結合代碼詳細聊聊 Java 網絡編程中的 BIO、NIO 和 AIO
本文從操作系統的角度來解釋BIO,NIO,AIO的概念,含義和背后的那些事。本文主要分為3篇。
-
第一篇 講解BIO和NIO以及IO多路復用
-
第二篇 講解磁盤IO和AIO
-
第三篇 講解在這些機制上的一些應用的實現方式,比如nginx,nodejs,Java NIO等
到底什么是“IO Block”
很多人說BIO不好,會“block”,但到底什么是IO的Block呢?考慮下面兩種情況:
-
用系統調用
read從socket里讀取一段數據 -
用系統調用
read從一個磁盤文件讀取一段數據到內存
如果你的直覺告訴你,這兩種都算“Block”,那么很遺憾,你的理解與Linux不同。Linux認為:
-
對于第一種情況,算作block,因為Linux無法知道網絡上對方是否會發數據。如果沒數據發過來,對于調用
read的程序來說,就只能“等”。 -
對于第二種情況,不算做block。
是的,對于磁盤文件IO,Linux總是不視作Block。
你可能會說,這不科學啊,磁盤讀寫偶爾也會因為硬件而卡殼啊,怎么能不算Block呢?但實際就是不算。
一個解釋是,所謂“Block”是指操作系統可以預見這個Block會發生才會主動Block。例如當讀取TCP連接的數據時,如果發現Socket buffer里沒有數據就可以確定定對方還沒有發過來,于是Block;而對于普通磁盤文件的讀寫,也許磁盤運作期間會抖動,會短暫暫停,但是操作系統無法預見這種情況,只能視作不會Block,照樣執行。
基于這個基本的設定,在討論IO時,一定要嚴格區分網絡IO和磁盤文件IO。NIO和后文講到的IO多路復用只對網絡IO有意義。
嚴格的說,O_NONBLOCK和IO多路復用,對標準輸入輸出描述符、管道和FIFO也都是有效的。但本文側重于討論高性能網絡服務器下各種IO的含義和關系,所以本文做了簡化,只提及網絡IO和磁盤文件IO兩種情況。
本文先著重講一下網絡IO。
BIO
有了Block的定義,就可以討論BIO和NIO了。BIO是Blocking IO的意思。在類似于網絡中進行read, write, connect一類的系統調用時會被卡住。
舉個例子,當用read去讀取網絡的數據時,是無法預知對方是否已經發送數據的。因此在收到數據之前,能做的只有等待,直到對方把數據發過來,或者等到網絡超時。
對于單線程的網絡服務,這樣做就會有卡死的問題。因為當等待時,整個線程會被掛起,無法執行,也無法做其他的工作。
順便說一句,這種Block是不會影響同時運行的其他程序(進程)的,因為現代操作系統都是多任務的,任務之間的切換是搶占式的。這里Block只是指Block當前的進程。
于是,網絡服務為了同時響應多個并發的網絡請求,必須實現為多線程的。每個線程處理一個網絡請求。線程數隨著并發連接數線性增長。這的確能奏效。實際上2000年之前很多網絡服務器就是這么實現的。但這帶來兩個問題:
-
線程越多,Context Switch就越多,而Context Switch是一個比較重的操作,會無謂浪費大量的CPU。
-
每個線程會占用一定的內存作為線程的棧。比如有1000個線程同時運行,每個占用1MB內存,就占用了1個G的內存。
也許現在看來1GB內存不算什么,現在服務器上百G內存的配置現在司空見慣了。但是倒退20年,1G內存是很金貴的。并且,盡管現在通過使用大內存,可以輕易實現并發1萬甚至10萬的連接。但是水漲船高,如果是要單機撐1千萬的連接呢?
