統計學習方法讀書筆記8-樸素貝葉斯
標簽: 統計學習方法讀書筆記 python 機器學習 算法 樸素貝葉斯
1.樸素貝葉斯的基本方法
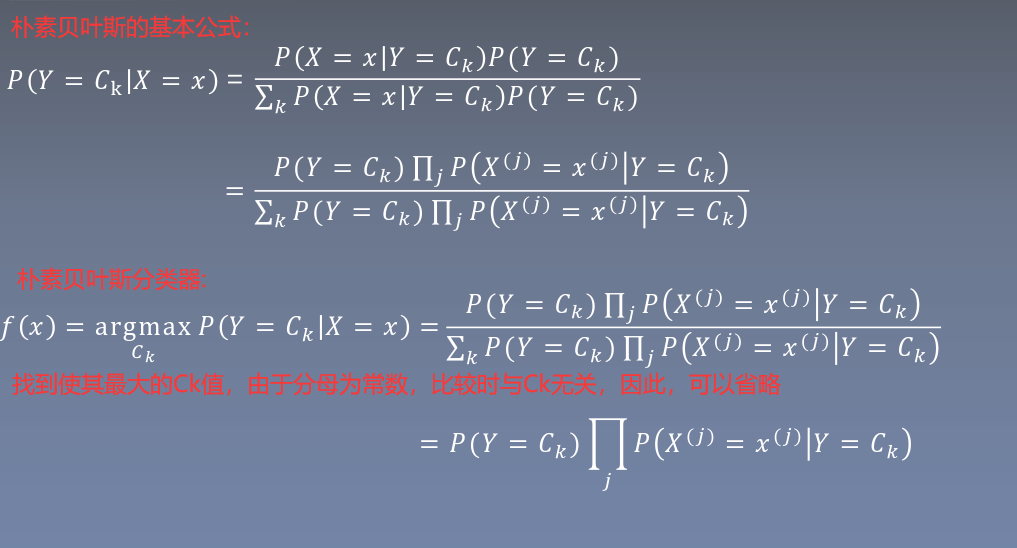
2.樸素貝葉斯的參數估計
1.極大似然估計


2.樸素貝葉斯算法

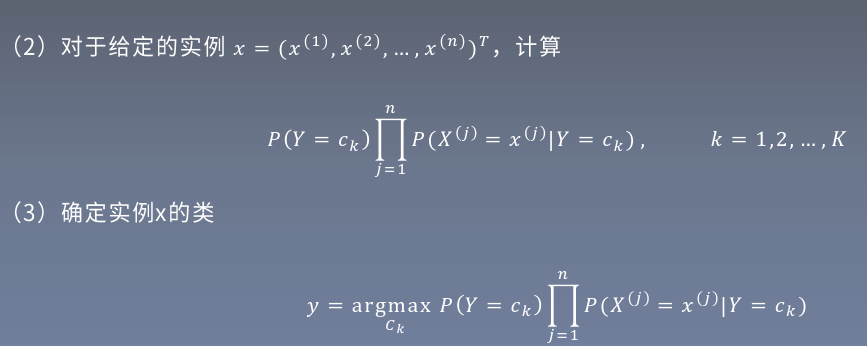

3.貝葉斯估計
用極大似然估計可能出現所要估計的概率值為0的情況,這是會影響到后驗概率的計算結果,使分類產生偏差。解決這一問題的方法就是采用貝葉斯估計,原理是在分子、分母中加上指定數值,使得不同項之間大小關系不變,,但消除了分母為0的可能性



