Mysql深度講解InnoDB引擎與Index索引(四)
前言
上篇【Mysql深度講解InnoDB引擎與Index索引(三)】已經從理論上說明了索引能夠對我們查詢的效率起到比較大的幫助,以及一些基本的索引創建原則,那么有沒有一個比較好的辦法直觀的比較兩個索引的效率呢?當然是有的,它就是索引的選擇性,本篇就聊聊如何建一個高效的索引。注:本篇創建的表和索引在附錄里,請對照觀看。更多Mysql調優內容請點擊【Mysql優化-深度講解系列目錄】。
選擇性
一般來說要建一個高效的索引,首先要看這個列里面的重復值是否很多,索引需要基于不重復的值才能達到最高效率,過濾哪些列能夠建索引的指標就叫做索引的選擇性(Selectivity)。選擇性的計算簡單來說是指不重復的索引值(也叫基數,Cardinality)與表記錄數的比值:
索引選擇性 = 基數 / 記錄數
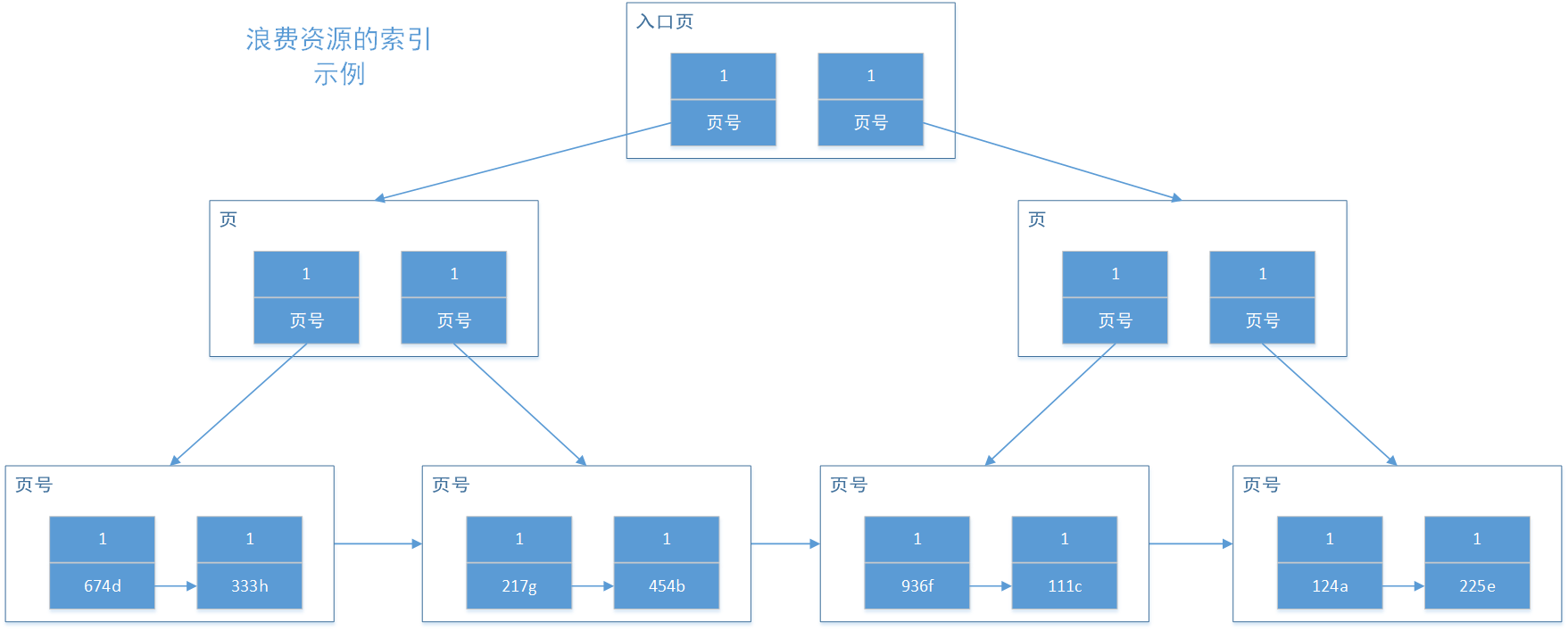
選擇性的取值范圍為(0, 1],選擇性越高的索引價值越大。如果選擇性等于1,就代表這個列的不重復值和表記錄數是一樣的,也就是說該列沒有重復值,那么對這個列建立索引是非常合適的。如果選擇性非常小,那么就代表這個列的重復值是很多的, 不適合建立索引。也就是選擇性越大(越接近1),索引的效率越高。如下建了一個B+樹父節點都相同的索引,完全沒有任何意義。
索引的空間
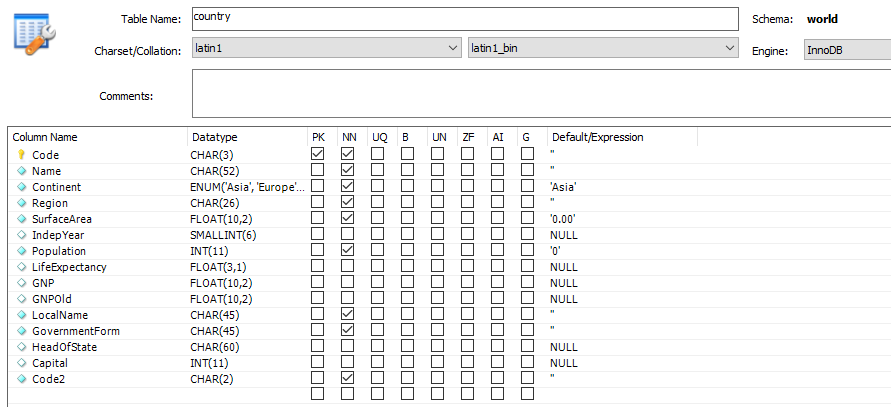
比如設想這樣一張表:country表只有一個主鍵索引PRIMARY(此表為Mysql自帶的表)。
在目前的條件下我想查詢一個國家的名字(Name字段)對應的國家的政體(GovernmentForm字段),只能進行全表掃描,比如:
explain select name,GovernmentForm from country;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | country | NULL | ALL | NULL | NULL | NULL | NULL | 239 | 100.00 | NULL |
那么可以對或建立索引,看下兩個索引的選擇性:
SELECT count(DISTINCT(concat(GovernmentForm)))/count(*) AS Selectivity FROM country; -- 0.1464
SELECT count(DISTINCT(concat(name,GovernmentForm)))/count(*) AS Selectivity FROM country; -- 1.0000
可以看到,如果我們選擇只針對GovernmentForm做索引,選擇性是非常低的只有0.1464。如果對Name和GovernmentForm做一個聯合索引,那么選擇性就直接飆到了最高1。但是還有一個問題,可以看到表設計里面Name字段是char類型Latin字符集占用了52Byte,而GovernmentForm字段占用的也不少有45Byte。這樣索引一個節點的長度就有可能達到97Byte,我們如果建立了這樣一個全值索引,需要的容量開銷也是不小的。有沒有辦法做到選擇性非常高,而占用的空間有比較小的辦法呢?
