Hadoop學習筆記(1)-環境搭建
標簽: Java 工具使用 Hadoop hadoop hdfs
認識Hadoop
簡單描述,Hadoop是一款實現分布式海量數據存儲和離線海量數據分析的工具。官方地址。Hadoop提供的安裝方式有單機模式、偽分布式模式和完全分布式模式,不知道為什么有強迫癥似的,如果有分布式模式必須要安裝完全分布式模式。為了部署完全分布式模式的Hadoop,我采用docker的方式部署3個容器。不得不說docker確實是一個非常適合個人學習的安裝各種軟件的工具,如果你是windows環境,docker可以讓你很方便的安裝一個軟件在Linux系統上。
準備和部署
環境選擇
- 宿主機系統:win10
- hadoop版本:3.1.0
- 容器系統:ubuntu16
- jdk:1.8
安裝包準備
由于我的網絡原因,我選擇預先下載好jdk和hadoop在本地然后用docker來構建Hadoop鏡像。jdk下載地址這里我選擇的是Linux x64的壓縮包,因為我的鏡像以ubuntu16為基礎鏡像,然后Hadoop下載地址。然后將文件和DockerFile一起。
配置文件準備
-
配置core-site.xml
<?xml version="1.0"?> <configuration> <property> <!--指定namenode--> <name>fs.defaultFS</name> <value>hdfs://hadoop-master:9000/</value> </property> </configuration> -
配置hdfs-site.xml
<?xml version="1.0"?> <configuration> <property> <!--指定namenode存放位置--> <name>dfs.namenode.name.dir</name> <value>file:///root/hdfs/namenode</value> <description>NameNode directory for namespace and transaction logs storage.</description> </property> <property> <!--指定hdfs datanode存放位置--> <name>dfs.datanode.data.dir</name> <value>file:///root/hdfs/datanode</value> <description>DataNode directory</description> </property> <property> <!--指定hdfs保存數據的副本數量--> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration> -
mapred.xml
<?xml version="1.0"?> <configuration> <property> <!--配置hadoop(Map/Reduce)運行在YARN上--> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
yarn-site.xml
<?xml version="1.0"?> <configuration> <property> <!--nomenodeManager獲取數據的方式是shuffle--> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <!--指定Yarn的老大(ResourceManager)的地址--> <name>yarn.resourcemanager.hostname</name> <value>hadoop-master</value> </property> </configuration> -
配置Hadoop啟動環境變量
# The java implementation to use. export JAVA_HOME=/usr/lib/jvm/java-se-8u40-ri/ export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"} # Extra Java CLASSPATH elements. Automatically insert capacity-scheduler. for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do if [ "$HADOOP_CLASSPATH" ]; then export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f else export HADOOP_CLASSPATH=$f fi done # Extra Java runtime options. Empty by default. export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true" # Command specific options appended to HADOOP_OPTS when specified export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS" export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS" export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS" export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS" export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS" # The following applies to multiple commands (fs, dfs, fsck, distcp etc) export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS" export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER} export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER} export HADOOP_PID_DIR=${HADOOP_PID_DIR} export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR} # A string representing this instance of hadoop. $USER by default. export HADOOP_IDENT_STRING=$USER export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
Dockerfile文件準備
FROM ubuntu:16.04
MAINTAINER houwanfei
# 安裝openssh-server
RUN apt-get update && apt-get install -y openssh-server
# 配置ssh免密登陸
RUN ssh-****** -t rsa -f ~/.ssh/id_rsa -P '' && \
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 復制jdk和配置jdk環境
RUN mkdir /usr/lib/jvm/
ADD openjdk-8u40-b25-linux-x64-10_feb_2015.tar.gz /usr/lib/jvm/
ENV JAVA_HOME /usr/lib/jvm/java-se-8u40-ri/
ENV PATH $PATH:$JAVA_HOME/bin
# 復制hadoop和配置hadoop配置
RUN mkdir /usr/local/hadoop/
ADD hadoop-3.1.1.tar.gz /usr/local/hadoop/
ENV HADOOP_HOME /usr/local/hadoop/hadoop-3.1.1
ENV PATH $PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 創建hadoop相關文件目錄
RUN mkdir -p ~/hdfs/namenode && \
mkdir -p ~/hdfs/datanode && \
mkdir $HADOOP_HOME/logs
COPY config/* /tmp/
RUN mv /tmp/ssh_config ~/.ssh/config && \
mv /tmp/hadoop-env.sh $HADOOP_HOME/etc/hadoop/hadoop-env.sh && \
mv /tmp/hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml && \
mv /tmp/core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml && \
mv /tmp/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml && \
mv /tmp/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml && \
mv /tmp/workers $HADOOP_HOME/etc/hadoop/workers &&
RUN chmod +x ~/start-hadoop.sh && \
chmod +x $HADOOP_HOME/sbin/start-yarn.sh
# format namenode
RUN $HADOOP_HOME/bin/hdfs namenode -format
CMD [ "sh", "-c", "service ssh start; bash"]
```
文件結構
構建鏡像
# 切換到上圖的文件目錄
docker build -t hou/hadoop .