問題的關鍵在于,當調用read接受網絡請求時,有數據到了就用,沒數據到時,實際上是可以干別的。使用大量線程,僅僅是因為Block發生,沒有其他辦法。
當然你可能會說,是不是可以弄個線程池呢?這樣既能并發的處理請求,又不會產生大量線程。但這樣會限制最大并發的連接數。比如你弄4個線程,那么最大4個線程都Block了就沒法響應更多請求了。
要是操作IO接口時,操作系統能夠總是直接告訴有沒有數據,而不是Block去等就好了。于是,NIO登場。
NIO
NIO是指將IO模式設為“Non-Blocking”模式。在Linux下,一般是這樣:
void setnonblocking(int fd) {
int flags = fcntl(fd, F_GETFL, 0);
fcntl(fd, F_SETFL, flags | O_NONBLOCK);
}
再強調一下,以上操作只對socket對應的文件描述符有意義;對磁盤文件的文件描述符做此設置總會成功,但是會直接被忽略。
這時,BIO和NIO的區別是什么呢?
在BIO模式下,調用read,如果發現沒數據已經到達,就會Block住。
在NIO模式下,調用read,如果發現沒數據已經到達,就會立刻返回-1, 并且errno被設為EAGAIN。
在有些文檔中寫的是會返回
EWOULDBLOCK。實際上,在Linux下EAGAIN和EWOULDBLOCK是一樣的,即#define EWOULDBLOCK EAGAIN
于是,一段NIO的代碼,大概就可以寫成這個樣子。
struct timespec sleep_interval{.tv_sec = 0, .tv_nsec = 1000};
ssize_t nbytes;
while (1) {
/* 嘗試讀取 */
if ((nbytes = read(fd, buf, sizeof(buf))) < 0) {
if (errno == EAGAIN) { // 沒數據到
perror("nothing can be read");
} else {
perror("fatal error");
exit(EXIT_FAILURE);
}
} else { // 有數據
process_data(buf, nbytes);
}
// 處理其他事情,做完了就等一會,再嘗試
nanosleep(sleep_interval, NULL);
}
這段代碼很容易理解,就是輪詢,不斷的嘗試有沒有數據到達,有了就處理,沒有(得到EWOULDBLOCK或者EAGAIN)就等一小會再試。這比之前BIO好多了,起碼程序不會被卡死了。
但這樣會帶來兩個新問題:
-
如果有大量文件描述符都要等,那么就得一個一個的read。這會帶來大量的Context Switch(
read是系統調用,每調用一次就得在用戶態和核心態切換一次) -
休息一會的時間不好把握。這里是要猜多久之后數據才能到。等待時間設的太長,程序響應延遲就過大;設的太短,就會造成過于頻繁的重試,干耗CPU而已。
要是操作系統能一口氣告訴程序,哪些數據到了就好了。
于是IO多路復用被搞出來解決這個問題。
IO多路復用
IO多路復用(IO Multiplexing) 是這么一種機制:程序注冊一組socket文件描述符給操作系統,表示“我要監視這些fd是否有IO事件發生,有了就告訴程序處理”。
IO多路復用是要和NIO一起使用的。盡管在操作系統級別,NIO和IO多路復用是兩個相對獨立的事情。NIO僅僅是指IO API總是能立刻返回,不會被Blocking;而IO多路復用僅僅是操作系統提供的一種便利的通知機制。操作系統并不會強制這倆必須得一起用——你可以用NIO,但不用IO多路復用,就像上一節中的代碼;也可以只用IO多路復用 + BIO,這時效果還是當前線程被卡住。但是,IO多路復用和NIO是要配合一起使用才有實際意義。因此,在使用IO多路復用之前,請總是先把fd設為O_NONBLOCK。
對IO多路復用,還存在一些常見的誤解,比如:
-
IO多路復用是指多個數據流共享同一個Socket。其實IO多路復用說的是多個Socket,只不過操作系統是一起監聽他們的事件而已。
多個數據流共享同一個TCP連接的場景的確是有,比如Http2 Multiplexing就是指Http2通訊中中多個邏輯的數據流共享同一個TCP連接。但這與IO多路復用是完全不同的問題。
