Python讀寫Excel表格
Python寫Excel——xlwt
Python寫Excel的難點,不在構造一個Workbook的本身,而是填充的數據,不過這不在范圍內。
在寫Excel的操作中,也有棘手的問題,比如寫入合并的單元格,就是比較麻煩的,另外寫入還有不同的樣式。
詳細代碼如下:
import xlwt
#設置表格樣式
def set_style(name,height,bold=False):
style = xlwt.XFStyle()
font = xlwt.Font()
font.name = name
font.bold = bold
font.color_index = 4
font.height = height
style.font = font
return style
#寫Excel
def write_excel():
f = xlwt.Workbook()
sheet1 = f.add_sheet('學生',cell_overwrite_ok=True)
row0 = ["姓名","年齡","出生日期","愛好"]
colum0 = ["張三","李四","戀習Python","小明","小紅","無名"]
#寫第一行
for i in range(0,len(row0)):
sheet1.write(0,i,row0[i],set_style('Times New Roman',220,True))
#寫第一列
for i in range(0,len(colum0)):
sheet1.write(i+1,0,colum0[i],set_style('Times New Roman',220,True))
sheet1.write(1,3,'2006/12/12')
sheet1.write_merge(6,6,1,3,'未知')#合并行單元格
sheet1.write_merge(1,2,3,3,'打游戲')#合并列單元格
sheet1.write_merge(4,5,3,3,'打籃球')
f.save('test.xls')
if __name__ == '__main__':
write_excel()
結果圖:
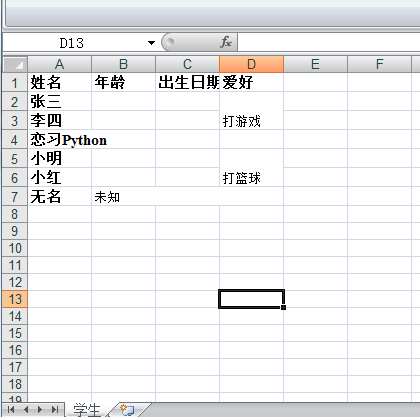
在此,對write_merge()的用法稍作解釋,如上述:sheet1.write_merge(1,2,3,3,'打游戲'),即在四列合并第2,3列,合并后的單元格內容為"合計",并設置了style。其中,里面所有的參數都是以0開始計算的。
Python讀Excel——xlrd
Python讀取Excel表格,相比xlwt來說,xlrd提供的接口比較多,但過程也有幾個比較麻煩的問題,比如讀取日期、讀合并單元格內容。
下面先看看基本的操作:

(圖表數據)
整體思路為,打開文件,選定表格,讀取行列內容,讀取表格內數據
詳細代碼如下:
import xlrd
from datetime import date,datetime
file = 'test3.xlsx'
def read_excel():
wb = xlrd.open_workbook(filename=file)#打開文件
print(wb.sheet_names())#獲取所有表格名字
sheet1 = wb.sheet_by_index(0)#通過索引獲取表格
sheet2 = wb.sheet_by_name('年級')#通過名字獲取表格
print(sheet1,sheet2)
print(sheet1.name,sheet1.nrows,sheet1.ncols)
rows = sheet1.row_values(2)#獲取行內容
cols = sheet1.col_values(3)#獲取列內容
print(rows)
print(cols)
print(sheet1.cell(1,0).value)#獲取表格里的內容,三種方式
print(sheet1.cell_value(1,0))
print(sheet1.row(1)[0].value)
運行結果如下:

那么問題來了,上面的運行結果中紅框框中的字段明明是出生日期,可顯示的確實浮點數;同時合并單元格里面應該是有內容的,結果不能為空。
別急,我們來一一解決這兩個問題:
1.Python讀取Excel中單元格內容為日期的方式
Python讀取Excel中單元格的內容返回的有5種類型,即上面例子中的ctype:
ctype : 0 empty,1 string,2 number, 3 date,4 boolean,5 error
即date的ctype=3,這時需要使用xlrd的xldate_as_tuple來處理為date格式,先判斷表格的ctype=3時xldate才能開始操作。
詳細代碼如下:
import xlrd
from datetime import date,datetime
print(sheet1.cell(1,2).ctype)
date_value = xlrd.xldate_as_tuple(sheet1.cell_value(1,2),wb.datemode)
print(date_value)
print(date(*date_value[:3]))
print(date(*date_value[:3]).strftime('%Y/%m/%d'))
運行結果如下:

2.獲取合并單元格的內容
在操作之前,先介紹一下merged_cells()用法,merged_cells返回的這四個參數的含義是:(row,row_range,col,col_range),其中[row,row_range)包括row,不包括row_range,col也是一樣,即(1, 3, 4, 5)的含義是:第1到2行(不包括3)合并,(7, 8, 2, 5)的含義是:第2到4列合并。
詳細代碼如下:
print(sheet1.merged_cells)
print(sheet1.cell_value(1,3))
print(sheet1.cell_value(4,3))
print(sheet1.cell_value(6,1))
運行結果如下:
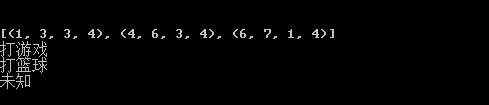
發現規律了沒?是的,獲取merge_cells返回的row和col低位的索引即可! 于是可以這樣批量獲取:
詳細代碼如下:
merge = []
print(sheet1.merged_cells)
for (rlow,rhigh,clow,chigh) in sheet1.merged_cells:
merge.append([rlow,clow])
for index in merge:
print(sheet1.cell_value(index[0],index[1]))
運行結果跟上圖一樣,如下:
智能推薦
Python——Excel文件讀寫
最新做測試案例時,需要使用*.xls文件作為輸入,然后發現對于Excel文件,python有第三方庫,官網地址為Working with Excel Files in Python,其中包含多個庫。這里我選用的是xlrd,官網里有文檔鏈接 xlrd cell object(單元格對象)包含三個屬性:ctype, value和xf_index. Python中,cell(單元格)的類型和對應的類型值...

Python 讀寫excel文件
最近需要用到Python來操作excel表,讀取表格內容到數據庫。所以就搜索了相關資料。 查找了一下,可以操作excel表的幾個庫有以下幾個: openpyxl 這個是推薦使用的庫,可以讀寫Excel 2010以上格式,以.xlsx結尾的文件。 xlsxwriter 這個支持.xlsx,但是只支持寫入,格式化等操作,不支持讀取。 xlrd 這個支持讀取數據,支持以xls結尾的文件,也就是比較老的格...


freemarker + ItextRender 根據模板生成PDF文件
1. 制作模板 2. 獲取模板,并將所獲取的數據加載生成html文件 2. 生成PDF文件 其中由兩個地方需要注意,都是關于獲取文件路徑的問題,由于項目部署的時候是打包成jar包形式,所以在開發過程中時直接安照傳統的獲取方法沒有一點文件,但是當打包后部署,總是出錯。于是參考網上文章,先將文件讀出來到項目的臨時目錄下,然后再按正常方式加載該臨時文件; 還有一個問題至今沒有解決,就是關于生成PDF文件...
電腦空間不夠了?教你一個小秒招快速清理 Docker 占用的磁盤空間!
Docker 很占用空間,每當我們運行容器、拉取鏡像、部署應用、構建自己的鏡像時,我們的磁盤空間會被大量占用。 如果你也被這個問題所困擾,咱們就一起看一下 Docker 是如何使用磁盤空間的,以及如何回收。 docker 占用的空間可以通過下面的命令查看: TYPE 列出了docker 使用磁盤的 4 種類型: Images:所有鏡像占用的空間,包括拉取下來的鏡像,和本地構建的。 Con...
猜你喜歡

requests實現全自動PPT模板
http://www.1ppt.com/moban/ 可以免費的下載PPT模板,當然如果要人工一個個下,還是挺麻煩的,我們可以利用requests輕松下載 訪問這個主頁,我們可以看到下面的樣式 點每一個PPT模板的圖片,我們可以進入到詳細的信息頁面,翻到下面,我們可以看到對應的下載地址 點擊這個下載的按鈕,我們便可以下載對應的PPT壓縮包 那我們就開始做吧 首先,查看網頁的源代碼,我們可以看到每一...


Linux C系統編程-線程互斥鎖(四)
互斥鎖 互斥鎖也是屬于線程之間處理同步互斥方式,有上鎖/解鎖兩種狀態。 互斥鎖函數接口 1)初始化互斥鎖 pthread_mutex_init() man 3 pthread_mutex_init (找不到的情況下首先 sudo apt-get install glibc-doc sudo apt-get install manpages-posix-dev) 動態初始化 int pthread_...

統計學習方法 - 樸素貝葉斯
引入問題:一機器在良好狀態生產合格產品幾率是 90%,在故障狀態生產合格產品幾率是 30%,機器良好的概率是 75%。若一日第一件產品是合格品,那么此日機器良好的概率是多少。 貝葉斯模型 生成模型與判別模型 判別模型,即要判斷這個東西到底是哪一類,也就是要求y,那就用給定的x去預測。 生成模型,是要生成一個模型,那就是誰根據什么生成了模型,誰就是類別y,根據的內容就是x 以上述例子,判斷一個生產出...

styled-components —— React 中的 CSS 最佳實踐
https://zhuanlan.zhihu.com/p/29344146 Styled-components 是目前 React 樣式方案中最受關注的一種,它既具備了 css-in-js 的模塊化與參數化優點,又完全使用CSS的書寫習慣,不會引起額外的學習成本。本文是 styled-components 作者之一 Max Stoiber 所寫,首先總結了前端組件化樣式中的最佳實踐原則,然后在此基...