DC學院爬蟲學習筆記(五):使用pandas保存豆瓣短評數據
保存數據的方法:
- open函數保存
- pandas包保存(本節課重點講授)
- csv模塊保存
- numpy包保存
使用open函數保存數據
1. open函數用法
- 使用with open()新建對象
- 寫入數據
import requests
from lxml import etree
url = 'https://book.douban.com/subject/1084336/comments/'
r = requests.get(url).text
s = etree.HTML(r)
file = s.xpath('//div[@class="comment"]/p/text()')
with open('pinglun.txt', 'w', encoding='utf-8') as f: #使用with open()新建對象f
for i in file:
# print(i)
f.write(i) #寫入數據,文件保存在當前工作目錄- 可以使用以下方法得到當前工作目錄或者修改當前工作目錄
import os
os.getcwd()#得到當前工作目錄'C:\\Users\\Dell'
os.chdir()#修改當前工作目錄,括號中傳入工作目錄的路徑2. open函數的打開模式

使用pandas保存數據
1. Python數據分析的工具包
- numpy: (Numerical Python的簡稱),是高性能科學計算和數據分析的基礎包
- pandas:基于Numpy創建的Python包,含有使數據分析工作變得更加簡單的高級數據結構和操作工具
- matplotlib:是一個用于創建出版質量圖表的繪圖包(主要是2D方面)
- 常見的導入方法:
import pandas as pd #導入pandas
import numpy as np #導入numpy
import matplotlib.pypolt as plt #導入matplotlib2. pandas保存數據到Excel
- 導入相關的庫
- 將爬取到的數據儲存為DataFrame對象(DataFrame 是一個表格或者類似二維數組的結構,它的各行表示一個實例,各列表示一個變量)
- to_excel() 實例方法:用于將DataFrame保存到Excel
df.to_excel('文件名.xlsx', sheet_name = 'Sheet1')
#其中df為DataFrame結構的數據,sheet_name = 'Sheet1'表示將數據保存在Excel表的第一張表中- read_excel() 方法:從excel文件中讀取數據
pd.read_excel('文件名.xlsx', 'Sheet1', index_col=None, na_values=['NA'])3. pandas保存數據到csv文件
- 導入相關的庫
- 將數據儲存為DataFrame對象
- 保存數據到csv文件
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(6,3)) #創建隨機值并保存為DataFrame結構
print(df.head())
df.to_csv('numpppy.csv') 0 1 2
0 0.028705 -0.351902 -0.821870
1 0.279090 0.577875 -1.283121
2 1.563792 -0.146931 -0.587794
3 -0.272610 -0.342182 0.847883
4 1.380459 0.462965 -1.799529
實戰
爬取《小王子》豆瓣短評的數據,并把數據保存為本地的excel表格
import requests
from lxml import etree
url = 'https://book.douban.com/subject/1084336/comments/'
r = requests.get(url).text
s = etree.HTML(r)
file = s.xpath('//div[@class="comment"]/p/text()')
import pandas as pd
df = pd.DataFrame(file)
df.to_excel('pinglun.xlsx')爬取《小王子》豆瓣短評前5頁的短評數據
import requests
from lxml import etree
import pandas as pd
urls=['https://book.douban.com/subject/1084336/comments/hot?p={}'.format(str(i)) for i in range(1, 6, 1)] #通過觀察的url翻頁的規律,使用for循環得到5個鏈接,保存到urls列表中
pinglun = [] #初始化用于保存短評的列表
for url in urls: #使用for循環分別獲取每個頁面的數據,保存到pinglun列表
r = requests.get(url).text
s = etree.HTML(r)
file = s.xpath('//div[@class="comment"]/p/text()')
pinglun = pinglun + file
df = pd.DataFrame(pinglun) #把pinglun列表轉換為pandas DataFrame
df.to_excel('pinglun.xlsx') #使用pandas把數據保存到excel表格智能推薦
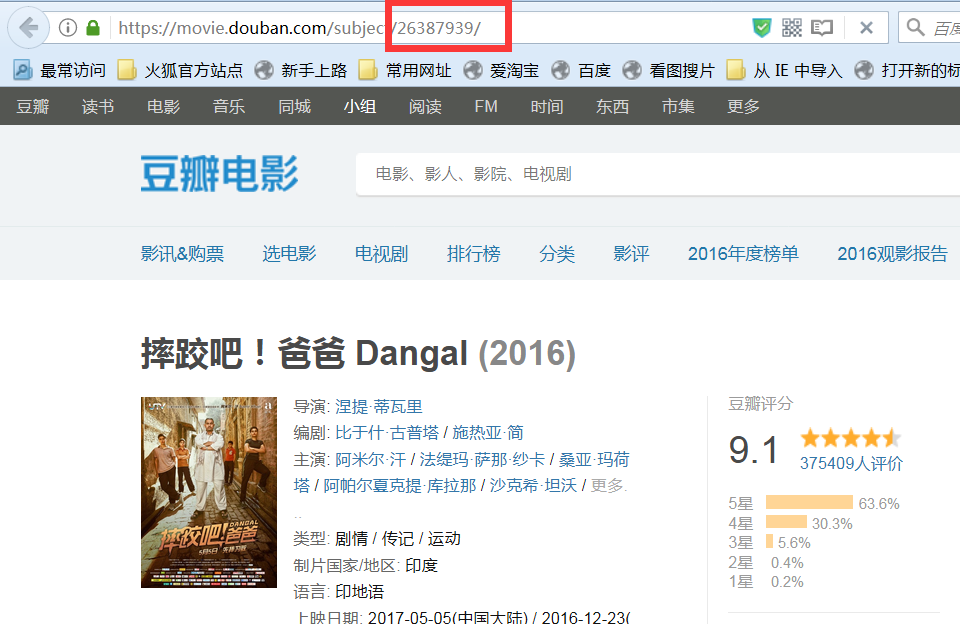
DC學院數據分析師(入門)學習筆記----基于網站API抓取《摔跤吧!爸爸》的豆瓣評分情況
前幾天在某公眾號上看到了對《戰狼2》的數據分析,涉及人群,觀看時間,影評,地點等等,分析的超級棒,所以就想著數據分析是一件很有說話權的事情。作為這方面的小白,決定抽時間學習一番。于是乎,通過博客來記錄一下自己的學習路程。 其實就是跟著網課的操作筆記 這次是基于網站API抓取《摔跤吧!爸...
