1.1 大數據 從0到1環境搭建HADOOP偽分布式 hadoop-3.2.1
標簽: 大數據
文章目錄
1、虛擬機安裝
VMware-workstation-full-15.5.0-14665864 網盤秘鑰
2、虛擬機信息獲取
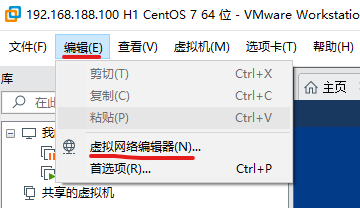
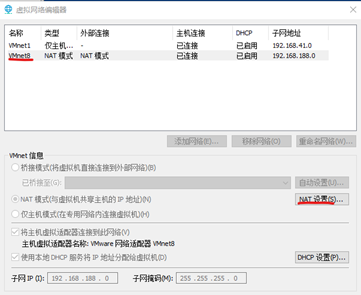
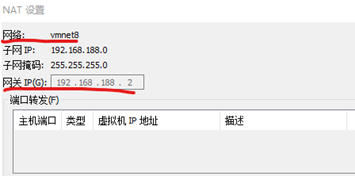
獲取網關
3、操作系統
192.168.188.100 H1 CentOS 7 64 位 按照網上教程安裝 我安裝的有桌面的
http://mirrors.aliyun.com/centos/
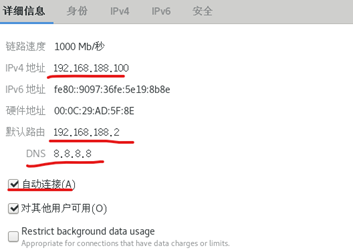
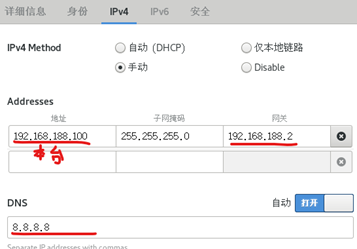
注意網絡配置 外面設置
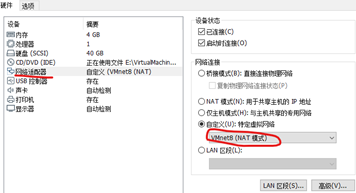
里面設置網卡 路由網關和先前一致
4、shh工具
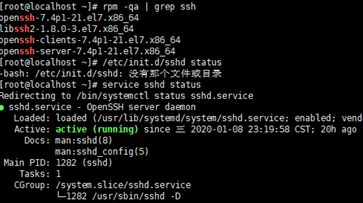
里面查看下是否安裝 rpm -qa | grep ssh
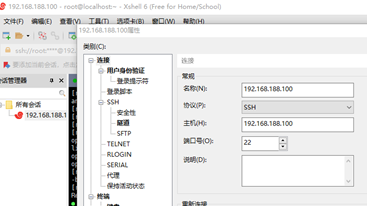
Windows安裝Xshell工具連linux
Windows安裝Xftp外面可以界面傳輸包到linux
5、查看 rpm -qa | grep pdsh 木得
yum install pdsh 安裝失敗
6、 yum安裝很多木得,先安裝rpm包
yum -y install epel-release
yum clean all && yum makecache
再試 :yum install pdsh 安裝成功
7、安裝或查看java -version

8、變更JAVA 為linux版本 支持更穩定
rpm -qa | grep java
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.221-2.6.18.1.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.222.b03-1.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.221-2.6.18.1.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.222.b03-1.el7.x86_64
mkdir -p /usr/local/java
tar -zxvf jdk-8u231-linux-x64.tar.gz -C /usr/local/java
vim /etc/profile
底部插入
export JAVA_HOME=/usr/local/java/jdk1.8.0_231
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile

9、新建hadoop用戶以及用戶組,給予sudo權限
sudo usermod -a -G hadoop hadoop
sudo nano /etc/sudoers
在 root ALL=(ALL) ALL 下面添加:(復制里面的 不然容易出錯)
hadoop ALL=(ALL) ALL
10、建個hadoop文件夾 授權給hadoop用戶
mkdir -p /usr/local/hadoop
chown -R hadoop:hadoop /usr/local/hadoop
11、用hadoop用戶 操作 解壓
su hadoop
tar -zxvf hadoop-3.2.1.tar.gz -C /usr/local/hadoop
12、后續直接參照官網即可:
Prepare to Start the Hadoop Cluster
Unpack the downloaded Hadoop distribution. In the distribution, edit the file etc/hadoop/hadoop-env.sh to define some parameters as follows: set to the root of your Java installation
export JAVA_HOME=/usr/java/latest
Try the following command:
$ bin/hadoop
Standalone Operation
By default, Hadoop is configured to run in a non-distributed mode, as a single Java process. This is useful for debugging.
