XML解析___使用Dom or使用Sax
標簽: # XML
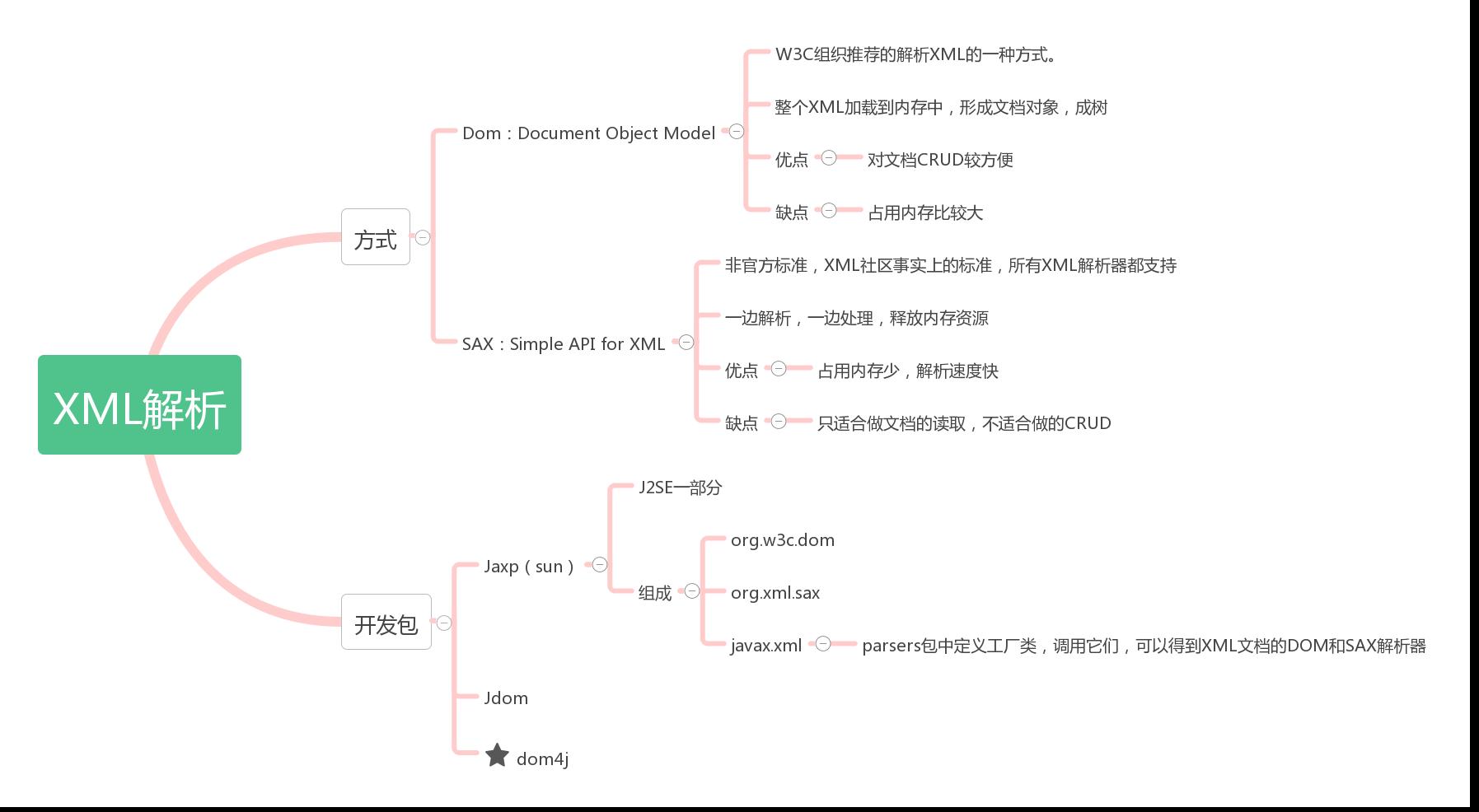
xml解析方式分為兩種,dom和sax
dom:(Document Object Model,即對文檔對象模型)是W3C組織推薦的處理XML的一種方式
Sax:(Simple API for XML)不是官方標準,但它是xml社區事實上的標準,幾乎所有的xml解析器都支持它。
XML解析開發包
Jaxp、Jdom、dom4J
使用DOM解析XML介紹
DOM模型(Document Object model)
DOM 解析器在解析XML文檔時,會把文檔中的所有元素,按照其出現的層次關系,解析成一個個Node對象(節點)。
優點:把xml文件在內存中構造樹形結構,可以遍歷和修改節點
缺點:如果文件比較大,內存有壓力,解析的實際那會比較長
使用Dom解析XML的步驟
調用DocumentBuilderFactory.newInstance()方法得到創建DOM解析器的工廠。
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
調用工廠對象的newDocumentBuilder方法得到DOM解析器對象。
DocumentBuilder builder = dbf.newDocumentBuilder();
調用Dom解析器對象的parse()方法解析XML文檔,得到代表這個文檔的Document對象,進行可以利用DOM特性對整個XML文檔進行操作了。
Document doc = builder.parse("src/com/demo.xml");//此處填寫需要解析的XML的路徑
總結:先反射一個解析工廠對象,再通過這個解析工廠對象創建一個Dom解析器對象,再通過Dom解析器對象獲得doc文檔對象。
Dom解析XML實例
(1)給出需要解析的XML文件
<?xml version="1.0" encoding="UTF-8"?>
<employees>
<employee id="0">
<name>Alexia</name>
<age>23</age>
<sex>Female</sex>
<weight> 150 </weight>
<weight><a>160</a></weight>
</employee>
<employee id="1">
<name height="178">Edward</name>
<age>24</age>
<sex>Male</sex>
</employee>
<employee id="2">
<name>wjm</name>
<age>23</age>
<sex>Female</sex>
</employee>
<employee id="3">
<name>wh</name>
<age>24</age>
<sex>Male</sex>
</employee>
</employees>
(2)使用Dom對XML進行解析
package com.demo;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class Domxml {
/*
*類說明:
* 使用Dom解析XMl
*Dom解析XMl的步驟:
* 1:創建一個dbf工廠對象的對象。
* 2:通過dbf工廠對象創建一個dom解析器DocumentBuilder對象。
* 3:通過DocumentBuilder對象的parse(String fileName)方法解析xml文件
*
*/