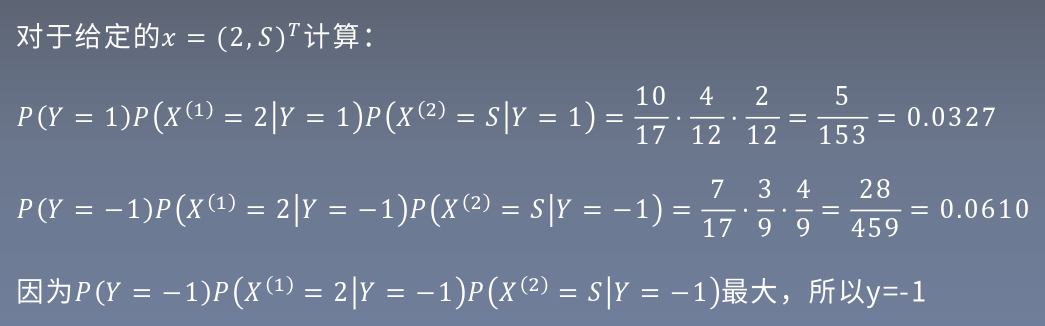
3.后驗概率最大化-期望風險最小化

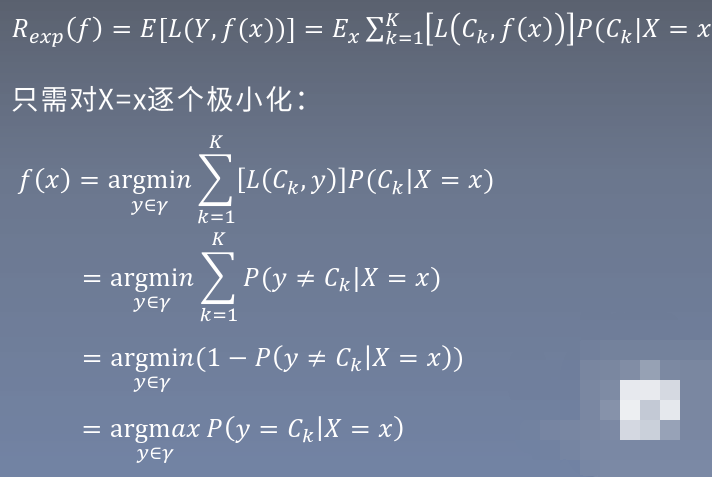
4.樸素貝葉斯代碼實現
#!usr/bin/env python
# -*- coding:utf-8 _*-
"""
@author: liujie
@software: PyCharm
@file: natives.py
@time: 2020/10/21 17:18
"""
import time
import numpy as np
from tqdm import tqdm
def loaddata(filename):
"""
加載數據集
:param filename: 文件路徑
:return: 數據與標簽
"""
# 存放數據及標簽
dataArr = []
labelArr = []
# 讀取文件
fr = open(filename)
# 遍歷讀取文件每一行
for line in tqdm(fr.readlines()):
# 獲取當前行,并按','進行切割,返回列表
curLine = line.strip().split(',')
# 獲取數據
# 將數據進行了二值化處理,大于128的轉換成1,小于的轉換成0,方便后續計算
dataArr.append([int(int(num) > 128) for num in curLine[1:]])
# 獲取標簽
labelArr.append(int(curLine[0]))
# 返回數據集與標簽
return dataArr, labelArr
def NaivesBayes(Py, Px_y, x):
"""
通過貝葉斯進行概率估計
:param Py: 先驗概率分布
:param Px_y: 條件概率分布
:param x: 要估計的樣本
:return: 返回所有label的估計概率
"""
# 設置特征數目
featureNum = 784
# 設置類別數目
classNum = 10
# 建立存放所有標記的概率的數組
P = [0] * classNum
# 對于每一個類別,單獨估計其概率
for i in range(classNum):
# 初始化sum為0,sum為求和項。
# 在訓練過程中對概率進行了log處理,所以這里原先應當是連乘所有概率,最后比較哪個概率最大
# 但是當使用log處理時,連乘變成了累加,所以使用sum
sum = 0
# 獲取某一個類別的某個特征的概率,進行累加
for j in range(featureNum):
# x[j] = 0或1
sum += Px_y[i][j][x[j]]
# 最后再和先驗概率相加(也就是式4.7中的先驗概率乘以后頭那些東西,乘法因為log全變成了加法)
P[i] = sum + Py[i]
# 返回該概率最大值對應的索引,即為分類
return P.index(max(P))
def model_test(Py, Px_y, testDataArr, testLabelArr):
"""
對數據集進行測試
:param Py: 先驗概率
:param Px_y: 條件概率
:param testDataArr:測試數據集
:param testLabelArr: 測試數據標簽
:return: 返回正確率
"""
# 錯誤值計數
errorCnt = 0
# 遍歷測試集的每一個樣本
for i in tqdm(range(len(testDataArr))):
# 獲取預測值
predict = NaivesBayes(Py, Px_y, testDataArr[i])
# 如果預測值不等于標志,則errorCnt + 1
if predict != testLabelArr[i]:
errorCnt += 1
# 返回準確率
return 1 - (errorCnt / len(testDataArr))
def getAllProbability(trainDataArr, trainLabelArr):
"""
通過訓練集獲得先驗概率與條件概率
:param trainDataArr: 訓練數據集
:param trainLabelArr: 訓練數據集標簽
:return: 返回先驗概率與條件概率
"""
# 設置特征數目
featureNum = 784
# 設置類別數目
labelNum = 10
# 初始化先驗概率存放數組
Py = np.zeros((labelNum, 1))
# 對每個類別進行一次循環,分別計算它們的先驗概率分布
for i in range(labelNum):