The following example copies the unpacked conf directory to use as input and then finds and displays every match of the given regular expression. Output is written to the given output directory.
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
$ cat output/*
Pseudo-Distributed Operation
Hadoop can also be run on a single-node in a pseudo-distributed mode where each Hadoop daemon runs in a separate Java process.
Configuration
Use the following:
etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Setup passphraseless ssh
Now check that you can ssh to the localhost without a passphrase:
$ ssh localhost
If you cannot ssh to localhost without a passphrase, execute the following commands:
$ ssh-****** -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
Execution
The following instructions are to run a MapReduce job locally. If you want to execute a job on YARN, see YARN on Single Node.
- Format the filesystem:
$ bin/hdfs namenode -format
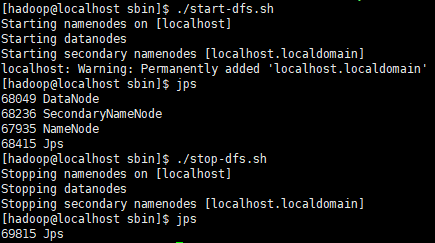
- Start NameNode daemon and DataNode daemon:
$ sbin/start-dfs.sh
The hadoop daemon log output is written to the $HADOOP_LOG_DIR directory (defaults to $HADOOP_HOME/logs).
