Python爬蟲筆記——爬蟲入門
一、爬蟲
-
爬蟲是什么
我們把互聯網有價值的信息都比喻成大的蜘蛛網,而各個接地那就是存放的數據,而蜘蛛網上的蜘蛛比喻成爬蟲,而爬蟲是可以自動抓取互聯網信息的程序,從互聯網上抓取一切有價值的信息,并把站點的html和js返回的圖片爬到本地,并存出起來。 -
爬蟲用途
爬取網站信息數據,12306搶票,網絡投票等。
二、BeautifulSoup使用
BeautifulSoup是一個可以從HTML或XML文件中提取數據的Python庫.它能夠通過你喜歡的轉換器實現慣用的文檔導航,查找,修改文檔的方式.BeautifulSoup會幫你節省數小時甚至數天的工作時間.
看了一些BeautifulSoup的教程文檔,還是推薦大家可以看看 BeautifulSoup中文官方文檔 ,官方文檔還是很好用的。
主要還是分析html的網頁格式,找到想爬取內容在html對應的位置,使用beautifulsoup找到對應元素,獲取標簽內容。
三、爬取豆瓣電影TOP250
-
分析網頁數據構成,獲取元素位置。如圖,我們可以查看元素在HTML里面對應標簽位置,使用beautifulsoup庫來進行解析獲取想要的數據。
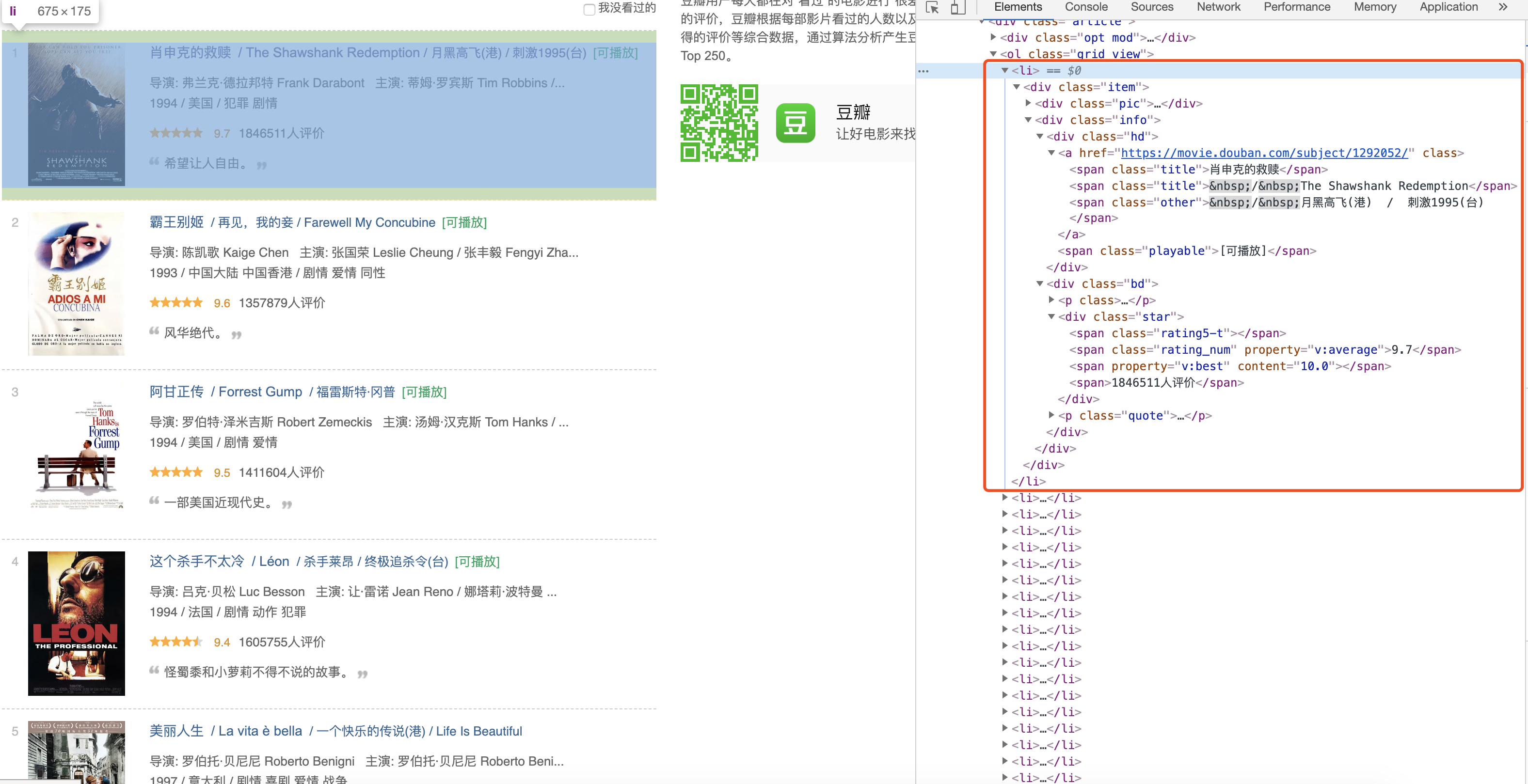
-
直接上代碼
import requests from bs4 import BeautifulSoup import re import json #模擬瀏覽器訪問 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'} #爬取數據結果集 result =[] # 獲取電影詳情頁鏈接 def get_deatil_url(url): req = requests.get(url, headers=headers) bs = BeautifulSoup(req.text, 'html.parser') urls = bs.find_all("div", attrs={"class":"info"}) if len(urls) > 0: for item in urls: link = item.find("a").get('href') get_details(link) # 獲取頁面詳情 def get_details(url): req = requests.get(url, headers=headers) bs = BeautifulSoup(req.text, 'html.parser') try: # 電影排名(這樣寫要確定標簽的屬性或者class值是唯一的能定位到) rank = bs.find("span", attrs={"class": "top250-no"}).get_text() # 電影名稱 name = bs.find("span", attrs={"property": "v:itemreviewed"}).get_text().split(' ')[0] # 評分 score = bs.find("strong", attrs={"class":"ll rating_num"}).get_text() data = { 'rank' : rank, 'name': name, 'score': score } print(data) result.append(data) except Exception as e: print(e) ## 3.獲取的數據保存到json文件中 def save_json(result): with open('movie.json','w',encoding='utf-8') as file: file.write(json.dumps(result,indent=2,ensure_ascii=False)) if __name__ == '__main__': ## 1.#根據列表url可以看出start后面為當前頁面第一條的起始序號 for i in range(0,10): url = 'https://movie.douban.com/top250?start={}&filter='.format(i * 25) ## 2.通過url獲取頁面詳情 get_deatil_url(url) ## 3.將爬取的數據集保存到json文件中。 save_json(result) -
運行爬蟲結果
運行生成的json文件跟python文件會在同一目錄下面。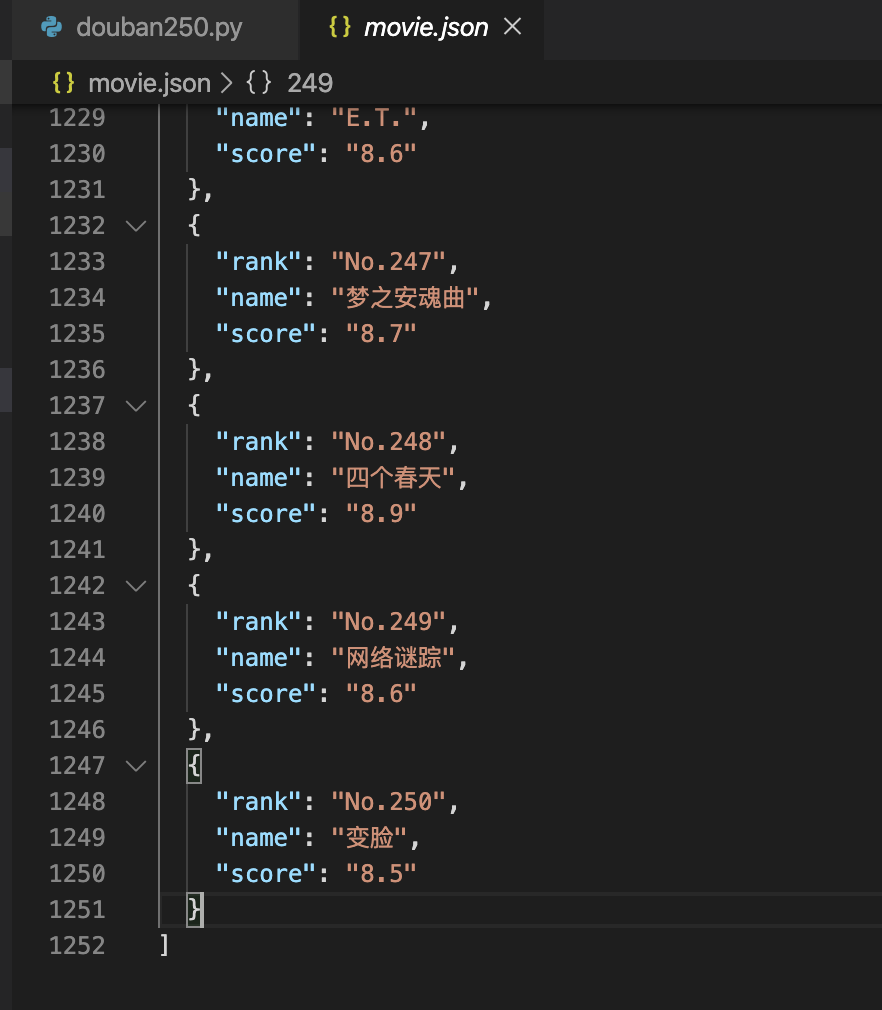
四、總結
以上算是python爬蟲的簡單例子,很多入門python爬蟲的都有拿豆瓣top250列表做為練手對象,如果對python有興趣可以試試。
智能推薦
Python 爬蟲入門實戰
1. 前言 首先自我介紹一下,我是一個做 Java 的開發人員,從今年下半年開始,一直在各大技術博客網站發表自己的一些技術文章,差不多有幾個月了,之前在 cnblog 博客園加了網站統計代碼,看到每天的訪問量逐漸多了起來,就想著寫一個爬蟲,看下具體閱讀量增加了多少,這也就成了本文的由來。 2. 技術選型 爬蟲這個功能,我個人理解是什么語言都能寫的,只要能正常發送 HTTP 請求,將響應回來的靜態頁...