public static void main(String[] args) throws Exception{
//1.創建【dbf工廠對象】
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
//設置解析器,忽略注釋和空格<a>
dbf.setIgnoringComments(true);
dbf.setIgnoringElementContentWhitespace(true);
//2.通過dbf工廠對象獲得【Dom解析對象】
DocumentBuilder builder = dbf.newDocumentBuilder();
//3。調用DOm解析器對象,解析xml文檔,獲得[文檔Document對象]
Document doc = builder.parse("src/conn/demo.xml");//此處填需要解析的xml的路徑
//獲得根節點
Element root = doc.getDocumentElement();
System.out.println(root.getTagName());//獲得節點名字
//根據標簽名獲得節點集合
NodeList nodeList = doc.getElementsByTagName("employee");
System.out.println("employee節點個數:" + nodeList.getLength());
//遍歷節點集合
for(int i = 0;i<nodeList.getLength();i++){
Element element = (Element) nodeList.item(i);//強制轉換
//獲取id屬性值
String attribute = element.getAttribute("id");
System.out.println("id:"+attribute);
//獲取第一個employee
if(i==0){
//獲得元素下面的name文本
System.out.println("name文本值為: "+element.getElementsByTagName("name").item(0).getFirstChild().getNodeValue());
//獲得元素下面的sex文本
System.out.println("sex文本值: "+element.getElementsByTagName("sex").item(0).getFirstChild().getNodeValue());
//獲得元素下面的 age文本
System.out.println("age文本值: "+element.getElementsByTagName("age").item(0).getFirstChild().getNodeValue());
//獲得元素下面的 weight文本
System.out.println("weight文本值: "+element.getElementsByTagName("weight").item(0).getFirstChild().getNodeValue());
// 獲得第二個Weight里a標簽中的文本值
System.out.println(element.getElementsByTagName("weight").item(1).getFirstChild().getFirstChild().getNodeValue());
}
System.out.println("");
System.out.println("");
