Python第三方庫pandas學習筆記
標簽: Python學習 數據分析 python pandas
Python第三方庫pandas學習筆記
pandas簡介
都一起學習pandas了,肯定對這個庫有所了解了。
pandas操作命令
pandas的常用數據類型
在講基本操作的時候,我們應該先對要操作的東西有個了解。相比起numpy,pandas能夠操作的數據類型更加多樣。而在pandas中,數據通常通過兩種方式進行組織。
- Series,一維的帶標簽數組
- DataFrame,二維的Series容器
下面這個圖能夠很直觀地看出兩種數組組織方式的特點
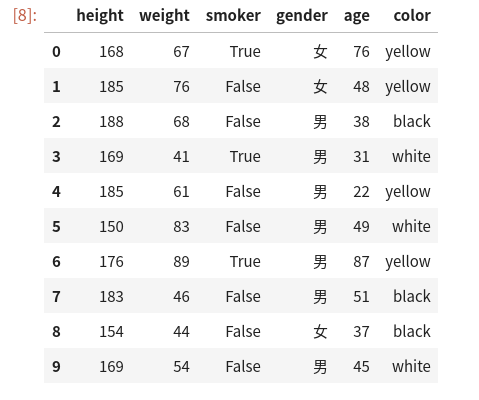
其中,每一列都是一個Series,然后多列組合在一起就構成了一個二維的Series容器。那么,當數據以DataFrame的格式進行組織的時候,要確定某一行某一列,需要怎么索引定位?在numpy中我們直接通過下標的方式就可以實現這一操作。而在pandas中類似,只是這個下標有時候不再是單純的數字。
那么,從現在開始,假設我們生成了如上表的隨機數據。我們可以做的操作如下
pandas基本操作
#生成上面數據的代碼(來源:https://zhuanlan.zhihu.com/p/100064394)
import pandas as pd
import numpy as np
boolean=[True,False]
gender=["男","女"]
color=["white","black","yellow"]
data=pd.DataFrame({
"height":np.random.randint(150,190,10),
"weight":np.random.randint(40,90,10),
"smoker":[boolean[x] for x in np.random.randint(0,2,10)],
"gender":[gender[x] for x in np.random.randint(0,2,10)],
"age":np.random.randint(15,90,10),
"color":[color[x] for x in np.random.randint(0,len(color),10) ]
}
)
對于上面生成的隨機數據,我們可以通過data.index查看他的索引,data.columns查看他的列標簽。

這個索引在生成的時候,由于我們沒有添加額外的信息。所以他只能默認為數字。因此,在pandas中,我們最基本的操作就是:
- 通過
data.index = 標簽序列來改變數據的標簽 - 也可以通過
data.set_index()來設置標簽

- 同樣地,還可以通過
data.colums = ['col1', 'col2'...]來改變Series的列標簽
顯示基本屬性
DataFrame的基本屬性主要有

當然,當我們獲取到一些DataFrame數據的第一時間,我們還可以通過data.info()和data.describe()來快速瀏覽數據相關的信息
pandas索引和切片
在我們設定好合適的index和columns以后,就可以進行索引和切片操作了
索引
先講對于Series的索引操作。對于一個DataFrame的數據組合,我們可以通過選擇具體的某一列來確定一個Series。仍然用上面生成的數據為例:

這時候的height_data就是pandas里面的Series類型數據。可以進行如下操作
height_data[i]height_data[a:b:step]- 也可以進行
bool索引:height_data>170 - 也可以通過
height_data.isna()判斷元素是否為NaN - 如果
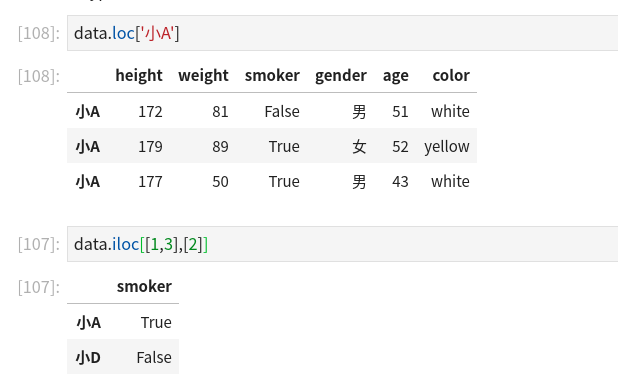
index是字符串,那么我們還可以通過height_data[['小A','小B']]這樣的方式顯示小A和小B的身高數據
此外,在pandas中,對于DataFrame類型的數據,還可以通過標簽和位置索引行數據
data.loc通過行標簽進行行索引data.iloc根據位置獲取行數據
切片
進而就是常用的切片操作,在bool索引的基礎上,我們可以很快地根據需要進行切片操作。
- 當切片對象是
series時,通過height_data[height_data>170]可以快速的完成切片操作 - 當然,也可以利用**索引2.**進行切片
當切片對象是DataFrame的時候,可以通過如下兩種方式進行切片
-
直接切片
data[1:5:2] -
根據某一個特征進行選擇切片。比如我們想篩選不吸煙的所有個體。
data[data['smoker'] == False] -
當然,也可以根據身高大于等于175且不吸煙的男性進行篩選

