JavaWeb學習的第九天(可擴展標記語言XML_語法_約束_解析)
標簽: Java修仙之路
一、JS創建對象的兩種方式
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script>
/*JS去創建對象的原型方式*/
var student=new Object();
student.id=1;
student.name="張三";
student.age=20;
console.log(student)
/*JS通過JSON方式創建Js對象第二種方式*/
var student1={id:1,name:"張三",age:20};
var student2={id:2,name:"李四",age:21};
var student3={id:3,name:"王五",age:22};
var arr=["a","b","c"];
var arr=[{id:1,name:"張三",age:20},{id:2,name:"李四",age:21},{id:3,name:"王五",age:22}];
console.log(arr)
/*JSON本身是JS創建對象的一種方式,本質是JS里面的對象表示法*/
</script>
</head>
<body>
</body>
</html>
運行結果截圖

二、XML概述
1.什么是XML
HTML:網頁中展示數據,HTML語法松散,
XML(擴展標記語言),一開始出現是為了替換HTML,語法非常嚴格
XML被設計用來傳輸和存儲數據
在網絡中傳輸數據用兩種方式json和xml,但是現在一般的傳輸數據是用JSON
XML一般用于存儲數據,主要用于配置文件
XML的可用標簽是固定的,元素數量不是固定的
2.XML的基本語法
1.1 xml文檔的后綴名 .xml
1.2 xml第一行必須定義為文檔聲明
1.3 xml文檔中有且僅有一個根標簽
1.4 屬性值必須使用引號(單雙都可)引起來
1.5 標簽必須正確關閉
1.6 xml標簽名稱區分大小寫
注意:滿足語法規則的xml文檔,我們稱之為格式良好的xml
3.XML的文檔聲明
3.1 文檔聲明:通常出現在XML的第一行第一列的位置!!!
3.2 寫法:<?xml 屬性名=”屬性值” 屬性名=”屬性值” ...?>
version:必須的.使用”1.0”
encoding:字符集.是使用瀏覽器打開的時候采用的默認的字符集的編碼.
standalone:描述XML文檔是否需要依賴其他的文件.
3.3 xml中導入外部樣式表:<?xml-stylesheet type="text/css" href="test.css" ?>
4.XML的注釋
<!-- XML的注釋 -->
5.XML的元素
4.1 名稱可以包含字母、數字以及其它的字符
4.2 名稱不能以數字或者標點符號開始
4.3 名稱不能以字符“xml”(或者XML、Xml) 開始
4.4 名稱不能包含空格
6.XML的屬性
6.1 屬性的名稱規范與元素一致.
6.2 必須用引號引起來
7.XML的特殊字符和CDATA區
< | < | 小于
> | > | 大于
& | & | 和號
'| ' | 單引號
"| " | 引號
假如您在 XML 文檔中放置了一個類似 "<" 字符,那么這個文檔會產生一個錯誤,這是因為解析器會把它解釋為新元素的開始。因此你不能這樣寫:
<message>if salary < 1000 then</message>
為了避免此類錯誤,需要把字符 "<" 替換為實體引用,就像這樣:
<message>if salary <1000 then</message>
XML的CDATA區:(CDATA:Character Data) <![CDATA[ 內容 ]]>
<script>
<![CDATA[function matchwo(a,b){if (a < b && a < 0){return 1}else{return 0}}]]>
</script>
在上面的例子中,在 CDATA 區段中的所有東西都會被解析器忽略。
三、XML的約束
1.為什么會有XML的約束
<!--XML作為配置文件給框架提供載體,XML文檔中的標簽應該是固定的-->
<!--如何規定在一個XML中只能寫某一些東西,不能寫另外的一些東西??-->
<!--提供了一種機制-XML約束(會用)-->
2.什么是XML的約束
就是用來約束XML的文檔中可以出現哪些標簽,不能出現哪些標簽,標簽中是否有順序,出現的次數.
XML的約束:用來規范XML的寫法.