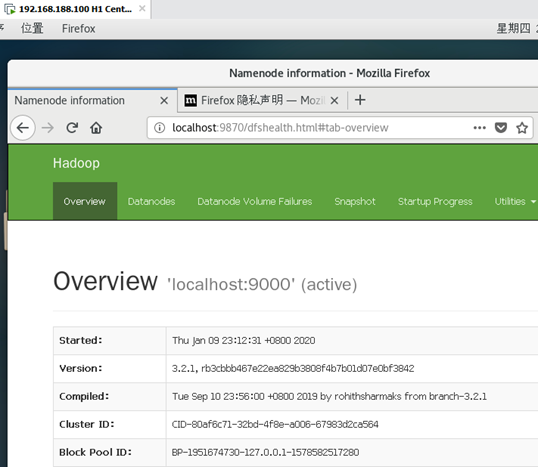
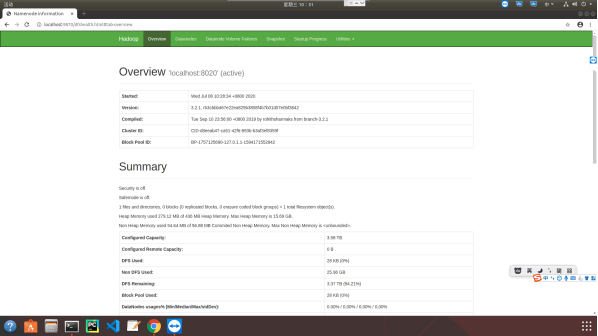
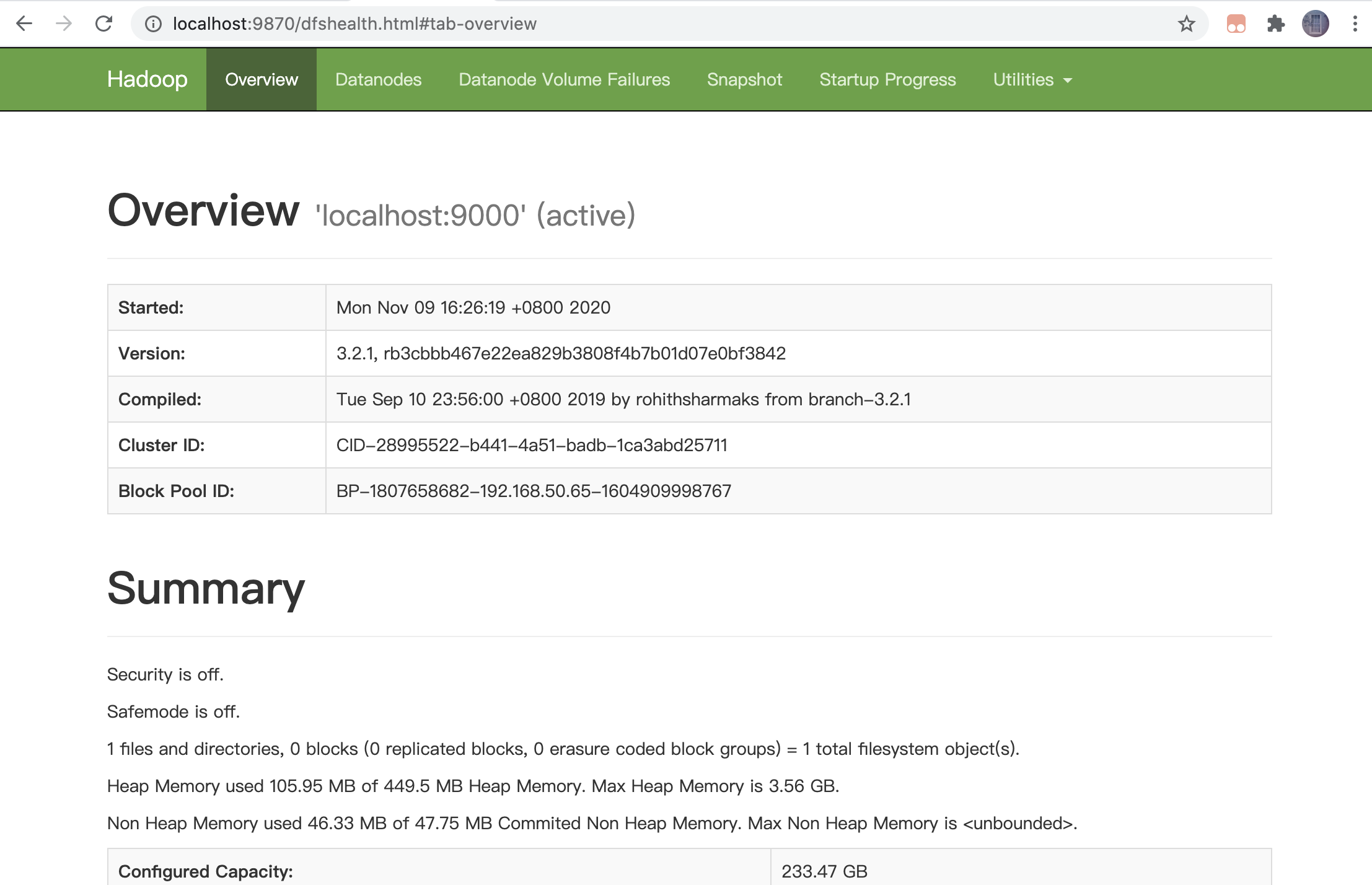
3. Browse the web interface for the NameNode; by default it is available at:
a. NameNode - http://localhost:9870/ 在虛擬機里面瀏覽器登錄
- Make the HDFS directories required to execute MapReduce jobs:
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/<username>
- Copy the input files into the distributed filesystem:
$ bin/hdfs dfs -mkdir input
$ bin/hdfs dfs -put etc/hadoop/*.xml input
- Run some of the examples provided:
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
- Examine the output files: Copy the output files from the distributed filesystem to the local filesystem and examine them:
$ bin/hdfs dfs -get output output
$ cat output/*
or
View the output files on the distributed filesystem:
$ bin/hdfs dfs -cat output/*
- When you’re done, stop the daemons with:
$ sbin/stop-dfs.sh
本地 /usr/local/hadoop/hadoop-3.2.1/sbin/./stop-dfs.sh
YARN on a Single Node
You can run a MapReduce job on YARN in a pseudo-distributed mode by setting a few parameters and running ResourceManager daemon and NodeManager daemon in addition.