System.out.println("");
System.out.println("");
// System.out.println("name文本值為: "+element.getElementsByTagName("name").item(i).getFirstChild().getNodeValue());
// //獲得元素下面的age文本
// System.out.println("sex文本值: "+element.getElementsByTagName("sex").item(i).getFirstChild().getNodeValue());
// //獲得元素下面的 文本
// System.out.println("age文本值: "+element.getElementsByTagName("age").item(i).getFirstChild().getNodeValue());
//
// Element element2 = (Element)nodeList.item(1);
// String nameValue2 = element2.getElementsByTagName("name").item(0).getFirstChild().getNodeValue();
// String ageValue2 = element2.getElementsByTagName("age").item(0).getFirstChild().getNodeValue();
// String sexValue2 = element2.getElementsByTagName("sex").item(0).getFirstChild().getNodeValue();
// System.out.println("第二個節點的name文本值:"+nameValue2);
// System.out.println("第二個節點的age文本值:"+ageValue2);
// System.out.println("第二個節點的sex文本值:"+sexValue2);
}
}
}
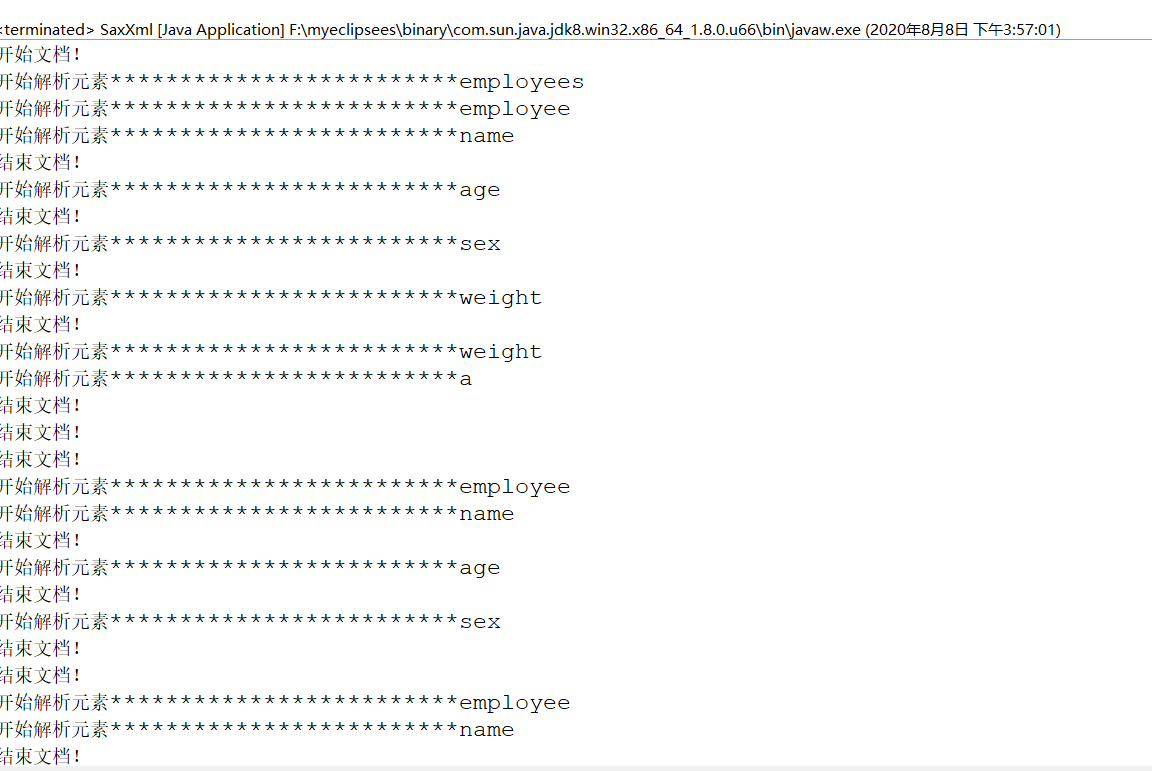
得到結果如下:
使用SAX解析XML介紹
SAX解析允許在讀取文檔的時候,即對文檔進行處理,而不必等到整個文檔裝載完才會對文檔當進行處理。
優點:解析可以立即開始,速度快,沒有內存壓力
缺點:不能對節點做修改
使用SAX解析XML步驟
使用Sax解析XML的準備工作:
1.繼承DefaultHandler類:這是解析XML的事件處理基類
2.覆蓋statDocument/endDocument,startElement/endElement方法
使用SAXParserFactory創建SAX解析工廠
SAXParserFactory spf = SAXParserFactory.newInstance();
通過SAX解析工廠得到解析器對象
SAXParser saxParse = spf.newSAXParser();
通過解析器對象得到一個XML的讀取器
XMLRead xmlReader = sp.getXMLReader();設置讀取器的事件處理器
xmlReader.setContentHandler(new BookParserHandler());解析xml文件
File file = new File("src/com/demo.xml");
saxParse.parse(file, new SaxXML());//第二個參數為類名代碼如下:
package com.demo;
import java.io.File;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SaxXml extends DefaultHandler {
//在解析整個文檔開始時調用
@Override
public void startDocument() throws SAXException {
super.startDocument();
System.out.println("開始文檔! ");
}
//在解析整個文檔結束時調用
public void endDocument() throws SAXException{
System.out.println("結束文檔! ");
}
//在解析元素開始時被調用
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
System.out.println("開始解析元素*************************"+qName);
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
// TODO Auto-generated method stub
super.endElement(uri, localName, qName);
System.out.println("結束文檔!");
}
public static void main(String[] args) throws Exception, SAXException {
//1 發射一個Sax解析工廠對象
SAXParserFactory spf = SAXParserFactory.newInstance();
//2 創建Sax解析器對象
SAXParser saxParser = spf.newSAXParser();
//3 解析xml文件
File file = new File("src/conn/demo.xml");
//4.解析XML文件
saxParser.parse(file,new SaxXml());
}
}運行結果:
智能推薦
XML解析:使用DOM4j解析xml文件
當前環境:dom4j 1.6.1 1.簡介 dom4j一個簡潔高效的xml解析工具 2.創建當前的users.xml文件用于解析 3.查找dom4j可以解析xml的類 1.查看當前的源碼查找可用的dom4j的加載當前xml文件 通過源碼發現io包中有一個DOMReader可以用來加載當前的xml文件流 通過查看源碼發現具有一個read方法加載Document對象,所以可以這樣使用 4.使用dom4...
【XML解析】使用Jaxp對XML進行DOM解析
【前言】 璐小編在之前學習BS的時候接觸過XML(請戳:【XML】基礎知識初步認識),后來在項目中我們也會遇到XML的配置文件,現在學習Java又遇到對XML的文檔內容進行解析。看來對于XML的認知是不斷加深的過程~ 本篇簡介XML解析的方式以及使用Jaxp對XML文檔進行dom解析。 【XML解析】 對于XML解析方...

使用Dom4j解析XML
轉載自 使用Dom4j解析XML dom4j是一個Java的XML API,類似于jdom,用來讀寫XML文件的。dom4j是一個非常非常優秀的Java XML API,具有性能優異、功能強大和極端易用使用的特點,同時它也是一個開放源代碼的軟件,可以在SourceForge上找到它. 對主流的Ja...