3.Xml約束有兩種分類
1. DTD(簡單約束)
2. Schema約束(比DTD更加復雜,約束的更加細致)
4.DTD引入的兩種方式
DTD的引入方式:
內部的DTD:<!DOCTYPE persons [要寫的約束]>
外部的DTD:
一種本地DTD:<!DOCTYPE persons SYSTEM "mybatis.dtd">
一種網絡DTD:<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
實例說明
<?xml version="1.0" encoding="UTF-8" ?>
<!--文檔內部引入-->
<!DOCTYPE student [
<!ELEMENT student (to,from,heading,body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)>
]>
<student>
<to>George</to>
<from>John</from>
<heading>Reminder</heading>
<body>Don't forget the meeting!</body>
</student>
<?xml version="1.0" encoding="UTF-8" ?>
<!--外部引入本地DTD文檔-->
<!DOCTYPE student SYSTEM "student01.dtd">
<!--system:本地的,public:網絡上的-->
<student>
<to></to>
<from></from>
<heading></heading>
<body></body>
</student>
<!--外部引入網絡DTD文檔-->
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
5.Schema引入的方式
<?xml version="1.0" encoding="UTF-8" ?>
<beans xmlns="http://www.springframework.org/schema/bianyiit/spring"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/bianyiit/spring
spring_beans1.xsd">
<bean></bean>
</beans>
實例說明
<!--spring.xml-->
<?xml version="1.0" encoding="UTF-8" ?>
<!--引約束文件-->
<beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.springframework.org/schema/beans"
xmlns:tt="http://www.springframework.org/schema/bianyiit/spring"
xsi:schemaLocation="
http://www.springframework.org/schema/bianyiit/spring spring_beans1.xsd
http://www.springframework.org/schema/beans spring_beans.xsd">
<tt:bean></tt:bean>
</beans>
<!--在根標簽beans上去引外部配置文件-->
<!--namespace:名稱空間,文檔的全限定類名,唯一可以指向文檔的名稱
在xsd約束中會定義一個全限定類名:targetNamespace="http://www.springframework.org/schema/beans"-->
<!--schemaLocation位置:指定上面的名稱空間的位置-->
spring_beans.xsd(注意Schema約束文檔的后綴名為xsd)
spring_beans1.xsd
注意:上述圖片只是XML約束文檔的部分截圖
四、XML的解析
2.XML提供了兩種解析方式--DOM解析和SAX解析
3.DOM解析方式的原理
3.1 DOM解析方式的原理,先一次性將xml文檔加載到內存,形成一顆DOM樹
3.2 document對象代表著整個文檔,xml只有一個根節點root,根節點下面會有很多子節點
3.3 XMLDOM樹的結構如下所示
<root>
<child>
<subchild>.....</subchild>
</child>
</root>
3.4 通過document對象獲取整個xml的文檔,再通過分別document對象調用方法分別獲取各個標簽,屬性以及文本的內容
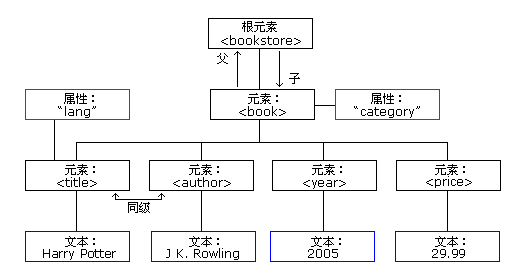
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
4.SAX解析方式的原理
1. 沒解析到根標簽之前,讀出第一行<?xml version="1.0" encoding="UTF-8" ?>發出一個解析開始文檔的事件,
2. 當讀到根標簽的時候,發出一個解析開始標簽的事件student,
3. 又會向下解析另外一個開始標簽的事件student,
4. 然后發出一個解析標簽name的事件,
5. 下一次發出一個解析文本name里面的張三的標簽,
6. 當解析到</student>的結束標簽,
7. 最后到一個結束文檔的標簽
SAX解析圖解如下

5.兩種解析方式之間的區別(面試題)
DOM解析的特點:
1.需要一次性將文檔加載至內存,形成DOM樹,消耗內存空間
2.方便進行文檔的增刪改...操作
SAX解析的特點:
1.基于事件驅動逐行解析,比較節省內存空間
2.不能進行文檔的增刪改,只能進行查詢的操作
6.針對這兩種解析的方式,不同的公司提供了不同的API的實現.
* JAXP :SUN公司提供的一套XML的解析的API.
* JDOM :開源組織提供了一套XML的解析的API-jdom.
* DOM4J :開源組織提供了一套XML的解析的API-dom4j (現在一般使用這種方式解析XML配置文件)
* Jsoup :html解析器,也可以用來解析xml
* pull :主要應用在Android手機端解析XML.
7.解析實例演示
DOM4J的入門案例步驟:
* 【步驟一】導入jar包.dom4j-1.6.1.jar
* 【步驟二】創建解析器
* 【步驟三】解析文檔獲得代表文檔的Document對象.
* 【步驟四】獲得跟節點.
* 【步驟五】從跟節點下查找其他的節點.