-
IO多路復用是NIO,所以總是不Block的。其實IO多路復用的關鍵API調用(
select,poll,epoll_wait)總是Block的,正如下文的例子所講。 -
IO多路復用和NIO一起減少了IO。實際上,IO本身(網絡數據的收發)無論用不用IO多路復用和NIO,都沒有變化。請求的數據該是多少還是多少;網絡上該傳輸多少數據還是多少數據。IO多路復用和NIO一起僅僅是解決了調度的問題,避免CPU在這個過程中的浪費,使系統的瓶頸更容易觸達到網絡帶寬,而非CPU或者內存。要提高IO吞吐,還是提高硬件的容量(例如,用支持更大帶寬的網線、網卡和交換機)和依靠并發傳輸(例如HDFS的數據多副本并發傳輸)。
操作系統級別提供了一些接口來支持IO多路復用,最老掉牙的是select和poll。
select
select長這樣:
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
它接受3個文件描述符的數組,分別監聽讀取(readfds),寫入(writefds)和異常(expectfds)事件。那么一個 IO多路復用的代碼大概是這樣:
struct timeval tv = {.tv_sec = 1, .tv_usec = 0};
ssize_t nbytes;
while(1) {
FD_ZERO(&read_fds);
setnonblocking(fd1);
setnonblocking(fd2);
FD_SET(fd1, &read_fds);
FD_SET(fd2, &read_fds);
// 把要監聽的fd拼到一個數組里,而且每次循環都得重來一次...
if (select(FD_SETSIZE, &read_fds, NULL, NULL, &tv) < 0) { // block住,直到有事件到達
perror("select出錯了");
exit(EXIT_FAILURE);
}
for (int i = 0; i < FD_SETSIZE; i++) {
if (FD_ISSET(i, &read_fds)) {
/* 檢測到第[i]個讀取fd已經收到了,這里假設buf總是大于到達的數據,所以可以一次read完 */
if ((nbytes = read(i, buf, sizeof(buf))) >= 0) {
process_data(nbytes, buf);
} else {
perror("讀取出錯了");
exit(EXIT_FAILURE);
}
}
}
}
首先,為了select需要構造一個fd數組(這里為了簡化,沒有構造要監聽寫入和異常事件的fd數組)。之后,用select監聽了read_fds中的多個socket的讀取時間。調用select后,程序會Block住,直到一個事件發生了,或者等到最大1秒鐘(tv定義了這個時間長度)就返回。之后,需要遍歷所有注冊的fd,挨個檢查哪個fd有事件到達(FD_ISSET返回true)。如果是,就說明數據已經到達了,可以讀取fd了。讀取后就可以進行數據的處理。
select有一些發指的缺點:
-
select能夠支持的最大的fd數組的長度是1024。這對要處理高并發的web服務器是不可接受的。 -
fd數組按照監聽的事件分為了3個數組,為了這3個數組要分配3段內存去構造,而且每次調用
select前都要重設它們(因為select會改這3個數組);調用select后,這3數組要從用戶態復制一份到內核態;事件到達后,要遍歷這3數組。很不爽。 -
select返回后要挨個遍歷fd,找到被“SET”的那些進行處理。這樣比較低效。 -
select是無狀態的,即每次調用select,內核都要重新檢查所有被注冊的fd的狀態。select返回后,這些狀態就被返回了,內核不會記住它們;到了下一次調用,內核依然要重新檢查一遍。于是查詢的效率很低。
poll
poll與select類似于。它大概長這樣:
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
poll的代碼例子和select差不多,因此也就不贅述了。有意思的是poll這個單詞的意思是“輪詢”,所以很多中文資料都會提到對IO進行“輪詢”。