pandas進一步操作
前面提到,在我們剛拿到數據的時候,我們可以做一些簡單的操作。比如,通過.info()和.describe()等方法查看數據的基本信息。而當我們需要對數據進行統計分析的時候。比如,查看年齡最大的幾個人、有多少人是不吸煙的等。因此,我們需要對數據進行排序、或者計數。
data.sort_values('height', ascending=False)將整個數據組,按照身高進行降序排序data['color'].value_counts()進行膚色頻次統計
當然,我們仍然可以對int64和float數據進行基本的數理統計
data.mean()
data.max()
data.std()
data.median()
如何創建Series和DataFrame數據
直觀地講,Series里面的數據有點像字典,其中index對應的是鍵,而列對應的值則是鍵值。所以,可以直接將字典類型數據轉換成pandas里面的Series數據類型。
而當字典類型包含多個值時,這個字典類型的鍵就會轉換成DataFrame中的columns而非index。這要求每個鍵對應的值個數相同

讀取外部數據
很多時候,我們會通過各種途徑得到一系列數據文件。以csv為例,我們直接使用pd.read_csv即可。只是剛讀取得到的數據,也許需要做一些數據預處理工作。比如缺省數據如何處理
寫在后面
到目前為止,只是把基本的pandas所涉及到的知識點復述了一遍。完全沒有任何工作難度。權當做了個筆記。準備這周抽空將csv實例分析整理一下。那才是讓我進階不少的東西。盡管折騰也很多
智能推薦
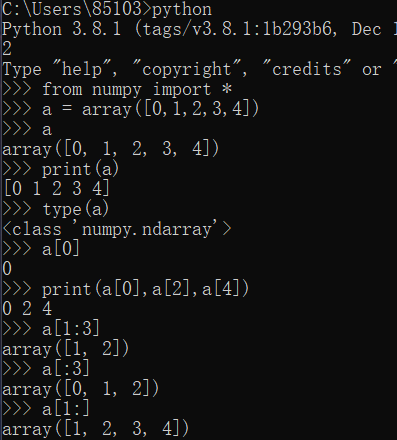
NumPy常用函數——Python第三方庫
關于Python第三方庫NumPy: NumPy(Numerical Python) 是 Python 語言的一個擴展程序庫,提供了多維數組和矩陣的常用操作,同時也提供了一些高效的科學計算函數。NumPy可以直接完成數組和矩陣的運算,無需循環,同時其底層運算通過C語言實現,處理速度快效率高,適用于大規模多維數組運算。 pip安裝NumPy庫: NumPy可利用pip方法進行安裝: NumPy常用函...

python常用第三方庫的安裝
python常用第三方庫的安裝 推薦使用清華源鏡像安裝 檢查第三方庫是否正常安裝的方法: 在cmd中輸入pip list,可以看到安裝的所有庫 在python環境下,導入第三方庫,例如:import pandas,回車后,若無異常,表示安裝成功 如果沒有pip的小伙伴,可以在cmd中輸入下列代碼,安裝以及更新pip:...
Python 安裝第三方庫
1、PIP工具 PIP安裝目錄 c:\python34\scripts 確認PIP是否安裝,執行 pip -V c:\Python34\Scripts>pip -V 顯示 安裝第三方庫 pyExcelerator c:\Python34\Scripts>pip...
python添加第三方庫
今天在導入requests庫出現錯誤,下載時發現python文件夾下 Scripts竟然是空的,打開cmd輸入 安裝pip會在Scripts文件夾下發現這些 接下來輸入 這樣環境變量就配置好了 然后cmd進入到你的Scripts路徑下開始安裝requests包,指令是 其實你也可以用這個下載各種第三方庫指令也是這個 pip install + …… 安裝好的庫可以在py...
Python安裝第三方庫Pygame
問題 在安裝第三方庫的時候經常會遇到: 最近在寫一個小游戲時,引入Pygame模塊發生報錯,結果在Pycharm中怎么也安裝不上。 檢查Python版本 打開命令行窗口(Windows+R輸入cmd),輸入python,查看當前python版本。 以版本python3.7為例,下載的Pygame包需要與之匹配,下載含有"cp37",否則會報錯: 下載對應的.whl...
猜你喜歡
python第三方庫Faker源碼解讀
源碼背景 Faker是一個Python第三方庫,GITHUB開源項目,主要用于創建偽數據創建的數據包含地理信息類、基礎信息類、個人賬戶信息類、網絡基礎信息類、瀏覽器信息類、文件信息類、數字類 文本加密類、時間信息類、其他類別等。 源碼的地址:https://github.com/joke2k/faker 收集的函數速查:https://blog.csdn.net/qq_41545431/artic...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...