創建自定義子網
創建自定義docker子網來部署hadoop節點
docker network create –subnet 172.19.0.1/16 hadoop
配置系統路由
hadoop讀寫都是客戶端直連數據節點,因此通過映射容器端口的方式并不適用,因為一個客戶端要讀寫文件時,先請求master節點,master節點告訴客戶端應該去哪臺機器讀寫,但是端口卻是固定的,因此用映射宿主機端口的方式就有問題,因為應用程序不知道你映射了端口,會出現連接的情況。如果是windows環境,這里有一個解決辦法,是將docker的ip加入系統路由,這樣就可以不需要端口映射,直接在宿主機內開發測試。
# 172.19.0.0/16是我自定義的hadoop子網
route add 172.19.0.0/16 mask 255.255.255.0 10.0.75.2
啟動容器
# 啟動master容器
docker run -dit --name hadoop-master --net hadoop --hostname hadoop-master hou/hadoop
# 啟動salve1容器
docker run -dit --name hadoop-salve1 --net hadoop --hostname hadoop-salve1 hou/hadoop
# 啟動salve2容器
docker run -dit --name hadoop-salve2 --net hadoop --hostname hadoop-salve2 hou/hadoop
啟動Hadoop集群
# 進入master容器
docker exec -it hadoop-master /bin/bash
# 進入hadoop目錄的sbin目錄,執行start-all.sh,就可以啟動集群
./start-all.sh
驗證集群啟動成功
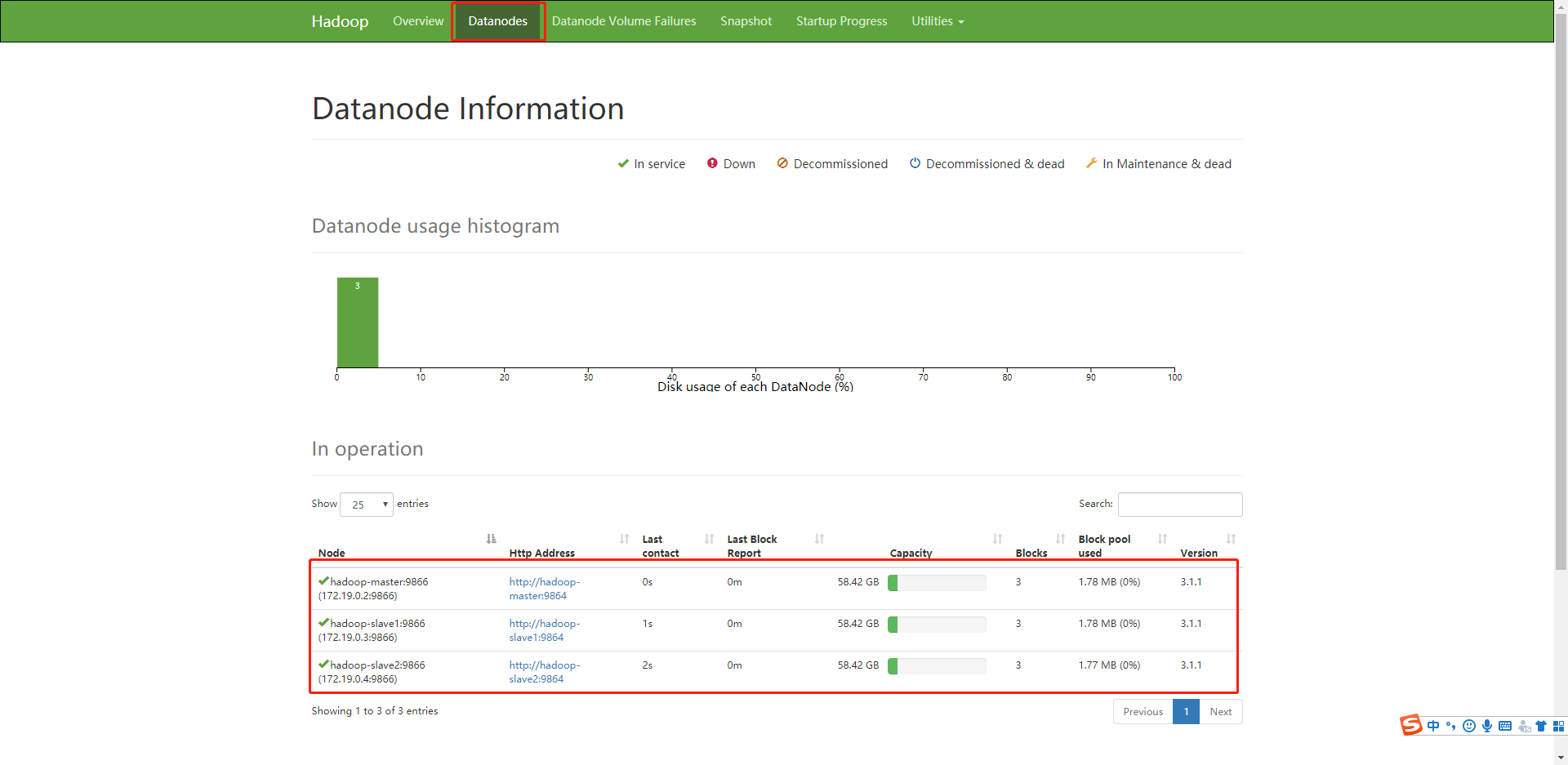
# 瀏覽器輸入,ip要根據自己的,端口hadoop3.0之后管理頁面端口換成了9870
http://172.19.0.2:9870/
結果,點擊datanode,可以看到有三個數據節點,說明啟動成功。
開發第一個HDFS程序
創建一個空的maven項目
加入jar依賴
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
</exclusions>
</dependency>
編寫讀寫hdfs的代碼
package com.hadoop.hadoop_demo.service;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.net.URI;
/**
* @Description
* @auther houwf
* @create 2020-01-15 14:53
*/
public class HdfsService {
private static String hdfsPath = "hdfs://172.19.0.2:9000";
public static Configuration getConfiguration() {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", hdfsPath);
return configuration;
}
/**
* 獲取HDFS文件系統對象
* @return
* @throws Exception
*/
public static FileSystem getFileSystem() throws Exception {
// 客戶端去操作hdfs時是有一個用戶身份的,默認情況下hdfs客戶端api會從jvm中獲取一個參數作為自己的用戶身份
// DHADOOP_USER_NAME=hadoop
// 也可以在構造客戶端fs對象時,通過參數傳遞進去
return FileSystem.get(new URI(hdfsPath), getConfiguration());
}
/**
* 在HDFS創建文件夾
* @param path
* @return
* @throws Exception
*/
public static boolean mkdir(String path) throws Exception {
if (StringUtils.isEmpty(path)) {