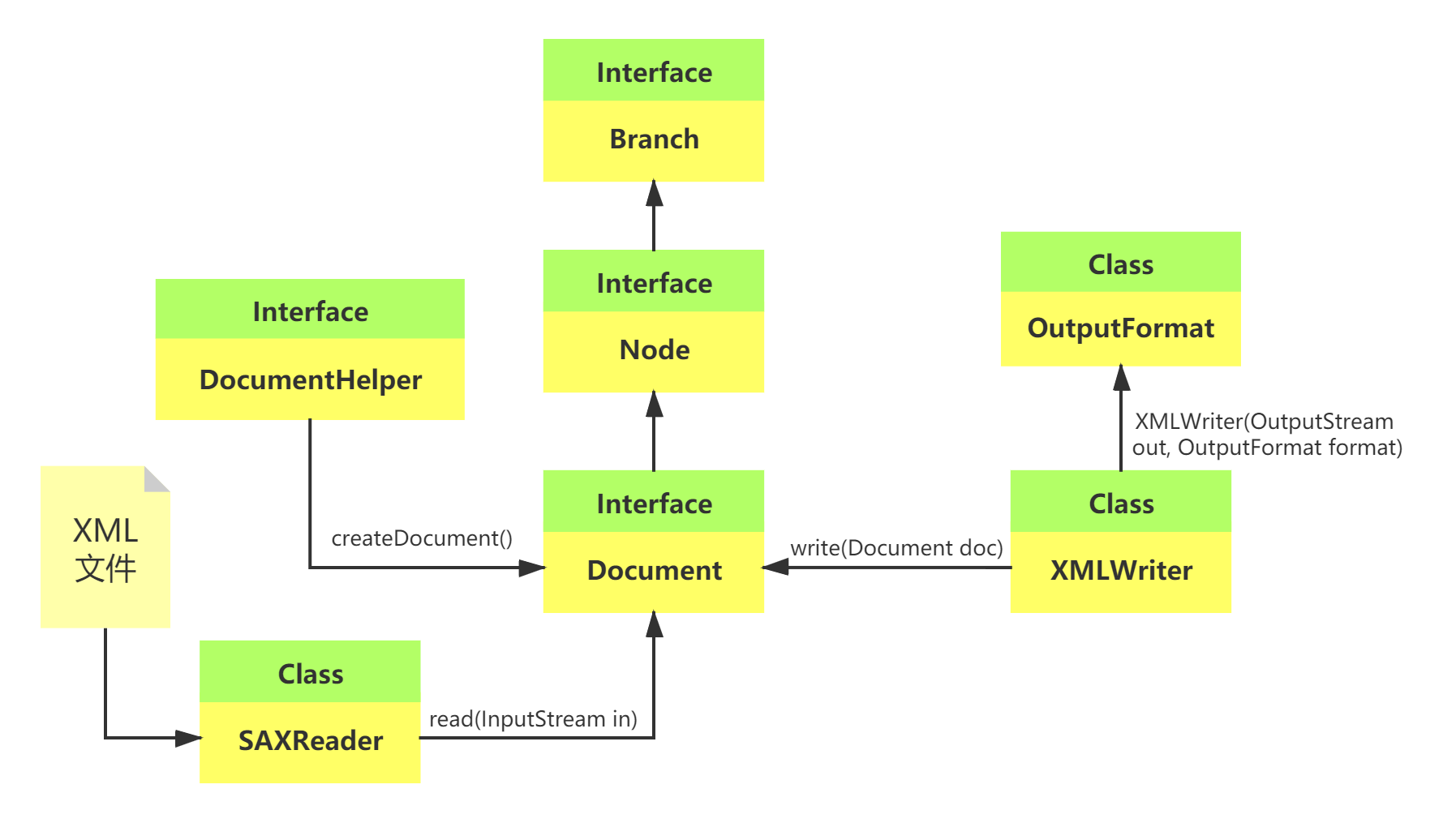
使用DOM4J解析XML
使用DOM4J解析XML DOM4J同時具備了DOM寫入和SAX讀取的操作,并做了存儲優化,使用DOM4J時要導入dom4j的開發包dom4j-x.x.x.jar。 DOM4J提供有自己的一堆實現類庫: DocumentHelper工具類:org.dom4j.DocumentHelper No 返回值 方法名 描述 1 Document createDocument() 創建新的文檔 2 Elem...