The following instructions assume that 1. ~ 4. steps of the above instructions are already executed.
- Configure parameters as follows:
etc/hadoop/mapred-site.xml:
cd /usr/local/hadoop/hadoop-3.2.1/etc/hadoop/
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
etc/hadoop/yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
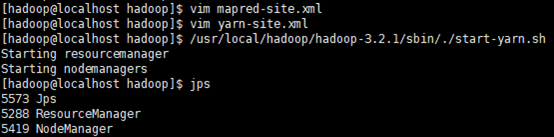
- Start ResourceManager daemon and NodeManager daemon:
$ sbin/start-yarn.sh
/usr/local/hadoop/hadoop-3.2.1/sbin/./start-yarn.sh
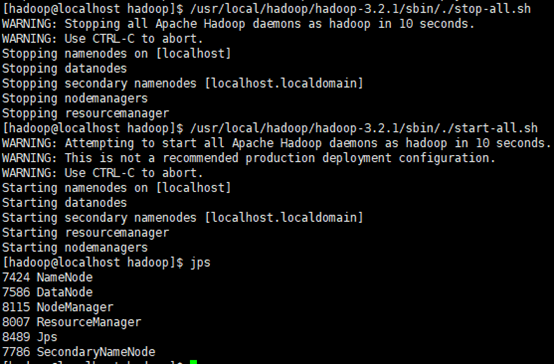
/usr/local/hadoop/hadoop-3.2.1/sbin/./stop-all.sh
/usr/local/hadoop/hadoop-3.2.1/sbin/./start-all.sh