return false;
}
if (existFile(path)) {
return true;
}
FileSystem fs = getFileSystem();
// 目標路徑
Path srcPath = new Path(path);
boolean isOk = fs.mkdirs(srcPath);
fs.close();
return isOk;
}
/**
* 判斷HDFS文件是否存在
* @param path
* @return
* @throws Exception
*/
public static boolean existFile(String path) throws Exception {
if (StringUtils.isEmpty(path)) {
return false;
}
FileSystem fs = getFileSystem();
Path srcPath = new Path(path);
boolean isExists = fs.exists(srcPath);
return isExists;
}
public static void createFile(String path, String fileName, String localfile) throws Exception {
FileSystem fileSystem = getFileSystem();
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(localfile)));
Path newPath = new Path(path + "/" + fileName);
FSDataOutputStream outputStream = fileSystem.create(newPath);
String content = null;
while ((content = br.readLine()) != null) {
outputStream.writeBytes(content + "\n");
}
outputStream.close();
fileSystem.close();
}
/**
* 讀文件
*/
public static String readFile(String path) throws Exception {
FileSystem fs = getFileSystem();
Path srcPath = new Path(path);
FSDataInputStream inputStream = fs.open(srcPath);
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
StringBuilder sb = new StringBuilder();
String line = null;
while ((line = reader.readLine()) != null) {
sb.append(line);
}
return sb.toString();
}
public static void main(String[] args) throws Exception {
HdfsService.mkdir("learn");
System.out.println(HdfsService.existFile("learn"));
String loaclFile = "E:/download/madame_bovary.txt";
HdfsService.createFile("learn","madame_bovary", loaclFile);
// System.out.println(HdfsService.readFile("learn/ncdc1901"));
}
}
智能推薦
CentOS 6學習筆記(十四)--CentOS6環境搭建Solr集群(SolrCloud)
安裝 Solr 單機版 建議閱讀我之前發布的筆記: CentOS 6學習筆記(十)–CentOS6環境安裝Solr 搭建 ZooKeeper 集群 建議閱讀我之前發布的筆記: CentOS 6學習筆記(十三)–CentOS6環境搭建ZooKeeper集群 搭建 Solr 集群 (SolrCloud) 本筆記通過在單臺服務器上運行 4 個 Solr 實例的方式來模擬 Solr...