# np.mat(trainLabelArr) == i:將標簽轉換為矩陣形式,里面的每一位與i比較,若相等,該位變為Ture,反之False
# np.sum(np.mat(trainLabelArr) == i):計算上一步得到的矩陣中Ture的個數,進行求和(直觀上就是找所有label中有多少個
# 為i的標記,求得4.8式P(Y = Ck)中的分子)
# 貝葉斯估計:分子加1,分母加上K(K為標簽可取的值數量,這里有10個數,取值為10)
Py[i] = (np.sum(np.mat(trainLabelArr) == True) + 1) / (len(trainLabelArr) + 10)
# 轉為log形式,防止下溢出
Py = np.log(Py)
# 計算條件概率 Px_y=P(X=x|Y = y)
# 計算條件概率分成了兩個步驟,下方第一個大for循環用于累加,參考書中“4.2.3 貝葉斯估計 式4.10”,下方第一個大for循環內部是
# 用于計算式4.10的分子,至于分子的+1以及分母的計算在下方第二個大For內
# 初始化為全0矩陣,用于存放所有情況下的條件概率,xj只有0和1
Px_y = np.zeros((labelNum, featureNum, 2))
# 對標記集進行遍歷
for i in range(len(trainLabelArr)):
# 獲取當前循環所使用的標記
label = trainLabelArr[i]
# 獲取當前要處理的樣本
x = trainDataArr[i]
# 對該樣本的每一維特診進行遍歷
for j in range(featureNum):
# 在矩陣中對應位置加1
# 這里還沒有計算條件概率,先把所有數累加,全加完以后,在后續步驟中再求對應的條件概率
Px_y[label][j][int(x[j])] += 1
# 第二個大for循環,計算式4.10的分母,以及分子和分母之間的除法
# 循環每一個標記
for label in range(labelNum):
# 循環每一個標記對應的每一個特征
for j in range(featureNum):
# 獲取y=label,第j個特診為0的個數
Px_y0 = Px_y[label][j][0]
# 獲取y=label,第j個特診為1的個數
Px_y1 = Px_y[label][j][1]
# 對式4.10的分子和分母進行相除,再除之前依據貝葉斯估計,分母需要加上2(為每個特征可取值個數)
# 分別計算對于y= label,x第j個特征為0和1的條件概率分布
Px_y[label][j][0] = np.log((Px_y0 + 1) / (Px_y0 + Px_y1 + 2))
Px_y[label][j][1] = np.log((Px_y1 + 1) / (Px_y0 + Px_y1 + 2))
return Py, Px_y
if __name__ == '__main__':
start = time.time()
# 讀取數據集
print('start to read trainSet')
trainDataArr, trainLabelArr = loaddata('data/mnist_train.csv')
print('start to read testSet')
testDataArr, testLabelArr = loaddata('data/mnist_test.csv')
# 開始訓練,學習先驗概率與條件概率分布
print('start to train')
Py, Px_y = getAllProbability(trainDataArr, trainLabelArr)
# 使用習得的先驗概率與條件概率分布,開始測試
print('start to test')
accuracy = model_test(Py, Px_y, testDataArr, testLabelArr)
# 打印準確率
print('accuracy = ', accuracy)
# 打印時間
end = time.time()
print('time=', end - start)
start to read trainSet
100%|██████████| 60000/60000 [00:17<00:00, 3379.31it/s]
start to read testSet
100%|██████████| 10000/10000 [00:02<00:00, 3418.50it/s]
start to train
start to test
100%|██████████| 10000/10000 [00:41<00:00, 242.28it/s]
accuracy = 0.8435
time= 102.47366952896118
智能推薦