前綴索引
上面的問題,是可以解決的,即前綴索引。這里的前綴索引,并不是之前說的最左原則。而是對某一列的前幾個字符進行創建索引,就是用列的前綴代替整個列作為索引key。當前綴長度合適時,可以做到既使得前綴索引的選擇性接近全列索引,同時因為索引key變短而減少了索引文件的大小和維護開銷。根據這個前綴索引的策略,我們選擇使用Name的前10Byte和GovernmentForm的前10Btye構建一個前綴索引,首先先看下選擇性:
SELECT count(DISTINCT(concat(left(name,10),left(GovernmentForm,10))))/count(*) AS Selectivity FROM country; -- 1.0000
選擇性依然是無比強大的1,但是我們索引的節點長度最大值已經減小為20Byte了,幾乎縮小了5倍,但是選擇性依然是1。那么如何建一個前綴索引呢?使用如下語法就可以了,本例中指定索引字段的長度為10即可。
ALTER TABLE country ADD INDEX `idx_cty_nm_gf` (name(10),GovernmentForm(10));
但是前綴索引兼顧索引大小和查詢速度,但是其缺點是不能用于ORDER BY和GROUP BY操作,也不能用于覆蓋索引。因為這個兩個關鍵字都是對完整的列值進行排序和查找的,前綴索引由于缺乏了部分數據,因而無法應用于這些關鍵字的查詢。
覆蓋索引
所謂的覆蓋索引是指一個查詢的狀態,說的是一個查詢語句中所有查詢的列,和所有條件(where, in, join等等)涉及的列都可以利用索引,也就是被索引覆蓋掉。這種查詢稱為覆蓋索引,并不單單指聚簇索引,或者二級索引,也可以指二者通用,只要這次查詢的結果不需要進行回表操作,一般來說就可以被稱為覆蓋索引查詢。這點可以用explain關鍵字返回的Extra列看出來,覆蓋索引Extra列顯示的是‘Using index’。
回表
再介紹更多索引操作的時候,先說下什么叫做回表。之前幾篇文章已經分析過,輔助索引找出來的最終是主鍵,通過主鍵再去主鍵索引里面查找真實的數據,這個過程就被稱作回表。基本上Mysql通過二級索引查詢都需要需要進行回表操作。
匹配范圍值
select * from t1 where b > 1 and b < 20000;
由于我們建立的B+樹中的數據頁和記錄是先按 b列 排序的,所以我們上邊的查詢過程其實是這樣的:
- 首先找到 b列 值為1的記錄。
- 然后找到 b列 值為20000的記錄。
- 由于所有記錄都是由鏈表連起來的(記錄之間用單鏈表,數據頁之間用雙鏈表),所以他們之間的記錄都可以很容易的取出來。
- 找到這些記錄的主鍵值,再到聚簇索引中回表查找完整的記錄。
不過在使用聯合進行范圍查找的時候需要注意,如果對多個列同時進行范圍查找的話,只有對索引最左邊的那個 列進行范圍查找的時候才能用到B+樹索引,比如:
select * from t1 where b > 1 and c > 1;
上邊這個查詢可以分成兩個部分:
- 通過條件
b > 1來對b進行范圍,查找的結果可能有多條b值不同的記錄。 - 對這些b值不同的記錄繼續通過
c > 1繼續過濾。
這樣子對于聯合索引來說,只能用到 b列 的部分,而用不到 c列 的部分,因為只有b值相同的情況下才能用 c列 的值 進行排序,而這個查詢中通過 b列 進行范圍查找的記錄中可能并不是按照 c列 進行排序的,所以在搜索條件中繼續以 c列 進行查找時是用不到這個B+樹索引的。
精確匹配某一列并發未匹配另一列
對于同一個聯合索引來說,雖然對多個列都進行范圍查找時只能用到最左邊那個索引列,但是如果左邊的列是精確查找,則右邊的列可以進行范圍查找。比如下面的sql,當b=1確定一個結果集以后,那么c>1就可以利用索引idx_t1_bcd了。
select * from t1 where b = 1 and c > 1;
排序 order by
例如一個排序sql是如何利用索引的呢?
