Netty拾遺(八)——編碼與解碼
文章目錄
前言
走到現在,其實應該有一個意識了,針對數據接收端,需要Netty從底層網絡接口中讀取數據,然后將數據讀取到ByteBuf,這個時候依舊是二進制數據,但是有時候我們需要將二進制轉換成對象。針對數據發送端,如果發送的是JavaBean對象,則需要將對象轉換成二進制數據流發送到網絡底層,這就涉及到Netty的編碼器和解碼器的內容,同時針對JavaBean的序列化,又涉及到集成第三方序列化組件的問題。同時這一篇開始,測試不再寫完整的服務端和客戶端了,通過 EmbeddedChannel進行測試。
解碼器
其實關于解碼器,我們在上一篇博客中已經接觸過了,Netty粘包與拆包。其中用到了LineBasedFrameDecoder,DelimiterBasedFrameDecoder,FixedLengthFrameDecoder三種解碼器,其不同的解碼方式,給粘包拆包提供了不同的解決方案。
ByteToMessageDecoder解碼器
這些都是Netty給我們提供的開箱即用的解碼器,但是這幾個類有都繼承于一個類,可以通過類的組成結構圖查看繼承關系。可以看到ByteToMessageDecoder是三種解碼器的基類,同時該類也繼承了ChannelInboundHandler.
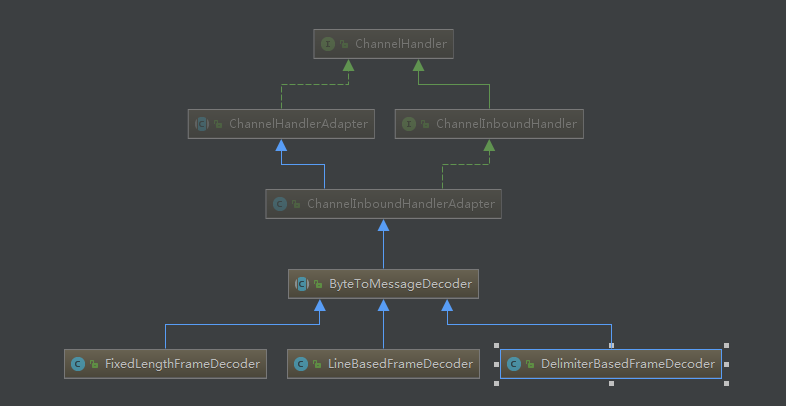
ByteToMessageDecoder解碼器解碼流程其實也和普通的handler差不多,甚至可以簡單的理解為該解碼器就是pipeline中一個普通的handler。ByteToMessageDecoder的解碼流程可以描述為:首先,將上一個Handler傳遞過來的數據輸入到ByteBuf中的數據進行解碼,解碼出一個List對象列表。然后,迭代這個集合列表,逐個將解碼之后的對象傳入到下一個入站處理器。
ByteToMessageDecoder是一個抽象類,具體的解碼方法decode交給了具體的子類去實現。如果我們要自定義解碼器,可以直接繼承ByteToMessageDecoder,然后復寫其中的decode方法即可。
實例
自定義一個解碼器和Handler
/**
* autor:liman
* createtime:2020/9/25
* comment:自定義的解碼器,String解碼器,將byte中的數據,按位轉換成String
*/
@Slf4j
public class IntValuePlus100Decoder extends ByteToMessageDecoder {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
int i = in.readInt();
i = i + 100; //加100,可以看作是個解碼操作
out.add(i);
log.info("解碼之后的數據為:{}", i);
}
}
/**
* autor:liman
* createtime:2020/9/25
* comment:簡單的業務處理,這里接受解碼之后的數據
*/
@Slf4j
public class Byte2CharStringHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.info("處理解碼之后的數據為:{}",msg);
}
}
測試代碼
@Test
public void testAdd100Decoder(){
ChannelInitializer testChannel = new ChannelInitializer<EmbeddedChannel>() {
@Override
protected void initChannel(EmbeddedChannel ch) throws Exception {
ch.pipeline().addLast(new IntValuePlus100Decoder());
ch.pipeline().addLast(new Byte2CharStringHandler());
}
};
//將我們定義的channelInit傳遞給EmbeddedChannel
EmbeddedChannel embeddedChannel = new EmbeddedChannel(testChannel);
int paramValue = new Random().nextInt(39);
log.info("客戶端即將要發送的int數據為:{}",paramValue);
ByteBuf buf = Unpooled.buffer();
buf.writeInt(paramValue);
embeddedChannel.writeInbound(buf);//將buf寫入EmbeddedChannel
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
MessageToMessageDecoder解碼器
前面提到的ByteToMessageDecoder解碼器的作用其實比較簡單,是將ByteBuf的類型轉換成我們需要的Java對象。而MessageToMessageDecoder解碼器的作用其實是將一種Java對象轉換成另外一種Java對象。因此在我們編寫自定義的MessageToMessageDecoder的時候需要指定對象。
具體實例這里不再貼出,大體和ByteToMessageDecoder差不多,這里不再贅述。
多說一句
關于Netty中開箱即用的解碼器,總結到現在,我們其實已經接觸了很多,從粘包和拆包那一篇博客中,我們用到了LineBasedFrameDecoder,DelimiterBasedFrameDecoder和FixedLengthFrameDecoder三個解碼器,其實還有最復雜的一種LengthFieldBasedFrameDecoder解碼器,這個解碼器較為復雜,后續會在序列化一文中進行總結。
編碼器
編碼器主要用于針對出站的數據處理,整體類圖結構如下
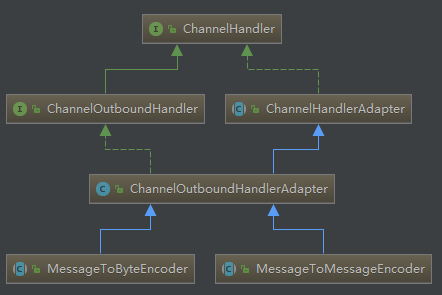
MessageToByteEncoder編碼器
可以通過名稱看出其實就是將一個Java對象編碼成ByteBuf數據包,其實也是一個抽象類,具體的實現會交給之類,比如Netty給我們提供的StringEncoder也繼承這個類。如果我們自己實現編碼器,也只需要繼承這個類即可,大體操作和編碼邏輯和解碼器類似,這里不再貼出實例代碼。
MessageToMessageEncoder編碼器
與解碼器之間的對應關系一樣,MessageToMessageEncoder的作用其實就是將一個Java對象編碼成另一個Java對象,這里不再贅述。
總結
簡單總結了一下編碼和解碼器,大部分參考了《Netty、Redis、Zookeeper高并發實戰》一書。其中還提到了ByteToMessageCodec編解碼器,這個基類中提供了編碼和解碼方法。如果實現了這個類,就不需要單獨編寫解碼器和編碼器。
智能推薦