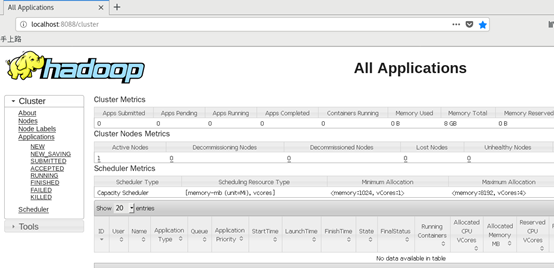
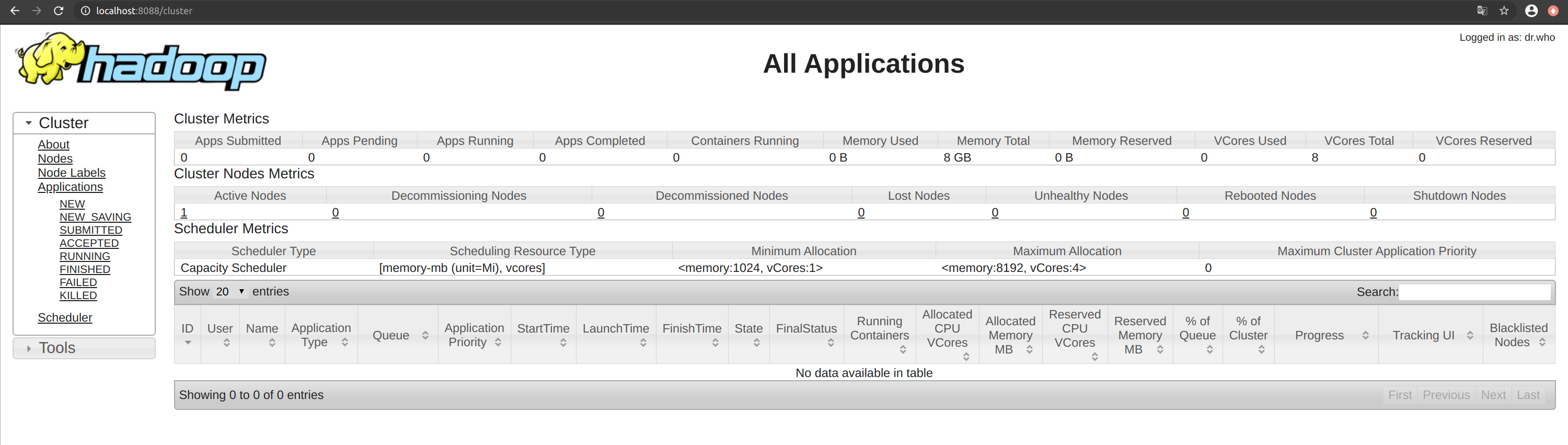
 3. Browse the web interface for the ResourceManager; by default it is available at:
3. Browse the web interface for the ResourceManager; by default it is available at:
o ResourceManager - http://localhost:8088/
4. Run a MapReduce job.
5. When you’re done, stop the daemons with:
$ sbin/stop-yarn.sh
13、安裝成功
智能推薦
安裝Hadoop3.2.1(很多坑)
安裝Hadoop3.2.1(很多坑) 從官網下載hadoop包,hadoop-3.2.1.tar.gz ,342.56M 931KB/s 用時 8m 19s 解壓,路徑為/home/wang/hadoop/hadoop-3.2.1 設置環境變量 加入以下設置 生效 不成功的話,修改權限, 改密碼:123456 檢查環境變量是否設置成功 報錯:ERROR: JAVA_HOME is not set ...