《統計學習方法》代碼全解析——第四部分樸素貝葉斯
1.樸素貝葉斯法是典型的生成學習方法。生成方法由訓練數據學習聯合概率分布 (,) P(X,Y) ,然后求得后驗概率分布 (|) P(Y|X) 。具體來說,利用訓練數據學習 (|) P(X|Y) 和 () P(Y) 的估計,得到聯合概率分布: (,)=()(|) 概率估計方法可以是極大似然估計或貝葉斯估計。 2.樸素貝葉斯法的基本假設是條件獨立性 這是一個較強的假...
(每天一點點)統計學習方法——樸素貝葉斯法
1、概率論基礎 貝葉斯原理就是求解后驗概率。如果已知p(x|c)要求p(c|x),我們可以使用貝葉斯公式進行求解。 貝葉斯公式: ps:圖片出處 樸素貝葉斯分類器中的樸素指的是特征樣本之間相互獨立。 2、舉個栗子 已在線社區留言板為例子,我們要屏蔽侮辱性言論。對此問題我們建立兩個類別:侮辱性和非侮辱性。我們先定一個詞典,比如[dog,love,cute…],然后把一條留言分成詞向量[...

統計學習方法第四章(樸素貝葉斯)及Python實現及sklearn實現
1原理 樸素貝葉斯 貝葉斯:根據貝葉斯定理p(y|x) = p(y)p(x|y)/p(x).選擇p(y|x) 最大的類別作為x的類別。可知樸素貝葉斯是監督學習的生成模型(由聯合概率分布得到概率分布)。選擇p(y|x) 最大的類別時,分母相同,所以簡化為比較 p(y)p(x|y)的大小。 樸素: 計算p(x|y)的概率,假設x是n維向量,每維向量有sn個取值可能,則就要計算類別*(sn的n次方)次。...

統計學習方法第四章:樸素貝葉斯法(naive Bayes),貝葉斯估計及python實現
統計學習方法第二章:感知機(perceptron)算法及python實現 統計學習方法第三章:k近鄰法(k-NN),kd樹及python實現 統計學習方法第四章:樸素貝葉斯法(naive Bayes),貝葉斯估計及python實現 統計學習方法第五章:決策樹(decision tree),CART算法,剪枝及python實現 統計學習方法第五章:決策樹(decision tree),ID3算法,C...

猜你喜歡
《統計學習方法》讀書筆記——感知機
感知機 一、感知機的定義 假設輸入空間 X⊆Rn\mathcal{X}\subseteq{\mathcal{R^n}}X⊆Rn,輸出空間Y={+1,−1}\mathcal{Y} = \{+1, -1\}Y={+1,−1}; 輸入x∈Xx\in\mathcal{X}x∈X表示樣本的特征向量,輸出y∈Yy\in\mathcal{...

統計學習方法讀書筆記--概論
定義 統計學習==統計機器學習 方法分類 監督學習 無監督學習 半監督學習 強化學習 三要素 模型 策略 算法 步驟 得到一個有限的訓練數據集合;(原始數據) 確定假設空間,即學習模型的集合;(是分類問題,還是回歸問題) 確定模型選擇的準則,即學習的策略;(選擇什么樣的分類器呢?) 實現求解最優模型的算法,即學習的算法;(分類器的參數怎么求?) 通過學習方法選擇最優模型;(各種模型,哪個是最優的?...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...