《統計學習方法》代碼全解析——第四部分樸素貝葉斯
標簽: 機器學習 深度學習 人工智能 python 神經網絡
1.樸素貝葉斯法是典型的生成學習方法。生成方法由訓練數據學習聯合概率分布 (,) P(X,Y) ,然后求得后驗概率分布 (|) P(Y|X) 。具體來說,利用訓練數據學習 (|) P(X|Y) 和 () P(Y) 的估計,得到聯合概率分布:
(,)=()(|)
概率估計方法可以是極大似然估計或貝葉斯估計。
2.樸素貝葉斯法的基本假設是條件獨立性
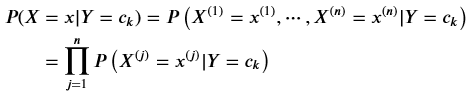
這是一個較強的假設。由于這一假設,模型包含的條件概率的數量大為減少,樸素貝葉斯法的學習與預測大為簡化。因而樸素貝葉斯法高效,且易于實現。其缺點是分類的性能不一定很高。
3.樸素貝葉斯法利用貝葉斯定理與學到的聯合概率模型進行分類預測。
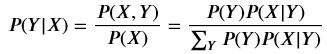
將輸入 分到后驗概率最大的類 。
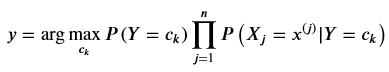
后驗概率最大等價于0-1損失函數時的期望風險最小化。
模型: 高斯模型 多項式模型 伯努利模型
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
import math
# data
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100, :])
# print(data)
return data[:,:-1], data[:,-1]
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
X_test[0], y_test[0]
class NaiveBayes:
def __init__(self):
self.model = None
# 數學期望
@staticmethod
def mean(X):
return sum(X) / float(len(X))
# 標準差(方差)
def stdev(self, X):
avg = self.mean(X)
return math.sqrt(sum([pow(x - avg, 2) for x in X]) / float(len(X)))
# 概率密度函數
def gaussian_probability(self, x, mean, stdev):
exponent = math.exp(-(math.pow(x - mean, 2) /
(2 * math.pow(stdev, 2))))
return (1 / (math.sqrt(2 * math.pi) * stdev)) * exponent
# 處理X_train
def summarize(self, train_data):
summaries = [(self.mean(i), self.stdev(i)) for i in zip(*train_data)]
return summaries
# 分類別求出數學期望和標準差
def fit(self, X, y):
labels = list(set(y))
data = {label: [] for label in labels}
for f, label in zip(X, y):
data[label].append(f)
self.model = {
label: self.summarize(value)
for label, value in data.items()
}
return 'gaussianNB train done!'
# 計算概率
def calculate_probabilities(self, input_data):
# summaries:{0.0: [(5.0, 0.37),(3.42, 0.40)], 1.0: [(5.8, 0.449),(2.7, 0.27)]}
# input_data:[1.1, 2.2]
probabilities = {}
for label, value in self.model.items():
probabilities[label] = 1
for i in range(len(value)):
mean, stdev = value[i]
probabilities[label] *= self.gaussian_probability(
input_data[i], mean, stdev)
return probabilities
# 類別
def predict(self, X_test):
# {0.0: 2.9680340789325763e-27, 1.0: 3.5749783019849535e-26}
label = sorted(
self.calculate_probabilities(X_test).items(),
key=lambda x: x[-1])[-1][0]
return label
def score(self, X_test, y_test):
right = 0
for X, y in zip(X_test, y_test):
label = self.predict(X)
if label == y:
right += 1
return right / float(len(X_test))scikit-learn實例
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
clf.predict([[4.4, 3.2, 1.3, 0.2]])
智能推薦

統計學習方法學習筆記3——樸素貝葉斯模型
樸素貝葉斯屬于:概率模型、參數化模型、和生成模型 目錄 1.樸素貝葉斯基本方法 2.后驗概率最大化的含義 3.樸素貝葉斯算法: 樸素貝葉斯python實現4.1: 樸素貝葉斯sklearn實現作業4.1 貝葉斯的優缺點: 1.樸素貝葉斯基本方法 2.后驗概率最大化的含義 3.樸素貝葉斯算法: 樸素貝葉斯python實現4.1: 結果: 樸素貝葉斯sklearn實現作業4.1 貝葉斯的優缺點: 由于...