上面說的select和下文說的epoll本質上都是輪詢。
poll優化了select的一些問題。比如不再有3個數組,而是1個polldfd結構的數組了,并且也不需要每次重設了。數組的個數也沒有了1024的限制。但其他的問題依舊:
-
依然是無狀態的,性能的問題與
select差不多一樣; -
應用程序仍然無法很方便的拿到那些“有事件發生的fd“,還是需要遍歷所有注冊的fd。
目前來看,高性能的web服務器都不會使用select和poll。他們倆存在的意義僅僅是“兼容性”,因為很多操作系統都實現了這兩個系統調用。
如果是追求性能的話,在BSD/macOS上提供了kqueue api;在Salorias中提供了/dev/poll(可惜該操作系統已經涼涼);而在Linux上提供了epoll api。它們的出現徹底解決了select和poll的問題。Java NIO,nginx等在對應的平臺的上都是使用這些api實現。
因為大部分情況下我會用Linux做服務器,所以下文以Linux epoll為例子來解釋多路復用是怎么工作的。
用epoll實現的IO多路復用
epoll是Linux下的IO多路復用的實現。這里單開一章是因為它非常有代表性,并且Linux也是目前最廣泛被作為服務器的操作系統。細致的了解epoll對整個IO多路復用的工作原理非常有幫助。
與select和poll不同,要使用epoll是需要先創建一下的。
int epfd = epoll_create(10);
epoll_create在內核層創建了一個數據表,接口會返回一個“epoll的文件描述符”指向這個表。注意,接口參數是一個表達要監聽事件列表的長度的數值。但不用太在意,因為epoll內部隨后會根據事件注冊和事件注銷動態調整epoll中表格的大小。
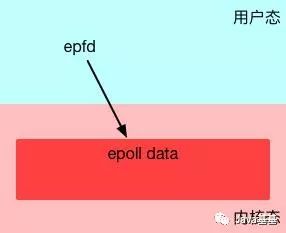
epoll創建
為什么epoll要創建一個用文件描述符來指向的表呢?這里有兩個好處:
-
epoll是有狀態的,不像
select和poll那樣每次都要重新傳入所有要監聽的fd,這避免了很多無謂的數據復制。epoll的數據是用接口epoll_ctl來管理的(增、刪、改)。 -
epoll文件描述符在進程被fork時,子進程是可以繼承的。這可以給對多進程共享一份epoll數據,實現并行監聽網絡請求帶來便利。但這超過了本文的討論范圍,就此打住。
epoll創建后,第二步是使用epoll_ctl接口來注冊要監聽的事件。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
其中第一個參數就是上面創建的epfd。第二個參數op表示如何對文件名進行操作,共有3種。
-
EPOLL_CTL_ADD- 注冊一個事件 -
EPOLL_CTL_DEL- 取消一個事件的注冊 -
EPOLL_CTL_MOD- 修改一個事件的注冊
第三個參數是要操作的fd,這里必須是支持NIO的fd(比如socket)。
第四個參數是一個epoll_event的類型的數據,表達了注冊的事件的具體信息。
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
比方說,想關注一個fd1的讀取事件事件,并采用邊緣觸發(下文會解釋什么是邊緣觸發),大概要這么寫:
struct epoll_data ev;
ev.events = EPOLLIN | EPOLLET; // EPOLLIN表示讀事件;EPOLLET表示邊緣觸發
ev.data.fd = fd1;
通過epoll_ctl就可以靈活的注冊/取消注冊/修改注冊某個fd的某些事件。
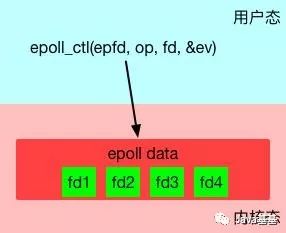
管理fd事件注冊
第三步,使用epoll_wait來等待事件的發生。
int epoll_wait(int epfd, struct epoll_event *evlist, int maxevents, int timeout);