Ubuntu 20.04.1 LTS 安裝 Hadoop3.2.1
文章目錄 大數據學習之路之基于Ubuntu20.04.1 LTS安裝 Hadoop3.2.1 環境準備 軟件準備 解壓Hadoop文件 設置Hadoop單機環境(獨立模式) 配置Hadoop環境變量 啟動hadoop 停止Hadoop 總結 大數據學習之路之基于Ubuntu20.04.1 LTS安裝 Hadoop3.2.1 大數據學習之路之基于Ubuntu20.04.1 LTS安裝 Hadoop3...
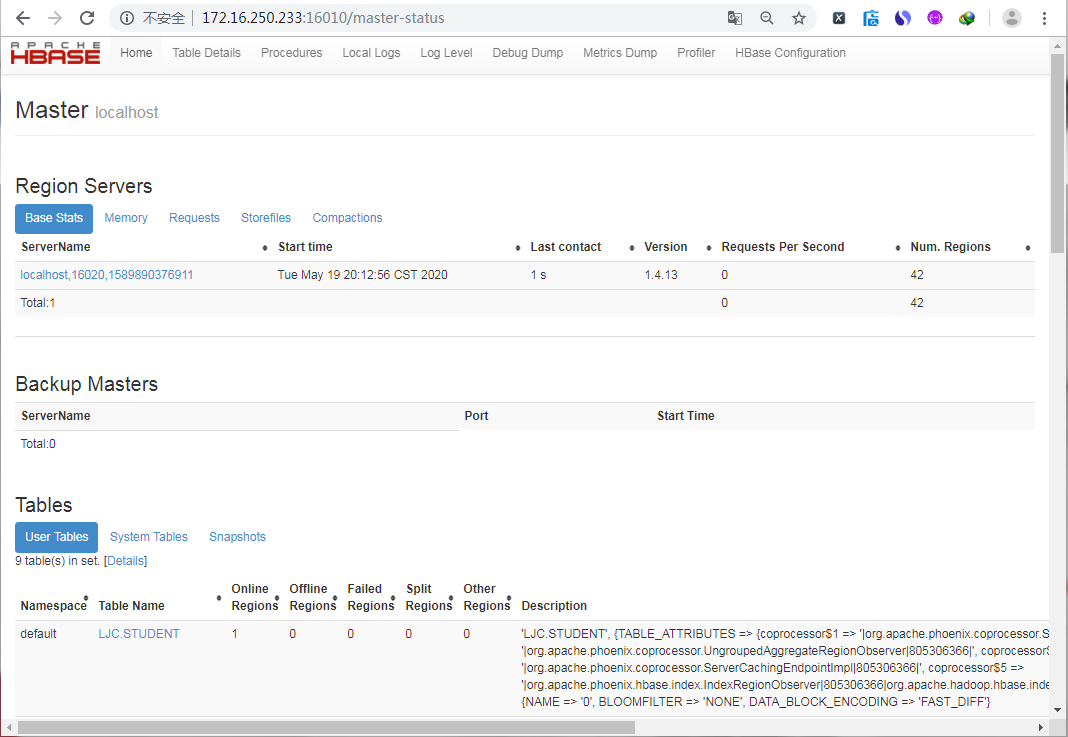
Hadoop3.2.1環境下安裝HBase
環境準備 Linux:CentOS Linux release 7.2.1511 (Core) # 使用 cat /etc/redhat-release 命令查看 JDK:jdk1.8.0_211 Hadoop:3.2.1 Zookeeper:3.4.14 HBase:1.4.13 安裝步驟 下載安裝包 修改配置 進入hbase的conf目錄,修改如下幾個配置文件。 hbase-env.sh &n...
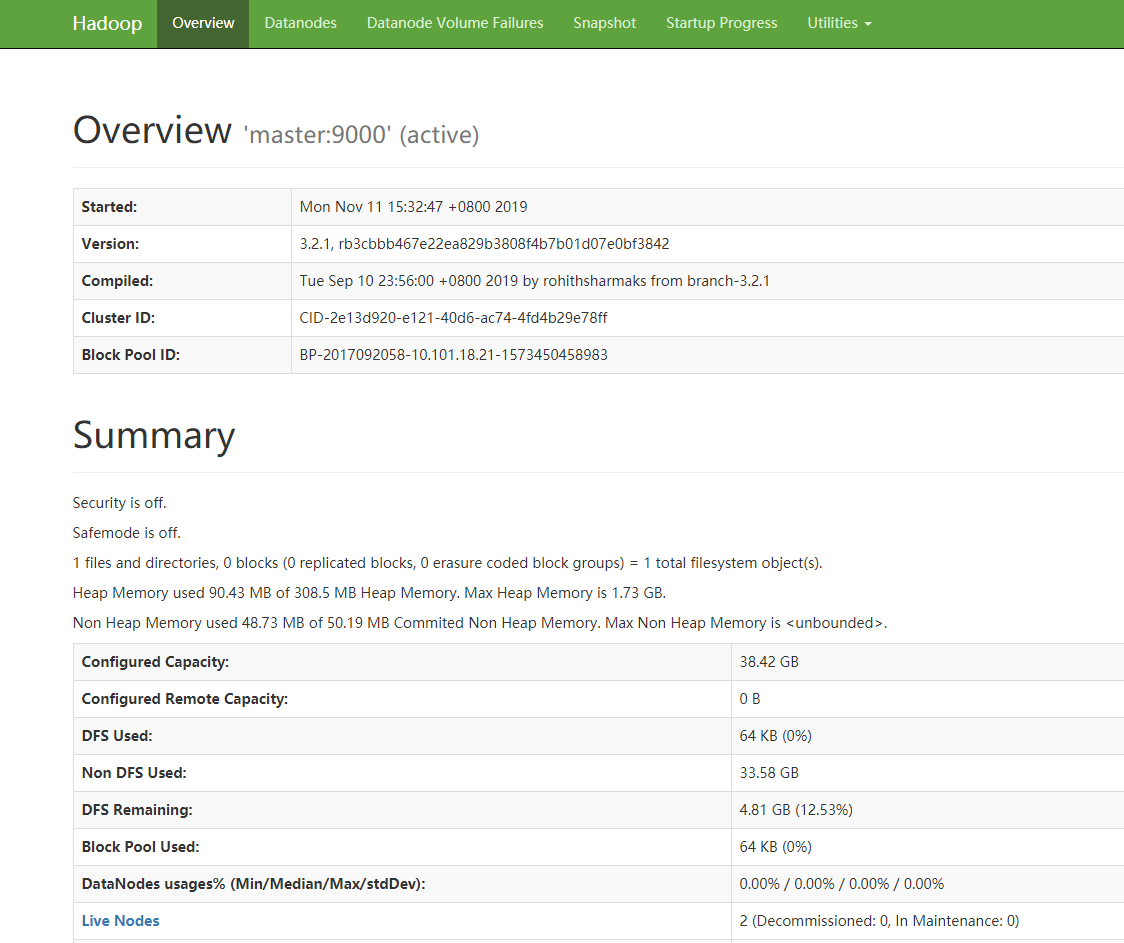
mac搭建hadoop3.2.1——偽分布模式