下載并導入解析XML時需要用的幾個jar包
鏈接:https://pan.baidu.com/s/1u0q5-TAofJh4y439Tu_57w
提取碼:hbro
復制這段內容后打開百度網盤手機App,操作更方便哦
<?xml version="1.0" encoding="UTF-8" ?>
<student>
<student id="1">
<name>張三</name>
<age>20</age>
</student>
<student id="2">
<name>李四</name>
<age>18</age>
</student>
</student>
package com.bianyiit.cast;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.junit.Test;
import java.io.InputStream;
import java.util.List;
public class Demo4J {
@Test
public void test2() throws DocumentException {
/*1.創建解析器對象*/
SAXReader saxReader=new SAXReader();
InputStream inputstream = Demo4J.class.getClassLoader().getResourceAsStream("xml01.xml");
Document document=saxReader.read(inputstream);
/*3.獲取文檔的根節點*/
Element rootElement=document.getRootElement();
List<Element> elements = rootElement.elements();
for (Element element : elements) {
String id = element.attribute("id").getValue();
Element nameElement = element.element("name");
String name = nameElement.getTextTrim();
Element ageElement = element.element("age");
String age = ageElement.getTextTrim();
System.out.println("id:"+id+"name:"+name+"age:"+age);
}
}
@Test
public void test1() throws DocumentException {
/*1.創建解析器對象*/
SAXReader saxReader=new SAXReader();
/*2.通過解析器加載文件*/
String path = Demo4J.class.getClassLoader().getResource("xml01.xml").getPath();
Document document=saxReader.read(path);
/*3.獲取文檔的根節點*/
Element rootElement=document.getRootElement();
/*4.獲取元素內容*/
String name=rootElement.getName();
System.out.println(name);
}
@Test
public void test3() throws DocumentException {
/*1.創建解析器對象*/
SAXReader saxReader = new SAXReader();
/*2.通過解析器加載文件*/
String path = Demo4J.class.getClassLoader().getResource("xml01.xml").getPath();
Document document = saxReader.read(path);
/*selectNodes方法是demo4J提供的對xpath的支持方式*/
/*List<Element> list = document.selectNodes("/student/student/name");
for (Element element : list) {
System.out.println(element.getTextTrim());
String name = element.attribute("name").getValue();
System.out.println(name);
}*/
Element node = (Element) document.selectSingleNode("//student[@id='1']");
Element name = node.element("name");
String textTrim = name.getTextTrim();
System.out.println(textTrim);
/*/一定是從文件的開始位置找的 //從文件的任意位置開始找的*/
}
}
三個單元測試代碼的結果依次截圖如下:
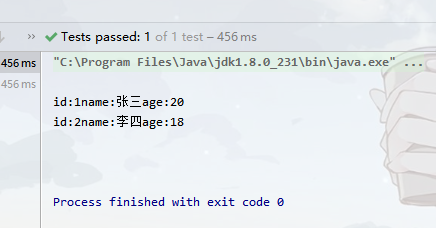


注意:selectNodes方法是demo4J提供的對xpath的支持方式,可以讓程序員能夠讓XML的任意位置開始查找節點元素
智能推薦

java基礎學習第九天
1.ArrayList 1.1ArrayList類概述 什么是集合 ? 提供一種存儲空間可變的存儲模型,存儲的數據容量可以發生改變 ArrayList集合的特點 ? 底層是數組實現的,長度可以變化 泛型的使用 ? 用于約束集合中存儲元素的數據類型 1.2ArrayList類常用方法 1.2.1構造方法 方法名 說明 public ArrayList() 創建一個空的集合對象 1.2.2成員方法 方...
Andriod Studio學習筆記第九天
底部導航的實現(BottomNavigationView使用練習) 一、簡述: 1.創建一個菜單Menu,添加Bottom的四個Item。 2.創建四個LayoutXML,并用Fragment加載。 3.主界面:ViewPager+BottomNavigationView,BottomNavigationView靜態調用Menu,ViewPager動態調用4個Fragment。 4.主程序:創建F...
以太坊學習第九天
開學了,ctf比賽加上課程,就沒怎么看合約了。 (實話是打游戲呢) 今天復習下之前的東西,順便把web3.js開進去。 按照課程進度,接下來會用truffle寫一個投票dapp的demo。 還是一如既往的遇到很多坑。 (接下來還是記錄的詳細點吧。過了這么多天回來看之前的記錄都看不懂了…) ——————&mdash...

Springboot開心學習(第九天)
文章目錄 1. SpringBoot整合Spring Data JPA 1.1 新增數據 1.2 修改 1.3 刪除操作 1.4 查詢操作 1.4.1 簡單查詢 1.4.2 排序查詢 1.4.3 分頁查詢 1.4.4 Spring Data JPA關鍵字定義查詢 1.4.5 Spring Data JPA自定義查詢SQL 1.4.5 Spring Data JPA自定義數據修改 2. Spring...