select * from t1 order by b, c, d;
這個查詢的結果集需要先按照 b列 值排序,如果記錄的 b列 值相同,則需要按照 c列 來排序,如果 c列 的值相同,則需要按照 d列 排序。因為這個B+樹索引本身就是按照上述規則排好序的,所以直接從索引中提取數據,然后進行回表操作取出該索引中不包含的列就好了。
分組 group by
分組利用索引的方式和排序類似,比如:
select b, c, d, count(*) from t1 group by b, c, d;
這個查詢語句相當于做了3次分組操作:
- 先把記錄按照 b列 值進行分組,所有 b列 值相同的記錄劃分為一組。
- 將每個 b列 值相同的分組里的記錄再按照 c列 的值進行分組,將 c列 值相同的記錄放到一個分組里。
- 再將上一步中產生的分組按照 d列 的值分成更小的分組。
如果沒有索引的話,這個分組過程全部需要在內存里實現,而如果有索引的話,正好這個分組順序又和B+樹中的索引列的順序是一致的,所以可以直接使用B+樹索引進行分組。但是對于聯合索引有個問題需要注意,ORDER BY的子句后邊的列的順序也必須按照索引列的順序給出,如果給出 order by c, b, d 的順序,也是用不了B+樹索引的。同理, order by b或者order by b, c 這種匹配索引左邊的列的形式可以使用部分的B+樹索引。當聯合索引 左邊列的值為常量,也可以使用后邊的列進行排序,比如這樣:
select * from t1 where b = 1 order by c, d;
這個查詢能使用聯合索引進行排序是因為 b列 的值相同的記錄是按照 c列, d列 排序的。
ASC & DECS索引
對于使用聯合索引進行排序的場景,我們要求各個排序列的排序順序是一致的,也就是要么各個列都是ASC規則 排序,要么都是DESC規則排序。ORDER BY子句后的列如果不加ASC或者DESC默認是按照ASC排序規則排序的,也就是升序排序的,比如下面這個查詢就是用不到索引的。
select * from t1 order by b ASC, c DESC;
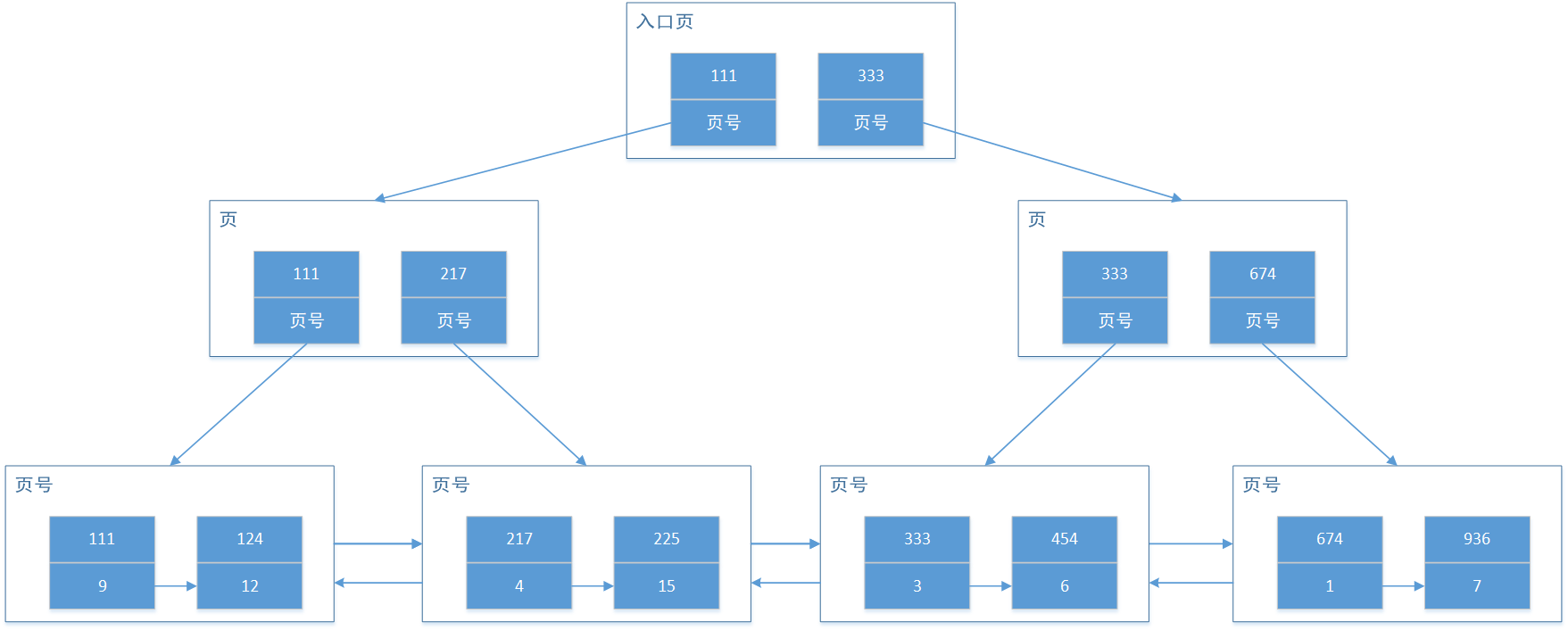
說到了ASC和DECS關鍵字,InnoDB中的索引并不單單是一個B+樹,而是一個B+樹的變種,因為其最后的葉子指針是一個雙向指針,用來快速查找逆序,如下圖。
修改默認的索引(index hint)
修改使用索引use關鍵字:
explain select * from t1 use index(idx_t1_bcd) where a=1 and b=6;