1 homebrew安裝 安裝完畢后使用brew doctor查看是否安裝成功 2 設置ssh免密登錄 因為hadoop中,在啟動datanode、namenode時都需要免密登錄,不設置,則會出現Permission denied的錯誤提示,導致無法啟動DataNode。 設置免密登錄: 之后再使用ssh localhost命令,直接可以登錄: 3 安裝Hadoop 首先要在電腦中成功安裝jdk...
Hadoop3.2.1版本的環境搭建
最近有人提出能不能發一些大數據相關的知識,No problem ! 今天先從安裝環境說起,搭建起自己的學習環境。 Hadoop的三種搭建方式以及使用環境: 單機版適合開發調試; 偽分布式適合模擬集群學習; 完全分布式適用生產環境。 這篇文件介紹如何搭建完全分布式的hadoop集群,一個主節點,兩個數據節點。 先決條件 準備3臺服務器 虛擬機、物理機、云上實例均可,本篇使用Openstack私有云里...
猜你喜歡
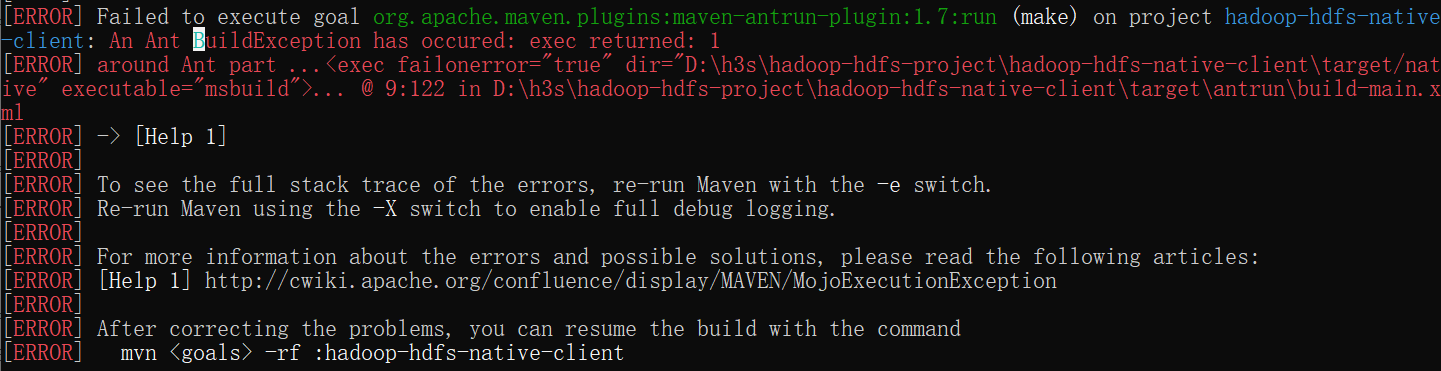
win10下編譯hadoop3.2.1源碼成功
測試一番后,整理干貨如下: 1.BUILDING.txt Building on Windows Requirements: Windows System JDK 1.8 Maven 3.0 or later ProtocolBuffer 2.5.0 CMake 3.1 or newer Visual Studio 2010 Professional or Higher Windows SDK 8...