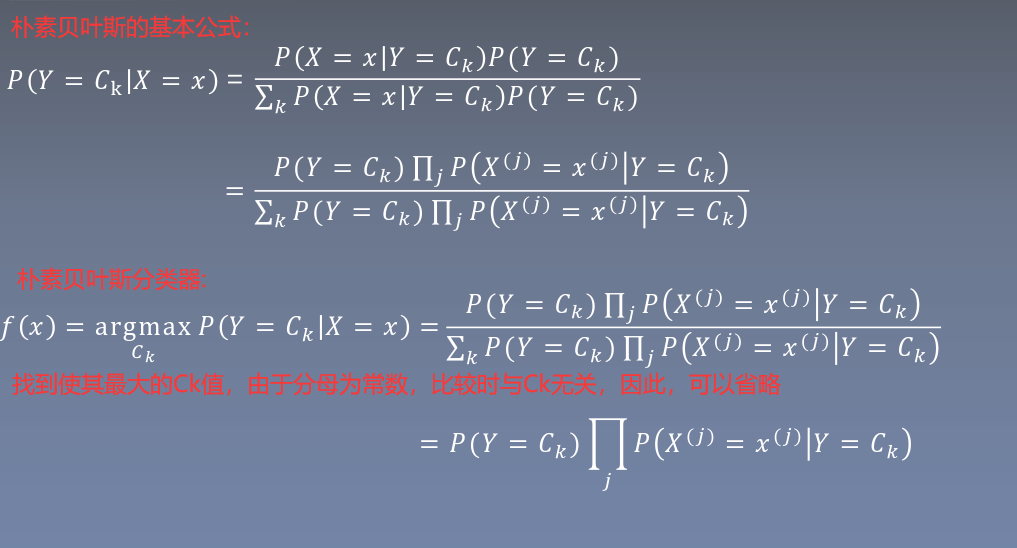
統計學習方法讀書筆記8-樸素貝葉斯
文章目錄 1.樸素貝葉斯的基本方法 2.樸素貝葉斯的參數估計 1.極大似然估計 2.樸素貝葉斯算法 3.貝葉斯估計 3.后驗概率最大化-期望風險最小化 4.樸素貝葉斯代碼實現 1.樸素貝葉斯的基本方法 2.樸素貝葉斯的參數估計 1.極大似然估計 2.樸素貝葉斯算法 3.貝葉斯估計 用極大似然估計可能出現所要估計的概率值為0的情況,這是會影響到后驗概率的計算結果,使分類產生偏差。解決這一問題的方法就...
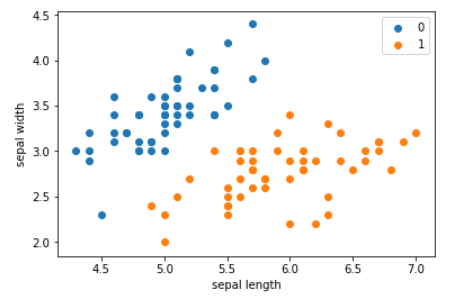
《統計學習方法》代碼全解析——第三部分k近鄰法
1. 近鄰法是基本且簡單的分類與回歸方法。 k 近鄰法的基本做法是:對給定的訓練實例點和輸入實例點,首先確定輸入實例點的 個最近鄰訓練實例點,然后利用這 個訓練實例點的類的多數來預測輸入實例點的類。 2. 近鄰模型對應于基于訓練數據集對特征空間的一個劃分。 k 近鄰法中,當訓練集、距離度量、 值及分類決策規則確定后,其結果唯一確定。 3....
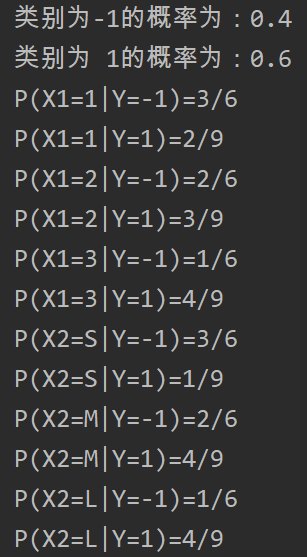
樸素貝葉斯(naive Bayes)的python實現——基于《統計學習方法》例題的編程求解
樸素貝葉斯方法是基于貝葉斯定理與特征條件獨立假設的分類方法。認為樣本的特征X與標簽y服從聯合概率分布P(X, y),所有的樣本都是基于這個概率分布產生的。由于條件概率P(X=x|Y=y)的參數具有指數數量級,因此進行估算切實際。貝葉斯法對條件概率分布做了條件獨立性假設,從而減少了模型的復雜性,增加了模型的泛化能力,減少了過擬合的風險。 #后驗概率最大化 可以證明,期望風險最小化準則可以得到后驗概率...
(每天一點點)統計學習方法——樸素貝葉斯法
1、概率論基礎 貝葉斯原理就是求解后驗概率。如果已知p(x|c)要求p(c|x),我們可以使用貝葉斯公式進行求解。 貝葉斯公式: ps:圖片出處 樸素貝葉斯分類器中的樸素指的是特征樣本之間相互獨立。 2、舉個栗子 已在線社區留言板為例子,我們要屏蔽侮辱性言論。對此問題我們建立兩個類別:侮辱性和非侮辱性。我們先定一個詞典,比如[dog,love,cute…],然后把一條留言分成詞向量[...
猜你喜歡
第四部分-Challenge
文章目錄 54.less54-Challenge-1 54.1、注入解析--十次刷新 54.2、代碼賞析 55.less55-Challenge-2 56.less56-Challenge-3 57.less57-Challenge-4 58.less58-Challenge-5 59.less59-Challenge-6 60.less60-Challenge-7 61.less61-Chall...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...