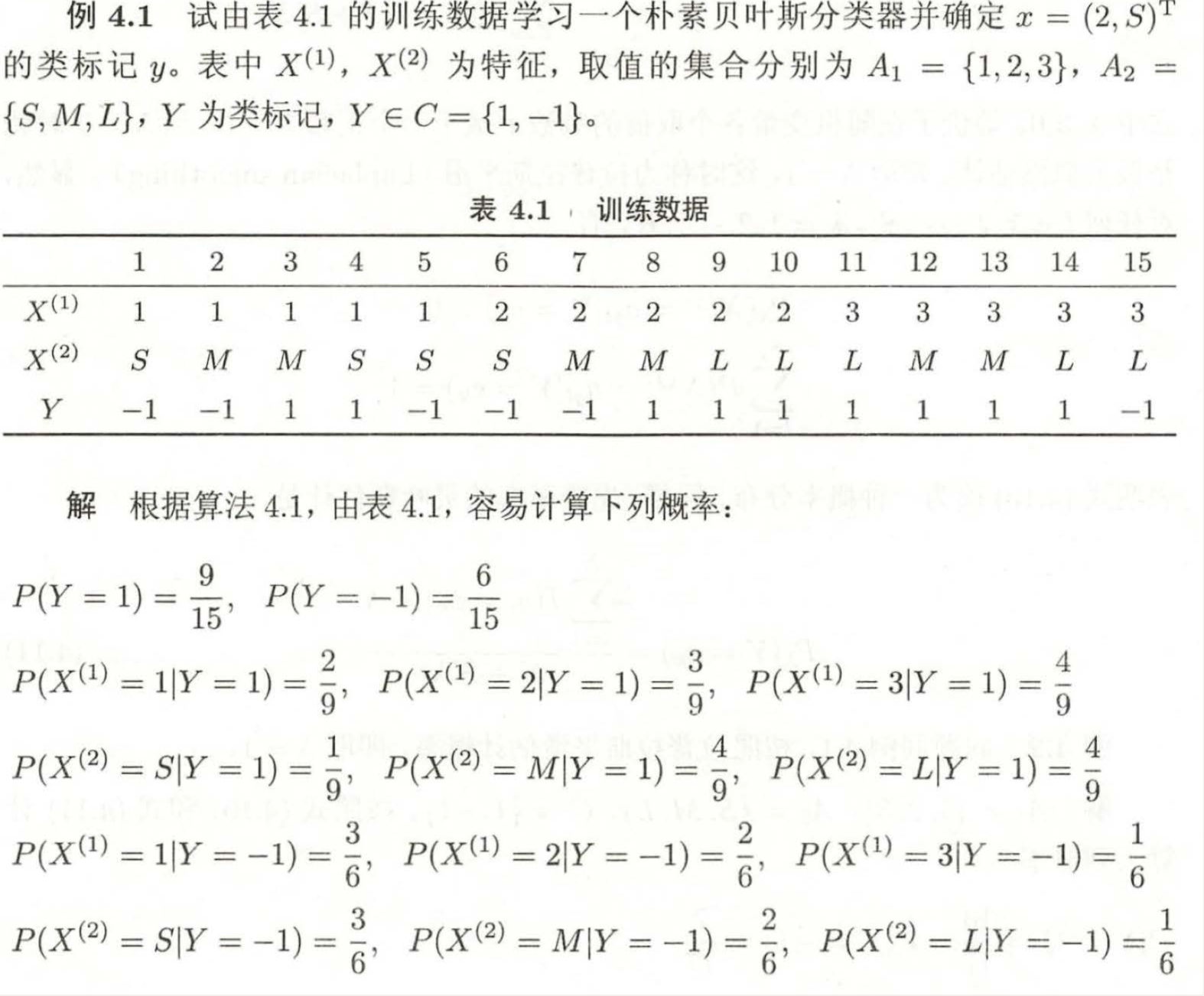
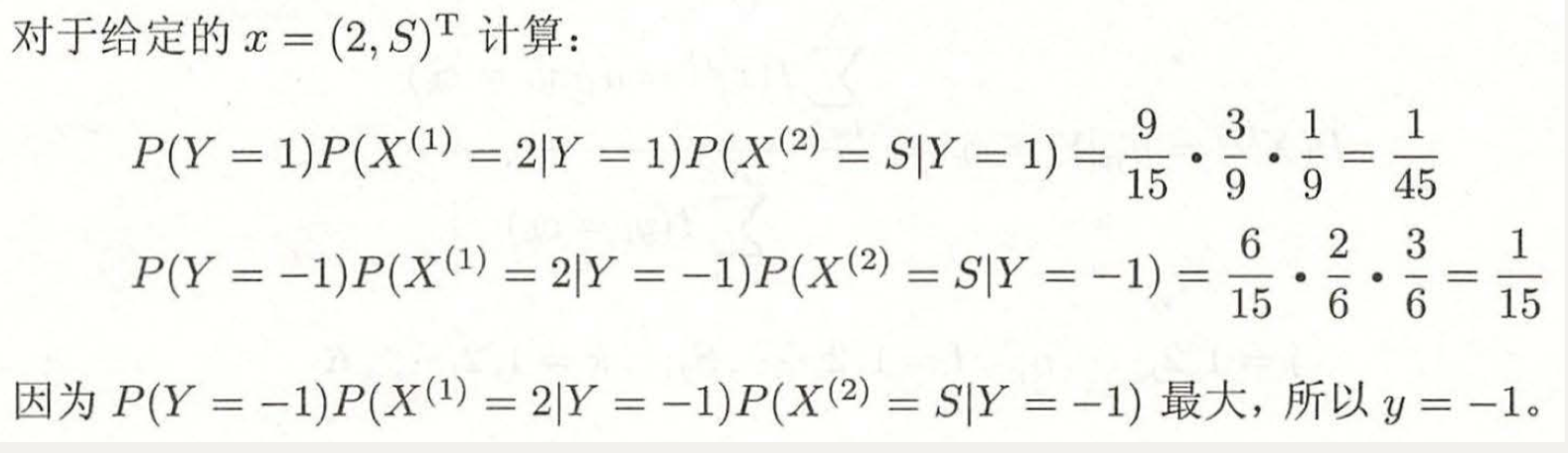
3.2貝葉斯估計