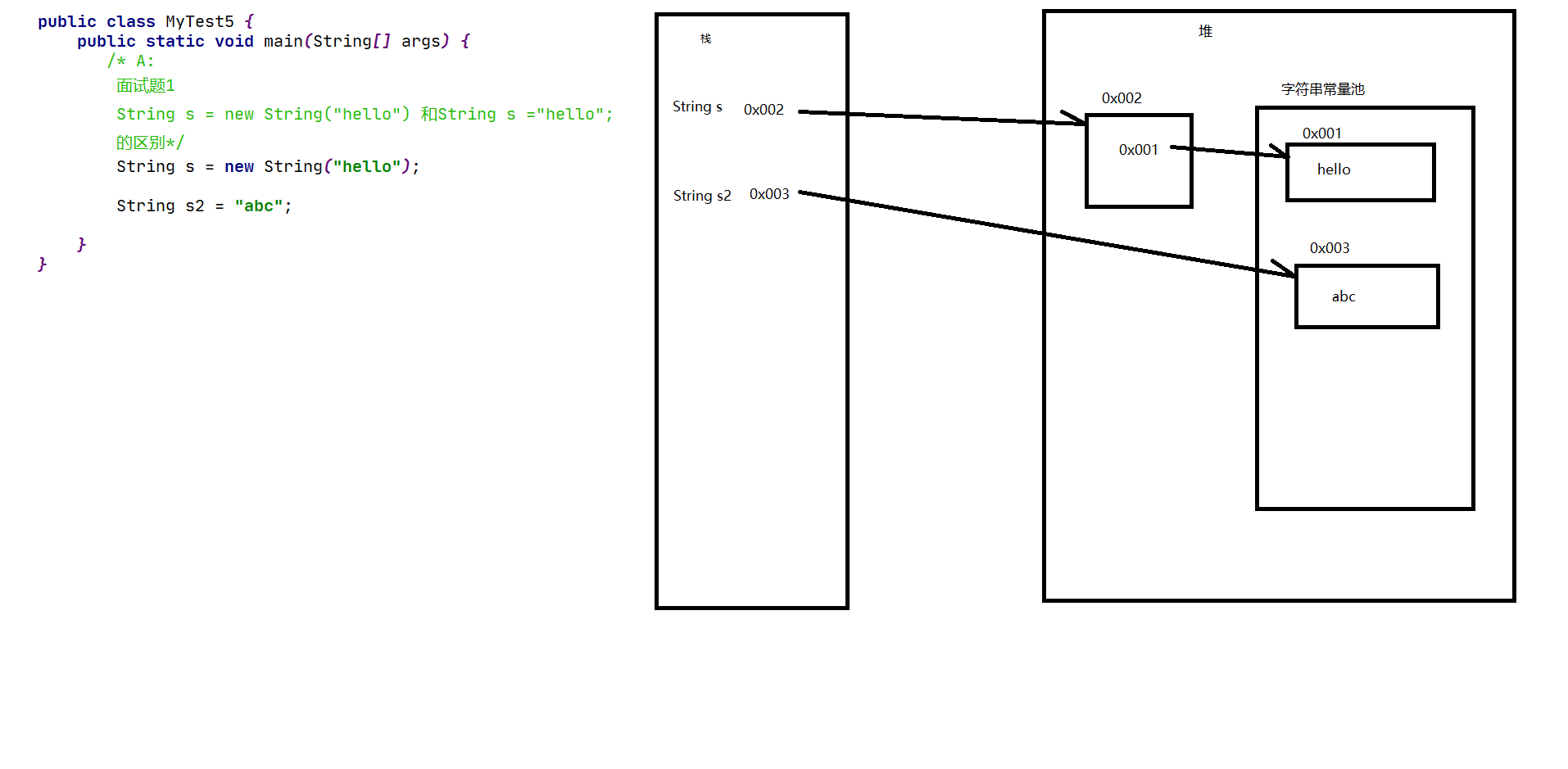
JAVA第九天學習之String類
bJAVA第九天學習之String類 String字符串:由一個或者多個字符組成的序列,可以看成是一個帶有索引的字符數組 ? String() 初始化一個新創建的 String 對象,使其表示一個空字符序列。 把字節數組轉成字符串 ? 運行結果:abcd ? 你 把字符數組轉換成字符串 運算結果:abcd你好 ? 你好 String s = new String(“hello&rdqu...
猜你喜歡


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...