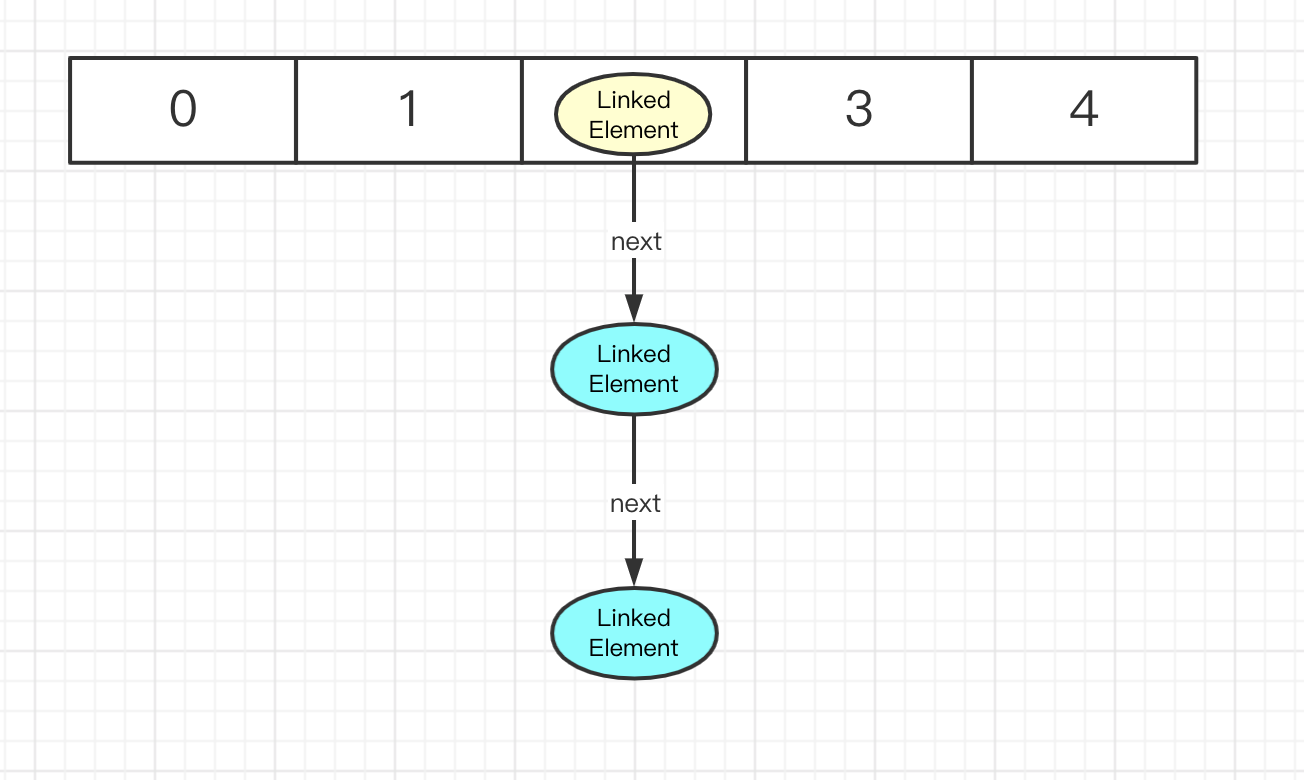
Hadoop3.2.1 【 HDFS 】源碼分析 : BlocksMap解析
一.概述 BlocksMap是Namenode上與數據塊相關的最重要的類, 它管理著Namenode上數據塊的元數據, 包括當前數據塊屬于哪個HDFS文件, 以及當前數據塊保存在哪些Datanode上。 當Datanode啟動時, 會對Datanode的本地磁盤進行掃描, 并將當前Datanode上保存的數據塊信息匯報到Namenode。 Namenode收到Datanode的匯報信息后, 會建立...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...