4.補充
? 在實際運用中,不光需要使用貝葉斯估計(保證概率不為0),同時也要取對數(保證連乘結果不下溢出)。
為什么?
? 由于連乘項都是0-1之間的,那很多個(特征個數)0-1之間的數相乘,最后的數一定是非常非常小了,可能無限接近于0。對于程序而言過于接近0的數可能會造成下溢出,也就是精度不夠表達了。所以我們會給整個連乘項取對數,這樣哪怕所有連乘最后結果無限接近0,那取完log以后數也會變得很大(雖然是負的很大),計算機就可以表示了。
取完log以后結果會不會發生變化?
? 答案是不會的。log在定義域內是遞增函數,log(x)中的x也是遞增函數。在單調性相同的情況下,連乘得到的結果大,log取完也同樣大,并不影響不同的連乘結果的大小的比較
5.代碼復現(jupyter)
#下載minist手寫數據集,并加載
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
#X_train.shape is (60000, 28, 28)
#y_train.shape is (60000,)
#我們將數據展開一下
X_train = X_train.reshape(-1 , 28*28)
y_train = y_train.reshape(-1 , 1)
X_test = X_test.reshape(-1 , 28*28)
y_test = y_test.reshape(-1 , 1)
#為了簡便,我們將手寫數據圖片二值化一下
X_train[X_train < 128] = 0
X_train[X_train >= 128] = 1
X_test[X_test < 128] = 0
X_test[X_test >= 128] = 1
import numpy as np
#根據公式計算先驗概率P_y,利用拉普拉斯平滑λ=1,并對連乘公式取log
P_y = np.zeros((10 , 1))
classes = 10
for i in range(classes):
P_y[i] = ((np.sum(y_train == i))+1)/(len(y_train)+classes)
P_y = np.log(P_y)
print(P_y)
#計算條件概率Px_y
#這個模塊實現求取各個特征值的個數
Px_y = np.zeros((classes , X_train.shape[1] , 2))
for i in range(X_train.shape[0]):
k = y_train[i]
x = X_train[i]
for feature in range(X_train.shape[1]):
Px_y[k,feature,x[f]] += 1
#開始計算條件概率Px_y
#
for index in range(classes):
for f in range(X_train.shape[1]):
Px_y[index , f , 0] = (Px_y[index , f , 0] + 1) / (np.sum(y_train == index) + 2)
Px_y[index , f , 1] = (Px_y[index , f , 1] + 1) / (np.sum(y_train == index) + 2)
#為了把連乘變成連加,我們對Px_y取一個log對數
Px_y = np.log(Px_y)
#拿一個出來看看
print(Px_y[0])
#我們預測的最終結果放在predict中
#每一個數據在10個分類器的結果放在res中,取一個argmax就得到一個預測值
predict = np.zeros((y_test.shape[0],1))
for data in range(y_test.shape[0]):
res = np.zeros((classes , 1))
for i in range(classes):
res[i] = P_y[i]
for f in range(X_train.shape[1]):
res[i] += Px_y[i,f,X_test[data,f]]
predict[data] = np.argmax(res)
predict = predict.astype(int)
#取兩個拿出來對比一下
print(predict[:5])
print(y_test[:5])
#預測一下準確率
precision = np.sum(predict == y_test) / y_test.shape[0]
print(precision)
覺得有用就請點個贊吧
參考文章:
李航統計學習方法第二版
統計學習方法|樸素貝葉斯原理剖析及實現
智能推薦
(每天一點點)統計學習方法——樸素貝葉斯法
1、概率論基礎 貝葉斯原理就是求解后驗概率。如果已知p(x|c)要求p(c|x),我們可以使用貝葉斯公式進行求解。 貝葉斯公式: ps:圖片出處 樸素貝葉斯分類器中的樸素指的是特征樣本之間相互獨立。 2、舉個栗子 已在線社區留言板為例子,我們要屏蔽侮辱性言論。對此問題我們建立兩個類別:侮辱性和非侮辱性。我們先定一個詞典,比如[dog,love,cute…],然后把一條留言分成詞向量[...