特別留意,這一步是"block"的。只有當注冊的事件至少有一個發生,或者timeout達到時,該調用才會返回。這與select和poll幾乎一致。但不一樣的地方是evlist,它是epoll_wait的返回數組,里面只包含那些被觸發的事件對應的fd,而不是像select和poll那樣返回所有注冊的fd。
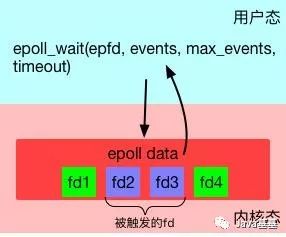
監聽fd事件
綜合起來,一段比較完整的epoll代碼大概是這樣的。
#define MAX_EVENTS 10
struct epoll_event ev, events[MAX_EVENTS];
int nfds, epfd, fd1, fd2;
// 假設這里有兩個socket,fd1和fd2,被初始化好。
// 設置為non blocking
setnonblocking(fd1);
setnonblocking(fd2);
// 創建epoll
epfd = epoll_create(MAX_EVENTS);
if (epollfd == -1) {
perror("epoll_create1");
exit(EXIT_FAILURE);
}
//注冊事件
ev.events = EPOLLIN | EPOLLET;
ev.data.fd = fd1;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, fd1, &ev) == -1) {
perror("epoll_ctl: error register fd1");
exit(EXIT_FAILURE);
}
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, fd2, &ev) == -1) {
perror("epoll_ctl: error register fd2");
exit(EXIT_FAILURE);
}
// 監聽事件
for (;;) {
nfds = epoll_wait(epdf, events, MAX_EVENTS, -1);
if (nfds == -1) {
perror("epoll_wait");
exit(EXIT_FAILURE);
}
for (n = 0; n < nfds; ++n) { // 處理所有發生IO事件的fd
process_event(events[n].data.fd);
// 如果有必要,可以利用epoll_ctl繼續對本fd注冊下一次監聽,然后重新epoll_wait
}
}
此外,epoll的手冊 中也有一個簡單的例子。
所有的基于IO多路復用的代碼都會遵循這樣的寫法:注冊——監聽事件——處理——再注冊,無限循環下去。
epoll的優勢
為什么epoll的性能比select和poll要強呢? select和poll每次都需要把完成的fd列表傳入到內核,迫使內核每次必須從頭掃描到尾。而epoll完全是反過來的。epoll在內核的數據被建立好了之后,每次某個被監聽的fd一旦有事件發生,內核就直接標記之。epoll_wait調用時,會嘗試直接讀取到當時已經標記好的fd列表,如果沒有就會進入等待狀態。
同時,epoll_wait直接只返回了被觸發的fd列表,這樣上層應用寫起來也輕松愉快,再也不用從大量注冊的fd中篩選出有事件的fd了。
簡單說就是select和poll的代價是"O(所有注冊事件fd的數量)",而epoll的代價是"O(發生事件fd的數量)"。于是,高性能網絡服務器的場景特別適合用epoll來實現——因為大多數網絡服務器都有這樣的模式:同時要監聽大量(幾千,幾萬,幾十萬甚至更多)的網絡連接,但是短時間內發生的事件非常少。
但是,假設發生事件的fd的數量接近所有注冊事件fd的數量,那么epoll的優勢就沒有了,其性能表現會和poll和select差不多。
epoll除了性能優勢,還有一個優點——同時支持水平觸發(Level Trigger)和邊沿觸發(Edge Trigger)。
水平觸發和邊沿觸發
默認情況下,epoll使用水平觸發,這與select和poll的行為完全一致。在水平觸發下,epoll頂多算是一個“跑得更快的poll”。
而一旦在注冊事件時使用了EPOLLET標記(如上文中的例子),那么將其視為邊沿觸發(或者有地方叫邊緣觸發,一個意思)。那么到底什么水平觸發和邊沿觸發呢?