如果use index(idx_t1_bcd)里面指定了索引,那么就會使用那個索引。而且這個語法里可以寫多個索引,查詢優化器只會根據指定的索引進行成本的計算。本例中就是只會用并且計算idx_t1_bcd的結果,即便有其他的索引也不會使用。
與之類似的force關鍵字:
explain select * from t1 force index(idx_t1_bcd) where a=1 and b=6;
強制使用某個索引,這里只能指定使用一個索引。
忽略索引ignore關鍵字:
explain select * from t1 ignore index(idx_t1_bcd) where a=1 and b=6;
忽略使用某個索引,這里能指定忽略多個索引。
總結
總之建立索引的規律就是:
- 索引列的類型盡量小
- 利用索引字符串值的前綴
- 主鍵自增
- 定位并刪除表中的重復和冗余索引
- 盡量使用覆蓋索引進行查詢,避免回表帶來的性能損耗。
附:本例中構建的表:
create table t1(
a int primary key,
b int,
c int,
d int,
e varchar(20)
) engine=InnoDB;
create index idx_t1_bcd on t1(b,c,d);
insert into t1 values(12,1,2,4,'a');
insert into t1 values(6,4,5,4,'b');
insert into t1 values(9,1,1,1,'c');
insert into t1 values(1,6,7,4,'d');
insert into t1 values(15,2,2,5,'e');
insert into t1 values(7,9,3,6,'f');
insert into t1 values(4,2,1,7,'g');
insert into t1 values(3,3,3,3,'h');
insert into t1 values(10,5,5,5,'ss');
create table t2(
a int primary key,
b int,
c int,
d int,
e varchar(20)
) engine=InnoDB;
insert into t2 values(1,6,7,4,'d');
insert into t2 values(4,2,1,7,'g');
insert into t2 values(3,3,3,3,'h');
智能推薦
InnoDB存儲引擎(五)索引與算法