python拾遺(二)
21、python list 列表中可以用的swap方法 mylist[i], mylist[j] = mylist[j], mylist[i] 這樣就可以swap兩個元素了 還有 a ^= b b ^= a a ^= b 22、python取整及保留小數 23、Python拷貝(深拷貝deepcopy與淺拷貝copy) Python中的對象之間賦值時是按引用傳遞的,如果需要拷貝對象,需要使用標準...

Python拾遺(一)
python扔在一邊很久了,最近剛好有幾天閑,買了本《Head First Python》復習一下。 跟python結緣是因為教C語言的王青老師推薦我們邊學C邊學python,記得說是C結合腳本語言會發揮出比較大的威力,還推薦了一門Coursera上的公開課,名字好像叫how to program,當時只是聽說,因為當時各種狀態,并沒有學。 后來用一個暑假學《learn python the ha...

C語言拾遺
short, long short 和 long 用于修飾整型,和 int 一起使用,但使用時 int 關鍵字可以省略。 short, int, long 在不同的機器架構下占用的長度不同,但一般遵循以下限制:short長度小于等于int,int長度小于等于long,一般short長度至少需要16位,long長度至少需要32位。 extern 引用全局變量(外部變量)時需要先使用 extern 關...

【Practical】Dropout拾遺
文章目錄 早期:Vanilla-Dropout. 現代:Inverted-Dropout. 模型集成角度理解. Dropout & L2-norm. Dropout & GD. 論文資源. 早期:Vanilla-Dropout. 【Dropout思想提出者Hinton在2014年論文中敘述的版本】 訓練過程中獨立地以概率 p p p 保留下每一個神經元,注意這里的 p p p 代表...

猜你喜歡

freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...