【Python 爬蟲】(二)使用 Requests 爬取豆瓣短評
文章目錄 Requests庫介紹 Requests庫安裝 Requests庫的簡單用法 實戰 爬蟲協議 Requests庫介紹 Requests庫官方的介紹有這么一句話:Requests,唯一的一個非轉基因的 Python HTTP 庫,人類可以安全享用。 這句話直接并霸氣地宣示了Requests庫是python最好的一個HTTP庫。 想要深入學習Requests庫,可以參考官方文檔:http:/...
爬蟲-爬取豆瓣短評
爬蟲-爬取豆瓣短評 啥是爬蟲? ? 按照一定的規則,自動地抓取互聯網信息的程序。 為啥要用爬蟲? ? 可以利用爬蟲自動地采集互聯網中的信息,采集回來后進行相應的存儲或處理,在需要檢索某些信息的時候,只需在采集回來的信息中進行檢索 怎么用爬蟲? 爬蟲分為三個部分 1、解析網頁 2、提取信息 3、保存信息 接下來將會用requests庫來實現一個簡單地爬蟲 爬取豆瓣短評 首先我們需要安裝request...
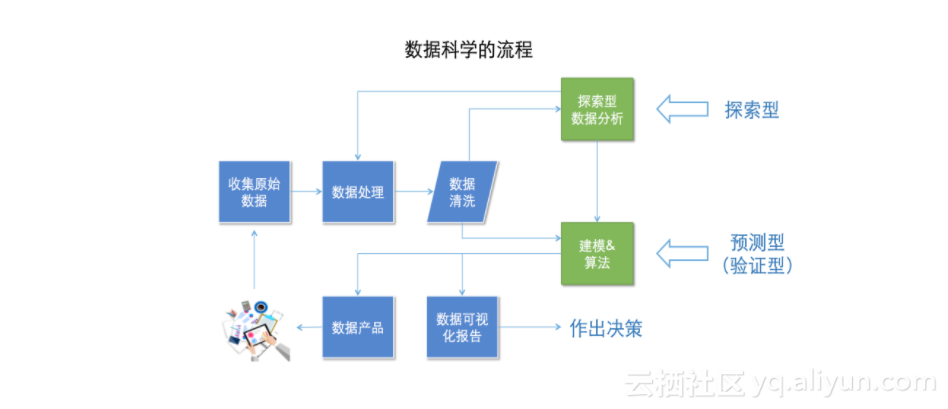
DC學院學習筆記(十二):數據分析—探索型數據分析
終于學習到課程的核心部分了——數據分析了! 數據分析三大類型 探索型數據分析 驗證型數據分析 預測型數據分析 數據科學的流程: 探索型數據分析的作用 與數據清理相輔相成 支持驗證型數據分析、預測型數據分析 探索型數據分析的常用圖表 條形圖、直方圖 餅圖(餅圖在探索型數據分析中使用較少,原因是肉眼對于角度之間的大小差別沒有對高度之間的差別敏感) 折線圖、散點圖 箱形圖 下面仔...
DC學院學習筆記(七):基于HeidiSQL的數據庫操作
在本機裝了HeidiSQL,開始學習用數據庫來進行數據預處理。 SQL SQL查詢語句 查詢語句的通用格式 SELECT */column FROM table name WHERE condition 新增語句的通用格式 INSERT INTO table_name(column1,column2...) VALUES(values1,values2...) 修改語句的通用格式 UPDATE t...
猜你喜歡

爬蟲實踐---豆瓣短評+詞云分析
電影頁面: https://movie.douban.com/subject/26363254 熱評: 第一頁:https://movie.douban.com/subject/26363254/comments?start=0&limit=20&sort=new_score&status=P 第n頁:https://movie.douban.com/subject/263...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...