考慮下圖中的例子。有兩個socket的fd——fd1和fd2。我們設定監聽f1的“水平觸發讀事件“,監聽fd2的”邊沿觸發讀事件“。我們使用在時刻t1,使用epoll_wait監聽他們的事件。在時刻t2時,兩個fd都到了100bytes數據,于是在時刻t3, epoll_wait返回了兩個fd進行處理。在t4,我們故意不讀取所有的數據出來,只各自讀50bytes。然后在t5重新注冊兩個事件并監聽。在t6時,只有fd1會返回,因為fd1里的數據沒有讀完,仍然處于“被觸發”狀態;而fd2不會被返回,因為沒有新數據到達。

水平觸發和邊沿觸發
這個例子很明確的顯示了水平觸發和邊沿觸發的區別。
-
水平觸發只關心文件描述符中是否還有沒完成處理的數據,如果有,不管怎樣
epoll_wait,總是會被返回。簡單說——水平觸發代表了一種“狀態”。 -
邊沿觸發只關心文件描述符是否有新的事件產生,如果有,則返回;如果返回過一次,不管程序是否處理了,只要沒有新的事件產生,
epoll_wait不會再認為這個fd被“觸發”了。簡單說——邊沿觸發代表了一個“事件”。
那么邊沿觸發怎么才能迫使新事件產生呢?一般需要反復調用
read/write這樣的IO接口,直到得到了EAGAIN錯誤碼,再去嘗試epoll_wait才有可能得到下次事件。
那么為什么需要邊沿觸發呢?
邊沿觸發把如何處理數據的控制權完全交給了開發者,提供了巨大的靈活性。比如,讀取一個http的請求,開發者可以決定只讀取http中的headers數據就停下來,然后根據業務邏輯判斷是否要繼續讀(比如需要調用另外一個服務來決定是否繼續讀)。而不是次次被socket尚有數據的狀態煩擾;寫入數據時也是如此。比如希望將一個資源A寫入到socket。當socket的buffer充足時,epoll_wait會返回這個fd是準備好的。但是資源A此時不一定準備好。如果使用水平觸發,每次經過epoll_wait也總會被打擾。在邊沿觸發下,開發者有機會更精細的定制這里的控制邏輯。
但不好的一面時,邊沿觸發也大大的提高了編程的難度。一不留神,可能就會miss掉處理部分socket數據的機會。如果沒有很好的根據EAGAIN來“重置”一個fd,就會造成此fd永遠沒有新事件產生,進而導致餓死相關的處理代碼。
再來思考一下什么是“Block”
上面的所有介紹都在圍繞如何讓網絡IO不會被Block。但是網絡IO處理僅僅是整個數據處理中的一部分。如果你留意到上文例子中的“處理事件”代碼,就會發現這里可能是有問題的。
-
處理代碼有可能需要讀寫文件,可能會很慢,從而干擾整個程序的效率;
-
處理代碼有可能是一段復雜的數據計算,計算量很大的話,就會卡住整個執行流程;
-
處理代碼有bug,可能直接進入了一段死循環……
這時你會發現,這里的Block和本文之初講的O_NONBLOCK是不同的事情。在一個網絡服務中,如果處理程序的延遲遠遠小于網絡IO,那么這完全不成問題。但是如果處理程序的延遲已經大到無法忽略了,就會對整個程序產生很大的影響。這時IO多路復用已經不是問題的關鍵。
試分析和比較下面兩個場景:
-
web proxy。程序通過IO多路復用接收到了請求之后,直接轉發給另外一個網絡服務。
-
web server。程序通過IO多路復用接收到了請求之后,需要讀取一個文件,并返回其內容。
它們有什么不同?它們的瓶頸可能出在哪里?
總結
小結一下本文:
-
對于socket的文件描述符才有所謂BIO和NIO。
-
多線程+BIO模式會帶來大量的資源浪費,而NIO+IO多路復用可以解決這個問題。
-
在Linux下,基于epoll的IO多路復用是解決這個問題的最佳方案;epoll相比
select和poll有很大的性能優勢和功能優勢,適合實現高性能網絡服務。
但是IO多路復用僅僅是解決了一部分問題,另外一部分問題如何解決呢?且聽下回分解。
智能推薦
一文搞定網絡編程中的BIO、NIO和AIO(從理論到代碼演示)
在學習網絡編程時,容易混淆NIO、BIO、AIO這幾個概念,同時對于阻塞和非阻塞、同步和異步的理解也較為晦澀,本文將從最基礎的內核態/用戶態進行介紹,逐步講解在Java的IO編程中幾種不同IO操作方式及其具體實現。 BIO\NIO\AIO解析 1. Linux網絡IO模型介紹 1.1 基本概念 1.1.1 內核空間和用戶空間 1.1.2 內核態和用戶態 1.1.3 如何從用戶空間到內核空間 1.2...