入門python爬蟲
入門Python爬蟲 為了爬新浪體育直播間往年的直播和戰報自學了Python爬蟲,學習期間碰到了很多奇奇怪怪的網頁報錯,所以總結了一篇常用的http狀態碼(參見我另一篇博客),根據這個狀態碼可以輕松發現是網頁打開過程中的那一塊出了問題,現在把整個入門Python爬蟲的過程總結如下: 概述 1.什么是爬蟲 爬蟲,即網絡爬蟲,大家可以理解為在網絡上爬行的一直蜘蛛,互聯網就比作一張大網,而爬蟲便是在這張...
Python爬蟲入門實踐
編譯工具:PyCharm (community edition) 編譯環境:Python 3.6 操作系統:Windows10 專業版 爬取目標:選股寶 的利好消息 需要用到的庫: 為什么要用selenium呢? 答:一個頁面的信息是有限的,我們需要加載更多,而這個東西可以模擬點擊 PS:要模擬點擊還需要下載模擬器對應的driver,這里我用的是Chrome的chromedriver (...
Python爬蟲入門
Python爬蟲介紹 聚焦爬蟲和通用爬蟲 爬蟲根據其使用場景分為通用爬蟲和聚焦爬蟲,兩者區別并不是很大,他們獲取網頁信息的方式是相同的。但通用爬蟲收集網頁的全部信息,而聚焦爬蟲則只獲取和指定內容相關的網頁信息,即需要信息的篩選 爬蟲的工作原理 通用爬蟲是百度谷歌這樣提供搜索服務的公司使用的,他們需要將網上所有的網頁信息通過爬蟲全部抓取并存儲起來,并對這些信息進行分析處理,用戶進行搜索時就把有相關信...
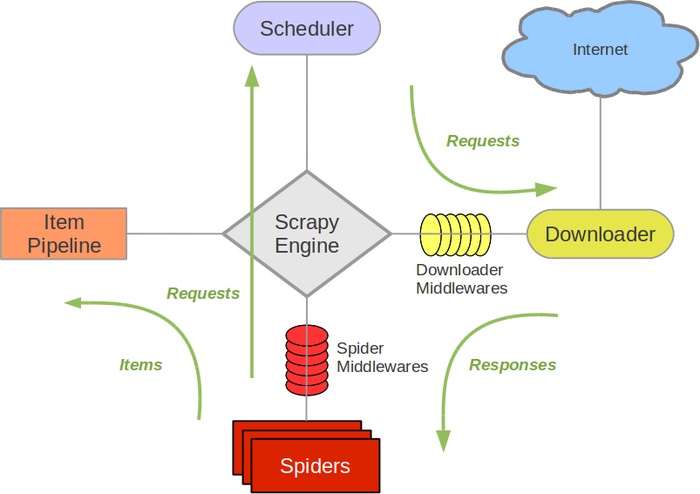
Python爬蟲Scrapy入門
Scrapy組成 Scrapy是Python開發的一個快速、高層次的屏幕抓取和web抓取框架,用于抓取web站點并從頁面中提取結構化的數據。 引擎(Scrapy):用來處理整個系統的數據流,觸發事務(框架核心)。 調度器(Scheduler):用來接受引擎發過來的請求, 壓入隊列中, 并在引擎再次請求的時候返回. 可以想像成一個URL(抓取網頁的網址或者說是鏈接)的優先隊列, 它來決定下一個要抓取...
猜你喜歡
python爬蟲入門
python爬蟲入門 首先注意,學習新東西,需要迅速的成就感,所以有其他編程語言基礎或者略懂的同志們,可以直接上手寫代碼,哪里不會學哪里,先搞個基本例子,有結果的;之后在繼續深入研究; 環境:idea編輯器,python3 1.直接上代碼 這是一個可以直接看到打印結果的菜鳥級爬蟲####打開連接的基本代碼,可以獲取網頁編碼 其實天下文章一大抄,代碼也能先抄抄;先爽了再說; 2.之后可能需要各種py...
Python 爬蟲入門
Python 目前的活躍度逐漸提升 我們應該掌握一些基本的操作 之前對Python的入門做了簡單的學習 ,當然一門語言不可能在這么短的時間內學習完成 ,只是可以在沒有學習完成的情況下使用,去提升學習,我學習爬蟲的最初原因是想寫一個Android的應用程序,奈何缺少數據,才驅使我去學習的(挺賴的…..) 一、 爬蟲入門 爬蟲的大概過程可以總結為: 請求數據源拿到自己想要的數據(一般情況...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...