目錄 5.1 概述 5.2 數據結構與算法 5.2.1 二分查找法 5.2.2 二叉查找樹和平衡二叉樹 5.2.3 B+樹 5.3 B+樹索引 5.3.1 聚集索引和非聚集索引 5.3.2 B+樹索引的使用 聯合索引 覆蓋索引 優化 5.4 B+樹索引的分裂 5.5 Cardinality值 5.6 全文索引 5.1 概述 InnoDB支持以下幾種常見的索引: B+樹索引 全文索引 ...
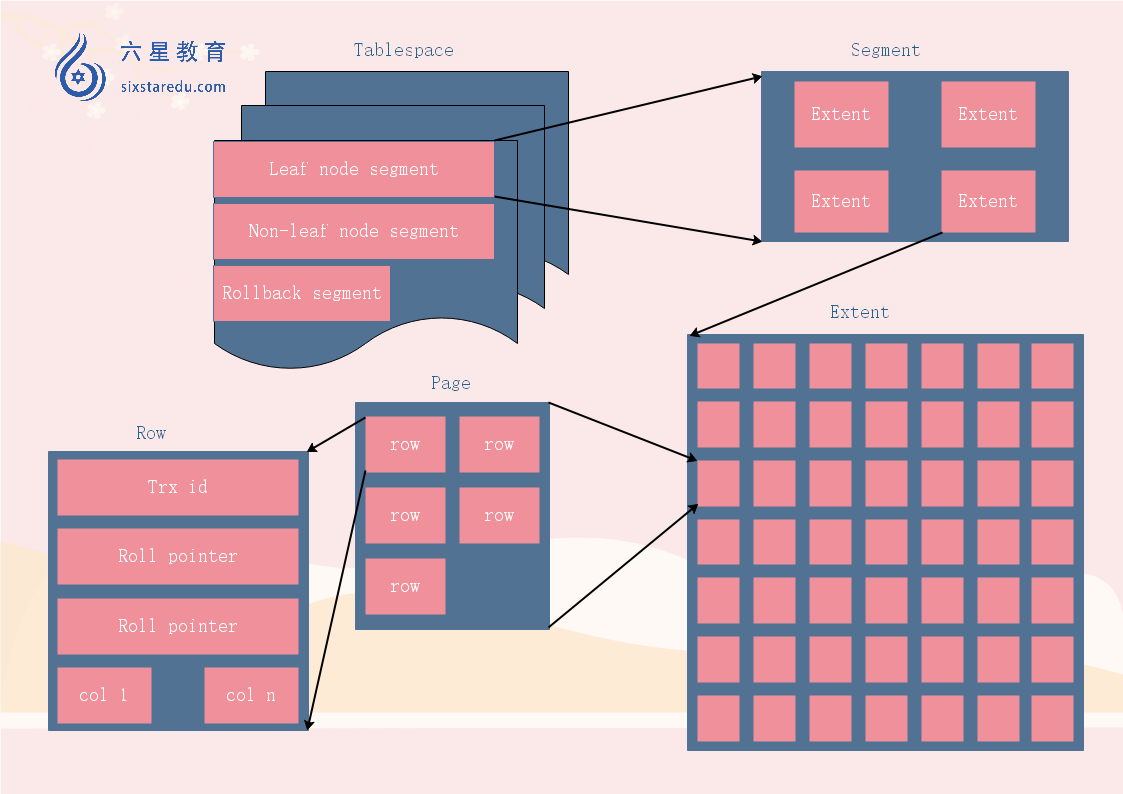
mysql索引與innodb結構
mysql索引與innodb結構 一、innodb存儲引擎結構 1. 簡介 2. innodb是如何去存儲數據的 3. innodb緩存池 (innodb_buffer_pool) 數據頁(data page) 索引頁 lru算法 二、什么是索引 1. mysql中的索引類型 1.1 索引術語 2. btree結構 2.1 二分法: 2.2 二叉樹 三、sql-io--索引執行流程 四、b+tre...

MySQL · 引擎特性 · InnoDB index lock前世今生
前言 InnoDB并發過程中使用兩類鎖進行同步。 1. 事務鎖 維護在不同的Isolation level下數據庫的Atomicity和Consistency兩大基本特性。 InnoDB定義了如下的lock mode: 2. 內存鎖 為了維護內存結構的一致性,比如Dictionary cache、sync array、trx system等結構。 InnoDB并沒有直接使用glibc提供的庫,而是...

MySQL數據庫索引與事務、存儲引擎MyISAM和InnoDB
MySQL數據庫索引與事務、存儲引擎MyISAM和InnoDB 索引 1、數據庫中的索引與書籍的目錄類似 ●在一本書中,無須閱讀整本書,利用目錄就可以快速查找所需信息 ●書中的目錄是一個詞語列表,其中注明了包含各個詞的頁碼 2、數據庫索引 ●在數據庫中,索引使數據庫程序無須對整個表進行掃描,就可以在其中找到所需數據 ●數據庫中的索引是某個表中一列或者若干列值的集合,以及物理標識這些值的數據頁的邏輯...
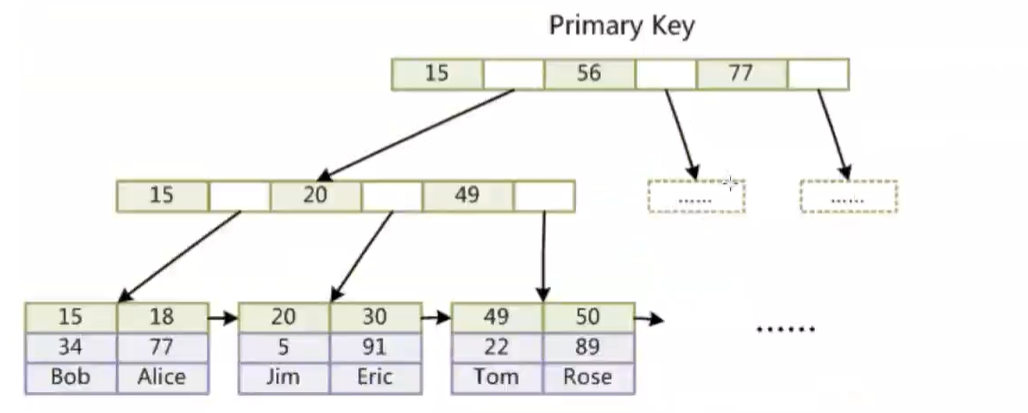
關于MySQL索引及InnoDB與MyISAM引擎的區別的學習筆記
1.索引 ·對表中一列或多列的值進行排序 ·定義一種存儲結構 ·快速檢索到數據 ·存儲引擎級實現,不同存儲引擎實現索引的機制是不一樣的 2.索引類型 ·普通索引:基本索引類型,沒什么限制,允許重復值和空值 ·唯一索引:索引列的值必須是唯一的,但允許空值 ·主鍵索引:不允許有空值的唯一索引 &middo...
