python爬蟲-淘寶商品比價定向爬蟲
淘寶商品比價定向爬蟲
內容是根據中國大學嵩天老師的python網絡爬蟲與信息提取進行的
視頻課件中的方法失效了,在其基礎上改了一點點。
功能描述:
目的:獲取淘寶搜索頁面信息,提取其中的商品名稱和價格
理解:淘寶搜索接口,翻頁處理
技術路線: requests-re
查看淘寶robots.txt,有協議。。。但還是可以爬= =。。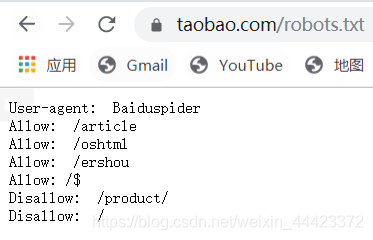
程序的結構設計
步驟1:提交商品搜索請求,循環獲取頁面
步驟2:對于每個頁面,提取商品名稱和價格信息
步驟3:將信息輸出到屏幕上
右鍵查看網頁源代碼,尋找到貨品名稱和價格

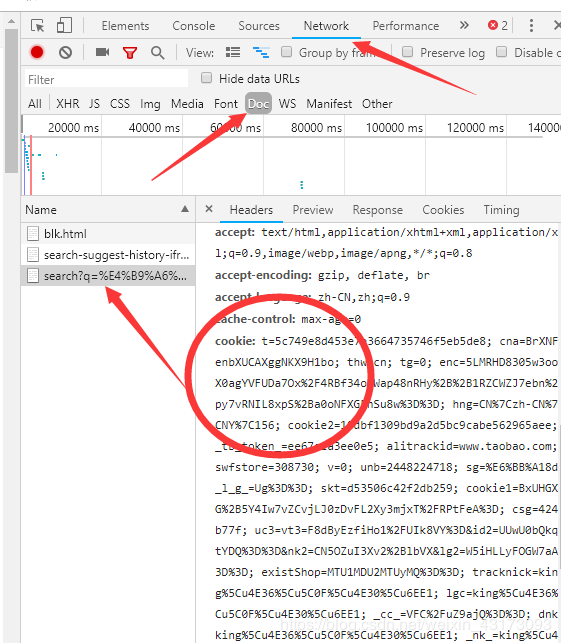
F12,進入開發者工具,點擊網絡。

有很多網站為了防止爬蟲程序爬網站造成網站癱瘓,所以我們的程序在模擬瀏覽器訪問這些網站時,需要攜帶一些headers頭部信息才能訪問,最常見的有User-Agent,referer、cookie等參數。
代碼
# 2.py
import re
import requests
def getHTMLText(url, header):
try:
r = requests.get(url, headers=header, timeout=30)
r.raise_for_status() # 判斷連接是否成功
r.encoding = r.apparent_encoding # 文本分析的編碼代替整體的編碼
return r.text # 輸出文本信息
except:
return ""
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) #解析文本中的view_price鍵的\d.的信息
tlt = re.findall(r'\"raw_title\"\:\".*?\"', html) # 最小匹配,約束商品的名稱
for i in range(len(plt)):
price = eval(plt[i].split(":")[1]) # 去掉view_price鍵,保留價格信息
title = eval(tlt[i].split(":")[1]) # 去掉raw_title鍵, 保留商品名稱
ilt.append([price, title])
except:
print("爬取失敗")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}" # 表頭設計
print(tplt.format("序號", "價格", "商品名稱"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
def main():
goods = "手機" # 爬取對象
depth = 2 # 爬取深度,第一頁和第二頁的信息
start_url = "https://s.taobao.com/search?q=" + goods # 相關的連接
header ={"Cookie": 'JSESSIONID=483114CA54D9E3EC44C678F087A292A2; alitrackid=www.taobao.com; lastalitrackid=www.taobao.com; _uab_collina=157184223096624103121517; cookie2=18b4bb6f781bc90523d10a3bc75c6ce3; v=0; _tb_token_=7e7e170193393; uc1=cookie14=UoTbnKsjIcJqLA%3D%3D; enc=ZXGacx4lpUoTzcd6eCVpx2AKQk6M8DEK7wrqMXInKzXGS5m%2B3aWvlfKtwwKxpn8Rp8mRTbqdEGFdEl7YZqGbOQ%3D%3D; uc4=id4=0%40UgQz0UFPEpG%2BWdxWQjDDNiCiCaVR&nk4=0%40sqg47a58uQ8HocwCGoZeH8s%3D; _cc_=WqG3DMC9EA%3D%3D; isg=BLu7T5gtYnPxGF7G9T5FYH7IU58lEM8SMtysqK15B7rRDNruNuB1Y5ENJmznNycK; thw=cn; uc3=lg2=V32FPkk%2Fw0dUvg%3D%3D&id2=UNN78lQManWbHg%3D%3D&nk2=sFCJrt5N&vt3=F8dByuciblXd1qlDkFA%3D; t=d0fb86b989797ef608dfa76ee5c92457; miid=1527146406316383276; mt=ci=2_1; lgc=%5Cu6709%5Cu69D1%5Cu6709; cna=f1Q3FkMFrCMCATr4aHgzB4Vu; tracknick=%5Cu6709%5Cu69D1%5Cu6709; l=dBQbKy8eqkMEv39YBOfChurza77OuIpT8kPzaNbMiICP_J5p5ShOWZQX5IT9Cn1Vns_D835z8-CXBLgW2yCS0-Y3L3k_J_XredTh.; tg=0; hng=CN%7Czh-CN%7CCNY%7C156',
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763'
} # 發送Headers的請求
infoList = []
for i in range(depth): # 每個頁面單獨進行處理
try:
url = start_url + "&s=" + str(44 * i) # 每個url連接進行設計
html = getHTMLText(url, header) # 獲取網頁
parsePage(infoList, html) # 處理頁面,信息
except: #頁面錯誤判斷,繼續爬取
continue
printGoodsList(infoList)
main()
cookie信息每個人都是不一樣的,上面的是我自己電腦chrome查找到的信息。
結果:


智能推薦
Python爬蟲(九)——京東比價定向爬蟲
文章目錄 Python爬蟲(九)——京東比價定向爬蟲 判斷可行性 查看鏈接 查看robots協議 程序的設計 步驟 方法 def getHTMLText(url) parsePage(ilt, html) printGoodLists(ilt) 完整代碼 Python爬蟲(九)——京東比價定向爬蟲 目標:獲取淘寶搜索頁面的信息,提取其中的商品名稱和價...

爬蟲學習:淘寶商品價格比價
最近在學習爬蟲,看的是嵩天老師的視頻,看到淘寶價格爬取的時候,遇到了問題,視頻中的代碼如下: 但是在爬去過程中,發現獲取的列表為空,獲取的html為搜索頁面,猜想可能是淘寶的反爬機制,要求登錄,這時候看到一篇文章:應對淘寶反爬機制 獲得了解決方案,即在代碼中加入cookie和user-agent: cookie 和 user-agent的獲取方法在鏈接中有,即在登錄淘寶后F12,如圖所示:...

猜你喜歡

freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...