統計學習方法第四章(樸素貝葉斯)及Python實現及sklearn實現
1原理 樸素貝葉斯 貝葉斯:根據貝葉斯定理p(y|x) = p(y)p(x|y)/p(x).選擇p(y|x) 最大的類別作為x的類別。可知樸素貝葉斯是監督學習的生成模型(由聯合概率分布得到概率分布)。選擇p(y|x) 最大的類別時,分母相同,所以簡化為比較 p(y)p(x|y)的大小。 樸素: 計算p(x|y)的概率,假設x是n維向量,每維向量有sn個取值可能,則就要計算類別*(sn的n次方)次。...

統計學習方法第四章:樸素貝葉斯法(naive Bayes),貝葉斯估計及python實現
統計學習方法第二章:感知機(perceptron)算法及python實現 統計學習方法第三章:k近鄰法(k-NN),kd樹及python實現 統計學習方法第四章:樸素貝葉斯法(naive Bayes),貝葉斯估計及python實現 統計學習方法第五章:決策樹(decision tree),CART算法,剪枝及python實現 統計學習方法第五章:決策樹(decision tree),ID3算法,C...

統計學習筆記六----樸素貝葉斯
前言 樸素貝葉斯(naive Bayes)算法是基于貝葉斯定理和特征條件獨立假設的分類方法,它是一種生成模型! 對于給定的訓練數據集,首先基于特征條件獨立假設學習輸入/輸出的聯合概率分布;然后基于此模型,對給定的輸入x,利用貝葉斯定理求出后驗概率最大的輸出y。 樸素貝葉斯算法實現簡單,學習與預測的效率都很高,是一種常用的方法。 條件獨立性的假設 樸素貝葉斯法對條件概率分布作了條件獨立性...
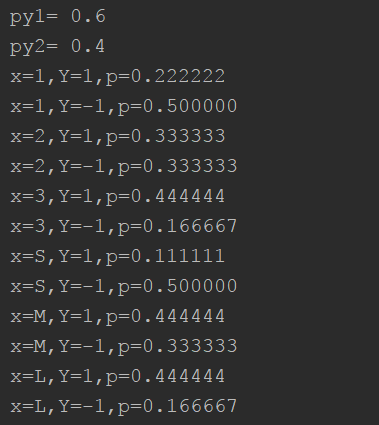
李航統計學樸素貝葉斯例4.1python代碼
關于樸素貝葉斯算法的原理可以參考李航統計學習方法,博客的話,這篇就不錯:https://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html 下面是關于李航一書例題的代碼實現部分: 首先是例4.1不加分類的部分: 先貼結果: 感覺比kd樹好寫很多,上代碼:(新手上路,大神們多指點) ...
猜你喜歡


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...