Java使用DOM方式解析xml文件
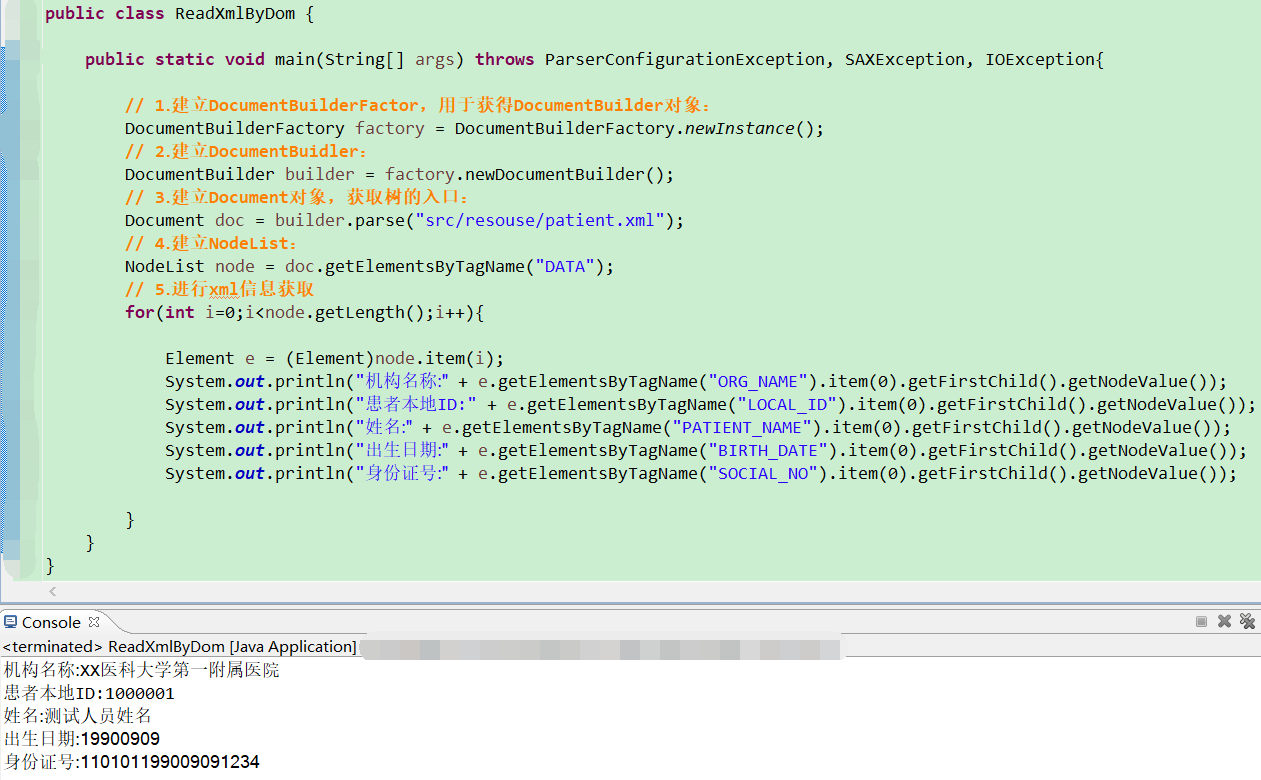
XML解析 根據提供的patient.xml文件,獲取xml文件中機構名稱、患者本地ID、姓名、出生日期、身份證號。 解析框架不限,如dom4j,jdom, sax, jackson等 <!-- patient.xml --> <?xml version="1.0" encoding="UTF-8"?> <...
猜你喜歡

使用jdk DOM,SAX和第三方jar包DOM4J創建,解析xml文件
xml的創建,解析 1. 什么是xml文件 1.1 什么是xml文件 1.2 解析xml的方式,優缺點 2. 使用dom操作xml文件 2.1 使用dom創建xml文件 2.2 使用dom解析xml文件 2.3 使用dom對xml文件增刪改 3. 使用SAX解析xml文件 4. 使用DOM4J操作xml文件 4.1 使用DOM4J創建xml文件 4.2 使用DOM4J解析xml文件 1. 什么是x...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...