Java 網絡編程實戰筆記:BIO、NIO、AIO
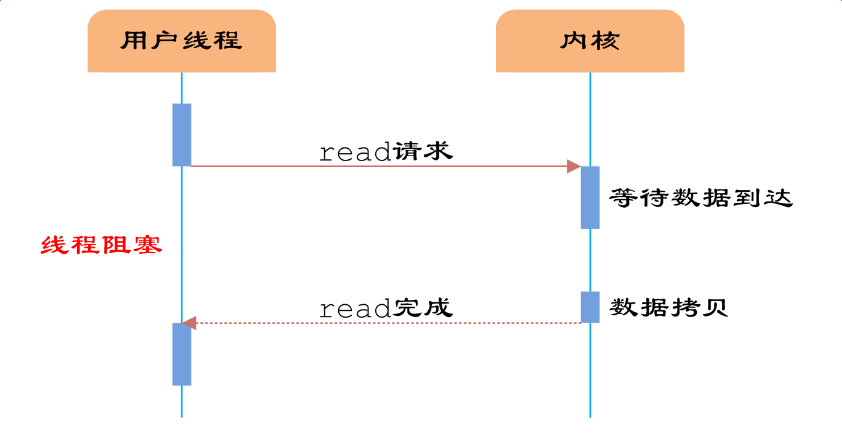
Java 網絡編程學習筆記 前置概念 Java IO 模型 IO 模型 對應的 Java 版本 BIO(同步阻塞 IO) 1.4 之前 NIO(同步非阻塞 IO) 1.4 AIO(異步非阻塞 IO) 1.7 Linux 內核 IO 模型 阻塞 IO 最傳統的一種 IO 模型,在讀寫數據過程中會發生阻塞。 當用戶線程發出 IO 請求后,內核會去查看數據是否就緒,如果沒有就緒就會等待數據就緒,而用戶線...
BIO、NIO、AIO網絡編程
概述 IO IO是輸入和輸出的縮寫. Java的IO包主要關注的是從目標媒介讀取數據以及輸出數據到目標媒介,目標媒介包括: 文件 管道(線程內部通信) 網絡連接 內存緩存 標準輸入、輸出和錯誤輸出 輸出操作 輸入操作 流 流從概念上來說是一個連續的數據流。在Java IO中流既可以是字節流(以字節為單位進行讀寫),也可以是字符流(以字符為單位進行讀寫,如Reader/Writer)。你既可以從流中...

java高并發實戰(八)——BIO、NIO和AIO
由于之前看的容易忘記,因此特記錄下來,以便學習總結與更好理解,該系列博文也是第一次記錄,所有有好多不完善之處請見諒與留言指出,如果有幸大家看到該博文,希望報以參考目的看瀏覽,如有錯誤之處,謝謝大家指出與留言。 一、什么是NIO? NIO是New I/O的簡稱,與舊式的基于流的I/O方法相對,從名字看,它表示新的一套Java I/O標準。是一種多路復用;它是在Java 1.4中被納入到JDK中的,并...
Java BIO NIO AIO 模型介紹和使用樣例
在計算機的世界中,IO操作是不可避免的一個話題,IO操作涉及到的阻塞,非阻塞,同步和異步這些概念常常讓我感到混亂,為此,專門抽出時間對這些概念做了一下簡單的研究,記錄如下。希望可以幫助還在這些概念中掙扎的同學。 1.阻塞,非阻塞,同步和異步 IO操作實際上可以分為兩步:發起IO請求和實際的IO操作。...
猜你喜歡


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...