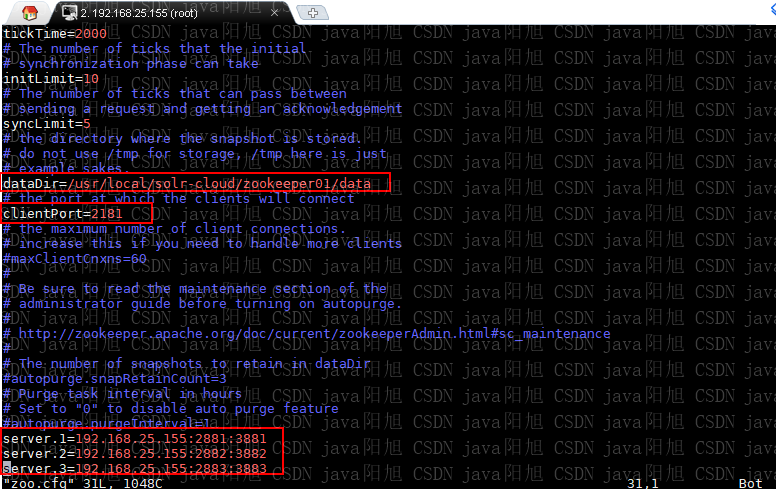
CentOS 6學習筆記(十三)--CentOS6環境搭建ZooKeeper集群
安裝 ZooKeeper 單機版 建議閱讀我之前發布的筆記: CentOS 6學習筆記(六)–CentOS6環境安裝ZooKeeper 搭建 ZooKeeper 集群 本筆記通過在單臺服務器上運行 3 個 ZooKeeper 實例的方式來模擬 ZooKeeper 集群。 本篇筆記是為后續搭建 SolrCloud 做準備。 創建 ZooKeeper 實例 配置 ZooKeeper 實例 ...
CentOS 6學習筆記(十二)--CentOS6環境搭建Redis集群
安裝 Redis 單機版 建議閱讀我之前發布的筆記: CentOS 6學習筆記(九)–CentOS6環境安裝Redis 搭建 Redis 集群 Redis 集群中至少應該有三個節點,要保證集群的高可用,需要每個節點有一個備份機。也就是說,Redis 集群至少需要 6 臺服務器。 本筆記通過在單臺服務器上運行 6 個 Redis 實例的方式來模擬 Redis 集群。 準備工作 安裝 Ru...
opencv學習筆記(一)-- opencv+vs2017環境搭建
opencv+vs2017環境搭建 vs2017的安裝 opencv3.4的安裝 環境配置 添加系統環境變量 vs2017中的配置 vs2017的安裝 這里我用一個在線安裝包安裝,鏈接如下:https://pan.baidu.com/s/1YB6rbQxMfCBs8IlXS_AkQg 提取碼milk 我選擇的是專業版在線安裝,打開之后等一會會出現安裝選擇界面 這里勾選通用windows平臺開發和使...
【TypeScript學習筆記1】WebStorm 2019環境下配置TypeScript項目【非原創】
引言 大概對JavaScript腳本語言了解以后,開始向JS的超集也就是TypeScript領域進軍,此篇筆記是參考Cr博主的TypeScript - (二) 在WebStorm中創建和配置TypeScript項目 本人編寫本博文的用意:2019版本下的WebStorm配置TypeScript資源少,并且作為本人學習筆記,不作其他用意。 運行原理 運行原理都一樣,安裝好node,TypeScrip...
猜你喜歡
【Fabric 1】v1.0環境搭建
基于Ubuntu 16.04 1.安裝docker 2.安裝docker-compose 3.安裝golang 4.從github下載fabric源碼 5.下載fabric docker鏡像 6.查看第5步下載的docker鏡像 7.啟動fabric網絡 8.測試fabric網絡 9.關閉網絡 just go ahead~~~...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...