猜你喜歡
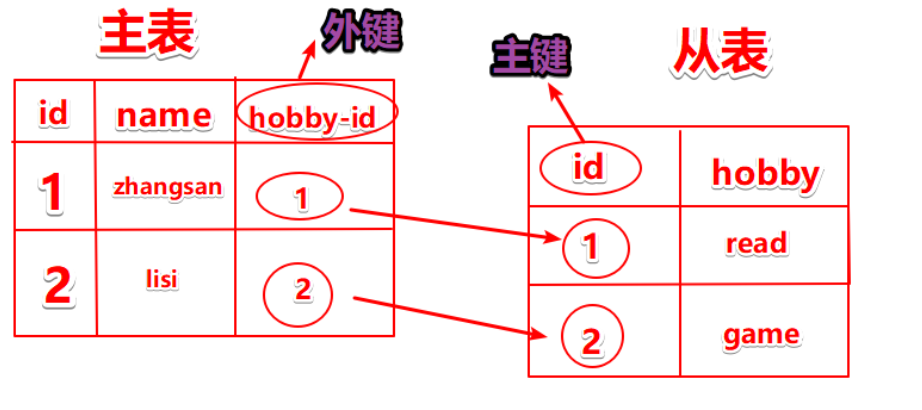
MySQL——索引與事務、視圖、存儲過程(軟件開發)、 存儲引擎MylSAM和InnoDB
文章目錄 一、索引 1、索引的概念 2、索引的作用 3、索引的分類 4、創建索引的原則依據 5、創建索引的方法 6、索引示例 二、事務 1、事務的概念 2、事務的ACID特點 3、事務的操作 1)事務處理命令控制事務 2)使用set命令進行控制 4、事務示例 三、視圖 1、概念 2、視圖作用 3、視圖示例 四、存儲過程(軟件開發方向) 五、存儲引擎 1、存儲引擎的概念 2、MyISAM 1)MyI...
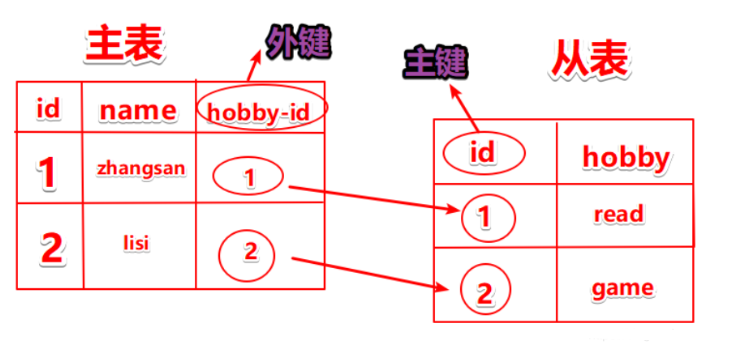
MySQL——索引與事務、存儲過程(軟件開發)、 存儲引擎MylSAM和InnoDB
文章目錄 一、索引 1、索引的概念 2、索引的作用 3、索引的分類 4、創建索引的原則依據 5、創建索引的方法 6、索引示例 二、事務 1、事務的概念 2、事務的ACID特點 3、事務的操作 4、事務示例 三、存儲過程(軟件開發方向) 四、存儲引擎 1、存儲引擎的概念 2、MyISAM 3、MyISAM使用的生產場景 4、InnoDB 5、企業選擇存儲引擎依據 6、配置存儲引擎 6、修改存儲引擎 ...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...